Recognition: unknown
In-memory Multidimensional Indexing Using the skd-tree
Pith reviewed 2026-05-07 12:35 UTC · model grok-4.3
The pith
The skd-tree improves multi-dimensional indexing in memory by slicing each node into multiple partitions along one dimension.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
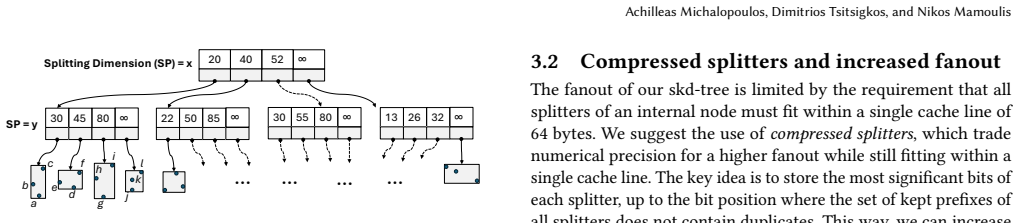
We propose the slicing kd-tree (skd-tree), a variant of the kd-tree where each node partitions the space of its subtree into multiple slices across a single splitting dimension. By compressing the splitters of the partitions and with the help of data-parallelism, we radically reduce the number of levels of the tree and limit the number of computations required for multi-dimensional range and proximity queries. The nodes resemble the nodes of a main-memory B+-tree, however a different dimension is used at each level. Our novel range and kNN algorithms on the skd-tree apply only a small constant number of SIMD instructions at each node during tree traversal. Our contributions also include a to
What carries the argument
The skd-tree node, which partitions its subtree space into multiple slices along one chosen dimension using compressed splitters and SIMD traversal.
If this is right
- Range and kNN queries traverse fewer levels and execute only a small constant number of SIMD instructions at each visited node.
- Tree height drops substantially compared with conventional kd-trees for the same data volume.
- A top-down construction plus specialized inner and leaf nodes maintain balance while supporting efficient updates.
- The design delivers competitive or better query times than established methods on both real and synthetic multi-dimensional collections.
Where Pith is reading between the lines
- The slicing idea could be grafted onto other spatial trees to achieve similar height reductions in high-dimensional settings.
- Wider SIMD registers on newer CPUs would amplify the per-node speedups already obtained.
- The update algorithm suggests the structure can handle moderate dynamism, though sustained high-update workloads would require further balance measurements.
Load-bearing premise
The reduction in tree height and per-node computations from slicing and SIMD usage will produce net gains over existing structures across varied data distributions and query workloads without excessive overhead from slice management or node balancing.
What would settle it
A direct head-to-head timing experiment on a high-dimensional skewed dataset where skd-tree range or kNN queries take longer than a standard kd-tree or R-tree because of slice-handling costs.
Figures




read the original abstract
In this paper, we revisit the problem of indexing multi-dimensional data in memory for the efficient support of multi-dimensional range queries and nearest neighbor queries. This is a classic problem in main-memory databases, where there is a need for indexing multiple columns simultaneously. Established data structures include the R-tree, kd-tree, quad-tree, and grid-based partitioning. More recently, multi-dimensional learned indexes have also been proposed to address this problem. We propose slicing kd-tree (skd-tree), a variant of the kd-tree, where each node partitions the space of its subtree into multiple slices across a single splitting dimension. By compressing the splitters of the partitions and with the help of data-parallelism, we (i) radically reduce the number of levels of the tree and (ii) limit the number of computations required for multi-dimensional range and proximity queries. The nodes of the skd-tree resemble the nodes of a main-memory B+-tree, however, a different dimension is used at each level. Our novel range and kNN algorithms on the skd-tree apply only a small constant number of SIMD instructions at each node during tree traversal. Our contributions also include a novel top-down construction algorithm, different types of inner and leaf nodes that warrant tree balancing, and a novel update algorithm. Our skd-tree achieves strong performance compared to existing methods, according to our experimental evaluation on real and synthetic datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the skd-tree, a variant of the kd-tree for in-memory multi-dimensional indexing that supports range and nearest-neighbor queries. Each node partitions its subtree space into multiple slices along a single dimension using compressed splitters; combined with SIMD, this is claimed to reduce tree height and per-node computation. The design includes a top-down construction algorithm, heterogeneous inner/leaf nodes to maintain balance, and a novel update algorithm. The central claim is that the skd-tree delivers strong performance relative to kd-trees, R-trees, quad-trees, grids, and learned indexes on real and synthetic datasets.
Significance. If the net performance gains from reduced height and SIMD traversal hold without being offset by slice-management or rebalancing costs, the skd-tree would represent a practical advance for main-memory multi-column indexing in databases. The explicit use of data-parallelism at each node and the top-down construction with balancing mechanisms are concrete strengths that differentiate it from prior kd-tree variants.
major comments (3)
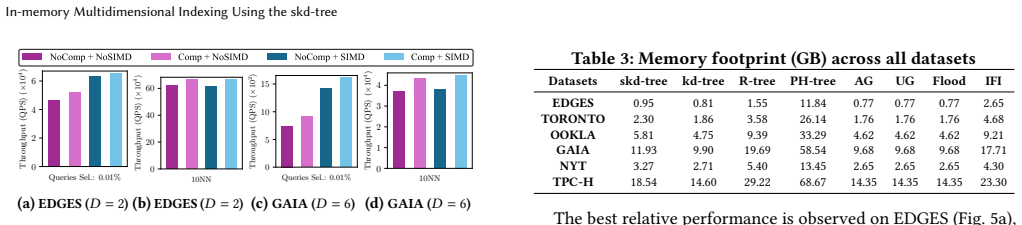
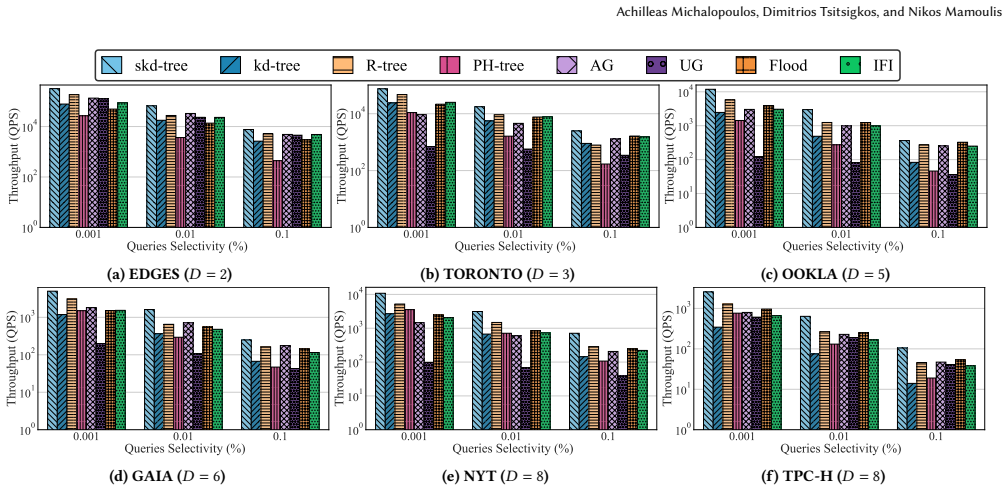
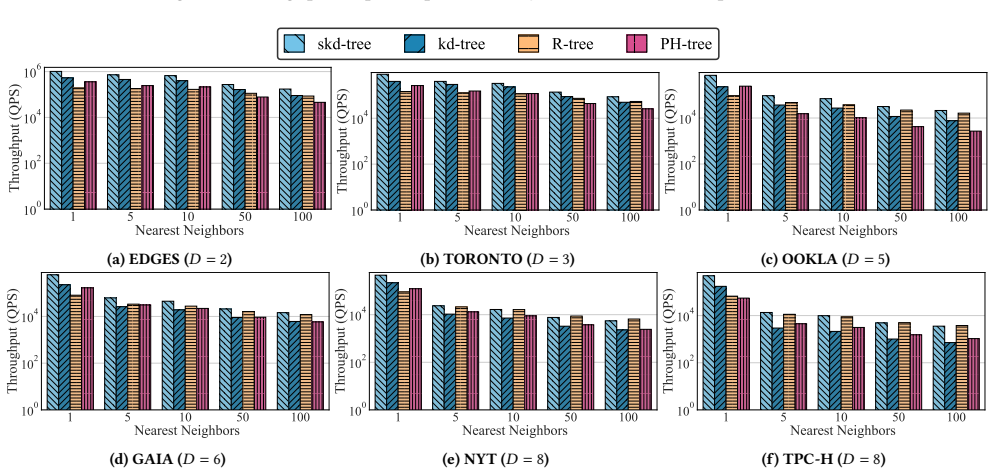
- [§6] §6 (Experimental Evaluation): The headline claim of 'strong performance' is presented without a quantitative breakdown of slice-selection overhead versus traversal savings, without workload or data-distribution details, and without error bars or statistical analysis; this directly undermines verification of the weakest assumption that slicing plus SIMD yields net gains across varied inputs.
- [§4] §4 (Construction and Balancing): The top-down construction with heterogeneous inner/leaf nodes is asserted to keep height logarithmic, yet no height bounds, fan-out analysis, or rebalancing frequency measurements are supplied; without these, it is impossible to confirm that update costs do not re-introduce the height and computation penalties the design aims to eliminate.
- [§5] §5 (Query Algorithms): The range and kNN traversal algorithms are described as using only a small constant number of SIMD instructions per node, but the text supplies no cache-miss or instruction-count measurements for the slice-lookup step; this leaves the reduced-computation claim dependent on an untested assumption about memory-access behavior.
minor comments (2)
- Notation for compressed splitters and slice identifiers is introduced without a consolidated table of symbols, making it harder to follow the node layout across sections.
- Figure captions in the experimental section should explicitly state the hardware (SIMD width, cache sizes) and the exact baseline implementations used for comparison.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. The comments correctly identify areas where additional quantitative analysis, measurements, and details would strengthen the manuscript. We address each major comment below and will incorporate the requested revisions.
read point-by-point responses
-
Referee: [§6] §6 (Experimental Evaluation): The headline claim of 'strong performance' is presented without a quantitative breakdown of slice-selection overhead versus traversal savings, without workload or data-distribution details, and without error bars or statistical analysis; this directly undermines verification of the weakest assumption that slicing plus SIMD yields net gains across varied inputs.
Authors: We agree that a quantitative breakdown of slice-selection overhead versus traversal savings, along with workload details and statistical analysis, would better substantiate the performance claims. In the revised manuscript we will add a dedicated analysis subsection that isolates the costs of compressed splitter lookup and SIMD slice selection against the savings from reduced tree height. We will also expand the experimental section with explicit workload and data-distribution characteristics for each dataset and include error bars from repeated runs together with basic statistical significance tests. revision: yes
-
Referee: [§4] §4 (Construction and Balancing): The top-down construction with heterogeneous inner/leaf nodes is asserted to keep height logarithmic, yet no height bounds, fan-out analysis, or rebalancing frequency measurements are supplied; without these, it is impossible to confirm that update costs do not re-introduce the height and computation penalties the design aims to eliminate.
Authors: The heterogeneous inner/leaf node design and top-down construction are intended to preserve logarithmic height while supporting updates. We acknowledge that explicit bounds and measurements are missing. In the revision we will provide a fan-out analysis together with a proof sketch for the expected height under the chosen splitting policy. We will also report empirical rebalancing frequency and update-cost measurements on the same real and synthetic datasets used for queries, demonstrating that rebalancing overhead remains negligible relative to the query-time benefits. revision: yes
-
Referee: [§5] §5 (Query Algorithms): The range and kNN traversal algorithms are described as using only a small constant number of SIMD instructions per node, but the text supplies no cache-miss or instruction-count measurements for the slice-lookup step; this leaves the reduced-computation claim dependent on an untested assumption about memory-access behavior.
Authors: We will augment the query-algorithm section with hardware performance-counter results that quantify cache misses and instruction counts for the slice-lookup step under both range and kNN workloads. These measurements will be collected on the same platforms used for the end-to-end experiments and will be compared against the baseline kd-tree, R-tree, and learned-index implementations to confirm that the constant SIMD instruction count translates into the expected reduction in memory-access overhead. revision: yes
Circularity Check
No significant circularity in skd-tree design or claims
full rationale
The paper introduces a new data structure (skd-tree) as a kd-tree variant using slicing, compressed splitters, SIMD traversal, heterogeneous nodes, top-down construction, and a custom update algorithm. All core contributions are algorithmic descriptions and empirical measurements on real/synthetic data; no equations, parameters, or performance predictions are shown to reduce by construction to fitted inputs or self-referential definitions. No load-bearing self-citations appear in the provided text, and the performance claim is explicitly tied to experimental evaluation rather than any derived equivalence. The derivation chain is self-contained as a novel proposal validated externally via benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
d.].Boost C++ Library
[n. d.].Boost C++ Library. https://www.boost.org/
-
[2]
d.].GAIA source
[n. d.].GAIA source. https://cdn.gea.esac.esa.int/Gaia/gdr3/gaia_source/
-
[3]
d.].NYC Yellow Taxi Trip Data
[n. d.].NYC Yellow Taxi Trip Data. https://www.kaggle.com/datasets/elemento/ nyc-yellow-taxi-trip-data
-
[4]
d.].OOKLA
[n. d.].OOKLA. https://www.kaggle.com/datasets/dhruvildave/ookla-internet- speed-dataset
-
[5]
d.].PH-tree Code
[n. d.].PH-tree Code. https://github.com/tzaeschke/phtree-cpp
-
[6]
d.].TPC-H Homepage
[n. d.].TPC-H Homepage. http://www.tpc.org/tpch/
-
[7]
Spatial Hadoop Datasets
2015. Spatial Hadoop Datasets. https://spatialhadoop.cs.umn.edu/datasets.html In-memory Multidimensional Indexing Using the skd-tree
2015
-
[8]
Agarwal, Lars Arge, Andrew Danner, and Bryan Holland-Minkley
Pankaj K. Agarwal, Lars Arge, Andrew Danner, and Bryan Holland-Minkley. 2003. Cache-oblivious data structures for orthogonal range searching. InProceedings of the 19th ACM Symposium on Computational Geometry, San Diego, CA, USA, June 8-10, 2003, Steven Fortune (Ed.). ACM, 237–245. doi:10.1145/777792.777828
-
[9]
Ibraheem Al-Furaih, Srinivas Aluru, Sanjay Goil, and Sanjay Ranka. 2000. Parallel Construction of Multidimensional Binary Search Trees.IEEE Trans. Parallel Distributed Syst.11, 2 (2000), 136–148. doi:10.1109/71.841750
-
[10]
Abdullah Al-Mamun, Ch. Md. Rakin Haider, Jianguo Wang, and Walid G. Aref
-
[11]
In23rd IEEE International Conference on Mobile Data Management, MDM 2022, Paphos, Cyprus, June 6-9,
The "AI + R" - tree: An Instance-optimized R - tree. In23rd IEEE International Conference on Mobile Data Management, MDM 2022, Paphos, Cyprus, June 6-9,
2022
-
[12]
doi:10.1109/MDM55031.2022.00023
IEEE, 9–18. doi:10.1109/MDM55031.2022.00023
-
[13]
Lars Arge, Mark de Berg, Herman J. Haverkort, and Ke Yi. 2004. The Priority R-Tree: A Practically Efficient and Worst-Case Optimal R-Tree. InProceedings of the ACM SIGMOD International Conference on Management of Data, Paris, France, June 13-18, 2004, Gerhard Weikum, Arnd Christian König, and Stefan Deßloch (Eds.). ACM, 347–358. doi:10.1145/1007568.1007608
-
[14]
Rudolf Bayer. 1997. The universal B-tree for multidimensional indexing: General concepts. InInternational Conference on Worldwide Computing and Its Applications. Springer, 198–209
1997
-
[15]
Norbert Beckmann, Hans-Peter Kriegel, Ralf Schneider, and Bernhard Seeger
-
[16]
The R*-Tree: An Efficient and Robust Access Method for Points and Rectangles. InProceedings of the 1990 ACM SIGMOD International Conference on Management of Data, Atlantic City, NJ, USA, May 23-25, 1990, Hector Garcia- Molina and H. V. Jagadish (Eds.). ACM Press, 322–331. doi:10.1145/93597.98741
-
[17]
Norbert Beckmann and Bernhard Seeger. 2009. A revised R*-tree in compar- ison with related index structures. InProceedings of the 2009 ACM SIGMOD International Conference on Management of data. 799–812
2009
-
[18]
Jon Louis Bentley. 1975. Multidimensional Binary Search Trees Used for Associa- tive Searching.Commun. ACM18, 9 (1975), 509–517. doi:10.1145/361002.361007
-
[19]
Jon Louis Bentley. 1979. Multidimensional Binary Search Trees in Database Applications.IEEE Trans. Software Eng.5, 4 (1979), 333–340. doi:10.1109/TSE. 1979.234200
work page doi:10.1109/tse 1979
-
[20]
Robert Binna, Eva Zangerle, Martin Pichl, Günther Specht, and Viktor Leis. 2018. HOT: A Height Optimized Trie Index for Main-Memory Database Systems. In Proceedings of the 2018 International Conference on Management of Data, SIGMOD Conference 2018, Houston, TX, USA, June 10-15, 2018, Gautam Das, Christopher M. Jermaine, and Philip A. Bernstein (Eds.). ACM...
-
[21]
Jose Luis Blanco and Pranjal Kumar Rai. 2014. nanoflann: a C++ header-only fork of FLANN, a library for Nearest Neighbor (NN) with KD-trees. https: //github.com/jlblancoc/nanoflann
2014
- [22]
- [23]
-
[24]
Yu Cao, Xiaojiang Zhang, Boheng Duan, Wenjing Zhao, and Huizan Wang. 2020. An Improved Method to Build the KD Tree Based on Presorted Results. In2020 IEEE 11th International Conference on Software Engineering and Service Science (ICSESS). 71–75. doi:10.1109/ICSESS49938.2020.9237636
-
[25]
Byn Choi, Rakesh Komuravelli, Victor Lu, Hyojin Sung, Robert L. Bocchino Jr., Sarita V. Adve, and John C. Hart. 2010. Parallel SAH k-D tree construction. InPro- ceedings of the ACM SIGGRAPH/EUROGRAPHICS Conference on High Performance Graphics 2010, Saarbrücken, Germany, June 25-27, 2010, Justin Hensley, Philipp Slusallek, David K. McAllister, and Christia...
-
[26]
Gaia Collaboration. 2023. Gaia Data Release 3: Summary of the content and survey properties.Astronomy & Astrophysics674 (June 2023), A1. doi:10.1051/ 0004-6361/202243940
2023
-
[27]
Angjela Davitkova, Evica Milchevski, and Sebastian Michel. 2020. The ML-Index: A Multidimensional, Learned Index for Point, Range, and Nearest-Neighbor Queries.. InEDBT. 407–410
2020
-
[28]
Jialin Ding, Vikram Nathan, Mohammad Alizadeh, and Tim Kraska. 2020. Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads.Proc. VLDB Endow.14, 2 (2020), 74–86. doi:10.14778/3425879.3425880
-
[29]
Haowen Dong, Chengliang Chai, Yuyu Luo, Jiabin Liu, Jianhua Feng, and Chaoqun Zhan. 2022. RW-Tree: A Learned Workload-aware Framework for R-tree Construction. In38th IEEE International Conference on Data Engineer- ing, ICDE 2022, Kuala Lumpur, Malaysia, May 9-12, 2022. IEEE, 2073–2085. doi:10.1109/ICDE53745.2022.00201
-
[30]
Gaia Collaboration et al. 2016. TheGaiamission.Astronomy & Astrophysics595 (Nov. 2016), A1. doi:10.1051/0004-6361/201629272
-
[31]
Raphael A Finkel and Jon Louis Bentley. 1974. Quad trees a data structure for retrieval on composite keys.Acta informatica4, 1 (1974), 1–9
1974
-
[32]
Jian Gao, Xin Cao, Xin Yao, Gong Zhang, and Wei Wang. 2023. LMSFC: A Novel Multidimensional Index based on Learned Monotonic Space Filling Curves.Proc. VLDB Endow.16, 10 (2023), 2605–2617. doi:10.14778/3603581.3603598
-
[33]
Goetz Graefe. 2024. More Modern B-Tree Techniques.Found. Trends Databases 13, 3 (2024), 169–249
2024
-
[34]
Tu Gu, Kaiyu Feng, Gao Cong, Cheng Long, Zheng Wang, and Sheng Wang. 2023. The RLR-Tree: A Reinforcement Learning Based R-Tree for Spatial Data.Proc. ACM Manag. Data1, 1 (2023), 63:1–63:26. doi:10.1145/3588917
-
[35]
Antonin Guttman. 1984. R-Trees: A Dynamic Index Structure for Spatial Search- ing. InSIGMOD’84, Proceedings of Annual Meeting, Boston, Massachusetts, USA, June 18-21, 1984, Beatrice Yormark (Ed.). ACM Press, 47–57. doi:10.1145/602259. 602266
-
[36]
Ali Hadian, Behzad Ghaffari, Taiyi Wang, and Thomas Heinis. 2023. COAX: Correlation-Aware Indexing. In39th IEEE International Conference on Data Engi- neering, ICDE 2023 - Workshops, Anaheim, CA, USA, April 3-7, 2023. IEEE, 55–59. doi:10.1109/ICDEW58674.2023.00014
-
[37]
Ali Hadian, Ankit Kumar, and Thomas Heinis. 2020. Hands-off Model Inte- gration in Spatial Index Structures. InAIDB@VLDB 2020, 2nd International Workshop on Applied AI for Database Systems and Applications, Held with VLDB 2020, Monday, August 31, 2020, Online Event / Tokyo, Japan, Bingsheng He, Berthold Reinwald, and Yingjun Wu (Eds.). https://drive.googl...
2020
-
[38]
Marios Hadjieleftheriou, Yannis Manolopoulos, Yannis Theodoridis, and Vassilis J. Tsotras. 2017. R-Trees: A Dynamic Index Structure for Spatial Searching. In Encyclopedia of GIS, Shashi Shekhar, Hui Xiong, and Xun Zhou (Eds.). Springer, 1805–1817. doi:10.1007/978-3-319-17885-1_1151
-
[39]
Warren Hunt, William R. Mark, and Gordon Stoll. 2006. Fast kd-tree Construction with an Adaptive Error-Bounded Heuristic. In2006 IEEE Symposium on Interactive Ray Tracing. 81–88. doi:10.1109/RT.2006.280218
-
[40]
Kersten, and Stefan Manegold
Stratos Idreos, Martin L. Kersten, and Stefan Manegold. 2007. Database Cracking. InThird Biennial Conference on Innovative Data Systems Research, CIDR 2007, Asilomar, CA, USA, January 7-10, 2007, Online Proceedings. www.cidrdb.org, 68–78
2007
-
[41]
Hosagrahar V Jagadish, Beng Chin Ooi, Kian-Lee Tan, Cui Yu, and Rui Zhang
-
[42]
iDistance: An adaptive B+-tree based indexing method for nearest neighbor search.ACM Transactions on Database Systems (TODS)30, 2 (2005), 364–397
2005
-
[43]
Ibrahim Kamel and Christos Faloutsos. 1994. Hilbert R-tree: An Improved R- tree using Fractals. InVLDB’94, Proceedings of 20th International Conference on Very Large Data Bases, September 12-15, 1994, Santiago de Chile, Chile, Jorge B. Bocca, Matthias Jarke, and Carlo Zaniolo (Eds.). Morgan Kaufmann, 500–509. http://www.vldb.org/conf/1994/P500.PDF
1994
-
[44]
Nguyen, Tim Kaldewey, Victor W
Changkyu Kim, Jatin Chhugani, Nadathur Satish, Eric Sedlar, Anthony D. Nguyen, Tim Kaldewey, Victor W. Lee, Scott A. Brandt, and Pradeep Dubey
-
[45]
FAST: fast architecture sensitive tree search on modern CPUs and GPUs. In Proceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2010, Indianapolis, Indiana, USA, June 6-10, 2010, Ahmed K. Elmagarmid and Divyakant Agrawal (Eds.). ACM, 339–350. doi:10.1145/1807167.1807206
-
[46]
Kihong Kim, Sang Kyun Cha, and Keunjoo Kwon. 2001. Optimizing Multidimen- sional Index Trees for Main Memory Access. InProceedings of the 2001 ACM SIGMOD international conference on Management of data, Santa Barbara, CA, USA, May 21-24, 2001, Sharad Mehrotra and Timos K. Sellis (Eds.). ACM, 139–150. doi:10.1145/375663.375679
-
[47]
Chi, Ani Kristo, Guillaume Leclerc, Samuel Madden, Hongzi Mao, and Vikram Nathan
Tim Kraska, Mohammad Alizadeh, Alex Beutel, Ed H. Chi, Ani Kristo, Guillaume Leclerc, Samuel Madden, Hongzi Mao, and Vikram Nathan. 2019. SageDB: A Learned Database System. In9th Biennial Conference on Innovative Data Systems Research, CIDR 2019, Asilomar, CA, USA, January 13-16, 2019, Online Proceedings. www.cidrdb.org. http://cidrdb.org/cidr2019/papers/...
2019
-
[48]
Chi, Jeffrey Dean, and Neoklis Polyzotis
Tim Kraska, Alex Beutel, Ed H. Chi, Jeffrey Dean, and Neoklis Polyzotis. 2018. The Case for Learned Index Structures. InProceedings of the 2018 International Conference on Management of Data, SIGMOD Conference 2018, Houston, TX, USA, June 10-15, 2018, Gautam Das, Christopher M. Jermaine, and Philip A. Bernstein (Eds.). ACM, 489–504. doi:10.1145/3183713.3196909
-
[49]
Cha, and Bongki Moon
Yongsik Kwon, Seonho Lee, Yehyun Nam, Joong Chae Na, Kunsoo Park, Sang K. Cha, and Bongki Moon. 2023. DB+-tree: A new variant of B+-tree for main- memory database systems.Inf. Syst.119 (2023), 102287
2023
-
[50]
Viktor Leis, Alfons Kemper, and Thomas Neumann. 2013. The adaptive radix tree: ARTful indexing for main-memory databases. In29th IEEE International Conference on Data Engineering, ICDE 2013, Brisbane, Australia, April 8-12, 2013, Christian S. Jensen, Christopher M. Jermaine, and Xiaofang Zhou (Eds.). IEEE Computer Society, 38–49. doi:10.1109/ICDE.2013.6544812
-
[51]
Leutenegger, Jeffrey Edgington, and Mario Alberto López
Scott T. Leutenegger, Jeffrey Edgington, and Mario Alberto López. 1997. STR: A Simple and Efficient Algorithm for R-Tree Packing. InProceedings of the Thir- teenth International Conference on Data Engineering, April 7-11, 1997, Birmingham, UK, W. A. Gray and Per-Åke Larson (Eds.). IEEE Computer Society, 497–506. doi:10.1109/ICDE.1997.582015
-
[52]
Mingxin Li, Hancheng Wang, Haipeng Dai, Meng Li, Chengliang Chai, Rong Gu, Feng Chen, Zhiyuan Chen, Shuaituan Li, Qizhi Liu, and Guihai Chen. 2024. A Survey of Multi-Dimensional Indexes: Past and Future Trends.IEEE Trans. Knowl. Data Eng.36, 8 (2024), 3635–3655. doi:10.1109/TKDE.2024.3364183 Achilleas Michalopoulos, Dimitrios Tsitsigkos, and Nikos Mamoulis
-
[53]
Pengfei Li, Hua Lu, Qian Zheng, Long Yang, and Gang Pan. 2020. LISA: A learned index structure for spatial data. InProceedings of the 2020 ACM SIGMOD international conference on management of data. 2119–2133
2020
-
[54]
Qiyu Liu, Maocheng Li, Yuxiang Zeng, Yanyan Shen, and Lei Chen. 2025. How good are multi-dimensional learned indexes? An experimental survey.VLDB J. 34, 2 (2025), 17. doi:10.1007/S00778-024-00893-6
-
[55]
Donald Meagher. 1982. Geometric modeling using octree encoding.Computer graphics and image processing19, 2 (1982), 129–147
1982
-
[56]
Ziyang Men, Zheqi Shen, Yan Gu, and Yihan Sun. 2025. Parallel kd-tree with Batch Updates.Proc. ACM Manag. Data3, 1 (2025), 62:1–62:26. doi:10.1145/3709712
-
[57]
Mokbel, Xiaopeng Xiong, and Walid G
Mohamed F. Mokbel, Xiaopeng Xiong, and Walid G. Aref. 2004. SINA: Scalable Incremental Processing of Continuous Queries in Spatio-temporal Databases. In SIGMOD. 623–634
2004
-
[58]
Moin Hussain Moti, Panagiotis Simatis, and Dimitris Papadias. 2022. Waffle: A Workload-Aware and Query-Sensitive Framework for Disk-Based Spatial Indexing.Proc. VLDB Endow.16, 4 (2022), 670–683. doi:10.14778/3574245.3574253
-
[59]
Kyriakos Mouratidis, Marios Hadjieleftheriou, and Dimitris Papadias. 2005. Con- ceptual Partitioning: An Efficient Method for Continuous Nearest Neighbor Monitoring. InSIGMOD. 634–645
2005
-
[60]
Vikram Nathan, Jialin Ding, Mohammad Alizadeh, and Tim Kraska. 2020. Learn- ing multi-dimensional indexes. InProceedings of the 2020 ACM SIGMOD interna- tional conference on management of data. 985–1000
2020
-
[61]
Sachith Pai, Michael Mathioudakis, and Yanhao Wang. 2024. WaZI: A Learned and Workload-aware Z-Index. InProceedings 27th International Conference on Extending Database Technology, EDBT 2024, Paestum, Italy, March 25 - March 28, Letizia Tanca, Qiong Luo, Giuseppe Polese, Loredana Caruccio, Xavier Oriol, and Donatella Firmani (Eds.). OpenProceedings.org, 55...
-
[62]
Yongxin Peng, Wei Zhou, Lin Zhang, and Hongle Du. 2020. A Study of Learned KD Tree Based on Learned Index. InInternational Conference on Networking and Network Applications, NaNA 2020, Haikou City, China, December 10-13, 2020. IEEE, 355–360. doi:10.1109/NANA51271.2020.00067
-
[63]
Octavian Procopiuc, Pankaj K Agarwal, Lars Arge, and Jeffrey Scott Vitter. 2003. Bkd-tree: A dynamic scalable kd-tree. InInternational symposium on spatial and temporal databases. Springer, 46–65
2003
-
[64]
Jianzhong Qi, Guanli Liu, Christian S Jensen, and Lars Kulik. 2020. Effectively learning spatial indices.Proceedings of the VLDB Endowment13, 12 (2020), 2341– 2354
2020
-
[65]
Jianzhong Qi, Yufei Tao, Yanchuan Chang, and Rui Zhang. 2018. Theoretically Optimal and Empirically Efficient R-trees with Strong Parallelizability.Proc. VLDB Endow.11, 5 (2018), 621–634. doi:10.1145/3187009.3177738
-
[66]
Frank Ramsak, Volker Markl, Robert Fenk, Martin Zirkel, Klaus Elhardt, and Rudolf Bayer. 2000. Integrating the UB-tree into a database system kernel.. In VLDB, Vol. 2000. 263–272
2000
-
[67]
Jun Rao and Kenneth A. Ross. 2000. Making B +-Trees Cache Conscious in Main Memory. InProceedings of the 2000 ACM SIGMOD International Conference on Management of Data, May 16-18, 2000, Dallas, Texas, USA, Weidong Chen, Jeffrey F. Naughton, and Philip A. Bernstein (Eds.). ACM, 475–486
2000
-
[68]
Suprio Ray, Rolando Blanco, and Anil K. Goel. 2014. Supporting Location-Based Services in a Main-Memory Database. InIEEE MDM. 3–12
2014
-
[69]
Yeasir Rayhan and Walid G. Aref. 2023. SIMD-ified R-tree Query Processing and Optimization. InProceedings of the 31st ACM International Conference on Advances in Geographic Information Systems, SIGSPATIAL 2023, Hamburg, Ger- many, November 13-16, 2023, Matthias Renz and Mario A. Nascimento (Eds.). ACM, 37:1–37:10. doi:10.1145/3589132.3625610
-
[70]
Maximilian Reif and Thomas Neumann. 2022. A Scalable and Generic Approach to Range Joins.Proc. VLDB Endow.15, 11 (2022), 3018–3030. doi:10.14778/3551793. 3551849
-
[71]
John T. Robinson. 1981. The K-D-B-Tree: A Search Structure For Large Multidi- mensional Dynamic Indexes. InProceedings of the 1981 ACM SIGMOD Interna- tional Conference on Management of Data, Ann Arbor, Michigan, USA, April 29 - May 1, 1981, Y. Edmund Lien (Ed.). ACM Press, 10–18. doi:10.1145/582318.582321
-
[72]
2006.Foundations of multidimensional and metric data structures
Hanan Samet. 2006.Foundations of multidimensional and metric data structures. Academic Press
2006
-
[73]
Benjamin Schlegel, Rainer Gemulla, and Wolfgang Lehner. 2009. k-ary search on modern processors. InProceedings of the Fifth International Workshop on Data Management on New Hardware, DaMoN 2009, Providence, Rhode Island, USA, June 28, 2009, Peter A. Boncz and Kenneth A. Ross (Eds.). ACM, 52–60. doi:10.1145/1565694.1565705
-
[74]
Sellis, Nick Roussopoulos, and Christos Faloutsos
Timos K. Sellis, Nick Roussopoulos, and Christos Faloutsos. 1987. The R+-Tree: A Dynamic Index for Multi-Dimensional Objects. InVLDB’87, Proceedings of 13th International Conference on Very Large Data Bases, September 1-4, 1987, Brighton, England, Peter M. Stocker, William Kent, and Peter Hammersley (Eds.). Morgan Kaufmann, 507–518. http://www.vldb.org/co...
1987
-
[75]
Amirhesam Shahvarani and Hans-Arno Jacobsen. 2016. A Hybrid B+-tree as Solution for In-Memory Indexing on CPU-GPU Heterogeneous Computing Platforms. InProceedings of the 2016 International Conference on Management of Data, SIGMOD Conference 2016, San Francisco, CA, USA, June 26 - July 01, 2016, Fatma Özcan, Georgia Koutrika, and Sam Madden (Eds.). ACM, 15...
-
[76]
Maxim Shevtsov, Alexei Soupikov, and Alexander Kapustin. 2007. Highly Parallel Fast KD-tree Construction for Interactive Ray Tracing of Dynamic Scenes.Com- put. Graph. Forum26, 3 (2007), 395–404. doi:10.1111/J.1467-8659.2007.01062.X
-
[77]
Christiansen, Jan M
Darius Sidlauskas, Simonas Saltenis, Christian W. Christiansen, Jan M. Johansen, and Donatas Saulys. 2009. Trees or grids?: indexing moving objects in main memory. InSIGSPATIAL/ACM-GIS. 236–245
2009
-
[78]
Stefan Sprenger, Patrick Schäfer, and Ulf Leser. 2018. Multidimensional range queries on modern hardware. InProceedings of the 30th International Conference on Scientific and Statistical Database Management, SSDBM 2018, Bozen-Bolzano, Italy, July 09-11, 2018, Dimitris Sacharidis, Johann Gamper, and Michael H. Böhlen (Eds.). ACM, 4:1–4:12. doi:10.1145/3221...
-
[79]
Stefan Sprenger, Patrick Schäfer, and Ulf Leser. 2019. BB-Tree: A practical and efficient main-memory index structure for multidimensional workloads. In Advances in Database Technology - 22nd International Conference on Extending Database Technology, EDBT 2019, Lisbon, Portugal, March 26-29, 2019, Melanie Herschel, Helena Galhardas, Berthold Reinwald, Iri...
-
[80]
Sivaprasad Sudhir, Michael J. Cafarella, and Samuel Madden. 2021. Replicated Layout for In-Memory Database Systems.Proc. VLDB Endow.15, 4 (2021), 984–997. doi:10.14778/3503585.3503606
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.