Recognition: unknown
Assessing the Impact of Noise and Speech Enhancement on the Intelligibility of Speech Codecs
Pith reviewed 2026-05-09 15:55 UTC · model grok-4.3
The pith
Classical speech codecs maintain better intelligibility than neural codecs under noise, and speech enhancement recovers much of the loss for the latter.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
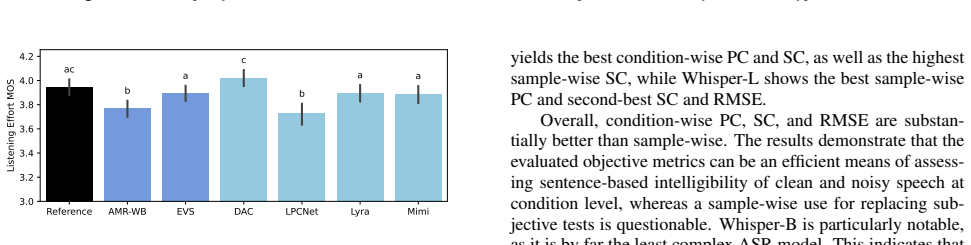
Classical codecs are more noise robust than neural codecs. Speech enhancement applied before coding produces significant gains in intelligibility and listening effort for codecs that noise otherwise impairs. Listening effort continues to expose performance differences once intelligibility scores have saturated. Objective intelligibility estimates derived from automatic speech recognition correlate strongly with averaged subjective intelligibility scores.
What carries the argument
Subjective listening tests measuring word intelligibility and effort, paired with automatic-speech-recognition-based objective prediction, applied to classical and neural codecs in clean and noisy conditions with and without pre-coding speech enhancement.
If this is right
- Neural codecs need noise-handling measures, such as prior speech enhancement, to approach classical performance in noisy environments.
- Listening effort supplies diagnostic value beyond intelligibility once scores reach ceiling levels.
- ASR-based objective measures can stand in for averaged human intelligibility ratings when comparing codecs across conditions.
- Real-world communication pipelines that include enhancement steps before neural coding can mitigate noise-related intelligibility drops.
Where Pith is reading between the lines
- Future neural codec designs could embed noise robustness internally rather than depending on separate enhancement stages.
- The observed gap suggests that deployment decisions for low-bitrate codecs should include explicit noise testing rather than relying on clean-condition benchmarks.
- Extending the same test protocol to additional languages or more varied acoustic scenes would test how stable the classical-neural robustness ordering remains.
Load-bearing premise
The chosen noise types and levels, the speech enhancement methods, the listener group, and the test materials produce results that generalize beyond the specific conditions tested.
What would settle it
A neural codec achieving intelligibility and effort scores statistically indistinguishable from classical codecs in the same noisy conditions without any speech enhancement would undermine the robustness difference.
Figures

read the original abstract
Preserving speech intelligibility is a minimum requirement for speech codecs in communication. Recently, very low-bitrate neural codecs have gained interest for replacing classical codecs, reinforcing the need to evaluate whether intelligibility is preserved in realistic scenarios. In this paper, we evaluate the intelligibility and listening effort of classical and neural speech codecs in clean and noisy conditions. Further, we assess the impact of speech enhancement (SE) before coding, simulating a possible audio processing pipeline. The results show that classical codecs are more noise robust than neural codecs. Further, SE can lead to significant intelligibility and listening effort improvements for codecs otherwise negatively affected by noise. Listening effort reveals nuanced differences when intelligibility is saturated. Lastly, objective intelligibility based on automatic speech recognition is highly correlated with subjective intelligibility scores averaged per condition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates intelligibility and listening effort for classical versus neural speech codecs in clean and noisy conditions, and examines the effect of applying speech enhancement (SE) prior to encoding. Subjective listening tests and ASR-based objective metrics are used; the central claims are that classical codecs are more noise-robust than neural codecs, that SE yields significant intelligibility and effort gains for noise-degraded codecs, that listening effort distinguishes conditions when intelligibility saturates, and that objective scores correlate highly with averaged subjective scores.
Significance. If the tested conditions prove representative, the work is significant for practical codec deployment: it identifies a concrete limitation of current neural codecs under noise and demonstrates a viable mitigation via SE front-ends. The reported correlation between objective and subjective measures also supports reduced reliance on listening tests. The empirical focus on both intelligibility and effort is directly relevant to communication-system design.
major comments (3)
- [Abstract and §3] Abstract and §3 (experimental conditions): the claim that classical codecs are more noise-robust than neural codecs is load-bearing for the headline result, yet the abstract and methods description provide no enumeration of noise types (stationary vs. non-stationary), SNR range, or number of noise realizations. Without these details the differential robustness finding cannot be assessed for generality versus artifact of the chosen test set.
- [§4] §4 (results): the statement that SE produces 'significant' intelligibility and listening-effort improvements requires reporting of exact statistical tests, effect sizes, and participant counts; these are not visible in the summary and are necessary to substantiate the claim that SE helps codecs 'otherwise negatively affected by noise.'
- [§4.2] §4.2 (objective-subjective correlation): the assertion of 'highly correlated' scores is central to the validation of ASR proxies, but no correlation coefficients, confidence intervals, or per-condition breakdowns are supplied, weakening the strength of this supporting result.
minor comments (2)
- [Abstract] Abstract: list the specific classical and neural codecs and the SE algorithms employed so readers can immediately contextualize the robustness and improvement claims.
- [§3] Figure captions and §3: ensure all listening-test materials (sentence count, speaker diversity, language) and SE matching/mismatching details are stated explicitly for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to improve clarity, statistical reporting, and transparency of the experimental conditions while preserving the integrity of the original results and claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (experimental conditions): the claim that classical codecs are more noise-robust than neural codecs is load-bearing for the headline result, yet the abstract and methods description provide no enumeration of noise types (stationary vs. non-stationary), SNR range, or number of noise realizations. Without these details the differential robustness finding cannot be assessed for generality versus artifact of the chosen test set.
Authors: We agree that explicit enumeration of noise conditions is necessary to evaluate the generality of the robustness finding. Section 3 already specifies the noise types (a mix of stationary and non-stationary noises drawn from standard corpora), the SNR range, and the number of realizations per condition. To make this information immediately accessible and to strengthen the abstract, we have added a concise summary of these parameters to the abstract and expanded the relevant paragraph in §3 with the exact counts and ranges. This revision allows readers to assess the scope of the classical-versus-neural comparison without changing any results or conclusions. revision: yes
-
Referee: [§4] §4 (results): the statement that SE produces 'significant' intelligibility and listening-effort improvements requires reporting of exact statistical tests, effect sizes, and participant counts; these are not visible in the summary and are necessary to substantiate the claim that SE helps codecs 'otherwise negatively affected by noise.'
Authors: We accept that the term 'significant' requires supporting statistical detail. The participant count (N listeners) is stated in the methods, but we have now added the precise statistical tests (repeated-measures ANOVA with post-hoc pairwise comparisons), the obtained p-values, and effect sizes (Cohen's d) directly in §4 for both intelligibility and listening-effort metrics. These additions confirm that the reported gains for noise-degraded codecs are statistically reliable and of practical magnitude, thereby substantiating the benefit of the SE front-end. revision: yes
-
Referee: [§4.2] §4.2 (objective-subjective correlation): the assertion of 'highly correlated' scores is central to the validation of ASR proxies, but no correlation coefficients, confidence intervals, or per-condition breakdowns are supplied, weakening the strength of this supporting result.
Authors: We agree that quantitative correlation measures are essential for validating the ASR-based proxies. In the revised §4.2 we now report the Pearson correlation coefficients together with 95% confidence intervals and include per-condition breakdowns. These values demonstrate the high degree of correlation between the objective scores and the averaged subjective intelligibility ratings, thereby reinforcing the utility of the ASR metric while addressing the referee's concern about the evidential strength of this result. revision: yes
Circularity Check
No circularity: purely empirical evaluation with no derivations or self-referential predictions
full rationale
This is an empirical evaluation paper that reports results from subjective intelligibility and listening effort tests on classical and neural codecs in clean/noisy conditions, with and without speech enhancement. The abstract and structure describe direct experimentation, data collection, and correlation analysis (e.g., ASR-based objective scores vs. subjective averages) without any mathematical derivations, fitted parameters renamed as predictions, self-definitional steps, or load-bearing self-citations. Claims about relative noise robustness and SE benefits rest on the experimental outcomes themselves rather than reducing to inputs by construction. No equations or uniqueness theorems are invoked that could create circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Oftentimes, proposed NSCs have been eval- uated only in clean speech conditions and without distinguish- ing between performance in clean and noisy conditions [1–6]
Introduction Neural speech codecs (NSCs) have recently gained popularity due to their capability of coding speech at lower bitrates than classical codecs. Oftentimes, proposed NSCs have been eval- uated only in clean speech conditions and without distinguish- ing between performance in clean and noisy conditions [1–6]. Moreover, the assessment of overall ...
-
[2]
No such comparison has been made for NSCs in noisy conditions
compared subjective and objective intelligibility results of NSCs in clean conditions, showing good correlations for STOI and ESTOI [26], but not for WER of ASR systems. No such comparison has been made for NSCs in noisy conditions. In addition, single-channel SE of noisy speech can negatively im- pact the WER of ASR systems [27], but we are not aware of ...
-
[3]
Assessing the Impact of Noise and Speech Enhancement on the Intelligibility of Speech Codecs
Experiments 2.1. Benchmarked Codecs Table 1 lists all codecs under test. We selected conventional speech codecs representative of current real-world communi- cation systems, including two generations of 3GPP codecs: AMR-WB[28] andEVS[29], evaluated at 6.6 kbps and 8 kbps, respectively, corresponding to their minimum or near-minimum operating bitrates. Bot...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Subjective Speech Intelligibility Evaluation Figure 1 depicts the subjective intelligibility results
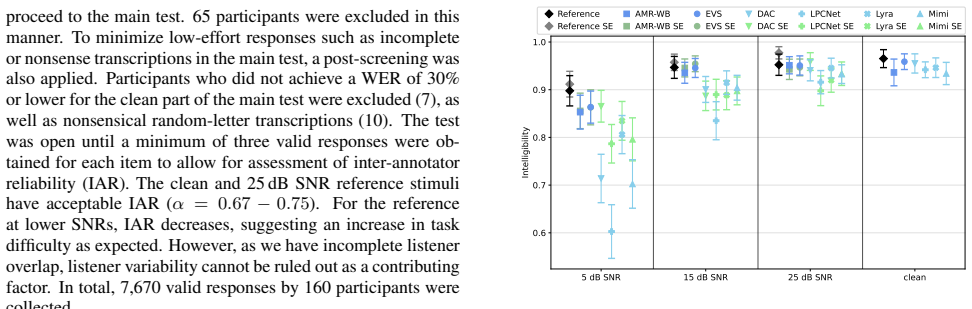
Results 3.1. Subjective Speech Intelligibility Evaluation Figure 1 depicts the subjective intelligibility results. As subjec- tive SI and WER scores showed a PC of0.99, WER is omit- ted. A linear mixed-effects model (LMM) was fitted to statis- tically analyze the effects of codec, noise type, SNR level, and SE on intelligibility. These factors were includ...
-
[5]
We assessed speech intelligibility and listening effort and demonstrated that neural codecs are less noise robust than classical codecs
Conclusion In this work, we conducted a crowdsourced evaluation of clean and noisy speech processed by multiple neural and classical speech codecs. We assessed speech intelligibility and listening effort and demonstrated that neural codecs are less noise robust than classical codecs. Additionally, we showed that SE prepro- cessing of noisy speech benefits...
-
[6]
Correctness of the plotting code was manually confirmed by the authors
Generative AI Use Disclosure Generative AI was used for cosmetic improvements of Figures 1 and 2. Correctness of the plotting code was manually confirmed by the authors
-
[7]
The authors thank Kishor Kayyar Lakshmi- narayana for his insightful feedback regarding test methodolo- gies
Acknowledgements This research was partially supported by the Free State of Bavaria in the DSGenAI project and by the Fraunhofer- Zukunftsstiftung. The authors thank Kishor Kayyar Lakshmi- narayana for his insightful feedback regarding test methodolo- gies
-
[8]
LPCNet: Improving neural speech synthesis through linear prediction,
J.-M. Valin and J. Skoglund, “LPCNet: Improving neural speech synthesis through linear prediction,” inICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP). IEEE, 2019, pp. 5891–5895
2019
-
[9]
High-fidelity audio compression with improved RVQGAN,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High-fidelity audio compression with improved RVQGAN,” in Advances in Neural Information Processing Systems, vol. 36. Curran Associates, Inc., 2023, pp. 27 980–27 993
2023
-
[10]
Moshi: A speech-text foundation model for real-time dialogue,
A. D ´efossez, L. Mazar´e, M. Orsini, A. Royer, P. P´erez, H. J´egou, E. Grave, and N. Zeghidour, “Moshi: A speech-text foundation model for real-time dialogue,” 2024
2024
-
[11]
Semanticodec: An ultra low bitrate semantic audio codec for general sound,
H. Liu, X. Xu, Y . Yuan, M. Wu, W. Wang, and M. D. Plumb- ley, “Semanticodec: An ultra low bitrate semantic audio codec for general sound,”IEEE Journal of Selected Topics in Signal Pro- cessing, vol. 18, no. 8, pp. 1448–1461, 2024
2024
-
[12]
Scaling transformers for low-bitrate high-quality speech coding,
J. D. Parker, A. Smirnov, J. Pons, C. Carr, Z. Zukowski, Z. Evans, and X. Liu, “Scaling transformers for low-bitrate high-quality speech coding,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=4YpMrGfldX
2025
-
[13]
TS3-Codec: Transformer-Based Simple Streaming Single Codec,
H. Wu, N. Kanda, S. Emre Eskimez, and J. Li, “TS3-Codec: Transformer-Based Simple Streaming Single Codec,” inInter- speech 2025, 2025, pp. 604–608
2025
-
[14]
ITU-R Recommenda- tion BS.1534-3: Method for the subjective assessment of interme- diate quality level of audio systems,
International Telecommunication Union, “ITU-R Recommenda- tion BS.1534-3: Method for the subjective assessment of interme- diate quality level of audio systems,” October 2015
2015
-
[15]
ITU-T Recommendation P.800: Methods for subjective determination of transmission quality,
——, “ITU-T Recommendation P.800: Methods for subjective determination of transmission quality,” August 1996
1996
-
[16]
ViSQOL v3: An open source production ready objec- tive speech and audio metric,
M. Chinen, F. S. Lim, J. Skoglund, N. Gureev, F. O’Gorman, and A. Hines, “ViSQOL v3: An open source production ready objec- tive speech and audio metric,” in2020 twelfth international con- ference on quality of multimedia experience (QoMEX). IEEE, 2020, pp. 1–6
2020
-
[17]
SCOREQ: Speech quality assessment with contrastive regression,
A. Ragano, J. Skoglund, and A. Hines, “SCOREQ: Speech quality assessment with contrastive regression,” inThe Thirty- eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://openreview.net/ forum?id=HDVsiUHQ1w
2024
-
[18]
Intelligibility and acceptability testing for speech technology,
A. Schmidt-Nielsen, “Intelligibility and acceptability testing for speech technology,”Applied speech technology, pp. 194–231, 1995
1995
-
[19]
Crowdsourced multilingual speech intelligibility testing,
L. Lechler and K. Wojcicki, “Crowdsourced multilingual speech intelligibility testing,” inICASSP 2024 - 2024 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 1441–1445
2024
-
[20]
Bench- marking Neural Speech Codec Intelligibility with SITool,
A. Leschanowsky, K. Kayyar Lakshminarayana, A. Rajasekhar, L. Behringer, I. Kilinc, G. Fuchs, and E. A. P. Habets, “Bench- marking Neural Speech Codec Intelligibility with SITool,” inIn- terspeech 2025, 2025, pp. 5488–5492
2025
-
[21]
R.-C. Zheng, Y . Ai, H.-P. Du, and L.-R. Dai, “Enhancing noise robustness for neural speech codecs through resource-efficient progressive quantization perturbation simulation,” 2025. [Online]. Available: https://arxiv.org/abs/2509.19025
-
[22]
Probing the Robustness Properties of Neural Speech Codecs,
W.-C. Tseng and D. Harwath, “Probing the Robustness Properties of Neural Speech Codecs,” inInterspeech 2025, 2025, pp. 5013– 5017
2025
-
[23]
A short- time objective intelligibility measure for time-frequency weighted noisy speech,
C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “A short- time objective intelligibility measure for time-frequency weighted noisy speech,” in2010 IEEE International Conference on Acous- tics, Speech and Signal Processing, 2010, pp. 4214–4217
2010
-
[24]
Low-resource audio codec (lrac): 2025 challenge description,
K. Wojcicki, Y . Z. Isik, L. Lechler, M. Yesilbursa, I. Bali ´c, W. Mack, R. Łaganowski, G. Zhang, Y . Adi, M. Kim, and S. Watanabe, “Low-resource audio codec (lrac): 2025 challenge description,” 2025. [Online]. Available: https://arxiv.org/abs/ 2510.23312
-
[25]
A comparative intelligibility study of speech enhancement algorithms,
Y . Hu and P. C. Loizou, “A comparative intelligibility study of speech enhancement algorithms,” in2007 IEEE International Conference on Acoustics, Speech and Signal Processing - ICASSP ’07, vol. 4, 2007, pp. IV–561–IV–564
2007
-
[26]
The 2nd clar- ity enhancement challenge for hearing aid speech intelligibility enhancement: Overview and outcomes,
M. A. Akeroyd, W. Bailey, J. Barker, T. J. Cox, J. F. Culling, S. Graetzer, G. Naylor, Z. Podwi ´nska, and Z. Tu, “The 2nd clar- ity enhancement challenge for hearing aid speech intelligibility enhancement: Overview and outcomes,” inICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
2023
-
[27]
The 3rd Clarity Prediction Chal- lenge: A machine learning challenge for hearing aid intelligibility prediction,
J. Barker, M. A. Akeroyd, T. J. Cox, J. F. Culling, J. Firth, S. Graetzer, and G. Naylor, “The 3rd Clarity Prediction Chal- lenge: A machine learning challenge for hearing aid intelligibility prediction,” inThe 6th Clarity Workshop on Improving Speech-in- Noise for Hearing Devices (Clarity-2025), 2025
2025
-
[28]
Evaluation of a near-end listening enhancement algorithm by combined speech intelligibility and listening effort measurements,
J. Rennies, A. Pusch, H. Schepker, and S. Doclo, “Evaluation of a near-end listening enhancement algorithm by combined speech intelligibility and listening effort measurements,”The Journal of the Acoustical Society of America, vol. 144, no. 4, pp. EL315– EL321, 2018
2018
-
[29]
ANSI/ASA S3.2-2020: Method for measuring the intelligibility of speech over communication systems,
Acoustical Society of America, “ANSI/ASA S3.2-2020: Method for measuring the intelligibility of speech over communication systems,” 2020
2020
-
[30]
Speech-in-noise testing: An introduction for audiolo- gists,
C. J. Billings, T. M. Olsen, L. Charney, B. M. Madsen, and C. E. Holmes, “Speech-in-noise testing: An introduction for audiolo- gists,”Seminars in Hearing, vol. 45, no. 1, pp. 55–82, September 2023
2023
-
[31]
Development of the hearing in noise test for the measurement of speech reception thresholds in quiet and in noise,
M. Nilsson, S. D. Soli, and J. A. Sullivan, “Development of the hearing in noise test for the measurement of speech reception thresholds in quiet and in noise,”The Journal of the Acoustical Society of America, vol. 95, no. 2, pp. 1085–1099, 1994
1994
-
[32]
Intelligibil- ity as a measure of speech perception: Current approaches, chal- lenges, and recommendations,
M. M. Baese-Berk, S. V . Levi, and K. J. Van Engen, “Intelligibil- ity as a measure of speech perception: Current approaches, chal- lenges, and recommendations,”The Journal of the Acoustical So- ciety of America, vol. 153, no. 1, p. 68, January 2023
2023
-
[33]
An algorithm for predicting the in- telligibility of speech masked by modulated noise maskers,
J. Jensen and C. H. Taal, “An algorithm for predicting the in- telligibility of speech masked by modulated noise maskers,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 24, no. 11, pp. 2009–2022, 2016
2009
-
[34]
Rethinking processing distortions: Dis- entangling the impact of speech enhancement errors on speech recognition performance,
T. Ochiai, K. Iwamoto, M. Delcroix, R. Ikeshita, H. Sato, S. Araki, and S. Katagiri, “Rethinking processing distortions: Dis- entangling the impact of speech enhancement errors on speech recognition performance,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 3589–3602, 2024
2024
-
[35]
The adaptive multi- rate wideband speech codec (AMR-WB),
B. Bessette, R. Salami, R. Lefebvre, M. Jelinek, J. Rotola-Pukkila, J. Vainio, H. Mikkola, and K. Jarvinen, “The adaptive multi- rate wideband speech codec (AMR-WB),”IEEE Transactions on Speech and Audio Processing, vol. 10, no. 8, pp. 620–636, 2002
2002
-
[36]
Standardization of the new 3GPP EVS codec,
S. Bruhn, H. Pobloth, M. Schnell, B. Grill, J. Gibbs, L. Miao, K. J ¨arvinen, L. Laaksonen, N. Harada, N. Naka, S. Ragot, S. Proust, T. Sanda, I. Varga, C. Greer, M. Jel ´ınek, M. Xie, and P. Usai, “Standardization of the new 3GPP EVS codec,” in2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 5703–5707
2015
-
[37]
Soundstream: An end-to-end neural audio codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “Soundstream: An end-to-end neural audio codec,”IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing, vol. 30, pp. 495–507, 2022
2022
-
[38]
Generative speech coding with predictive variance regularization,
W. B. Kleijn, A. Storus, M. Chinen, T. Denton, F. S. C. Lim, A. Luebs, J. Skoglund, and H. Yeh, “Generative speech coding with predictive variance regularization,” inICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 6478–6482
2021
-
[39]
Low bitrate high-quality rvqgan- based discrete speech tokenizer,
S. Shechtman and A. Dekel, “Low bitrate high-quality rvqgan- based discrete speech tokenizer,” inInterspeech 2024, 2024, pp. 4174–4178
2024
-
[40]
Dataset of British English speech recordings for psy- choacoustics and speech processing research: The clarity speech corpus,
S. Graetzer, M. A. Akeroyd, J. Barker, T. J. Cox, J. F. Culling, G. J. Naylor, E. Pancani, Z. Tu, R. Viveros-Mu ˜noz, and W. M. Whitmer, “Dataset of British English speech recordings for psy- choacoustics and speech processing research: The clarity speech corpus,”Data in Brief, vol. 41, p. 107951, Feb 2022
2022
-
[41]
Modified least-to-most greedy algorithm to search a minimum sentence set,
Suyanto, “Modified least-to-most greedy algorithm to search a minimum sentence set,” inTENCON 2006 - 2006 IEEE Region 10 Conference, 2006, pp. 1–3
2006
-
[42]
International Telecommunication Union,Recommendation G.191: Software Tools for Speech and Audio Coding Standard- ization, ITU-T, Geneva, Switzerland, November 2005
2005
-
[43]
The Diverse Environments Multi-channel Acoustic Noise Database (DEMAND): A database of multichannel environmental noise recordings,
J. Thiemann, N. Ito, and E. Vincent, “The Diverse Environments Multi-channel Acoustic Noise Database (DEMAND): A database of multichannel environmental noise recordings,” in21st Interna- tional Congress on Acoustics. Montreal, Canada: Acoustical Society of America, June 2013
2013
-
[44]
Deep- filternet2: Towards real-time speech enhancement on embedded devices for full-band audio,
H. Schr ¨oter, A. Maier, A. Escalante-B, and T. Rosenkranz, “Deep- filternet2: Towards real-time speech enhancement on embedded devices for full-band audio,” in2022 International Workshop on Acoustic Signal Enhancement (IWAENC), 2022, pp. 1–5
2022
-
[45]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inProceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Re- search. PMLR, 2023, pp. 28 492–28 518
2023
-
[46]
M. Sekoyan, N. R. Koluguri, N. Tadevosyan, P. Zelasko, T. Bartley, N. Karpov, J. Balam, and B. Ginsburg, “Canary- 1b-v2 & parakeet-tdt-0.6b-v3: Efficient and high-performance models for multilingual asr and ast,” 2025. [Online]. Available: https://arxiv.org/abs/2509.14128
-
[47]
ITU-T Recommenda- tion P.1401: Methods, metrics and procedures for statistical evalu- ation, qualification and comparison of objective quality prediction models,
International Telecommunication Union, “ITU-T Recommenda- tion P.1401: Methods, metrics and procedures for statistical evalu- ation, qualification and comparison of objective quality prediction models,” January 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.