Recognition: unknown
Task Vector Geometry Underlies Dual Modes of Task Inference in Transformers
Pith reviewed 2026-05-07 16:31 UTC · model grok-4.3
The pith
Transformers implement in-distribution task retrieval through convex combinations of task vectors and out-of-distribution adaptation through representations in a nearly orthogonal subspace.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training small transformers from scratch on latent-task sequence distributions, the authors show that two inference modes coexist within a single model. In-distribution behavior is governed by Bayesian task retrieval implemented internally through convex combinations of learned task vectors. OOD behavior arises through extrapolative task learning whose representations occupy a subspace nearly orthogonal to the task-vector subspace. The results link task-vector geometry, training distributions, and generalization behaviors.
What carries the argument
Task vectors, the task-specific directions extracted from middle-layer representations, whose convex combinations realize Bayesian retrieval for seen tasks while their orthogonal complement enables extrapolative learning for novel tasks.
If this is right
- Task-vector geometry is shaped by the training distribution.
- In-distribution inference operates via convex combinations of task vectors.
- Out-of-distribution generalization relies on representations in a nearly orthogonal subspace.
- The two modes can coexist inside one model without requiring separate components.
Where Pith is reading between the lines
- If the orthogonal-subspace mechanism holds in large models, training objectives could be designed to enlarge separation between the subspaces and thereby improve OOD performance.
- Targeted interventions that perturb only the task-vector subspace would be expected to impair in-distribution behavior while leaving OOD capabilities largely intact.
- Extending the synthetic distributions to richer task structures could test whether natural-language training data produces analogous orthogonal geometries in frontier models.
Load-bearing premise
The assumption that internal representations and inference modes found in small transformers trained on synthetic latent-task sequences transfer to the behavior of large language models trained on natural language data.
What would settle it
A measurement in a large language model in which out-of-distribution task representations lie inside the same subspace as in-distribution task vectors or in which convex combinations of task vectors fail to predict in-distribution behavior.
Figures


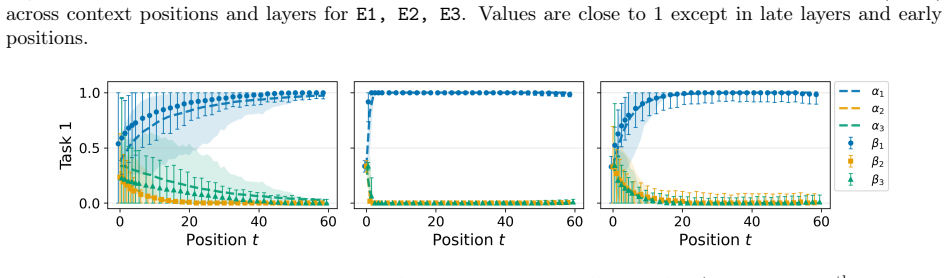

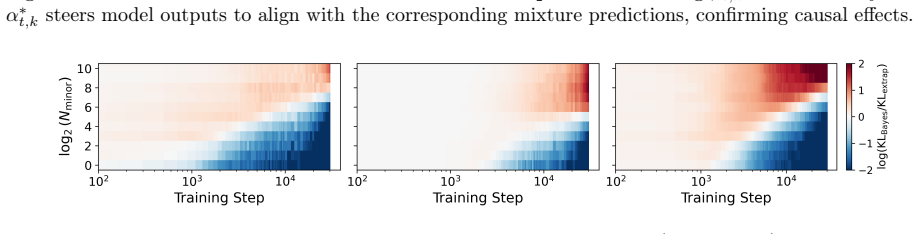









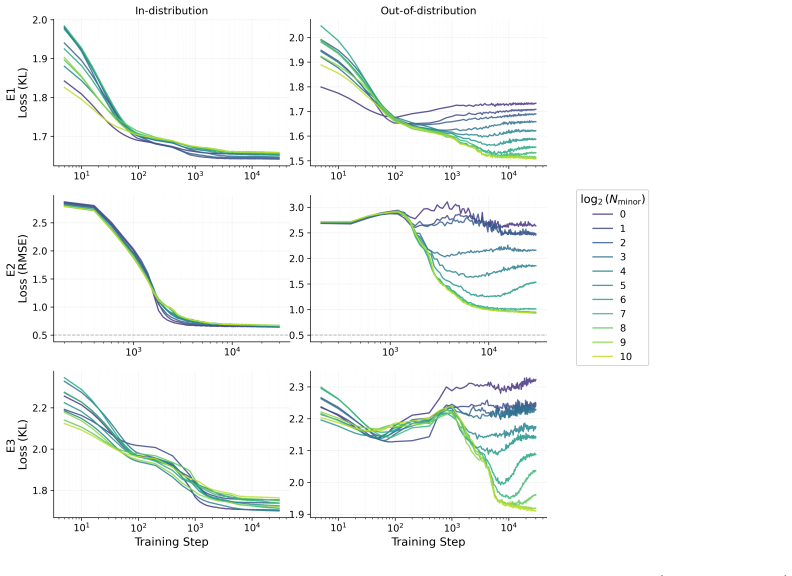






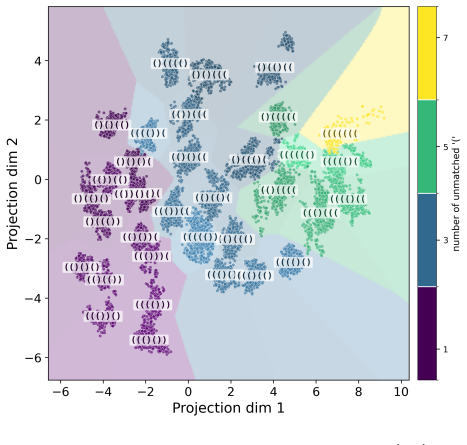
read the original abstract
Transformers are effective at inferring the latent task from context via two inference modes: recognizing a task seen during training, and adapting to a novel one. Recent interpretability studies have identified from middle-layer representations task-specific directions, or task vectors, that steer model behavior. However, a lack of rigorous foundations hinders connecting internal representations to external model behavior: existing work fails to explain how task-vector geometry is shaped by the training distribution, and what geometry enables out-of-distribution (OOD) generalization. In this paper, we study these questions in a controlled synthetic setting by training small transformers from scratch on latent-task sequence distributions, which allows a principled mathematical characterization. We show that two inference modes can coexist within a single model. In-distribution behavior is governed by Bayesian task retrieval, implemented internally through convex combinations of learned task vectors. OOD behavior, by contrast, arises through extrapolative task learning, whose representations occupy a subspace nearly orthogonal to the task-vector subspace. Taken together, our results suggest that task-vector geometry, training distributions, and generalization behaviors are closely related.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that two inference modes can coexist in a single transformer: in-distribution behavior is governed by Bayesian task retrieval implemented as convex combinations of learned task vectors, while out-of-distribution behavior arises from extrapolative task learning whose representations occupy a subspace nearly orthogonal to the task-vector subspace. These findings are obtained via controlled experiments training small transformers from scratch on synthetic latent-task sequence distributions, which enables a mathematical characterization relating task-vector geometry to the training distribution and generalization.
Significance. The synthetic controlled setting and mathematical characterization are clear strengths, allowing rigorous study of how internal geometry shapes ID vs. OOD inference without confounding factors from natural data. If the reported convex-combination and near-orthogonality properties prove robust, the work supplies a concrete geometric mechanism that could explain dual inference modes more broadly. The absence of any transfer experiments to large pretrained models or natural-language distributions, however, keeps the suggested generality speculative.
major comments (2)
- [Abstract and Conclusion] Abstract and final paragraph: the suggestion that 'task-vector geometry, training distributions, and generalization behaviors are closely related' in transformers generally is not supported by evidence, as all results are confined to small models trained on synthetic latent-task distributions; no experiments test whether the same convex/orthogonal structure appears in large language models or natural data.
- [Methods and Results (mathematical characterization)] The central geometric claims rest on task vectors extracted from the same models whose inference modes they are used to explain; it is unclear whether the vectors are defined independently of the ID/OOD measurements or whether the reported orthogonality and convex combinations are derived from first principles rather than observed post-hoc.
minor comments (2)
- [Throughout] Provide explicit equations for the claimed mathematical characterization of the convex combinations and the orthogonality metric, along with error bars or confidence intervals on the reported 'nearly orthogonal' angles.
- [Experimental Setup] Clarify the precise definition of the synthetic latent-task sequence distributions and the procedure for extracting task vectors from middle-layer representations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the value of our controlled synthetic setting and mathematical characterization. We address each major comment below and will revise the manuscript accordingly to tighten the scope of our claims while clarifying the theoretical foundations.
read point-by-point responses
-
Referee: [Abstract and Conclusion] Abstract and final paragraph: the suggestion that 'task-vector geometry, training distributions, and generalization behaviors are closely related' in transformers generally is not supported by evidence, as all results are confined to small models trained on synthetic latent-task distributions; no experiments test whether the same convex/orthogonal structure appears in large language models or natural data.
Authors: We agree that all empirical results and the mathematical characterization are confined to small transformers trained from scratch on synthetic latent-task sequence distributions. The abstract and conclusion use phrasing that could be read as implying broader applicability to transformers in general. We will revise both the abstract and the final paragraph to explicitly restrict the scope to the synthetic controlled setting, stating that the work provides a rigorous geometric mechanism in this environment rather than claiming direct evidence for large language models or natural data. No transfer experiments will be added, as they fall outside the current paper's focus on principled mathematical characterization. revision: yes
-
Referee: [Methods and Results (mathematical characterization)] The central geometric claims rest on task vectors extracted from the same models whose inference modes they are used to explain; it is unclear whether the vectors are defined independently of the ID/OOD measurements or whether the reported orthogonality and convex combinations are derived from first principles rather than observed post-hoc.
Authors: The task vectors are extracted from the trained models, but the key geometric properties are not observed post-hoc. Our mathematical characterization derives the emergence of a task-vector subspace, the convex-combination behavior for in-distribution inference, and the near-orthogonality of extrapolative representations for out-of-distribution tasks directly from the structure of the training distribution and the transformer architecture. The ID/OOD behavioral measurements serve to validate these analytically predicted properties rather than to define them. We will add a new subsection in the Methods that separates the first-principles derivation from the subsequent empirical extraction and validation steps, making this independence explicit. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper trains small transformers from scratch on synthetic latent-task sequence distributions and empirically characterizes the geometry of task vectors extracted from middle-layer representations. In-distribution behavior is shown to align with convex combinations of these vectors, while OOD behavior occupies a nearly orthogonal subspace. This is an observational analysis within a controlled generative process, not a reduction where predictions or modes are defined in terms of themselves or forced by fitting the same quantities used to measure them. No load-bearing self-citations, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation appear in the abstract or described setup. The synthetic setting is self-contained, and the dual-mode claim follows from direct measurement rather than tautological renaming or construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- task vector directions
axioms (1)
- domain assumption Middle-layer activations contain linearly extractable task-specific directions.
Reference graph
Works this paper leans on
-
[1]
Aitchison.The Statistical Analysis of Compositional Data
J. Aitchison.The Statistical Analysis of Compositional Data. Monographs on Statistics and Applied Probability. Chapman & Hall, London, 1986
1986
-
[2]
What learning algorithm is in-context learning? Investigations with linear models
Ekin Akyürek, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou. What learning algorithm is in-context learning? Investigations with linear models. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id= 0g0X4H8yN4I
2023
-
[3]
Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2023
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Con- erly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, and ...
2023
-
[4]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[5]
Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information.IEEE Transactions on information theory, 52(2):489–509, 2006
Emmanuel J Candès, Justin Romberg, and Terence Tao. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information.IEEE Transactions on information theory, 52(2):489–509, 2006
2006
-
[6]
Liam Carroll, Jesse Hoogland, Matthew Farrugia-Roberts, and Daniel Murfet. Dynamics of transient structure in in-context linear regression transformers.arXiv preprint arXiv:2501.17745, 2025
-
[7]
Compressed sensing.IEEE Transactions on information theory, 52(4): 1289–1306, 2006
David L Donoho. Compressed sensing.IEEE Transactions on information theory, 52(4): 1289–1306, 2006
2006
-
[8]
Uncertainty principles and signal recovery.SIAM Journal on Applied Mathematics, 49(3):906–931, 1989
David L Donoho and Philip B Stark. Uncertainty principles and signal recovery.SIAM Journal on Applied Mathematics, 49(3):906–931, 1989
1989
-
[9]
Duchi, Shai Shalev-Shwartz, Yoram Singer, and Tushar Chandra
John C. Duchi, Shai Shalev-Shwartz, Yoram Singer, and Tushar Chandra. Efficient projections onto the ℓ1-ball for learning in high dimensions. InProceedings of the 25th International Conference on Machine Learning (ICML), pages 272–279, 2008. doi: 10.1145/1390156.1390191
-
[10]
The evolution of statistical induction heads: In-context learning markov chains.Advances in neural information processing systems, 37:64273–64311, 2024
Ezra Edelman, Nikolaos Tsilivis, Benjamin L Edelman, Eran Malach, and Surbhi Goel. The evolution of statistical induction heads: In-context learning markov chains.Advances in neural information processing systems, 37:64273–64311, 2024. 13
2024
-
[11]
A mathematical framework for transformer circuits.Transformer Circuits Thread,
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A...
-
[12]
https://transformer-circuits.pub/2021/framework/index.html
2021
-
[13]
Toy models of superposition.Transformer Circuits Thread, 2022
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of superposition.Transformer Circuits Thread, 2022. https://transformer- circuits.pub/2022/t...
2022
-
[14]
What can transformers learn in-context? a case study of simple function classes.Advances in Neural Information Processing Systems, 35:30583–30598, 2022
Shivam Garg, Dimitris Tsipras, Percy S Liang, and Gregory Valiant. What can transformers learn in-context? a case study of simple function classes.Advances in Neural Information Processing Systems, 35:30583–30598, 2022
2022
-
[15]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, 2021
2021
-
[16]
When models manipulate manifolds: The geometry of a counting task, 2026
Wes Gurnee, Emmanuel Ameisen, Isaac Kauvar, Julius Tarng, Adam Pearce, Chris Olah, and Joshua Batson. When models manipulate manifolds: The geometry of a counting task.arXiv preprint arXiv:2601.04480, 2026
-
[17]
In-Context Learning Creates Task Vectors
Roee Hendel, Mor Geva, and Amir Globerson. In-context learning creates task vectors. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 9318–9333. Association for Computational Linguistics, 2023. doi: 10.18653/v1/2023.findings-emnlp.624. URLhttps://aclanthology.org/2023.findings-emnlp.624/
-
[18]
In-context learning state vector with inner and momentum optimiza- tion
Dongfang Li, Zhenyu Liu, Xinshuo Hu, Zetian Sun, Baotian Hu, and Min Zhang. In-context learning state vector with inner and momentum optimiza- tion. InAdvances in Neural Information Processing Systems 37 (NeurIPS 2024),
2024
-
[19]
URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/ 0ed52d7f6f641f228405d48a611e0684-Abstract-Conference.html
2024
-
[20]
Sheng Liu, Haotian Ye, Lei Xing, and James Y. Zou. In-context vectors: Making in context learning more effective and controllable through latent space steering. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 32287–32307. PMLR, 2024. URLhttps://proceedings.mlr.press/ v235...
2024
-
[21]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. URLhttps://openreview.net/forum?id= Bkg6RiCqY7
2019
-
[22]
Asymp- totic theory of in-context learning by linear attention.Proceedings of the National Academy of Sciences, 122(28):e2502599122, 2025
Yue M Lu, Mary Letey, Jacob A Zavatone-Veth, Anindita Maiti, and Cengiz Pehlevan. Asymp- totic theory of in-context learning by linear attention.Proceedings of the National Academy of Sciences, 122(28):e2502599122, 2025. 14
2025
-
[23]
Language models implement simple W ord2 V ec-style vector arithmetic
Jack Merullo, Carsten Eickhoff, and Ellie Pavlick. Language models implement simple Word2Vec- style vector arithmetic. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 5030–5047. Association for Computational Linguistics, 2024. do...
-
[24]
Distributed representations of words and phrases and their compositionality.Advances in neural information processing systems, 26, 2013
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality.Advances in neural information processing systems, 26, 2013
2013
-
[25]
Linguistic regularities in continuous space word representations
Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig. Linguistic regularities in continuous space word representations. In Lucy Vanderwende, Hal Daumé III, and Katrin Kirchhoff, editors, Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 746–751, Atlanta, Georgia,...
2013
-
[26]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads.arXiv preprint arXiv:2209.11895, 2022
work page internal anchor Pith review arXiv 2022
-
[27]
What in-context learning “learns” in-context: Disentangling task recognition and task learning
Jane Pan, Tianyu Gao, Howard Chen, and Danqi Chen. What in-context learning “learns” in-context: Disentangling task recognition and task learning. InFindings of the Association for Computational Linguistics: ACL 2023, pages 8298–8319, 2023
2023
-
[28]
Competition dynamics shape algorithmic phases of in-context learning
Core Francisco Park, Ekdeep Singh Lubana, and Hidenori Tanaka. Competition dynamics shape algorithmic phases of in-context learning. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=XgH1wfHSX8
2025
-
[29]
The linear representation hypothesis and the geometry of large language models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. InForty-first International Conference on Machine Learning, 2024
2024
-
[30]
The geometry of categorical and hierarchical concepts in large language models
Kiho Park, Yo Joong Choe, Yibo Jiang, and Victor Veitch. The geometry of categorical and hierarchical concepts in large language models. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=bVTM2QKYuA
2025
-
[31]
Approximation theory of the mlp model in neural networks.Acta numerica, 8: 143–195, 1999
Allan Pinkus. Approximation theory of the mlp model in neural networks.Acta numerica, 8: 143–195, 1999
1999
-
[32]
Qwen Team, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao L...
work page internal anchor Pith review arXiv 2025
-
[33]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019. 15
2019
-
[34]
Pretraining task diversity and the emergence of non-bayesian in-context learning for regression.Advances in neural information processing systems, 36:14228–14246, 2023
Allan Raventós, Mansheej Paul, Feng Chen, and Surya Ganguli. Pretraining task diversity and the emergence of non-bayesian in-context learning for regression.Advances in neural information processing systems, 36:14228–14246, 2023
2023
-
[35]
Transformers learn factored representations.arXiv preprint arXiv:2602.02385,
Adam Shai, Loren Amdahl-Culleton, Casper L Christensen, Henry R Bigelow, Fernando E Rosas, Alexander B Boyd, Eric A Alt, Kyle J Ray, and Paul M Riechers. Transformers learn factored representations.arXiv preprint arXiv:2602.02385, 2026
-
[36]
Transformers represent belief state geometry in their residual stream.Advances in Neural Information Processing Systems, 37:75012–75034, 2024
Adam S Shai, Sarah E Marzen, Lucas Teixeira, Alexander G Oldenziel, and Paul M Riechers. Transformers represent belief state geometry in their residual stream.Advances in Neural Information Processing Systems, 37:75012–75034, 2024
2024
-
[37]
Jiajun Song and Yiqiao Zhong. Uncovering hidden geometry in transformers via disentangling position and context.arXiv preprint arXiv:2310.04861, 2023
-
[38]
Jiajun Song, Zhuoyan Xu, and Yiqiao Zhong. Out-of-distribution generalization via composition: A lens through induction heads in transformers.Proceedings of the National Academy of Sciences, 122(6):e2417182122, 2025. doi: 10.1073/pnas.2417182122. URLhttps://www.pnas.org/doi/ abs/10.1073/pnas.2417182122
-
[39]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[40]
Daniel Freeman, Theodore R
Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Callum McDougall, Monte MacDiarmid, C. Daniel Freeman, Theodore R. Sumers, Ed- ward Rees, Joshua Batson, Adam Jermyn, Shan Carter, Chris Olah, and Tom Henighan. Scaling monose...
2024
-
[41]
Function vectors in large language models
Eric Todd, Millicent Li, Arnab Sen Sharma, Aaron Mueller, Byron C Wallace, and David Bau. Function vectors in large language models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[42]
A. W. van der Vaart.Asymptotic Statistics. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, 1998
1998
-
[43]
Cambridge Series in Statistical and Probabilistic Mathematics
Roman Vershynin.High-Dimensional Probability: An Introduction with Applications in Data Science. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, 2018
2018
-
[44]
Grokking of implicit reasoning in transformers: A mechanistic journey to the edge of generalization
Boshi Wang, Xiang Yue, Yu Su, and Huan Sun. Grokking of implicit reasoning in transformers: A mechanistic journey to the edge of generalization. InAdvances in Neural Information Processing Systems 37 (NeurIPS 2024), 2024. URL https://proceedings.neurips.cc/paper_files/ paper/2024/hash/ad217e0c7fecc71bdf48660ad6714b07-Abstract-Conference.html
2024
-
[45]
Dif- ferentiation and specialization of attention heads via the refined local learning coefficient
George Wang, Jesse Hoogland, Stan van Wingerden, Zach Furman, and Daniel Murfet. Dif- ferentiation and specialization of attention heads via the refined local learning coefficient. In International Conference on Learning Representations, 2025. 16
2025
-
[46]
Larger language models do in-context learning differently
Jerry Wei, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen, Hanxiao Liu, Da Huang, Denny Zhou, et al. Larger language models do in-context learning differently. arXiv preprint arXiv:2303.03846, 2023
-
[47]
Transformers: State-of-the-Art Natural Language Processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. Huggingface’s transformers: State-of-the-art natural language processing. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45. Asso...
-
[48]
An explanation of in-context learning as implicit bayesian inference
Sang Michael Xie, Aditi Raghunathan, Percy Liang, and Tengyu Ma. An explanation of in-context learning as implicit bayesian inference. InInternational Conference on Learning Representations, 2022
2022
-
[49]
number of independent directions along whichp(z)varies
Kayo Yin and Jacob Steinhardt. Which attention heads matter for in-context learning? InProceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of Machine Learning Research, pages 72428–72461. PMLR, 2025. URLhttps: //proceedings.mlr.press/v267/yin25e.html. Organization of the appendix.We organize our appendix into fi...
2025
-
[50]
Pool selection.With probability pminor = 0.1, draw from the minor pool; with probability 1−p minor = 0.9, draw from the major pool
-
[51]
table”→“t
Task selection.Sample a task z uniformly at random from the selected pool, then generate a sequence of lengthTfromp z. For the degenerate caseNminor = 0the minor pool is empty: the Bernoulli pool-selection step is skipped and every sequence is drawn from the major pool (equivalently, the effectivepminor collapses to0). For Nminor ≥ 1, this gives major tas...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.