Recognition: unknown
Agentic-imodels: Evolving agentic interpretability tools via autoresearch
Pith reviewed 2026-05-07 16:30 UTC · model grok-4.3
The pith
Evolving scikit-learn regressors for both accuracy and LLM simulability improves agentic data science performance by up to 73%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
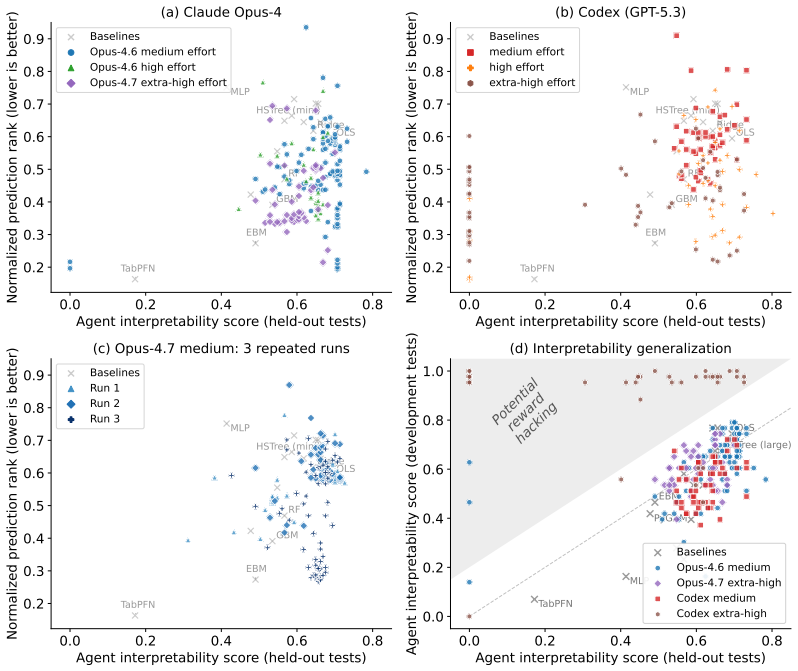
Agentic-imodels is an agentic autoresearch loop that develops a library of scikit-learn-compatible regressors for tabular data optimized for both predictive performance and a novel LLM-based interpretability metric. The metric measures a suite of LLM-graded tests that probe whether a fitted model's string representation is simulatable by an LLM. The evolved models jointly improve predictive performance and agent-facing interpretability, generalizing to new datasets and new interpretability tests. These models also improve downstream end-to-end agentic data science, increasing performance for Copilot CLI, Claude Code, and Codex on the BLADE benchmark by up to 73%.
What carries the argument
The Agentic-imodels autoresearch loop, which iteratively evolves scikit-learn regressors by jointly optimizing predictive performance and an LLM-based simulability metric that tests whether an LLM can answer questions about model behavior from its string representation alone.
If this is right
- The evolved models generalize to new datasets while retaining gains in both performance and interpretability.
- They pass additional interpretability tests beyond those used during evolution.
- Full agentic data science systems using the evolved models show concrete gains on the BLADE benchmark, up to 73% for multiple agent implementations.
- The approach produces scikit-learn-compatible tools that agents can directly incorporate into workflows.
Where Pith is reading between the lines
- The same autoresearch loop could be extended to evolve other components such as feature selectors or preprocessing steps for greater agent compatibility.
- If the simulability gains hold in practice, routine data tasks might shift to agents with less need for human review of model internals.
- Similar evolution methods might adapt to non-tabular settings like time-series or image models to support agent-driven analysis in those domains.
Load-bearing premise
The assumption that the LLM-based simulability metric accurately captures what makes a model useful to downstream agents rather than producing metric-specific artifacts or grader biases.
What would settle it
Deploying the evolved models inside complete agentic data science pipelines on entirely new datasets and observing no performance gain or even degradation relative to standard regressors in end-to-end task success.
Figures



read the original abstract
Agentic data science (ADS) systems are rapidly improving their capability to autonomously analyze, fit, and interpret data, potentially moving towards a future where agents conduct the vast majority of data-science work. However, current ADS systems use statistical tools designed to be interpretable by humans, rather than interpretable by agents. To address this, we introduce Agentic-imodels, an agentic autoresearch loop that evolves data-science tools designed to be interpretable by agents. Specifically, it develops a library of scikit-learn-compatible regressors for tabular data that are optimized for both predictive performance and a novel LLM-based interpretability metric. The metric measures a suite of LLM-graded tests that probe whether a fitted model's string representation is "simulatable" by an LLM, i.e. whether the LLM can answer questions about the model's behavior by reading its string output alone. We find that the evolved models jointly improve predictive performance and agent-facing interpretability, generalizing to new datasets and new interpretability tests. Furthermore, these evolved models improve downstream end-to-end ADS, increasing performance for Copilot CLI, Claude Code, and Codex on the BLADE benchmark by up to 73%
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Agentic-imodels, an autoresearch loop that evolves scikit-learn-compatible regressors for tabular data. These are optimized for both predictive performance and a novel LLM-based interpretability metric that uses LLM graders to test whether an LLM can answer behavioral questions about the model from its string representation alone. The authors claim the evolved models jointly improve both objectives, generalize to held-out datasets and new interpretability tests, and raise end-to-end ADS performance (Copilot CLI, Claude Code, Codex) by up to 73% on the BLADE benchmark.
Significance. If the results hold after validation, the work would be significant for developing data-science primitives explicitly designed for agent rather than human interpretability. The evolutionary autoresearch approach and the reported generalization across datasets and tests represent a concrete step toward agentic tools. The release of an evolved model library is a positive, reusable contribution.
major comments (3)
- [Abstract] Abstract: The abstract states performance and generalization results including a 73% downstream gain, but supplies no experimental details, baselines, statistical tests, dataset descriptions, or controls for LLM grader variability; without these the data cannot be assessed for post-hoc selection or robustness.
- [Method] Interpretability metric (method section): The metric is defined and graded entirely by LLMs, and downstream tasks also rely on LLMs from overlapping families (Copilot, Claude, Codex). No test is shown that the metric or gains are independent of the grader model family, leaving open the possibility that optimization exploits grader artifacts rather than genuine agent utility.
- [Experiments] Downstream experiments (results section): The BLADE gains are reported without an ablation that holds predictive performance fixed while varying only the interpretability score. This prevents attribution of the 73% lift to the interpretability component rather than incidental predictive improvement or evolution-loop effects.
minor comments (2)
- [Method] The composite objective function combining predictive loss and the LLM simulability score would benefit from an explicit equation and hyperparameter weighting details.
- [Results] Table or figure captions comparing baseline and evolved models should explicitly list the interpretability test prompts used for grading.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states performance and generalization results including a 73% downstream gain, but supplies no experimental details, baselines, statistical tests, dataset descriptions, or controls for LLM grader variability; without these the data cannot be assessed for post-hoc selection or robustness.
Authors: We agree the abstract is high-level by design. All requested details (dataset descriptions, baselines including standard scikit-learn regressors, statistical tests with p-values, and LLM grader controls via repeated evaluations with prompt variations) appear in Sections 4 and 5. We have revised the abstract to add one sentence referencing held-out generalization and robustness checks to mitigate concerns about post-hoc selection. revision: partial
-
Referee: [Method] Interpretability metric (method section): The metric is defined and graded entirely by LLMs, and downstream tasks also rely on LLMs from overlapping families (Copilot, Claude, Codex). No test is shown that the metric or gains are independent of the grader model family, leaving open the possibility that optimization exploits grader artifacts rather than genuine agent utility.
Authors: This is a substantive concern. The original experiments primarily used GPT-family graders for the metric. We will add new cross-family validation using Claude-3 and Llama-3 as alternative graders for the interpretability score; the evolved models retain their advantages in simulatability and downstream utility across families. These results and a short discussion of artifact mitigation will be inserted into the Method section. revision: yes
-
Referee: [Experiments] Downstream experiments (results section): The BLADE gains are reported without an ablation that holds predictive performance fixed while varying only the interpretability score. This prevents attribution of the 73% lift to the interpretability component rather than incidental predictive improvement or evolution-loop effects.
Authors: We accept that an explicit ablation isolating interpretability would strengthen causal claims. We will add a controlled ablation in the revised Results section: models evolved with the interpretability objective disabled are post-selected to match predictive performance of the joint-optimization models on validation data. This shows the additional downstream lift on BLADE attributable to the interpretability component beyond predictive performance or loop effects alone. revision: yes
Circularity Check
No significant circularity in empirical autoresearch loop
full rationale
The paper presents an empirical autoresearch procedure that evolves scikit-learn regressors via joint optimization of predictive loss and a separately defined LLM-graded simulability metric. Reported gains on held-out datasets, new test prompts, and downstream BLADE performance are framed as experimental results rather than mathematical derivations. No equations or claims reduce by construction to the inputs, no self-citations serve as load-bearing uniqueness results, and the metric is introduced as an explicit external evaluation rather than a tautology. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Evolutionary hyperparameters
axioms (1)
- domain assumption LLM graders can reliably and consistently assess whether a model string is simulatable by an LLM
invented entities (1)
-
Agentic-imodels library of evolved regressors
no independent evidence
Reference graph
Works this paper leans on
-
[1]
DS - Agent : Automated Data Science by Empowering Large Language Models with Case - Based Reasoning
Siyuan Guo, Cheng Deng, Ying Wen, Hechang Chen, Yi Chang, and Jun Wang. Ds-agent: Automated data science by empowering large language models with case-based reasoning.arXiv preprint arXiv:2402.17453, 2024
-
[2]
Fan Nie, Junlin Wang, Harper Hua, Federico Bianchi, Yongchan Kwon, Zhenting Qi, Owen Queen, Shang Zhu, and James Zou. Dsgym: A holistic framework for evaluating and training data science agents.arXiv preprint arXiv:2601.16344, 2026
-
[3]
Ziru Chen, Shijie Chen, Yuting Ning, Qianheng Zhang, Boshi Wang, Botao Yu, Yifei Li, Zeyi Liao, Chen Wei, Zitong Lu, et al. Scienceagentbench: Toward rigorous assessment of language agents for data-driven scientific discovery.arXiv preprint arXiv:2410.05080, 2024
-
[4]
Scientific discovery in the age of artificial intelligence.Nature, 620(7972):47–60, 2023
Hanchen Wang, Tianfan Fu, Yuanqi Du, Wenhao Gao, Kexin Huang, Ziming Liu, Payal Chandak, Shengchao Liu, Peter Van Katwyk, Andreea Deac, et al. Scientific discovery in the age of artificial intelligence.Nature, 620(7972):47–60, 2023
2023
-
[5]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024
work page internal anchor Pith review arXiv 2024
-
[6]
Samuel R Bowman, Jeeyoon Hyun, Ethan Perez, Edwin Chen, Craig Pettit, Scott Heiner, Kamil˙e Lukoši¯ut˙e, Amanda Askell, Andy Jones, Anna Chen, et al. Measuring progress on scalable oversight for large language models.arXiv preprint arXiv:2211.03540, 2022
-
[7]
Ai safety for everyone.Nature Machine Intelligence, 7(4):531–542, 2025
Balint Gyevnar and Atoosa Kasirzadeh. Ai safety for everyone.Nature Machine Intelligence, 7(4):531–542, 2025
2025
-
[8]
Cynthia Rudin. Please stop explaining black box models for high stakes decisions.arXiv preprint arXiv:1811.10154, 2018
-
[9]
James Murdoch, Chandan Singh, Karl Kumbier, Reza Abbasi-Asl, and Bin Yu
W. James Murdoch, Chandan Singh, Karl Kumbier, Reza Abbasi-Asl, and Bin Yu. Definitions, methods, and applications in interpretable machine learning.Proceedings of the National Academy of Sciences of the United States of America, 116(44):22071–22080, 2019
2019
-
[10]
Breiman, J
L. Breiman, J. H. Friedman, R. A. Olshen, and C. J. Stone.Classification and Regression Trees. Wadsworth and Brooks, Monterey, CA, 1984
1984
-
[11]
Regression shrinkage and selection via the lasso.Journal of the Royal Statistical Society
Robert Tibshirani. Regression shrinkage and selection via the lasso.Journal of the Royal Statistical Society. Series B (Methodological), pages 267–288, 1996
1996
-
[12]
imodels: a python package for fitting interpretable models.Journal of Open Source Software, 6(61):3192, 2021
Chandan Singh, Keyan Nasseri, Yan Shuo Tan, Tiffany Tang, and Bin Yu. imodels: a python package for fitting interpretable models.Journal of Open Source Software, 6(61):3192, 2021
2021
-
[13]
arXiv preprint arXiv:1909.09223 , year=
Harsha Nori, Samuel Jenkins, Paul Koch, and Rich Caruana. Interpretml: A unified framework for machine learning interpretability.arXiv preprint arXiv:1909.09223, 2019
-
[14]
Samuel G. Z. Asher, Janet Malzahn, Jessica M. Persano, Elliot J. Paschal, Andrew C. W. Myers, and Andrew B. Hall. Do claude code and codex p-hack? sycophancy and statistical analysis in large language models, February 2026. Preprint
2026
-
[15]
Rewolinski, Austin V
Zachary T. Rewolinski, Austin V . Zane, Hao Huang, Chandan Singh, Chenglong Wang, Jianfeng Gao, and Bin Yu. Sanity checks for agentic data science, 2026
2026
-
[16]
Ziming Luo, Atoosa Kasirzadeh, and Nihar B Shah. The more you automate, the less you see: Hidden pitfalls of ai scientist systems.arXiv preprint arXiv:2509.08713, 2025
-
[17]
means to an end
Venkatesh Sivaraman, Patrick V ossler, Adam Perer, Julian Hong, and Jean Feng. More than "means to an end": Supporting reasoning with transparently designed ai data science processes, 2026. 10
2026
-
[18]
Interpreting interpretability: understanding data scientists’ use of interpretability tools for machine learning
Harmanpreet Kaur, Harsha Nori, Samuel Jenkins, Rich Caruana, Hanna Wallach, and Jennifer Wort- man Vaughan. Interpreting interpretability: understanding data scientists’ use of interpretability tools for machine learning. InProceedings of the 2020 CHI conference on human factors in computing systems, pages 1–14, 2020
2020
-
[19]
Human factors in model interpretability: Industry practices, challenges, and needs.Proceedings of the ACM on Human-Computer Interaction, 4(CSCW1):1–26, 2020
Sungsoo Ray Hong, Jessica Hullman, and Enrico Bertini. Human factors in model interpretability: Industry practices, challenges, and needs.Proceedings of the ACM on Human-Computer Interaction, 4(CSCW1):1–26, 2020
2020
-
[20]
Towards A Rigorous Science of Interpretable Machine Learning
Finale Doshi-Velez and Been Kim. A roadmap for a rigorous science of interpretability.arXiv preprint arXiv:1702.08608, 2017
work page internal anchor Pith review arXiv 2017
-
[21]
The Mythos of Model Interpretability
Zachary C Lipton. The mythos of model interpretability.arXiv preprint arXiv:1606.03490, 2016
work page Pith review arXiv 2016
-
[22]
An evaluation of the human-interpretability of explanation.arXiv preprint arXiv:1902.00006, 2019
Isaac Lage, Emily Chen, Jeffrey He, Menaka Narayanan, Been Kim, Sam Gershman, and Finale Doshi- Velez. An evaluation of the human-interpretability of explanation.arXiv preprint arXiv:1902.00006, 2019
-
[23]
Ken Gu, Ruoxi Shang, Ruien Jiang, Keying Kuang, Richard-John Lin, Donghe Lyu, Yue Mao, Youran Pan, Teng Wu, Jiaqian Yu, et al. Blade: Benchmarking language model agents for data-driven science.arXiv preprint arXiv:2408.09667, 2024
-
[24]
Interpretable Machine Learning: Fundamental Principles and 10 Grand Challenges , shorttitle =
Cynthia Rudin, Chaofan Chen, Zhi Chen, Haiyang Huang, Lesia Semenova, and Chudi Zhong. Interpretable machine learning: Fundamental principles and 10 grand challenges.arXiv preprint arXiv:2103.11251, 2021
-
[25]
Ross Quinlan
J. Ross Quinlan. Induction of decision trees.Machine learning, 1(1):81–106, 1986
1986
-
[26]
Interpretable classifiers using rules and bayesian analysis: Building a better stroke prediction model
Benjamin Letham, Cynthia Rudin, Tyler H McCormick, and David Madigan. Interpretable classifiers using rules and bayesian analysis: Building a better stroke prediction model. 2015
2015
-
[27]
Generalized additive models.Statistical Science, 1(3):297–318, 1986
Trevor Hastie and Robert Tibshirani. Generalized additive models.Statistical Science, 1(3):297–318, 1986
1986
-
[28]
Accurate intelligible models with pairwise interactions
Yin Lou, Rich Caruana, Johannes Gehrke, and Giles Hooker. Accurate intelligible models with pairwise interactions. InProceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 623–631, 2013
2013
-
[29]
Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission
Rich Caruana, Yin Lou, Johannes Gehrke, Paul Koch, Marc Sturm, and Noemie Elhadad. Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission. InProceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining, pages 1721–1730, 2015
2015
-
[30]
Supersparse linear integer models for optimized medical scoring systems
Berk Ustun and Cynthia Rudin. Supersparse linear integer models for optimized medical scoring systems. Machine Learning, 102:349–391, 2016
2016
-
[31]
Augmenting interpretable models with large language models during training.Nature Communications, 14(1):7913, 2023
Chandan Singh, Armin Askari, Rich Caruana, and Jianfeng Gao. Augmenting interpretable models with large language models during training.Nature Communications, 14(1):7913, 2023
2023
-
[32]
Gamformer: In-context learning for generalized additive models.arXiv preprint arXiv:2410.04560, 2024
Andreas Mueller, Julien Siems, Harsha Nori, David Salinas, Arber Zela, Rich Caruana, and Frank Hutter. Gamformer: In-context learning for generalized additive models.arXiv preprint arXiv:2410.04560, 2024
-
[33]
Learning a decision tree algorithm with transformers.arXiv preprint arXiv:2402.03774, 2024
Yufan Zhuang, Liyuan Liu, Chandan Singh, Jingbo Shang, and Jianfeng Gao. Learning a decision tree algorithm with transformers.arXiv preprint arXiv:2402.03774, 2024
-
[34]
Ida-bench: Evaluating llms on interactive guided data analysis.arXiv preprint arXiv:2505.18223, 2025
Hanyu Li, Haoyu Liu, Tingyu Zhu, Tianyu Guo, Zeyu Zheng, Xiaotie Deng, and Michael I Jordan. Ida-bench: Evaluating llms on interactive guided data analysis.arXiv preprint arXiv:2505.18223, 2025
-
[35]
Evaluating Large Language Models in Scientific Discovery
Zhangde Song, Jieyu Lu, Yuanqi Du, Botao Yu, Thomas M Pruyn, Yue Huang, Kehan Guo, Xiuzhe Luo, Yuanhao Qu, Yi Qu, et al. Evaluating large language models in scientific discovery.arXiv preprint arXiv:2512.15567, 2025
work page internal anchor Pith review arXiv 2025
-
[36]
Autosdt: Scaling data-driven discovery tasks toward open co-scientists
Yifei Li, Hanane Nour Moussa, Ziru Chen, Shijie Chen, Botao Yu, Mingyi Xue, Benjamin Burns, Tzu-Yao Chiu, Vishal Dey, Zitong Lu, et al. Autosdt: Scaling data-driven discovery tasks toward open co-scientists. arXiv preprint arXiv:2506.08140, 2025
-
[37]
Jaehyun Nam, Jinsung Yoon, Jiefeng Chen, and Tomas Pfister. Ds-star: Data science agent via iterative planning and verification.arXiv preprint arXiv:2509.21825, 2025. 11
-
[38]
Joachim Baumann, Paul Röttger, Aleksandra Urman, Albert Wendsjö, Flor Miriam Plaza-del Arco, Johannes B Gruber, and Dirk Hovy. Large language model hacking: Quantifying the hidden risks of using llms for text annotation.arXiv preprint arXiv:2509.08825, 2025
-
[39]
Evaluating large language models as expert annotators.arXiv preprint arXiv:2508.07827, 2025
Yu-Min Tseng, Wei-Lin Chen, Chung-Chi Chen, and Hsin-Hsi Chen. Evaluating large language models as expert annotators.arXiv preprint arXiv:2508.07827, 2025
-
[40]
Ruiqi Zhong, Peter Zhang, Steve Li, Jinwoo Ahn, Dan Klein, and Jacob Steinhardt. Goal driven discovery of distributional differences via language descriptions.ArXiv, abs/2302.14233, 2023
-
[41]
what is different between these datasets?
Varun Babbar, Zhicheng Guo, and Cynthia Rudin. " what is different between these datasets?" a framework for explaining data distribution shifts.Journal of Machine Learning Research, 26(180):1–64, 2025
2025
-
[42]
Zhiying Zhu, Weixin Liang, and James Zou. Gsclip: A framework for explaining distribution shifts in natural language.arXiv preprint arXiv:2206.15007, 2022
-
[43]
MaNtLE: Model-agnostic natural language explainer.arXiv preprint arXiv:2305.12995, 2023
Rakesh R Menon, Kerem Zaman, and Shashank Srivastava. MaNtLE: Model-agnostic natural language explainer.arXiv preprint arXiv:2305.12995, 2023
-
[44]
Language models can explain neurons in language models, 2023
Steven Bills, Nick Cammarata, Dan Mossing, Henk Tillman, Leo Gao, Gabriel Goh, Ilya Sutskever, Jan Leike, Jeff Wu, and William Saunders. Language models can explain neurons in language models, 2023
2023
-
[45]
Chandan Singh, Aliyah R Hsu, Richard Antonello, Shailee Jain, Alexander G Huth, Bin Yu, and Jianfeng Gao. Explaining black box text modules in natural language with language models.arXiv preprint arXiv:2305.09863, 2023
-
[46]
Sage: An agentic explainer framework for interpreting sae features in language models
Jiaojiao Han, Wujiang Xu, Mingyu Jin, and Mengnan Du. Sage: An agentic explainer framework for interpreting sae features in language models. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 5: Industry Track), pages 483–495, 2026
2026
-
[47]
A multimodal automated interpretability agent
Tamar Rott Shaham, Sarah Schwettmann, Franklin Wang, Achyuta Rajaram, Evan Hernandez, Jacob Andreas, and Antonio Torralba. A multimodal automated interpretability agent. InForty-first International Conference on Machine Learning, 2024
2024
-
[48]
Agent laboratory: Using llm agents as research assistants
Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using llm agents as research assistants. Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5977–6043, 2025
2025
-
[49]
The virtual lab of ai agents designs new sars-cov-2 nanobodies.Nature, 646(8085):716–723, 2025
Kyle Swanson, Wesley Wu, Nash L Bulaong, John E Pak, and James Zou. The virtual lab of ai agents designs new sars-cov-2 nanobodies.Nature, 646(8085):716–723, 2025
2025
-
[50]
Large language models for automated open-domain scientific hypotheses discovery
Zonglin Yang, Xinya Du, Junxian Li, Jie Zheng, Soujanya Poria, and Erik Cambria. Large language models for automated open-domain scientific hypotheses discovery. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13545–13565, 2024
2024
-
[51]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review arXiv 2025
-
[52]
Mathematical discoveries from program search with large language models.Nature, pages 1–3, 2023
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models.Nature, pages 1–3, 2023
2023
-
[53]
Morris, Jyoti Aneja, Alexander M
Chandan Singh, John X. Morris, Jyoti Aneja, Alexander M. Rush, and Jianfeng Gao. Explaining patterns in data with language models via interpretable autoprompting, 2023
2023
-
[54]
Yiping Wang, Shao-Rong Su, Zhiyuan Zeng, Eva Xu, Liliang Ren, Xinyu Yang, Zeyi Huang, Xuehai He, Luyao Ma, Baolin Peng, et al. Thetaevolve: Test-time learning on open problems.arXiv preprint arXiv:2511.23473, 2025
-
[55]
Learning to discover at test time.arXiv preprint arXiv:2601.16175, 2026
Mert Yuksekgonul, Daniel Koceja, Xinhao Li, Federico Bianchi, Jed McCaleb, Xiaolong Wang, Jan Kautz, Yejin Choi, James Zou, Carlos Guestrin, et al. Learning to discover at test time.arXiv preprint arXiv:2601.16175, 2026
-
[56]
SkillClaw: Let Skills Evolve Collectively with Agentic Evolver
Ziyu Ma, Shidong Yang, Yuxiang Ji, Xucong Wang, Yong Wang, Yiming Hu, Tongwen Huang, and Xiangx- iang Chu. Skillclaw: Let skills evolve collectively with agentic evolver.arXiv preprint arXiv:2604.08377, 2026. 12
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
Memento-skills: Let agents design agents
Huichi Zhou, Siyuan Guo, Anjie Liu, Zhongwei Yu, Ziqin Gong, Bowen Zhao, Zhixun Chen, Menglong Zhang, Yihang Chen, Jinsong Li, et al. Memento-skills: Let agents design agents.arXiv preprint arXiv:2603.18743, 2026
-
[58]
Evoskill: Automated skill discovery for multi-agent systems.arXiv preprint arXiv:2603.02766, 2026
Salaheddin Alzubi, Noah Provenzano, Jaydon Bingham, Weiyuan Chen, and Tu Vu. Evoskill: Automated skill discovery for multi-agent systems.arXiv preprint arXiv:2603.02766, 2026
-
[59]
SKILLFOUNDRY: Building Self-Evolving Agent Skill Libraries from Heterogeneous Scientific Resources
Shuaike Shen, Wenduo Cheng, Mingqian Ma, Alistair Turcan, Martin Jinye Zhang, and Jian Ma. Skill- foundry: Building self-evolving agent skill libraries from heterogeneous scientific resources.arXiv preprint arXiv:2604.03964, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[60]
Meta-Harness: End-to-End Optimization of Model Harnesses
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. Meta-harness: End-to-end optimization of model harnesses.arXiv preprint arXiv:2603.28052, 2026
work page internal anchor Pith review arXiv 2026
-
[61]
HARBOR: Automated Harness Optimization
Biswa Sengupta and Jinhua Wang. Harbor: Automated harness optimization.arXiv preprint arXiv:2604.20938, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[62]
Dynamic cheatsheet: Test-time learning with adaptive memory
Mirac Suzgun, Mert Yuksekgonul, Federico Bianchi, Dan Jurafsky, and James Zou. Dynamic cheatsheet: Test-time learning with adaptive memory. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7080–7106, 2026
2026
-
[63]
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory
Tianxin Wei, Noveen Sachdeva, Benjamin Coleman, Zhankui He, Yuanchen Bei, Xuying Ning, Mengting Ai, Yunzhe Li, Jingrui He, Ed H Chi, et al. Evo-memory: Benchmarking llm agent test-time learning with self-evolving memory.arXiv preprint arXiv:2511.20857, 2025
work page internal anchor Pith review arXiv 2025
- [64]
-
[65]
Yufan Zhuang, Chandan Singh, Liyuan Liu, Yelong Shen, Dinghuai Zhang, Jingbo Shang, Jianfeng Gao, and Weizhu Chen. Test-time recursive thinking: Self-improvement without external feedback.arXiv preprint arXiv:2602.03094, 2026
-
[66]
Scikit-learn: Machine learning in python.the Journal of machine Learning research, 12(Oct):2825–2830, 2011
Fabian Pedregosa, Ga ë l Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, et al. Scikit-learn: Machine learning in python.the Journal of machine Learning research, 12(Oct):2825–2830, 2011
2011
-
[67]
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Prateek Mutalik Desai, David Salinas, and Frank Hutter. Tabarena: A living benchmark for machine learning on tabular data.arXiv preprint arXiv:2506.16791, 2025
-
[68]
Pmlb: a large benchmark suite for machine learning evaluation and comparison.BioData mining, 10(1):36, 2017
Randal S Olson, William La Cava, Patryk Orzechowski, Ryan J Urbanowicz, and Jason H Moore. Pmlb: a large benchmark suite for machine learning evaluation and comparison.BioData mining, 10(1):36, 2017
2017
-
[69]
Why do tree-based models still outperform deep learning on typical tabular data?Advances in neural information processing systems, 35:507–520, 2022
Léo Grinsztajn, Edouard Oyallon, and Gaël Varoquaux. Why do tree-based models still outperform deep learning on typical tabular data?Advances in neural information processing systems, 35:507–520, 2022
2022
-
[70]
Abhineet Agarwal, Yan Shuo Tan, Omer Ronen, Chandan Singh, and Bin Yu. Hierarchical shrinkage: improving the accuracy and interpretability of tree-based methods.arXiv:2202.00858, 2 2022. arXiv: 2202.00858
-
[71]
Routledge, 2017
Trevor J Hastie.Generalized additive models. Routledge, 2017
2017
-
[72]
Fast interpretable greedy- tree sums (figs).arXiv:2201.11931 [cs, stat], 1 2022
Yan Shuo Tan, Chandan Singh, Keyan Nasseri, Abhineet Agarwal, and Bin Yu. Fast interpretable greedy- tree sums (figs).arXiv:2201.11931 [cs, stat], 1 2022. arXiv: 2201.11931
-
[73]
J. H. Friedman and B. E. Popescu. Predictive learning via rule ensembles.The Annals of Applied Statistics, 2(3):916–954, 2008
2008
-
[74]
Random forests.Machine Learning, 45(1):5–32, 10 2001
Leo Breiman. Random forests.Machine Learning, 45(1):5–32, 10 2001
2001
-
[75]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
2025
-
[76]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review arXiv 2024
-
[77]
Mortgage lending in boston: interpreting hmda data.The American economic review, 86(1):25 – 53, 1996
Alicia H Munnell, Geoffrey M.B Tootell, Lynn E Browne, and James McEneaney. Mortgage lending in boston: interpreting hmda data.The American economic review, 86(1):25 – 53, 1996. 13
1996
-
[78]
Crofoot, Ian C
Margaret C. Crofoot, Ian C. Gilby, Martin C. Wikelski, and Roland W. Kays. Interaction location outweighs the competitive advantage of numerical superiority in <i>cebus capucinus</i> intergroup contests.Proceedings of the National Academy of Sciences, 105(2):577–581, 2008
2008
-
[79]
Tarek Naous, Philippe Laban, Wei Xu, and Jennifer Neville. Flipping the dialogue: Training and evaluating user language models.arXiv preprint arXiv:2510.06552, 2025
-
[80]
Shirley Wu, Evelyn Choi, Arpandeep Khatua, Zhanghan Wang, Joy He-Yueya, Tharindu Cyril Weera- sooriya, Wei Wei, Diyi Yang, Jure Leskovec, and James Zou. Humanlm: Simulating users with state alignment beats response imitation.arXiv preprint arXiv:2603.03303, 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.