Recognition: unknown
SigLoMa: Learning Open-World Quadrupedal Loco-Manipulation from Ego-Centric Vision
Pith reviewed 2026-05-07 15:37 UTC · model grok-4.3
The pith
SigLoMa lets quadrupedal robots perform open-world pick-and-place tasks from only onboard ego-centric vision at 5 Hz, matching expert human teleoperation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
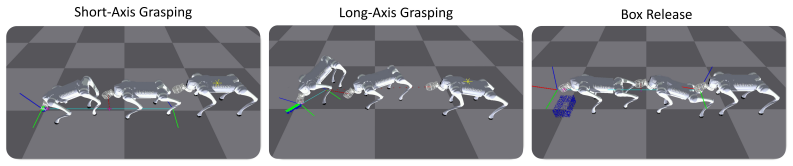
SigLoMa is a fully onboard, ego-centric vision-based pick-and-place framework for quadrupedal loco-manipulation that, relying solely on a 5 Hz open-vocabulary detector, successfully executes dynamic tasks across multiple scenarios with performance comparable to expert human teleoperation.
What carries the argument
Sigma Points, a lightweight geometric representation for exteroception that guarantees high scalability and native sim-to-real alignment, together with an ego-centric Kalman Filter that supplies robust high-rate state estimates despite slow visual updates.
If this is right
- Quadrupedal manipulation systems no longer require external motion capture or off-board computation.
- Open-vocabulary detectors can be used directly for flexible object specification in unstructured environments.
- Active sampling guided by hint poses reduces the number of samples needed to learn effective policies.
- Temporal encoding combined with simulated drift compensates for the robot's fixed visual blind spots.
Where Pith is reading between the lines
- The same geometric representation could be tested on other mobile platforms that face sim-to-real gaps during manipulation.
- Longer perception delays, such as those in underwater or space robots, might be handled by extending the Kalman filter design.
- Adding higher-level language-based task planning on top of the open-vocabulary detection would be a direct next step.
- Deployment cost could drop further if the system is validated across varying lighting and surface conditions.
Load-bearing premise
The assumption that Sigma Points and the Kalman Filter together can deliver state estimates accurate enough for precise control even with 200 ms visual latency and the robot's structural blind spots.
What would settle it
Real-world trials in which the robot completes the dynamic pick-and-place tasks at rates or success levels substantially below those achieved by expert human teleoperation.
Figures



read the original abstract
Designing an open-world quadrupedal loco-manipulation system is highly challenging. Traditional reinforcement learning frameworks utilizing exteroception often suffer from extreme sample inefficiency and massive sim-to-real gaps. Furthermore, the inherent latency of visual tracking fundamentally conflicts with the high-frequency demands of precise floating-base control. Consequently, existing systems lean heavily on expensive external motion capture and off-board computation. To eliminate these dependencies, we present SigLoMa, a fully onboard, ego-centric vision-based pick-and-place framework. At the core of SigLoMa is the introduction of Sigma Points, a lightweight geometric representation for exteroception that guarantees high scalability and native sim-to-real alignment. To bridge the frequency divide between slow perception and fast control, we design an ego-centric Kalman Filter to provide robust, high-rate state estimation. On the learning front, we alleviate sample inefficiency via an Active Sampling Curriculum guided by Hint Poses, and tackle the robot's structural visual blind spots using temporal encoding coupled with simulated random-walk drift. Real-world experiments validate that, relying solely on a 5Hz (200 ms latency) open-vocabulary detector, SigLoMa successfully executes dynamic loco-manipulation across multiple tasks, achieving performance comparable to expert human teleoperation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SigLoMa, a fully onboard, ego-centric vision-based framework for open-world quadrupedal loco-manipulation and pick-and-place. It introduces Sigma Points as a lightweight geometric exteroceptive representation claimed to ensure scalability and native sim-to-real alignment, an ego-centric Kalman Filter to bridge the gap between 5 Hz (200 ms latency) perception and high-frequency floating-base control, an Active Sampling Curriculum guided by Hint Poses to improve sample efficiency, and temporal encoding with simulated random-walk drift to handle structural visual blind spots. Real-world experiments are reported to show successful dynamic loco-manipulation across tasks with performance comparable to expert human teleoperation, relying solely on an open-vocabulary detector without external motion capture or offboard computation.
Significance. If the quantitative results and ablations hold, the work would be significant for demonstrating practical, infrastructure-free loco-manipulation on quadrupeds in open-world settings, directly addressing sample inefficiency, sim-to-real gaps, and perception-control latency conflicts that currently limit deployment of such systems.
major comments (3)
- [Ego-centric Kalman Filter] Ego-centric Kalman Filter section: the central claim that the filter enables dynamic loco-manipulation comparable to teleoperation despite 200 ms visual latency rests on unvalidated assumptions; no state-estimation error metrics, latency-ablation results, or explicit dynamics-model equations are provided to show that prediction error does not accumulate fatally in high-dynamics regimes.
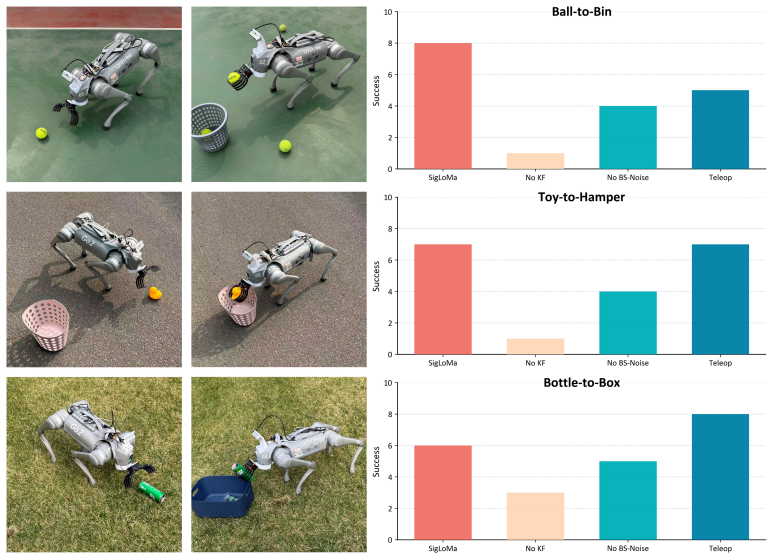
- [Real-world experiments] Real-world experiments / Results section: the assertion of performance 'comparable to expert human teleoperation' across multiple tasks is load-bearing for the paper's contribution, yet the manuscript provides no quantitative metrics (e.g., success rates, completion times, or error bars), ablation studies on Sigma Points versus baselines, or error analysis, making it impossible to verify whether the proposed mechanisms actually support the outcomes.
- [Sigma Points] Sigma Points definition and evaluation: the claims of 'guaranteed high scalability and native sim-to-real alignment' are central to eliminating external dependencies, but lack concrete comparative metrics, parameter counts, or sim-to-real transfer experiments against standard point-cloud or feature-based exteroception to substantiate the advantage.
minor comments (2)
- [Abstract] Abstract: 'multiple tasks' are referenced without enumeration; listing the specific pick-and-place scenarios would improve clarity and allow readers to assess task difficulty.
- [Methods] Notation and terminology: ensure 'Sigma Points' is formally defined with equations at first use and that all filter parameters (process/measurement noise covariances) are explicitly listed rather than left implicit.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript. We address each of the major comments point by point below. We have revised the manuscript to incorporate additional quantitative analyses and clarifications as suggested.
read point-by-point responses
-
Referee: [Ego-centric Kalman Filter] Ego-centric Kalman Filter section: the central claim that the filter enables dynamic loco-manipulation comparable to teleoperation despite 200 ms visual latency rests on unvalidated assumptions; no state-estimation error metrics, latency-ablation results, or explicit dynamics-model equations are provided to show that prediction error does not accumulate fatally in high-dynamics regimes.
Authors: We acknowledge the referee's concern regarding the validation of the ego-centric Kalman Filter. The manuscript does not currently include explicit state-estimation error metrics or latency ablations. In the revised version, we will add the dynamics model equations to the paper. Furthermore, we will provide quantitative error metrics from our experiments, including estimation errors for position, velocity, and orientation, as well as ablation studies on the filter's contribution to performance under latency. This will demonstrate that errors do not accumulate fatally in the tested high-dynamics scenarios. revision: yes
-
Referee: [Real-world experiments] Real-world experiments / Results section: the assertion of performance 'comparable to expert human teleoperation' across multiple tasks is load-bearing for the paper's contribution, yet the manuscript provides no quantitative metrics (e.g., success rates, completion times, or error bars), ablation studies on Sigma Points versus baselines, or error analysis, making it impossible to verify whether the proposed mechanisms actually support the outcomes.
Authors: We agree that the lack of quantitative metrics in the current manuscript makes it difficult to fully verify the claims. We will revise the Results section to include success rates, completion times with error bars across repeated trials for each task, and direct comparisons to expert human teleoperation performance. Additionally, we will incorporate ablation studies on the Sigma Points representation versus alternative exteroception methods, along with error analysis to highlight the role of each component in achieving the reported outcomes. revision: yes
-
Referee: [Sigma Points] Sigma Points definition and evaluation: the claims of 'guaranteed high scalability and native sim-to-real alignment' are central to eliminating external dependencies, but lack concrete comparative metrics, parameter counts, or sim-to-real transfer experiments against standard point-cloud or feature-based exteroception to substantiate the advantage.
Authors: We thank the referee for pointing out the need for more concrete evidence on Sigma Points. In the revision, we will add comparative metrics including computational costs, parameter counts for the representation, and results from sim-to-real transfer experiments comparing Sigma Points to standard point-cloud and feature-based approaches. These additions will provide quantitative support for the scalability and alignment claims. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and description introduce new constructs (Sigma Points as geometric exteroception representation, ego-centric Kalman Filter for high-rate estimation, Active Sampling Curriculum with Hint Poses, temporal encoding with simulated drift) and present real-world experimental validation of the overall system. No equations, self-citations, fitted parameters renamed as predictions, or self-definitional reductions are visible that would make any claimed result equivalent to its inputs by construction. The central claims rest on external validation rather than internal redefinition, making the derivation self-contained.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Sigma Points
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Hoeller, N
D. Hoeller, N. Rudin, D. Sako, and M. Hutter. Anymal parkour: Learning agile navigation for quadrupedal robots.Science Robotics, 9(88):eadi7566, 2024
2024
-
[2]
Zhuang, Z
Z. Zhuang, Z. Fu, J. Wang, C. Atkeson, S. Schwertfeger, C. Finn, and H. Zhao. Robot parkour learning. InConference on Robot Learning (CoRL), 2023
2023
- [3]
- [4]
-
[5]
Huang, S
R. Huang, S. Zhu, Y . Du, and H. Zhao. Moe-loco: Mixture of experts for multitask locomotion,
- [6]
-
[7]
Z. Fu, X. Cheng, and D. Pathak. Deep whole-body control: learning a unified policy for manipulation and locomotion. InConference on Robot Learning, pages 138–149. PMLR, 2023
2023
-
[8]
Y . Ma, A. Cramariuc, F. Farshidian, and M. Hutter. Learning coordinated badminton skills for legged manipulators.Science Robotics, 10(102), May 2025. ISSN 2470-9476. doi:10.1126/ scirobotics.adu3922. URLhttp://dx.doi.org/10.1126/scirobotics.adu3922
- [9]
-
[10]
W. Yu, D. Jain, A. Escontrela, A. Iscen, P. Xu, E. Coumans, S. Ha, J. Tan, and T. Zhang. Visual-locomotion: Learning to walk on complex terrains with vision. InConference on Robot Learning, pages 1691–1702. PMLR, 2022
2022
-
[11]
Agarwal, A
A. Agarwal, A. Kumar, J. Malik, and D. Pathak. Legged locomotion in challenging terrains using egocentric vision. InConference on Robot Learning, pages 403–415. PMLR, 2023
2023
-
[12]
T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter. Learning robust per- ceptive locomotion for quadrupedal robots in the wild.Science Robotics, 7(62):eabk2822, 2022
2022
-
[13]
ETH-PBL. Robust reinforcement learning-based locomotion for resource-constrained quadrupeds with exteroceptive sensing.arXiv preprint arXiv:2505.12537, 2025
- [14]
- [15]
- [16]
-
[17]
C. Liu, L. Jiang, Y . Wang, K. Yao, J. Fu, and X. Ren. Humanoid whole-body badminton via multi-stage reinforcement learning, 2025. URLhttps://arxiv.org/abs/2511.11218
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [18]
- [19]
-
[20]
S. Ross, G. J. Gordon, and J. A. Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning, 2011. URLhttps://arxiv.org/abs/1011.0686
work page Pith review arXiv 2011
-
[21]
A. Loquercio, A. Kumar, and J. Malik. Learning visual locomotion with cross-modal supervi- sion.arXiv preprint arXiv:2211.03785, 2022
-
[22]
D. Hoeller, N. Rudin, C. Choy, A. Anandkumar, and M. Hutter. Neural scene representation for locomotion on structured terrain, 2022. URLhttps://arxiv.org/abs/2206.08077
-
[23]
Gangapurwala, M
S. Gangapurwala, M. Geisert, R. Orsolino, M. Fallon, and I. Havoutis. Rloc: Terrain-aware legged locomotion using reinforcement learning and optimal control.IEEE Transactions on Robotics, 38(5):2908–2927, 2022
2022
-
[24]
H. Duan, B. Pandit, M. S. Gadde, B. J. Van Marum, J. Dao, C. Kim, and A. Fern. Learning vision-based bipedal locomotion for challenging terrain. In2024 IEEE International Confer- ence on Robotics and Automation (ICRA), pages 56–62. IEEE, 2024
2024
- [25]
- [26]
-
[27]
Fawcett et al
R. Fawcett et al. Vital: Vision-based terrain-aware locomotion for legged robots. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023
2023
- [28]
- [29]
- [30]
- [31]
-
[32]
Y . Ji, G. B. Margolis, and P. Agrawal. Dribblebot: Dynamic legged manipulation in the wild,
- [33]
- [34]
- [35]
- [36]
-
[37]
X. Liu, B. Ma, C. Qi, Y . Ding, N. Xu, Zhaxizhuoma, G. Zhang, P. Chen, K. Liu, Z. Jia, C. Guan, Y . Mo, J. Liu, F. Gao, J. Zhong, B. Zhao, and X. Li. Mlm: Learning multi-task loco-manipulation whole-body control for quadruped robot with arm, 2025. URLhttps: //arxiv.org/abs/2508.10538
-
[38]
Portela, A
T. Portela, A. Cramariuc, M. Mittal, and M. Hutter. Whole-body end-effector pose tracking,
- [39]
-
[40]
Hartley and A
R. Hartley and A. Zisserman.Multiple View Geometry in Computer Vision. Cambridge Uni- versity Press, Cambridge, UK, 2nd edition, 2003. ISBN 978-0-521-54051-3
2003
-
[41]
C. M. Bishop.Pattern recognition and machine learning. Springer, 2006
2006
- [42]
-
[43]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review arXiv 2017
- [44]
-
[45]
Calli, A
B. Calli, A. Singh, A. Walsman, S. Srinivasa, P. Abbeel, and A. M. Dollar. The ycb object and model set: Towards common benchmarks for manipulation research. In2015 international conference on advanced robotics (ICAR), pages 510–517. IEEE, 2015
2015
-
[46]
Q. Team. Qwen3.5: Accelerating productivity with native multimodal agents, February 2026. URLhttps://qwen.ai/blog?id=qwen3.5
2026
-
[47]
H. K. Cheng, S. W. Oh, B. Price, J.-Y . Lee, and A. Schwing. Putting the object back into video object segmentation, 2024. URLhttps://arxiv.org/abs/2310.12982. 11 A Hardware Setup and Task Workflow Hardware Setup.Our hardware setup utilizes the open-source 3D-printed mounting brackets from
-
[48]
Specifically, as shown in Figure 4, an overhead D435i camera is mounted with a fixed pitch angle
to firmly secure the camera and the end-effector. Specifically, as shown in Figure 4, an overhead D435i camera is mounted with a fixed pitch angle. The end-effector itself is an ultra-low-cost (<$20) servo-driven two-finger gripper. Figure 4:Hardware Setup.The overhead D435i camera is mounted at a fixed pitch alongside an ultra-low-cost servo-driven two-f...
-
[49]
,6}) independently
State Representation: The filter tracks the spatial state of each Sigma Pointsj (j∈ {0, . . . ,6}) independently. The system 12 state is defined directly in the current camera frame{C t}as a 6D vector encompassing its 3D position and relative velocity: Ctxj,t = Ctsj,t Ctvj,t ∈R 6 (4)
-
[50]
Process Model and Ego-Motion Compensation: The state transition is decoupled into point motion prediction and camera ego-motion compensa- tion. First, a linear kinematic model predicts the point’s displacement relative to the previous frame {Ct−1}over a time step∆t, where∆tdenotes the inter-frame interval: Ct−1s− j,t = Ct−1sj,t−1 + Ct−1vj,t−1∆t(5) Subsequ...
-
[51]
Measurement Model and Dynamic Update: When a visual observation is available, we extract the empirical 3D position by back-projecting the segmented image pixels, denoting this spatial observation asz j,t ∈R 3. Because the measurement space explicitly isolates the positional subspace of the full state vector, the observation model is strictly linear: zj,t ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.