Recognition: unknown
Surviving the Edge: Federated Learning under Networking and Resource Constraints
Pith reviewed 2026-05-07 12:32 UTC · model grok-4.3
The pith
Federated learning fails at 5-second latency, 50% packet loss, and 90% client dropouts due to TCP mismatches with its burst-idle pattern.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
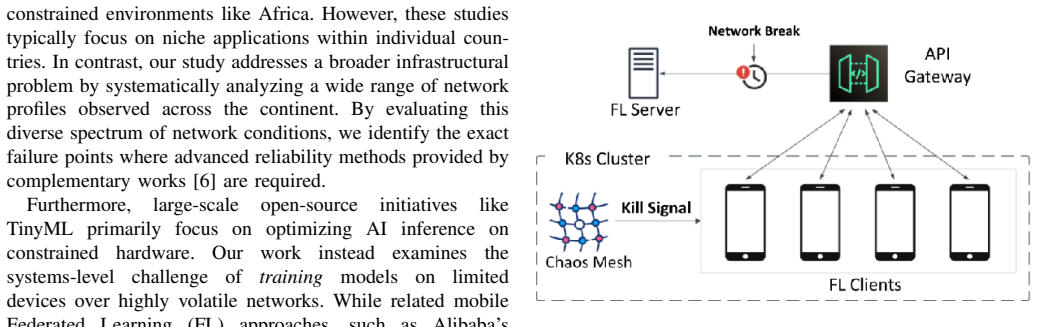
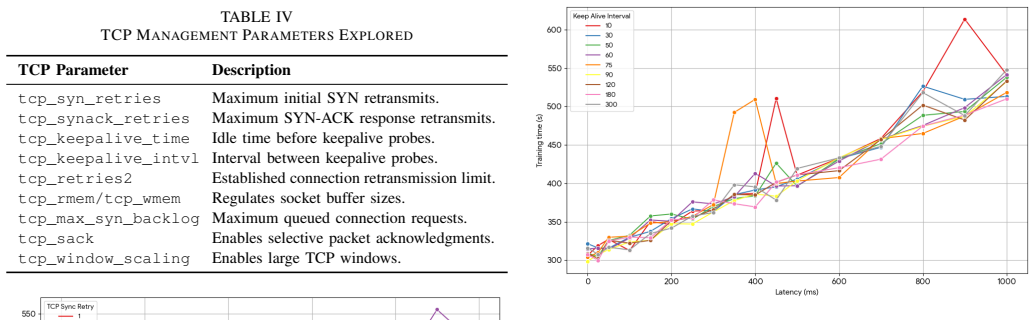
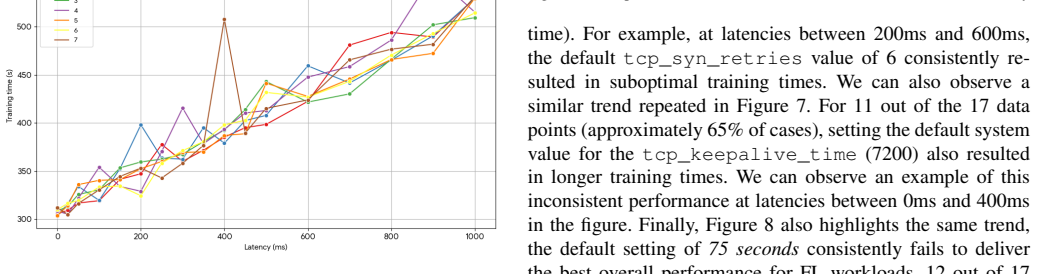
Using a reproducible testbed with chaos engineering tools to degrade networks in steps representative of resource-constrained deployments, the paper shows that FL training under the Flower framework catastrophically fails at 5-second one-way latency due to TCP handshake timeouts, above 50% packet loss due to buffer exhaustion, and with 90% client dropout rates. Systematic analysis of connection patterns during training rounds demonstrates that the periodic model update bursts violate the assumptions of default TCP configurations. Adjusting just three TCP connection management parameters significantly reduces training time under extreme latency.
What carries the argument
The mismatch between FL's burst-idle communication pattern and standard TCP connection management, exposed through analysis of connection patterns and validated by showing that targeted TCP parameter changes improve performance.
If this is right
- FL deployments can use the measured thresholds for latency, packet loss, and dropout to predict when standard setups will fail.
- Tuning a small number of TCP connection management parameters can extend the usable range of FL under high latency.
- Advanced reliability techniques become necessary only after the identified operational boundaries are crossed.
- The characterization supplies concrete guidelines for practitioners to assess edge deployments before full rollout.
Where Pith is reading between the lines
- Other distributed systems that exchange updates periodically rather than continuously may encounter similar TCP compatibility problems.
- Protocol designs that account for bursty traffic patterns could improve reliability for machine learning workloads at the edge.
- Direct measurements in live constrained networks would test whether the testbed thresholds hold outside simulated conditions.
Load-bearing premise
The testbed's simulated degradations accurately represent real-world constrained networks, and the failures arise primarily from the FL pattern violating TCP defaults rather than other unmeasured factors.
What would settle it
Repeated experiments showing that FL training succeeds at 5-second one-way latency under default TCP settings without any parameter changes, or that the three TCP adjustments produce no measurable reduction in training time.
Figures




read the original abstract
Motivated by the growing proliferation of federated learning (FL) in edge environments, we present the first systematic characterization of transport-layer breaking points in FL systems operating under conditions of highly constrained network and compute resources. Using a reproducible testbed with chaos engineering tools, we evaluate Flower under progressively degraded network conditions representative of resource-constrained deployments in Africa and similar environments. Our empirical investigation reveals a fundamental mismatch between FL's burst-idle communication pattern and standard TCP connection management. We identify precise operational boundaries: FL training catastrophically fails at 5-second one-way latency due to TCP handshake timeouts, above 50% packet loss due to buffer exhaustion, and with 90% client dropout rates. Through systematic analysis of connection patterns during training rounds, we demonstrate that FL's periodic model update bursts, separated by extended local training periods, violate the assumptions underlying default TCP configurations. To validate the significance of these findings, we show that adjusting just three TCP connection management parameters can significantly reduce training time under extreme latency, proving that transport-layer awareness is not merely beneficial but essential for FL deployment at the network edge. Our characterization methodology and findings provide practitioners with concrete thresholds for determining when standard FL deployments will fail and when advanced reliability techniques become necessary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to provide the first systematic characterization of transport-layer breaking points in federated learning (FL) systems under highly constrained network and compute resources. Using a reproducible testbed with chaos engineering tools to evaluate the Flower framework under conditions representative of edge deployments, it identifies precise failure thresholds: catastrophic failure at 5-second one-way latency due to TCP handshake timeouts, above 50% packet loss due to buffer exhaustion, and at 90% client dropout rates. The work attributes these to a fundamental mismatch between FL's periodic burst-idle communication pattern and default TCP connection management, demonstrates the issue via analysis of connection patterns during training rounds, and shows that tuning three TCP parameters can significantly reduce training time under extreme latency.
Significance. If the empirical findings hold after addressing methodological gaps, the work is significant for edge computing and FL deployment. It supplies concrete, actionable thresholds for when standard FL systems will fail in poor-connectivity environments and shows that modest transport-layer adjustments can extend viability, moving beyond generic advice to specific operational boundaries and a proof-of-concept fix. This could inform both FL framework design and network configuration practices for resource-constrained settings.
major comments (2)
- [Experimental Methodology / Testbed Description] The central empirical claims (precise thresholds of 5 s one-way latency, >50 % packet loss, and 90 % dropout) rest on the testbed's ability to isolate failures to the FL burst-idle pattern versus TCP defaults. The methods description provides no information on the number of independent runs, statistical procedures used to establish the boundaries, or controls for confounding variables introduced by the chaos-engineering tools themselves (e.g., whether latency injection also perturbs kernel timers or buffer behavior outside the intended variables).
- [Analysis of Connection Patterns] The attribution of observed catastrophes specifically to the mismatch between FL's burst-idle traffic and TCP assumptions requires explicit evidence that the degradation mechanisms do not independently produce the same symptoms. The systematic analysis of connection patterns during training rounds should include additional controls or ablation experiments to rule out testbed artifacts as the primary cause.
minor comments (1)
- [Abstract] The abstract states that 'adjusting just three TCP connection management parameters' yields significant improvement but does not name the parameters; adding this detail would strengthen the practical takeaway without altering the core contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important areas for improving the rigor of our experimental methodology. We address each major comment below and will incorporate the suggested changes in the revised manuscript.
read point-by-point responses
-
Referee: [Experimental Methodology / Testbed Description] The central empirical claims (precise thresholds of 5 s one-way latency, >50 % packet loss, and 90 % dropout) rest on the testbed's ability to isolate failures to the FL burst-idle pattern versus TCP defaults. The methods description provides no information on the number of independent runs, statistical procedures used to establish the boundaries, or controls for confounding variables introduced by the chaos-engineering tools themselves (e.g., whether latency injection also perturbs kernel timers or buffer behavior outside the intended variables).
Authors: We agree that the methods section requires additional detail to substantiate the isolation of failures to the FL burst-idle pattern. In the revised manuscript, we will expand the testbed description to specify the number of independent runs performed for each configuration, the statistical procedures used to establish the reported thresholds (including means and confidence intervals), and explicit controls verifying that the chaos-engineering tools affect only the intended network parameters without unintended side effects on kernel timers or buffers. revision: yes
-
Referee: [Analysis of Connection Patterns] The attribution of observed catastrophes specifically to the mismatch between FL's burst-idle traffic and TCP assumptions requires explicit evidence that the degradation mechanisms do not independently produce the same symptoms. The systematic analysis of connection patterns during training rounds should include additional controls or ablation experiments to rule out testbed artifacts as the primary cause.
Authors: We acknowledge the need for stronger evidence to confirm that the observed failures stem specifically from the FL-TCP mismatch rather than testbed artifacts. The revised version will include ablation experiments using synthetic continuous traffic patterns under identical network conditions, along with detailed TCP connection traces and state analysis during training rounds, to demonstrate that the catastrophic thresholds are unique to the burst-idle communication pattern. revision: yes
Circularity Check
Purely empirical testbed study with no derivation chain
full rationale
The paper conducts a reproducible chaos-engineering evaluation of Flower under controlled latency, loss, and dropout conditions. All reported thresholds (5 s one-way latency, 50 % packet loss, 90 % client dropout) and the claimed mismatch with TCP are presented as direct experimental observations rather than outputs of any fitted model, equation, or self-referential derivation. No mathematical steps, parameter estimation, or uniqueness theorems are invoked that could reduce to the input data by construction. The work therefore contains no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The progressive network degradations produced by the chaos-engineering testbed are representative of real resource-constrained deployments.
- ad hoc to paper Observed training failures are caused by the mismatch between FL burst-idle traffic and default TCP connection management.
Reference graph
Works this paper leans on
-
[1]
The importance of resource awareness in artificial intelligence for healthcare,
Z. Jia, J. Chen, X. Xu, J. Kheir, J. Hu, H. Xiao, S. Peng, X. S. Hu, D. Chen, and Y . Shi, “The importance of resource awareness in artificial intelligence for healthcare,”Nature Machine Intelligence, vol. 5, no. 7, pp. 687–698, 2023
2023
-
[2]
https://cipesa.org/wp-content/files/reports/SIFA23 report.pdf,
CIPESA, “https://cipesa.org/wp-content/files/reports/SIFA23 report.pdf,” accessed: 2026-02-18. [Online]. Available: https: //cipesa.org/wp-content/files/reports/SIFA23 Report.pdf
2026
-
[3]
Energy status in africa: Challenges, progress and sustainable pathways,
M. Agoundedemba, C. K. Kim, and H.-G. Kim, “Energy status in africa: Challenges, progress and sustainable pathways,”Energies, vol. 16, no. 23, 2023
2023
-
[4]
Communication-efficient learning of deep networks from decentralized data,
H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,”International Conference on Artificial Intelligence and Statistics, 2016
2016
-
[5]
Deep diving into africa’s inter-country latencies,
A. Formoso, J. Chavula, A. Phokeer, A. Sathiaseelan, and G. Tyson, “Deep diving into africa’s inter-country latencies,”IEEE International Conference on Computer Communications, pp. 2231–2239, 2018
2018
-
[6]
Towards federated learning at scale: System design,
K. Bonawitz, H. Eichner, W. Grieskamp, D. Huba, A. Ingerman, V . Ivanov, C. Kiddon, J. Kone ˇcn`y, S. Mazzocchi, B. McMahanet al., “Towards federated learning at scale: System design,” inProceedings of machine learning and systems, vol. 1, 2019, pp. 374–388
2019
-
[7]
Flower: A friendly federated learning research framework,
D. Beutel, T. Topal, A. Mathur, X. Qiu, T. Parcollet, and N. Lane, “Flower: A friendly federated learning research framework,” 07 2020
2020
-
[8]
Comparative analysis of open-source federated learning frameworks - a literature-based survey and review,
P. Riedel, L. Schick, R. V on Schwerin, M. Reichert, D. Schaudt, and A. Hafner, “Comparative analysis of open-source federated learning frameworks - a literature-based survey and review,”International Jour- nal of Machine Learning and Cybernetics, Jun. 2024
2024
-
[9]
A tutorial on federated learning from theory to practice: Foundations, software frameworks, exemplary use cases, and selected trends,
M. V . Luz ´on, N. Rodr ´ıguez-Barroso, A. Argente-Garrido, D. Jim ´enez- L´opez, J. M. Moyano, J. Del Ser, W. Ding, and F. Herrera, “A tutorial on federated learning from theory to practice: Foundations, software frameworks, exemplary use cases, and selected trends,”IEEE/CAA Journal of Automatica Sinica, vol. 11, no. 4, pp. 824–850, 2024
2024
-
[10]
The increased band- width fallacy: performance and usage in rural zambia,
M. Zheleva, P. Schmitt, M. Vigil, and E. Belding, “The increased band- width fallacy: performance and usage in rural zambia,” inProceedings of the 4th Annual Symposium on Computing for Development, 2013
2013
-
[11]
Africa’s data centre growth opportunity,
“Africa’s data centre growth opportunity,” https://aiimafrica.com/media/ media-centre/africas-data-centre-growth-opportunity/, accessed: 2026- 02-18
2026
-
[12]
Internet shutdowns in africa— dissent does not die in darkness: Network shutdowns and collective action in african countries,
J. Rydzak, M. Karanja, and N. Opiyo, “Internet shutdowns in africa— dissent does not die in darkness: Network shutdowns and collective action in african countries,”International Journal of Communication, vol. 14, p. 24, 2020
2020
-
[13]
Democratizing ai in africa: Federated learn- ing for low-resource edge devices,
J. Fabila, V . M. Campello, C. Mart ´ın-Isla, J. Obungoloch, K. Leo, A. Ronald, and K. Lekadir, “Democratizing ai in africa: Federated learn- ing for low-resource edge devices,” inMedical Information Computing. Springer Nature Switzerland, 2025, pp. 101–109
2025
-
[14]
Artificial intelligence (AI) deployments in Africa: benefits, challenges and policy dimensions,
A. Gwagwa, E. Kraemer-Mbula, N. Rizk, I. Rutenberg, and J. De Beer, “Artificial intelligence (AI) deployments in Africa: benefits, challenges and policy dimensions,”The African Journal of Information and Com- munication, vol. 26, pp. 1–28, 2020
2020
-
[15]
Federated learning on non-iid data silos: An experimental study,
Q. Li, Y . Diao, Q. Chen, and B. He, “Federated learning on non-iid data silos: An experimental study,”2022 IEEE 38th international conference on data engineering (ICDE), pp. 965–978, 2022
2022
-
[16]
Raspberry pi board overview,
“Raspberry pi board overview,” accessed: 2026-02-18. [Online]. Available: https://static.raspberrypi.org/files/products/Board Overview. pdf
2026
-
[17]
Layering as optimization decomposition: Questions and answers,
M. Chiang, S. H. Low, A. R. Calderbank, and J. C. Doyle, “Layering as optimization decomposition: Questions and answers,”2006 IEEE Military Communications conference, pp. 1–10, 2006
2006
-
[18]
Linux manual page - tcp(7),
“Linux manual page - tcp(7),” accessed: 2026-02-18. [Online]. Available: https://man7.org/linux/man-pages/man7/tcp.7.html
2026
-
[19]
Adaptive federated learning in resource constrained edge com- puting systems,
S. Wang, T. Tuor, T. Salonidis, K. K. Leung, C. Makaya, T. He, and K. Chan, “Adaptive federated learning in resource constrained edge com- puting systems,”IEEE Journal on Selected Areas in Communications, vol. 37, no. 6, pp. 1205–1221, 2019
2019
-
[20]
Network hexagons under attack: Secure crowdsourcing of georeferenced data,
O. Obadofin and J. Barros, “Network hexagons under attack: Secure crowdsourcing of georeferenced data,”2025 IEEE Security and Privacy Workshops (SPW), pp. 206–212, 2025
2025
-
[21]
GRPC HTTP/3 - key benefits and implementation considerations,
“GRPC HTTP/3 - key benefits and implementation considerations,” https://www.catchpoint.com/http2-vs-http3/grpc-http3, accessed: 2026- 02-18
2026
-
[22]
Gradient-based learning applied to document recognition,
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, Nov. 1998
1998
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.