Recognition: unknown
Label-Efficient School Detection from Aerial Imagery via Weakly Supervised Pretraining and Fine-Tuning
Pith reviewed 2026-05-07 03:55 UTC · model grok-4.3
The pith
A two-stage weakly supervised pipeline detects schools in aerial imagery after pretraining on auto-generated labels and fine-tuning on only 50 manual examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that first training object detectors on automatically generated bounding boxes derived from sparse location points and semantic segmentation masks, then fine-tuning those detectors on a small manually labeled set of 50 images, yields strong school detection performance in low-data regimes while sharply cutting annotation costs.
What carries the argument
The automatic labeling pipeline that converts sparse location points and semantic segmentation outputs into bounding-box labels, followed by the two-stage process of pretraining on the resulting noisy data and fine-tuning on limited clean labels.
If this is right
- Large-scale school mapping becomes feasible in regions lacking official records.
- Annotation effort for school detection drops dramatically while retaining useful accuracy.
- The same detectors can be deployed for education and connectivity initiatives worldwide.
- Performance remains promising even when only a few dozen clean labels are available.
- The framework extends to other infrastructure detection tasks that have sparse point data.
Where Pith is reading between the lines
- The approach could transfer to detecting other sparse infrastructure such as clinics or water points if similar point and segmentation data exist.
- Further gains might come from iterating the automatic labeling step or combining it with active learning to select the most useful manual examples.
- Testing the pipeline across different satellite resolutions and urban-rural mixes would clarify where the auto-label noise becomes too high.
- Releasing the auto-labeled dataset allows the community to benchmark improvements to the labeling pipeline itself.
Load-bearing premise
The bounding boxes produced by the automatic pipeline are accurate enough that pretraining on them still teaches the model useful features of schools rather than noise.
What would settle it
An experiment in which a detector fine-tuned only on the 50 manual labels matches or exceeds the performance of the full two-stage pipeline would show that the automatic pretraining step adds no value.
Figures




read the original abstract
Accurate school detection is essential for supporting education initiatives, including infrastructure planning and expanding internet connectivity to underserved areas. However, many regions around the world face challenges due to outdated, incomplete, or unavailable official records. Manual mapping efforts, while valuable, are labor-intensive and lack scalability across large geographic areas. To address this, we propose a weakly supervised framework for school detection from aerial imagery that minimizes the need for human annotations while supporting global mapping efforts. Our method is specifically designed for low-data regimes, where manual annotations are extremely scarce. We introduce an automatic labeling pipeline that leverages sparse location points and semantic segmentation to generate infrastructure masks from which we generate bounding boxes. Using these automatically labeled images, we train our detectors on a first training stage to learn a representation of what schools look like, then using a small set of manually labeled images, we fine-tune the previously trained models on this clean dataset. This two stage training pipeline enables large-scale and strong detection in low-data setting of school infrastructure with minimal supervision. Our results demonstrate strong object detection performance, particularly in the low-data regime, where the models achieve promising results using only 50 manually labeled images, significantly reducing the need for costly annotations. This framework supports education and connectivity initiatives worldwide by providing an efficient and extensible approach to mapping schools from space. All models, training code and auto-labeled data will be publicly released to foster future research and real-world impact.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a weakly supervised two-stage framework for school detection in aerial imagery. It describes an automatic labeling pipeline that converts sparse location points and semantic segmentation outputs into infrastructure masks and bounding boxes, uses these to pretrain object detectors, and then fine-tunes the models on a small set of 50 manually labeled images. The authors claim this approach achieves strong detection performance in low-data regimes while minimizing annotation costs, and they commit to publicly releasing models, code, and auto-labeled data.
Significance. If the central claim holds after validation, the work could meaningfully advance label-efficient object detection for remote-sensing applications in development contexts such as global school mapping. The public release of code, models, and data is a clear strength that supports reproducibility and downstream use. The significance remains conditional on demonstrating that the pretraining stage on automatically generated labels actually yields domain-adapted features rather than generic representations.
major comments (3)
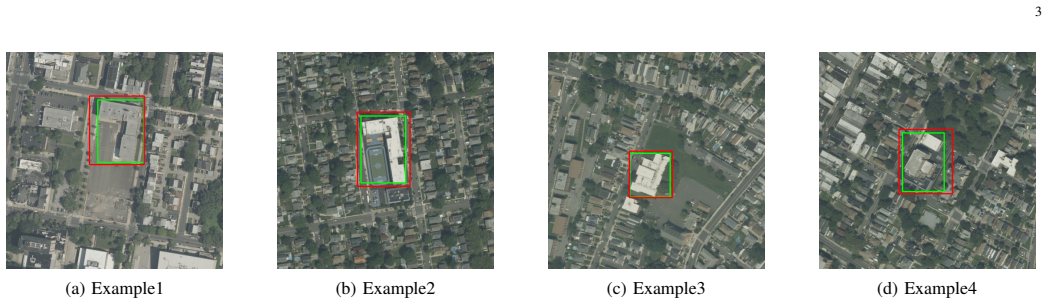
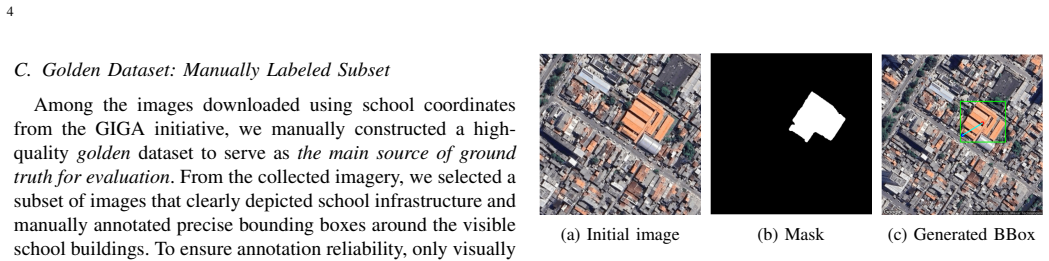
- [Section 3.2] Automatic labeling pipeline (Section 3.2): No quantitative diagnostics are supplied on the fidelity of the generated bounding boxes (e.g., IoU, precision, or recall against any manually annotated reference set). This is load-bearing for the headline claim because high false-positive rates or systematic mis-sizing in the auto-labels would render the first-stage pretraining ineffective, leaving the 50-label fine-tuning success unproven.
- [Section 4] Experimental evaluation (Section 4): The manuscript provides no ablation comparing the two-stage pipeline against a direct baseline of training solely on the 50 manual labels (or against other weakly supervised methods). Without this comparison, performance gains cannot be attributed to the proposed pretraining rather than to the fine-tuning data alone.
- [Section 4] Results reporting (Section 4 and abstract): Claims of “strong object detection performance” and “promising results” with 50 labels are not accompanied by concrete metrics (mAP, AP@0.5, etc.), baseline numbers, or error bars. This absence prevents verification that the data support the central claim.
minor comments (2)
- [Figure 1] The pipeline diagram (Figure 1) would benefit from explicit arrows and stage labels to clarify the flow from sparse points to masks to boxes to pretraining to fine-tuning.
- [Section 3] Notation for the semantic segmentation model and the object detector backbone should be introduced consistently in the method section rather than appearing first in the experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important aspects of validation and reporting that strengthen the manuscript. We have revised the paper to incorporate quantitative evaluations of the auto-labeling pipeline, ablation studies, and specific performance metrics with baselines and error bars. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Section 3.2] Automatic labeling pipeline (Section 3.2): No quantitative diagnostics are supplied on the fidelity of the generated bounding boxes (e.g., IoU, precision, or recall against any manually annotated reference set). This is load-bearing for the headline claim because high false-positive rates or systematic mis-sizing in the auto-labels would render the first-stage pretraining ineffective, leaving the 50-label fine-tuning success unproven.
Authors: We agree that quantitative assessment of the auto-generated labels is essential to confirm the pretraining stage contributes domain-adapted features. In the revised manuscript, Section 3.2 now includes an evaluation of the generated bounding boxes against a held-out manually annotated reference set. We report IoU, precision, and recall, which show the auto-labels achieve adequate fidelity for effective pretraining without introducing prohibitive noise. revision: yes
-
Referee: [Section 4] Experimental evaluation (Section 4): The manuscript provides no ablation comparing the two-stage pipeline against a direct baseline of training solely on the 50 manual labels (or against other weakly supervised methods). Without this comparison, performance gains cannot be attributed to the proposed pretraining rather than to the fine-tuning data alone.
Authors: We recognize the need for this ablation to isolate the pretraining benefit. The revised Section 4 now includes a direct baseline of training the detector from scratch on only the 50 manual labels, as well as comparisons to other weakly supervised approaches. Results show the two-stage pipeline outperforms the 50-label-only baseline, supporting attribution of gains to the weakly supervised pretraining stage. revision: yes
-
Referee: [Section 4] Results reporting (Section 4 and abstract): Claims of “strong object detection performance” and “promising results” with 50 labels are not accompanied by concrete metrics (mAP, AP@0.5, etc.), baseline numbers, or error bars. This absence prevents verification that the data support the central claim.
Authors: We apologize for the omission of specific numbers in the initial version. The revised manuscript and abstract now report concrete metrics including mAP, AP@0.5, and AP@0.75, along with baseline comparisons and error bars computed over multiple runs. These additions enable direct verification of the claimed performance in the low-data regime. revision: yes
Circularity Check
No circularity: standard empirical two-stage ML pipeline with no derivations or self-referential definitions
full rationale
The paper presents a conventional weakly-supervised object detection pipeline consisting of an automatic labeling step (sparse points + semantic segmentation masks converted to bounding boxes) followed by pretraining on the resulting noisy labels and fine-tuning on 50 clean manual annotations. No equations, parameter fittings, uniqueness theorems, or self-citations appear in the abstract or described method. The central performance claim is an empirical outcome on external imagery data rather than any quantity that reduces by construction to its own inputs. The skeptic concern about auto-label fidelity is a question of data quality and assumption validity, not a circular reduction in the derivation chain. The method is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pretraining on automatically generated noisy labels followed by fine-tuning on clean labels yields a detector whose performance generalizes to unseen aerial imagery.
- domain assumption Semantic segmentation applied to aerial imagery can reliably produce infrastructure masks from sparse point annotations.
Reference graph
Works this paper leans on
-
[1]
Suhaib Amin, Shaker El-Sappagh, Shariful Islam, et al. Towards interpretable and reliable deep learning mod- els.Frontiers in Neuroscience, 17:1293803, 2023. doi: 10.3389/fnins.2023.1293803. URL https://pubmed.ncbi. nlm.nih.gov/38077598/
-
[2]
Agricultural object detection with you only look once (yolo) algorithm: A bibliometric and systematic literature review.Computers and Electronics in Agriculture, 223: 109090, 2024
Chetan M Badgujar, Alwin Poulose, and Hao Gan. Agricultural object detection with you only look once (yolo) algorithm: A bibliometric and systematic literature review.Computers and Electronics in Agriculture, 223: 109090, 2024
2024
-
[3]
Satlaspretrain: A large- scale dataset for remote sensing image understanding,
Favyen Bastani, Piper Wolters, Ritwik Gupta, Joe Ferdi- nando, and Aniruddha Kembhavi. Satlaspretrain: A large- scale dataset for remote sensing image understanding,
- [4]
-
[5]
Ai-powered school mapping and connectivity status prediction us- ing earth observation
Kelsey Doerksen, Isabelle Tingzon, Casper Fibaek, Rochelle Schneider, and Do-Hyung Kim. Ai-powered school mapping and connectivity status prediction us- ing earth observation. InICLR 2024 Workshop on Machine Learning for Remote Sensing (ML4RS). UNICEF and ESA, 2024. URL https://github.com/unicef/ giga-global-school-mapping
2024
-
[6]
The pascal visual object classes (voc) challenge.International Journal of Computer Vision, 88(2):303–338, 2010
Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge.International Journal of Computer Vision, 88(2):303–338, 2010
2010
-
[7]
Every call is precious: Global optimization of black-box functions with unknown lips- chitz constants
Fares Fourati, Salma Kharrat, Vaneet Aggarwal, and Mohamed-Slim Alouini. Every call is precious: Global optimization of black-box functions with unknown lips- chitz constants. InInternational Conference on Artificial Intelligence and Statistics, pages 5176–5184. PMLR, 2025
2025
-
[8]
Fares Fourati, Mohamed-Slim Alouini, and Vaneet Ag- garwal. Ecpv2: Fast, efficient, and scalable global optimization of lipschitz functions.Proceedings of the AAAI Conference on Artificial Intelligence, 40(43): 36909–36918, Mar. 2026. doi: 10.1609/aaai.v40i43. 41018. URL https://ojs.aaai.org/index.php/AAAI/article/ view/41018
-
[9]
Han Fu, Xiangtao Fan, Zhenzhen Yan, and Xiaoping Du. Detection of schools in remote sensing images based on attention-guided dense network.ISPRS In- ternational Journal of Geo-Information, 10(11), 2021. ISSN 2220-9964. doi: 10.3390/ijgi10110736. URL https://www.mdpi.com/2220-9964/10/11/736
-
[10]
Giga interactive map
GIGA. Giga interactive map. https://maps.giga.global/ docs/explore-api, 2024. Accessed: 2025-07-28
2024
-
[11]
Ross Girshick. Fast r-cnn, 2015. URL https://arxiv.org/ abs/1504.08083
-
[12]
Rich feature hierarchies for accurate object detection and semantic segmentation
Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 580–587, 2014
2014
-
[13]
Google static maps api
Google Maps Platform. Google static maps api. https://developers.google.com/maps/documentation/ maps-static/, 2025. Accessed: 2025-08-01. 10
2025
-
[14]
Glenn Jocher. Yolov5. https://github.com/ultralytics/ yolov5, 2020. Consult ´e: 2025-07-27
2020
-
[15]
Ultralytics yolo11, 2024
Glenn Jocher and Jing Qiu. Ultralytics yolo11, 2024. URL https://github.com/ultralytics/ultralytics
2024
-
[16]
Ultra- lytics yolov8, 2023
Glenn Jocher, Ayush Chaurasia, and Jing Qiu. Ultra- lytics yolov8, 2023. URL https://github.com/ultralytics/ ultralytics
2023
-
[17]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Kevin Whitehead, Alexander Cardenas, Mihael Komis- sarchik, et al. Segment anything.arXiv preprint arXiv:2304.02643, 2023
work page internal anchor Pith review arXiv 2023
-
[18]
The global k-means clustering algorithm.Pattern recognition, 36(2):451–461, 2003
Aristidis Likas, Nikos Vlassis, and Jakob J Verbeek. The global k-means clustering algorithm.Pattern recognition, 36(2):451–461, 2003
2003
-
[19]
Lawrence Zitnick
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll ´ar, and C. Lawrence Zitnick. Microsoft coco: Common objects in context. InProceed- ings of the European Conference on Computer Vision (ECCV), pages 740–755. Springer, 2014
2014
-
[20]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision, pages 38–
-
[21]
Iyke Maduako, Zhuangfang Yi, Naroa Zurutuza, Shilpa Arora, Christopher Fabian, and Do-Hyung Kim. Auto- mated school location mapping at scale from satellite imagery based on deep learning.Remote Sensing, 14 (4):897, 2022. doi: 10.3390/rs14040897. URL https: //www.mdpi.com/2072-4292/14/4/897
-
[22]
lang-segment-anything: Language-guided segment anything
Luca Medeiros. lang-segment-anything: Language-guided segment anything. https: //github.com/lucamedeiros/langsegmentanything, 2023
2023
-
[23]
Vrushali Pagire, Murthy Chavali, and Ashish Kale. A comprehensive review of object detection with traditional and deep learning methods.Signal Processing, 237:110075, 2025. ISSN 0165-1684. doi: https://doi.org/10.1016/j.sigpro.2025.110075. URL https://www.sciencedirect.com/science/article/pii/ S0165168425001896
-
[24]
A comprehensive systematic review of yolo for medical object detection (2018 to 2023).IEEE Access, 12:57815–57836, 2024
Mohammed Gamal Ragab, Said Jadid Abdulkadir, Am- gad Muneer, Alawi Alqushaibi, Ebrahim Hamid Sum- iea, Rizwan Qureshi, Safwan Mahmood Al-Selwi, and Hitham Alhussian. A comprehensive systematic review of yolo for medical object detection (2018 to 2023).IEEE Access, 12:57815–57836, 2024
2018
-
[25]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Rong- hang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R ¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Doll ´ar, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:24...
work page internal anchor Pith review arXiv 2024
-
[26]
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks, 2016. URL https://arxiv. org/abs/1506.01497
-
[27]
Automatic vege- tation identification and building detection from a sin- gle nadir aerial image.Remote Sensing, 1(4):731–757,
Nicholas Shorter and Takis Kasparis. Automatic vege- tation identification and building detection from a sin- gle nadir aerial image.Remote Sensing, 1(4):731–757,
-
[28]
ISSN 2072-4292. doi: 10.3390/rs1040731. URL https://www.mdpi.com/2072-4292/1/4/731
-
[29]
Wojciech Sirko, Sergii Kashubin, Marvin Ritter, Abigail Annkah, Yasser Salah Eddine Bouchareb, Yann Dauphin, Daniel Keysers, Maxim Neumann, Moustapha Cisse, and John Quinn. Continental-scale building detection from high resolution satellite imagery.arXiv preprint arXiv:2107.12283, 2021
-
[30]
Ultralyt- ics yolo12: Attention-centric real-time object detectors,
Yunjie Tian, Qixiang Ye, and David Doermann. Ultralyt- ics yolo12: Attention-centric real-time object detectors,
-
[31]
URL https://docs.ultralytics.com/models/yolo12/
-
[32]
Large-scale school mapping using weakly supervised deep learning for universal school connectivity
Isabelle Tingzon, Utku Can Ozturk, and Ivan Dotu. Large-scale school mapping using weakly supervised deep learning for universal school connectivity. In Proceedings of the AAAI Conference on Artificial Intel- ligence, volume 39, pages 28449–28457, 2025
2025
-
[33]
Covid-19: Are children able to continue learning during school closures?,
UNICEF. Covid-19: Are children able to continue learning during school closures?,
-
[34]
UNICEF Data Brief
URL https://data.unicef.org/resources/ remote-learning-reachability-factsheet/. UNICEF Data Brief
-
[35]
Two thirds of the world’s school-age children have no internet access at home, new unicef-itu report says, 2020
UNICEF and ITU. Two thirds of the world’s school-age children have no internet access at home, new unicef-itu report says, 2020. Press Release
2020
-
[36]
Giga interactive map
UNICEF and ITU. Giga interactive map. https://maps. giga.global/map, 2024. Accessed: 2025-07-28
2024
-
[37]
With almost half of world’s population still offline, digital divide risks become ‘new face of inequality’, deputy secretary-general warns general as- sembly, April 2021
United Nations. With almost half of world’s population still offline, digital divide risks become ‘new face of inequality’, deputy secretary-general warns general as- sembly, April 2021. URL https://press.un.org/en/2021/ dsgsm1579.doc.htm. UN Press Release
2021
-
[38]
U.S. Geological Survey. National agriculture imagery program (naip): 2003–present, 2023. URL https://doi. org/10.5066/F7QN651G
-
[39]
Yolov10: Real-time end-to-end object detection.Advances in Neural Information Processing Systems, 37:107984–108011, 2024
Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, et al. Yolov10: Real-time end-to-end object detection.Advances in Neural Information Processing Systems, 37:107984–108011, 2024
2024
-
[40]
Yolo-rs: Remote sensing enhanced crop detection methods, 2025
Linlin Xiao, Zhang Tiancong, Yutong Jia, Xinyu Nie, Mengyao Wang, and Xiaohang Shao. Yolo-rs: Remote sensing enhanced crop detection methods, 2025. URL https://arxiv.org/abs/2504.11165
-
[41]
Mehrdad Yazdani, Mai H. Nguyen, Jessica Block, Daniel Crawl, Naroa Zurutuza, Dohyung Kim, Gordon Han- son, and Ilkay Altintas. Scalable detection of rural schools in africa using convolutional neural networks and satellite imagery. In2018 IEEE/ACM International Conference on Utility and Cloud Computing Compan- ion (UCC Companion), pages 1–6. IEEE, 2018. d...
-
[42]
Towards equitable 11 access to information and opportunity for all: map- ping schools with high-resolution satellite imagery and machine learning
Zhuangfang Yi, Naroa Zurutuza, Drew Bollinger, Manuel Garcia-Herranz, and Dohyung Kim. Towards equitable 11 access to information and opportunity for all: map- ping schools with high-resolution satellite imagery and machine learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 60–66, 2019
2019
-
[43]
Shiliang Zhu and Ming Miao. Scnet: A lightweight and efficient object detection network for remote sens- ing.IEEE Geoscience and Remote Sensing Letters, 21: 1–5, 2024. doi: 10.1109/LGRS.2023.3344937. URL https://doi.org/10.1109/LGRS.2023.3344937. APPENDIXA AUTOMATICHYPERPARAMETERTUNING USINGECP In this appendix, we describe the hyperparameter optimiza- ti...
-
[44]
This setup allows us to analyze how the different detectors scale when a moderate amount of labeled data becomes available
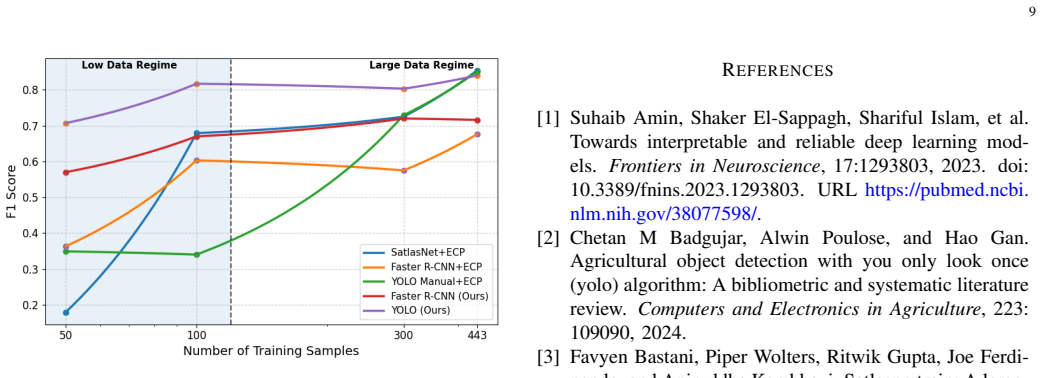
Results on small golden (300 train images):In this experimental scenario, the size of the golden training dataset to 300 images while keeping the validation and test sets unchanged. This setup allows us to analyze how the different detectors scale when a moderate amount of labeled data becomes available
-
[45]
Results on 443 train images:In the final experimental setting, we train the detectors on the full Golden dataset, which contains 443 manually labeled training images. The validation and test sets remain unchanged in order to preserve the comparability of the experiments. APPENDIXE METRICS We use the following standard metrics to evaluate object detection ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.