Recognition: unknown
Sparse Autoencoder Decomposition of Clinical Sequence Model Representations: Feature Complexity, Task Specialisation, and Mortality Prediction
Pith reviewed 2026-05-10 15:00 UTC · model grok-4.3
The pith
Sparse autoencoders decompose a clinical sequence model's representations into progressively more abstract features that improve mortality prediction in full-sequence linear probes but not in leakage-safe windows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
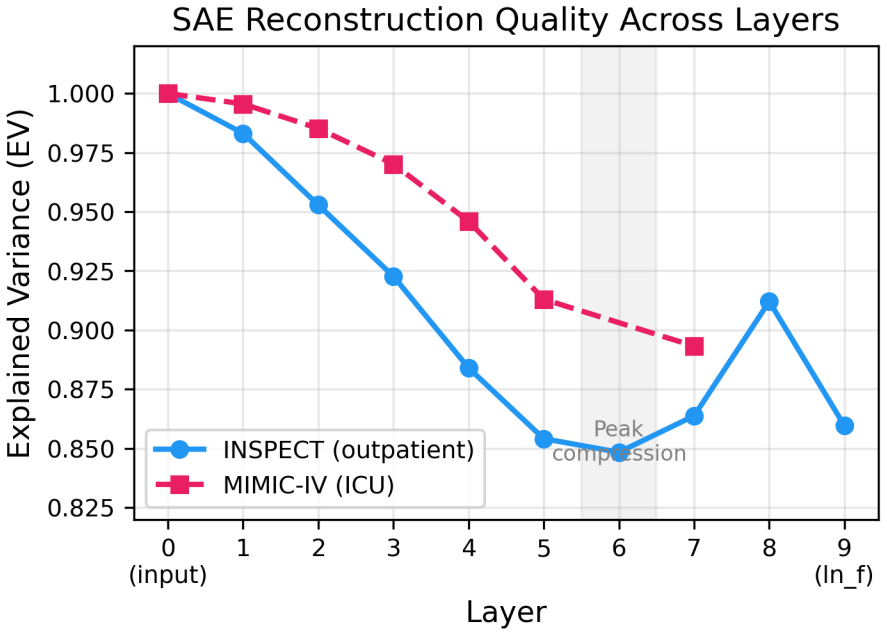
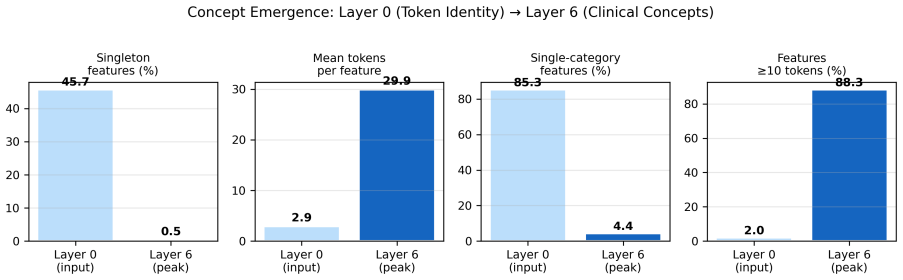
TopK SAEs applied layer-wise to FlatASCEND residual streams show that feature complexity grows with depth, shifting from 45.7 percent singleton token detectors at layer 0 to multi-category features spanning approximately 30 token types at layer 6. Full-sequence linear probes then demonstrate that these decomposed features raise AUC for mortality prediction above the dense baseline while lowering performance on length-of-stay regression; the advantage reverses or vanishes when probes are restricted to leakage-safe windows, with dense representations achieving higher AUCs on eICU-CRD 48-hour mortality, MIMIC-IV, and INSPECT 1-year and 3-year horizons.
What carries the argument
TopK sparse autoencoder decomposition of transformer residual stream activations, which extracts sparse feature vectors at each layer and enables layer-wise comparison of abstraction and task-specific probe performance.
If this is right
- SAE features become less token-specific and more abstract across transformer depth.
- Decomposed features raise mortality prediction accuracy relative to dense representations only when full sequences are available for probing.
- Dense representations match or exceed SAE performance once prediction windows are restricted to avoid leakage.
- Delta-mode intervention reduces SAE perturbation noise by a factor of 86 while still producing larger effects than random controls in some conditions.
- Individual SAE features reproduce at 21 percent across random seeds and should be treated as illustrative.
Where Pith is reading between the lines
- The observed probe-level task split between discrete and continuous targets may reflect how mortality depends on presence of sparse events while length of stay depends on aggregate magnitude.
- In production clinical systems the overhead of maintaining separate SAE dictionaries may be unnecessary if dense representations already suffice under realistic constraints.
- Low cross-seed reproducibility suggests that any downstream use of individual features requires ensemble or stability checks before claiming clinical meaning.
Load-bearing premise
That the TopK SAE decomposition extracts the model's learned clinical concepts without systematic artifacts and that full-sequence probe results are not confounded by information leakage.
What would settle it
Finding that SAE features produce lower AUC than dense representations for mortality in additional held-out leakage-safe windows or that manually inspected feature activations fail to correspond to recognizable clinical patterns.
Figures


read the original abstract
Sparse autoencoders (SAEs) have been applied to large language models and protein language models, but not systematically to electronic health record (EHR) foundation models. We train TopK SAEs on FlatASCEND, a 14.5-million-parameter autoregressive clinical sequence model, at all 10 residual stream extraction points on INSPECT (outpatient) and MIMIC-IV (ICU). SAE decomposition reveals progressive abstraction across transformer depth: layer-0 features are near-perfect token detectors (45.7% singleton), while layer-6 features span approximately 30 token types across multiple clinical categories (0.5% singleton). Under full-sequence simple linear probes, SAE features outperform dense representations for discrete event prediction (mortality) while dense representations outperform for continuous magnitude prediction (length of stay) - a probe-level representational phenomenon that does not extend to clinically relevant leakage-safe windows, where dense representations match or exceed SAE features across all tested settings (eICU-CRD 48-hour AUC: SAE 0.871 versus dense 0.880; base model zero-shot, SAE dictionaries trained on eICU activations; MIMIC-IV: 0.836 versus 0.914; INSPECT 1-year/3-year: 0.697 versus 0.800). A delta-mode intervention method reduces SAE perturbation noise by 86x, enabling cleaner feature-level experiments, though the resulting perturbation effects are larger than random controls in 3 of 4 conditions but not formally significant. Feature reproducibility across random seeds is 21%, and individual features should be interpreted as illustrative rather than stable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript applies TopK sparse autoencoders to the residual streams of FlatASCEND (a 14.5M-parameter autoregressive clinical sequence model) at all 10 layers on INSPECT (outpatient) and MIMIC-IV (ICU) data. It reports progressive abstraction (layer-0 features as near-perfect token detectors with 45.7% singleton rate; layer-6 features spanning ~30 token types), compares SAE features vs dense representations via linear probes on mortality (discrete) and length-of-stay (continuous) prediction, introduces a delta-mode intervention that reduces perturbation noise by 86x, and reports 21% feature reproducibility across random seeds. The abstract explicitly notes that the full-sequence probe advantage for SAE on mortality does not hold in leakage-safe windows, where dense representations match or exceed SAE performance.
Significance. If the progressive abstraction finding and leakage-safe probe results are robust, the work provides a first systematic SAE decomposition of an EHR foundation model and demonstrates that SAE features do not confer a general advantage over dense representations for clinically relevant prediction tasks. The delta-mode technique is a modest methodological contribution for reducing intervention noise, though its effects are not statistically significant. The low reproducibility underscores domain-specific challenges in obtaining stable interpretable features from clinical sequence models.
major comments (3)
- [Abstract and probe results] Abstract and probe evaluation sections: The central claim that SAE features outperform dense representations for mortality prediction under full-sequence linear probes is load-bearing for the task-specialisation narrative, yet the abstract itself reports the opposite pattern in leakage-safe windows (eICU-CRD 48h: SAE 0.871 vs dense 0.880; MIMIC-IV: 0.836 vs 0.914; INSPECT 1y/3y: 0.697 vs 0.800). This reversal indicates the full-sequence results are likely confounded by post-event token leakage, undermining the probe-level representational phenomenon and requiring the full-sequence comparisons to be de-emphasized or removed.
- [Reproducibility analysis] Reproducibility section: The reported 21% feature reproducibility across random seeds means the large majority of extracted features are unstable. This directly weakens the claims of progressive abstraction, feature complexity (e.g., 45.7% singleton at layer 0, 0.5% at layer 6), and task specialisation, as non-reproducible features cannot reliably illustrate these properties.
- [Delta-mode intervention] Delta-mode intervention results: Although the method reduces perturbation noise by 86x, the resulting effects are larger than random controls in only 3 of 4 conditions and not formally significant. Because this technique is presented as enabling cleaner feature-level experiments, the absence of statistical significance limits its demonstrated utility for causal analysis of clinical concepts.
minor comments (2)
- [Methods] Provide explicit details on data splits, SAE training hyperparameters (beyond the TopK sparsity level k), and the precise construction of leakage-safe windows to support reproducibility.
- [Abstract] Clarify the base-model zero-shot performance numbers referenced for the eICU-CRD setting in the abstract.
Simulated Author's Rebuttal
We appreciate the referee's constructive feedback on our manuscript. We address each of the major comments in detail below, indicating where revisions have been made to the manuscript.
read point-by-point responses
-
Referee: Abstract and probe results: The central claim that SAE features outperform dense representations for mortality prediction under full-sequence linear probes is load-bearing, yet the abstract reports the opposite in leakage-safe windows. This suggests confounding by post-event token leakage, requiring de-emphasis or removal of full-sequence comparisons.
Authors: We thank the referee for this observation. Our abstract and probe sections already explicitly note that the SAE advantage in full-sequence probes does not extend to leakage-safe windows, where dense representations match or exceed SAE performance across settings. We interpret the full-sequence results as a specific probe-level phenomenon rather than a general advantage. To further address the concern about potential leakage confounding, we have de-emphasized the full-sequence comparisons by moving the detailed tables and figures to the appendix and expanding the discussion on the importance of leakage-safe evaluations for clinical tasks. This revision maintains transparency while focusing on the robust findings. revision: partial
-
Referee: Reproducibility section: The reported 21% feature reproducibility across random seeds means the large majority of extracted features are unstable, weakening claims of progressive abstraction, feature complexity, and task specialisation.
Authors: We concur that 21% reproducibility implies most individual features are not stable across seeds. The manuscript already states that features should be interpreted as illustrative. The progressive abstraction and complexity claims are supported by aggregate statistics (e.g., singleton feature rates decreasing from 45.7% at layer 0 to 0.5% at layer 6, and increasing token span) that are consistent across dictionary trainings. We have added clarification in the reproducibility section that these layer-wise trends are reproducible at the population level, even as specific feature identities vary. This distinction preserves the validity of the abstraction narrative. revision: yes
-
Referee: Delta-mode intervention results: The method reduces perturbation noise by 86x, but effects are larger than random controls in only 3 of 4 conditions and not formally significant, limiting its utility for causal analysis of clinical concepts.
Authors: The referee accurately points out the lack of formal statistical significance in the perturbation effects. The delta-mode contribution centers on the measured 86x reduction in perturbation noise, which we quantify directly. We have revised the relevant section to highlight this noise reduction as the primary methodological advance and to caution that while it facilitates cleaner interventions, the observed effects on downstream tasks were not statistically significant in all cases, suggesting the need for further studies to establish causal utility. revision: partial
Circularity Check
No significant circularity in empirical SAE probe comparisons
full rationale
The paper is an empirical study reporting measured differences in linear probe performance between SAE features and dense representations on held-out clinical datasets (eICU-CRD, MIMIC-IV, INSPECT). No derivation chain, first-principles prediction, or fitted parameter is presented that reduces by construction to its own inputs; all AUC values and feature statistics are computed against external test data. The authors explicitly qualify that the full-sequence SAE advantage for mortality does not hold under leakage-safe windows (where dense representations match or exceed SAE), confirming the comparisons are not self-referential. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- TopK sparsity level k
axioms (1)
- domain assumption Residual stream activations in the clinical transformer contain linearly extractable features that correspond to clinically meaningful concepts.
Reference graph
Works this paper leans on
-
[1]
Y. Li, S. Rao, J. R. A. Solares, A. Hassaine, R. Ramakrishnan, D. Canoy, Y. Zhu, K. Rahimi, and G. Salimi-Khorshidi. BEHRT : Transformer for electronic health records. Scientific Reports, 10(1):1--12, 2020
2020
-
[2]
Rasmy, Y
L. Rasmy, Y. Xiang, Z. Xie, C. Tao, and D. Zhi. Med-BERT : pretrained contextualized embeddings on large-scale structured electronic health records for disease prediction. npj Digital Medicine, 4(1):1--13, 2021
2021
- [3]
-
[4]
doi:10.48550/arXiv.2301.03150 , abstract =
E. Steinberg, J. Fries, Y. Xu, and N. H. Shah. MOTOR : A time-to-event foundation model for structured medical records. arXiv preprint arXiv:2301.03150, 2023
-
[5]
Scaling Recurrence-aware Foundation Models for Clinical Records via Next-Visit Prediction
H. Rajamohan, Y. Yin, T. T. Zheng, . Scaling recurrence-aware foundation models for clinical records via next-visit prediction. arXiv preprint arXiv:2603.24562, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [6]
-
[7]
S. M. Lundberg and S. I. Lee. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems, 30:4765--4774, 2017
2017
-
[8]
Bricken, A
T. Bricken, A. Templeton, J. Batson, . Towards monosemanticity: Decomposing language models with dictionary learning. Transformer Circuits Thread, Anthropic, 2023
2023
-
[9]
Cunningham, A
H. Cunningham, A. Ewart, L. Riggs, R. Huben, and L. Sharkey. Sparse autoencoders find highly interpretable features in language models. In International Conference on Learning Representations, 2023
2023
-
[10]
Templeton, T
A. Templeton, T. Conerly, J. Marcus, . Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet . Transformer Circuits Thread, Anthropic, 2024
2024
-
[11]
A. V. Orlov, M. Schuster, and T. Berger. Sparse dictionary learning for biological foundation models: A comprehensive review. bioRxiv, doi:10.64898/2026.03.04.709491, 2026
- [12]
-
[13]
Press, N
O. Press, N. A. Smith, and M. Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. In International Conference on Learning Representations, 2022
2022
-
[14]
L. Gao, T. Dupuis, E. Denison, and A. Conmy. Scaling and evaluating sparse autoencoders. arXiv preprint arXiv:2406.04093, 2024
work page internal anchor Pith review arXiv 2024
-
[15]
arXiv preprint arXiv:2501.16615 , year=
G. Paulo and N. Belrose. Sparse autoencoders trained on the same data learn different features. arXiv preprint arXiv:2501.16615, 2025
-
[16]
W. A. Knaus, E. A. Draper, D. P. Wagner, and J. E. Zimmerman. APACHE II : A severity of disease classification system. Critical Care Medicine, 13(10):818--829, 1985
1985
-
[17]
J. R. Le Gall, S. Lemeshow, and F. Saulnier. A new simplified acute physiology score ( SAPS II ) based on a European/North American multicenter study. JAMA, 270(24):2957--2963, 1993
1993
-
[18]
A. E. W. Johnson, L. Bulgarelli, L. Shen, A. Gayles, A. Shammout, S. Horng, T. J. Pollard, B. Moody, B. Gow, L. Lehman, L. A. Celi, and R. G. Mark. MIMIC-IV , a freely accessible electronic health record dataset. Scientific Data, 10(1):1--9, 2023
2023
-
[19]
T. J. Pollard, A. E. W. Johnson, J. D. Raffa, L. A. Celi, R. G. Mark, and O. Badawi. The eICU Collaborative Research Database, a freely available multi-center database for critical care research. Scientific Data, 5(1):1--13, 2018
2018
-
[20]
A. L. Goldberger, L. A. N. Amaral, L. Glass, J. M. Hausdorff, P. C. Ivanov, R. G. Mark, J. E. Mietus, G. B. Moody, C. K. Peng, and H. E. Stanley. PhysioBank , PhysioToolkit , and PhysioNet : Components of a new research resource for complex physiologic signals. Circulation, 101(23):e215--e220, 2000
2000
-
[21]
Sainsbury, F
C. Sainsbury, F. Dong, and A. Karwath. FlatASCEND : Autoregressive clinical sequence generation with continuous time prediction and association-based pharmacological testing. Preprint, 2025
2025
-
[22]
M. Modi, J. E. Krull, D. Johnson, X. Wang, T. D. Gauntner, M. Li, H. Cheng, A. Ma, P. Zhang, D. G. Stover, Z. Li, and Q. Ma. Understanding clinical reasoning variability in medical large language models: A mechanistic interpretability study. medRxiv, doi:10.64898/2026.01.26.26344845, 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.