Recognition: unknown
CTM-AI: A Blueprint for General AI Inspired by a Model of Consciousness
Pith reviewed 2026-05-09 19:43 UTC · model grok-4.3
The pith
CTM-AI uses a consciousness model to select and integrate outputs from many foundation-model processors for broader task performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
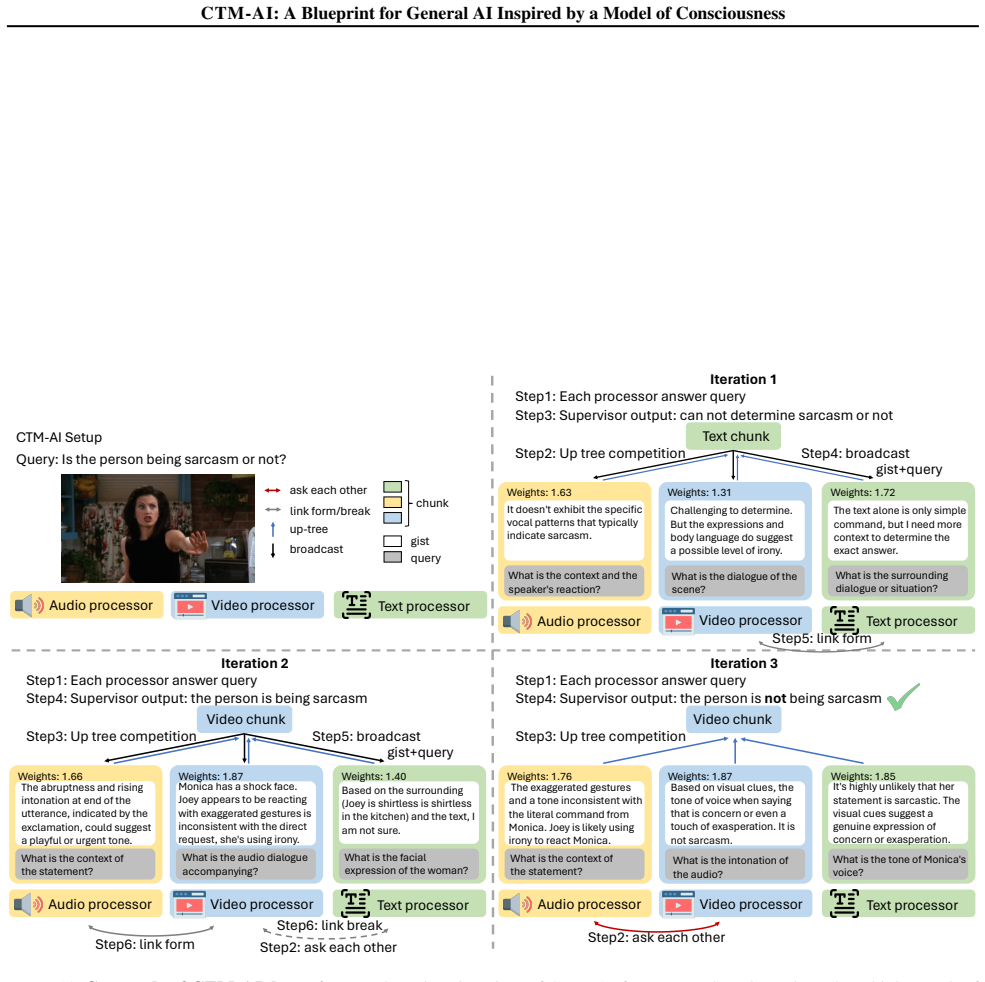
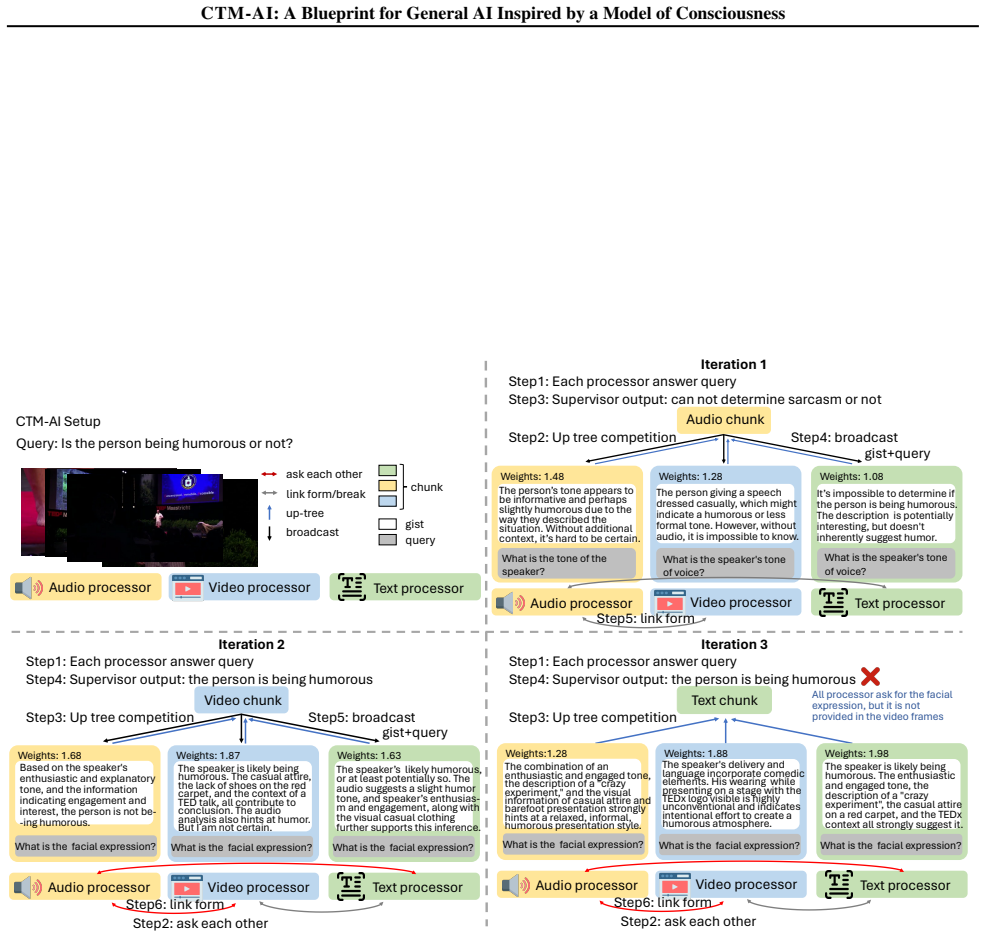
The paper claims that CTM-AI, built by combining the Conscious Turing Machine's processor-selection and integration rules with today's foundation models, supplies a principled blueprint for general AI. For any given task the system draws on a large pool of powerful processors, selects relevant outputs, integrates them, and allows exchange as needed, yielding state-of-the-art accuracy on sarcasm and humor detection benchmarks and substantial gains on tool-use and agentic benchmarks.
What carries the argument
The Conscious Turing Machine processor-selection and integration mechanism, which chooses relevant outputs from many specialized experts and general learners and combines them to solve the current task.
If this is right
- The architecture can outperform existing multimodal and multi-agent systems on sarcasm and humor detection tasks.
- It produces more than ten-point gains on tool-using and web-agent benchmarks.
- The design accommodates both specialized expert processors and unspecialized learners that can acquire new expertise.
- It supplies a single principled mechanism for handling diverse problems rather than separate ad-hoc solutions.
Where Pith is reading between the lines
- If the selection mechanism proves robust, the same blueprint could be tested on additional domains such as planning or scientific reasoning to check breadth of benefit.
- One could examine whether removing the CTM layer while keeping the same processors drops performance, isolating the contribution of the integration rules.
- The approach invites direct comparison with other orchestration methods to determine how much of the observed gain traces to consciousness-inspired selection versus simply having access to many models.
Load-bearing premise
The CTM selection and integration rules, when added to foundation models, will produce flexible general intelligence instead of merely providing task-specific coordination benefits.
What would settle it
A benchmark suite in which CTM-AI shows no improvement over standard multi-agent orchestration without the CTM selection layer would undermine the claim that the mechanism confers general utility.
Figures






read the original abstract
Despite remarkable advances, today's AI systems remain narrow in scope, falling short of the flexible, adaptive, and multisensory intelligence that characterizes human capabilities. This gap has fueled longstanding debates about whether AI might one day achieve human-like generality or even consciousness, and whether theories of consciousness can inspire new architectures for AI. This paper presents an early blueprint for implementing a general AI system, CTM-AI, combining the Conscious Turing Machine (CTM), a formal machine model of consciousness, with today's foundation models. CTM-AI contains an enormous number of powerful processors ranging from specialized experts (e.g., vision-language models and APIs) to unspecialized general-purpose learners poised to develop their own expertise. Crucially, for whatever problem must be dealt with, information from many processors is selected, integrated, and exchanged appropriately to solve the task. CTM-AI achieves state-of-the-art accuracy on MUStARD (72.28) and UR-FUNNY (72.13), outperforming multimodal and multi-agent frameworks. On tool-using and agentic tasks, CTM-AI achieves 10+ points of improvement on StableToolBench and WebArena-Lite. Overall, CTM-AI offers a principled, testable blueprint for general AI inspired by a model of consciousness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CTM-AI, an early blueprint for general AI that integrates the Conscious Turing Machine (CTM) model of consciousness with foundation models. The architecture consists of numerous processors (specialized experts such as vision-language models and APIs, plus unspecialized learners) whose outputs are selected, integrated, and exchanged to solve tasks. It reports state-of-the-art accuracy on MUStARD (72.28) and UR-FUNNY (72.13), outperforming multimodal and multi-agent frameworks, plus 10+ point gains on tool-using/agentic benchmarks including StableToolBench and WebArena-Lite.
Significance. If the reported gains are shown to arise specifically from the CTM processor-selection and integration mechanism rather than from the underlying foundation models or generic orchestration, the work would supply a concrete, testable architecture linking formal consciousness models to practical AI generality. The benchmark numbers, if reproducible with ablations, would constitute falsifiable evidence for the blueprint's utility on sarcasm detection, humor detection, and tool-use tasks.
major comments (3)
- [Abstract / Results] Abstract and Results section: The SOTA claims (MUStARD 72.28, UR-FUNNY 72.13, +10 on StableToolBench/WebArena-Lite) are presented without methods details, error bars, ablation studies, data splits, or pseudocode for the CTM selection/integration rule. This prevents verification that the CTM component, rather than the processors alone or standard multi-agent routing, produces the numbers.
- [§3] §3 (architecture description): The claim that 'information from many processors is selected, integrated, and exchanged appropriately' is central to the generality argument, yet no formal specification, algorithm, or comparison against non-CTM baselines using identical processors is supplied. Without this isolation, the consciousness-inspired element remains non-load-bearing for the performance claims.
- [Discussion / Experiments] Discussion / Experiments: No comparison is reported against competent multi-model orchestration systems that do not invoke the CTM processor-selection mechanism. This leaves open the possibility that equivalent gains could be obtained without the CTM layer, undermining the assertion that the blueprint advances beyond existing multi-agent frameworks.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction should explicitly cite the prior CTM papers that define the processor-selection formalism being extended.
- [§3] Notation for processor types and integration steps is introduced informally; a compact diagram or pseudocode block would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the current version of the manuscript requires substantial additions in methodological detail, formal specification, and comparative experiments to properly substantiate the role of the CTM mechanism. We will perform a major revision to address all points raised.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and Results section: The SOTA claims (MUStARD 72.28, UR-FUNNY 72.13, +10 on StableToolBench/WebArena-Lite) are presented without methods details, error bars, ablation studies, data splits, or pseudocode for the CTM selection/integration rule. This prevents verification that the CTM component, rather than the processors alone or standard multi-agent routing, produces the numbers.
Authors: We agree that the presentation of results is insufficiently detailed for verification. In the revised manuscript we will add a dedicated Methods subsection containing: pseudocode for the CTM processor-selection and integration rule, error bars from repeated runs with different random seeds, explicit data splits and preprocessing steps, and ablation experiments that hold the processor set fixed while varying only the selection/integration mechanism. These additions will allow readers to assess whether the reported gains are attributable to the CTM layer. revision: yes
-
Referee: [§3] §3 (architecture description): The claim that 'information from many processors is selected, integrated, and exchanged appropriately' is central to the generality argument, yet no formal specification, algorithm, or comparison against non-CTM baselines using identical processors is supplied. Without this isolation, the consciousness-inspired element remains non-load-bearing for the performance claims.
Authors: We accept this criticism. Section 3 will be expanded with a formal algorithmic description of the selection, integration, and exchange processes (including mathematical notation for the CTM-inspired rules). We will also insert direct experimental comparisons that use exactly the same processor pool but replace the CTM selection mechanism with standard multi-agent routing, thereby isolating the contribution of the consciousness-inspired component. revision: yes
-
Referee: [Discussion / Experiments] Discussion / Experiments: No comparison is reported against competent multi-model orchestration systems that do not invoke the CTM processor-selection mechanism. This leaves open the possibility that equivalent gains could be obtained without the CTM layer, undermining the assertion that the blueprint advances beyond existing multi-agent frameworks.
Authors: We agree that the absence of such baselines weakens the generality claim. The revised Experiments and Discussion sections will include head-to-head evaluations against established multi-agent orchestration frameworks (e.g., AutoGen-style and LangChain-style systems) that employ the identical foundation-model processors but lack the CTM selection and integration rules. These comparisons will clarify whether the observed improvements require the CTM layer. revision: yes
Circularity Check
No significant circularity: blueprint proposal with independent empirical results
full rationale
The paper presents CTM-AI as a high-level architectural blueprint that combines the authors' prior CTM model with existing foundation models and reports concrete benchmark accuracies (e.g., 72.28 on MUStARD). No mathematical derivation, first-principles prediction, or fitted parameter is claimed whose output reduces by construction to the input definitions or to a self-citation chain. The performance numbers are presented as experimental outcomes rather than logically forced results. Self-reference to the CTM is standard for building on prior formal work and does not render the new integration claim tautological. The architecture description remains open to external validation or ablation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Conscious Turing Machine provides a sufficient formal model for selecting and integrating information across heterogeneous processors to achieve general intelligence.
invented entities (1)
-
CTM-AI architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Butlin, P., Long, R., Elmoznino, E., Bengio, Y ., Birch, J., Constant, A., Deane, G., Fleming, S. M., Frith, C., Ji, X., et al. Consciousness in artificial intelligence: in- sights from the science of consciousness.arXiv preprint arXiv:2308.08708,
-
[4]
Adae- volve: Adaptive llm driven zeroth-order optimization.arXiv preprint arXiv:2602.20133, 2026
Cemri, M., Liu, S., Agarwal, S., Maheswaran, M., Li, Z., Mang, Q., Naren, A., Keutzer, K., Dimakis, A. G., Sen, K., Zaharia, M., and Stoica, I. AdaEvolve: Adaptive LLM driven zeroth-order optimization.arXiv preprint arXiv:2602.20133,
-
[5]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
- [6]
-
[7]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
URL https://arxiv. org/abs/2305.14325. Franklin, S., Madl, T., D’mello, S., and Snaider, J. Lida: A systems-level architecture for cognition, emotion, and learning.IEEE Transactions on Autonomous Mental Development, 6(1):19–41,
work page internal anchor Pith review arXiv
-
[8]
Guo, Z., Cheng, S., Wang, H., Liang, S., Qin, Y ., Li, P., Liu, Z., Sun, M., and Liu, Y . Stabletoolbench: Towards stable large-scale benchmarking on tool learning of large lan- guage models.arXiv preprint arXiv:2403.07714,
-
[9]
Stabletoolbench-mirrorapi: Modeling tool environments as mirrors of 7,000+ real-world apis
Guo, Z., Cheng, S., Niu, Y ., Wang, H., Zhou, S., Huang, W., and Liu, Y . Stabletoolbench-mirrorapi: Modeling tool environments as mirrors of 7,000+ real-world apis. In Findings of the Association for Computational Linguis- tics: ACL 2025, pp. 5247–5270,
2025
-
[10]
K., Rahman, W., Zadeh, A
10 CTM-AI: A Blueprint for General AI Inspired by a Model of Consciousness Hasan, M. K., Rahman, W., Zadeh, A. B., Zhong, J., Tan- veer, M. I., Morency, L.-P., and Hoque, M. E. Ur-funny: A multimodal language dataset for understanding humor. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International ...
2019
-
[11]
Towards a Science of Scaling Agent Systems
Kim, Y ., Gu, K., Park, C., Park, C., Schmidgall, S., Heydari, A. A., Yan, Y ., Zhang, Z., Zhuang, Y ., Malhotra, M., et al. Towards a science of scaling agent systems.arXiv preprint arXiv:2512.08296,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
PuzzleWorld: A Benchmark for Multimodal, Open-Ended Reasoning in Puzzlehunts
Li, H., Jiang, B., Naehu, A., Song, R., Zhang, J., Tjan- drasuwita, M., Ekbote, C., Chen, S.-S., Balachandran, A., Dai, W., et al. Puzzleworld: A benchmark for mul- timodal, open-ended reasoning in puzzlehunts.arXiv preprint arXiv:2506.06211, 2025a. Li, J., Selvaraju, R., Gotmare, A., Joty, S., Xiong, C., and Hoi, S. C. H. Align before fuse: Vision and la...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Li, J., Huang, P., Li, Y ., Chen, S., Hu, J., and Tian, Y . A unified multi-agent framework for universal multi- modal understanding and generation.arXiv preprint arXiv:2508.10494, 2025b. Liang, P. P., Zadeh, A., and Morency, L.-P. Foundations & trends in multimodal machine learning: Principles, challenges, and open questions.ACM Computing Surveys, 56(10):1–42,
- [14]
-
[15]
Liu, X., Zhang, T., Gu, Y ., Iong, I. L., Xu, Y ., Song, X., Zhang, S., Lai, H., Liu, X., Zhao, H., et al. Visualagent- bench: Towards large multimodal models as visual foun- dation agents.arXiv preprint arXiv:2408.06327,
-
[16]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Accessed: 2026-04-18. Novikov, A., V˜u, N., Eisenberger, M., Dupont, E., Huang, P.-S., Wagner, A. Z., Shirobokov, S., Kozlovskii, B., Ruiz, F. J., Mehrabian, A., et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131,
work page internal anchor Pith review arXiv 2026
-
[17]
ChatDev: Communicative Agents for Software Development
Qian, C., Liu, W., Liu, H., Chen, N., Dang, Y ., Li, J., Yang, C., Chen, W., Su, Y ., Cong, X., et al. Chatdev: Commu- nicative agents for software development.arXiv preprint arXiv:2307.07924,
work page internal anchor Pith review arXiv
-
[18]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Qin, Y ., Liang, S., Ye, Y ., Zhu, K., Yan, L., Lu, Y ., Lin, Y ., Cong, X., Tang, X., Qian, B., et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. arXiv preprint arXiv:2307.16789,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
URL https://arxiv. org/abs/2604.01658. Rosenthal, D.Consciousness and mind. Clarendon Press,
-
[20]
Agent laboratory: Using llm agents as research assistants.arXiv preprint arXiv:2501.04227, 2025
Schmidgall, S., Su, Y ., Wang, Z., Sun, X., Wu, J., Yu, X., Liu, J., Moor, M., Liu, Z., and Barsoum, E. Agent lab- oratory: Using llm agents as research assistants.arXiv preprint arXiv:2501.04227,
-
[21]
arXiv preprint arXiv:2406.04692 , year=
Wang, J., Wang, J., Athiwaratkun, B., Zhang, C., and Zou, J. Mixture-of-agents enhances large language model capabilities.arXiv preprint arXiv:2406.04692,
-
[22]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., and Zhou, D. Self-consistency im- proves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review arXiv
-
[23]
Xu, J., Guo, Z., Hu, H., Chu, Y ., Wang, X., He, J., Wang, Y ., Shi, X., He, T., Zhu, X., et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765,
work page internal anchor Pith review arXiv
-
[24]
A survey of ai agent protocols.arXiv preprint arXiv:2504.16736,
Yang, Y ., Chai, H., Song, Y ., Qi, S., Wen, M., Li, N., Liao, J., Hu, H., Lin, J., Chang, G., et al. A survey of ai agent protocols.arXiv preprint arXiv:2504.16736,
- [25]
-
[26]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Zhou, S., Xu, F. F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Bisk, Y ., Fried, D., Alon, U., et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854,
work page internal anchor Pith review arXiv
- [27]
-
[28]
As noted by Guo et al
as the tool environment, which fine-tunes a specialized LLM on StableToolBench’s cached API traces to stably mirror real API behaviors. As noted by Guo et al. (2025), some queries in the original test set reference APIs that are no longer available; such queries may fail during evaluation regardless of the agent’s behavior. We report results over queries ...
2025
-
[29]
For prompting-based baselines, we evaluate Qwen3-VL-8B-Instruct, Qwen3-VL-8B-thinking, Qwen3-Omni-flash, and Gemini- 2.5-flash-lite using identical zero-shot/few-shot prompts
(2.7B parameters), MMoE (Yu et al., 2023), and our BaseModel (Gemini-2.5-flash-lite). For prompting-based baselines, we evaluate Qwen3-VL-8B-Instruct, Qwen3-VL-8B-thinking, Qwen3-Omni-flash, and Gemini- 2.5-flash-lite using identical zero-shot/few-shot prompts. Humor Detection (URFUNNY). To assess multimodal affective understanding, we evaluate this task ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.