Recognition: 3 theorem links
· Lean TheoremLearning reveals invisible structure in low-rank RNNs
Pith reviewed 2026-05-08 18:34 UTC · model grok-4.3
The pith
Learning in low-rank RNNs reduces to low-dimensional ODEs in overlap space, separating functional connections from those that only shape training history.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We extend the low-rank framework from activity to learning by deriving gradient-descent dynamics directly in a reduced overlap space. We formulate a closed-form, low-dimensional system of ODEs that governs learning in this space, exact for linear RNNs and asymptotically exact for nonlinear RNNs in the large-N Gaussian limit. Central to our analysis is a distinction between two classes of overlaps: loss-visible overlaps, which fully determine network activity, output, and loss, and loss-invisible overlaps, which do not affect function but are required to describe learning. We illustrate the consequences of this decomposition through two phenomena. First, we show that learning can serve as a a
What carries the argument
the decomposition of pairwise overlaps into loss-visible and loss-invisible classes inside the low-rank connectivity space, which reduces the full weight-update dynamics to a low-dimensional closed-form ODE system
If this is right
- Learning acts as a perturbation that can expose differences in connectivity between networks that produce identical activity and loss.
- Loss-invisible overlaps can function as memory variables that encode aspects of training history when certain conditions on the loss and update rules hold.
- The reduced dynamics remain low-dimensional regardless of network size, providing a scalable description of learning.
- The theory yields concrete, testable predictions for how biological circuits might change during learning without immediately altering behavior.
Where Pith is reading between the lines
- If the separation holds, one could in principle train networks to store task history in invisible overlaps while keeping current performance unchanged.
- The same visible-invisible split might offer a way to model how biological synapses can carry long-term learning traces that are not expressed in immediate circuit output.
- Checking the approximation in moderately sized networks could identify the practical limits of the large-N reduction.
Load-bearing premise
The network must be large and its connectivity low-rank so that the Gaussian limit applies and the high-dimensional learning problem collapses to the overlap variables.
What would settle it
Run gradient descent on a finite but large low-rank RNN and check whether the time evolution of the measured overlap values follows the trajectories predicted by the derived ODE system.
Figures



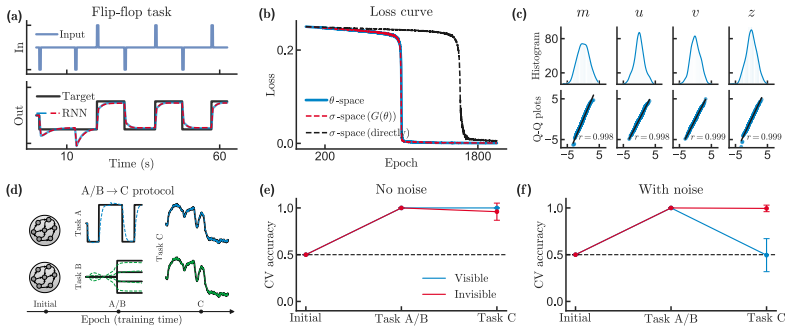
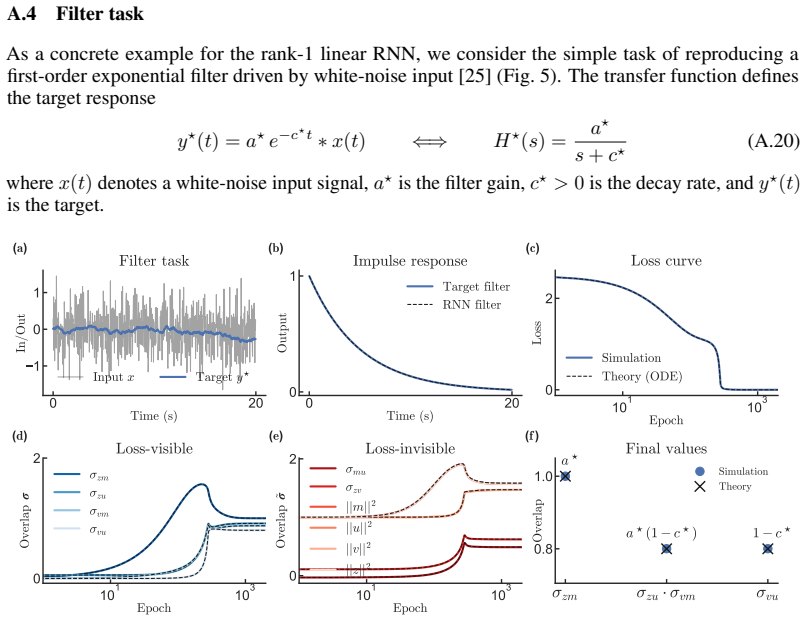
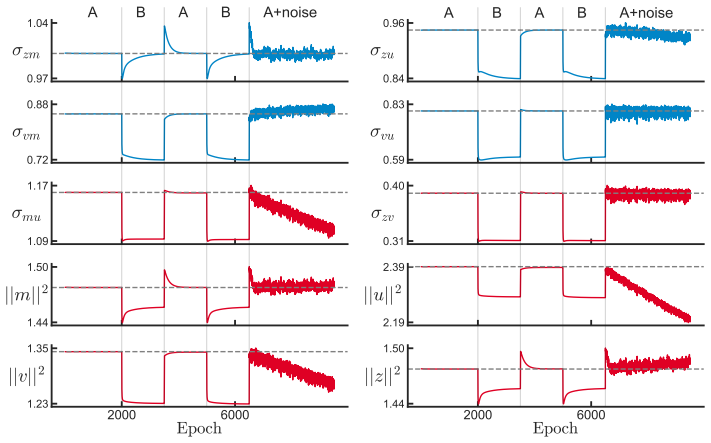


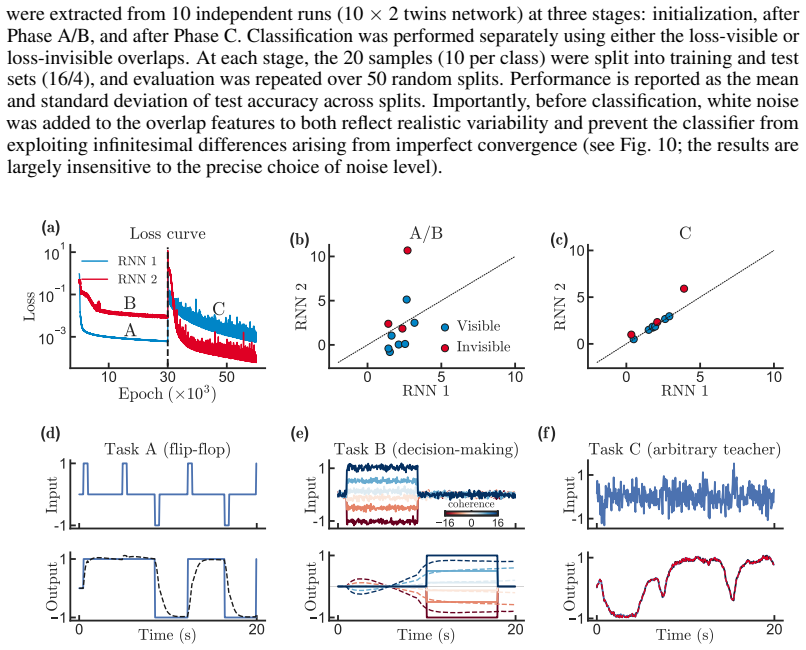
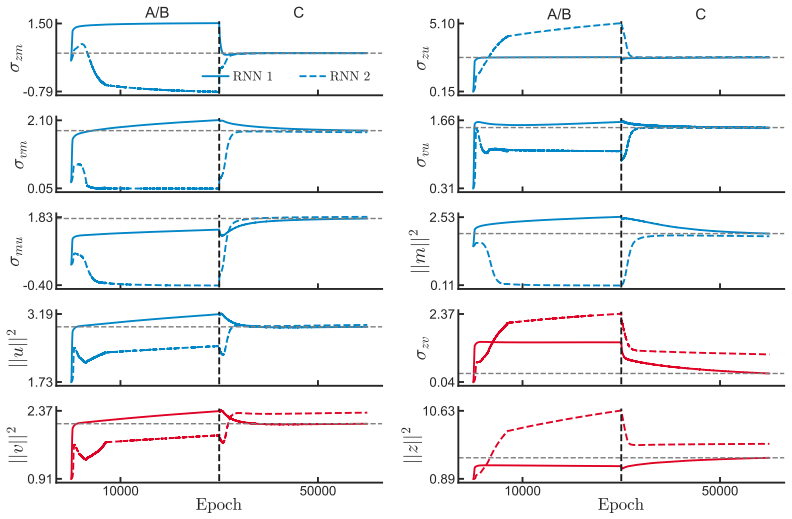

read the original abstract
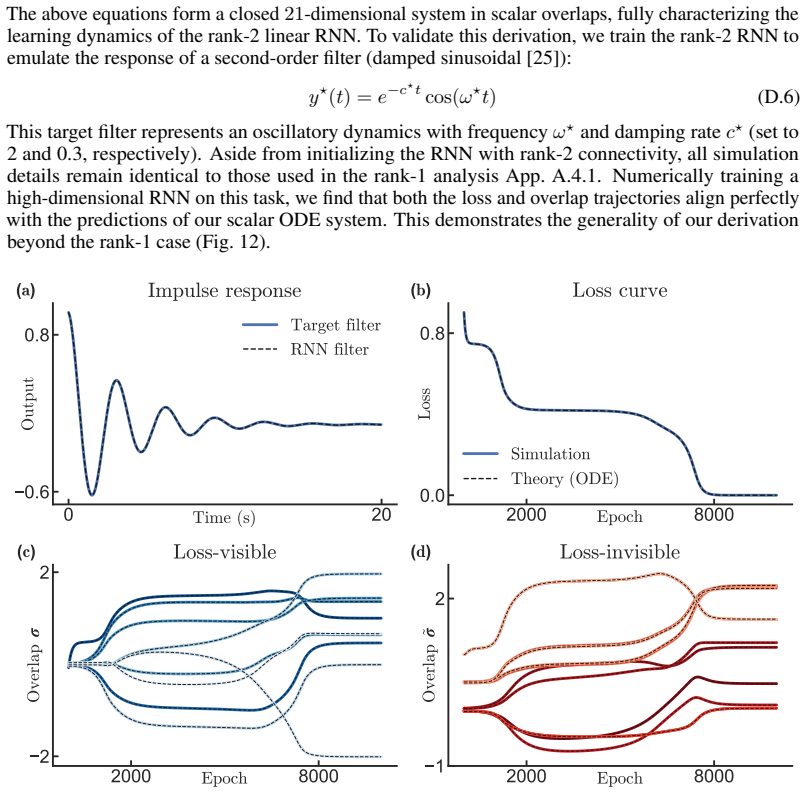
Learning in neural systems arises from synaptic changes that reshape the representations underlying behavior. While low-rank recurrent neural networks (RNNs) have emerged as a powerful framework for linking connectivity to function, a theoretical understanding of their learning process remains elusive. Here, we extend the low-rank framework from activity to learning by deriving gradient-descent dynamics directly in a reduced overlap space. We formulate a closed-form, low-dimensional system of ODEs that governs learning in this space, exact for linear RNNs and asymptotically exact for nonlinear RNNs in the large-$N$ Gaussian limit. Central to our analysis is a distinction between two classes of overlaps: loss-visible overlaps, which fully determine network activity, output, and loss, and loss-invisible overlaps, which do not affect function but are required to describe learning. We illustrate the consequences of this decomposition through two phenomena. First, we show that learning can serve as a perturbation that exposes differences in connectivity between functionally equivalent networks. Second, we show that loss-invisible overlaps can act as memory variables that encode training history, and characterize the conditions under which this occurs. Finally, we present several testable predictions for biological learning experiments derived from our theory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript derives gradient-descent dynamics for low-rank RNNs directly in a reduced space of overlaps, yielding a closed-form low-dimensional system of ODEs. The reduction is stated to be exact for linear RNNs and asymptotically exact for nonlinear RNNs in the large-N Gaussian limit. A key distinction is drawn between loss-visible overlaps (which determine activity, output, and loss) and loss-invisible overlaps (which do not affect function but participate in learning). The authors illustrate two consequences: learning acting as a perturbation that reveals connectivity differences between functionally equivalent networks, and loss-invisible overlaps serving as memory variables that encode training history under certain conditions. Testable predictions for biological experiments are also presented.
Significance. If the claimed reduction is rigorously established, the work supplies a tractable theoretical handle on how low-rank connectivity evolves under learning, bridging connectivity-based models with gradient-based training. The visible/invisible overlap decomposition offers a concrete mechanism for why functional equivalence can mask structural differences and how training history can be stored without altering immediate behavior. The exact linear case and the proposed biological predictions are concrete strengths that could guide both modeling and experiment.
major comments (1)
- [Derivation of the overlap ODEs (main theoretical section)] The central claim of asymptotic exactness for nonlinear RNNs rests on closure of the overlap dynamics in the large-N Gaussian limit. The manuscript must supply the explicit steps (or numerical checks) demonstrating that higher-order moments of the pre-activations factorize appropriately under the gradient flow and that the low-rank structure is preserved (or that rank inflation remains negligible). Without this verification, the reduction to a closed-form ODE system is not guaranteed for general activations or initializations.
minor comments (2)
- [Abstract] The abstract would benefit from a brief statement of the dimension of the reduced ODE system and the precise form of the visible/invisible overlap variables.
- [Notation and setup] Notation for the overlap matrices and the loss function should be introduced with a single consolidated table or equation block early in the text to aid readability.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments. We address the major comment on the derivation of the overlap ODEs below.
read point-by-point responses
-
Referee: [Derivation of the overlap ODEs (main theoretical section)] The central claim of asymptotic exactness for nonlinear RNNs rests on closure of the overlap dynamics in the large-N Gaussian limit. The manuscript must supply the explicit steps (or numerical checks) demonstrating that higher-order moments of the pre-activations factorize appropriately under the gradient flow and that the low-rank structure is preserved (or that rank inflation remains negligible). Without this verification, the reduction to a closed-form ODE system is not guaranteed for general activations or initializations.
Authors: We agree that a more explicit verification of the moment closure and rank preservation would strengthen the manuscript. In the revised version we have added Appendix D, which supplies the requested derivation. Under the large-N Gaussian assumption, the central limit theorem applied to the sum over neurons ensures that pre-activations remain Gaussian; higher-order moments therefore factorize into products of pairwise overlaps. The gradient updates are outer products of the visible and invisible overlaps with the input and output vectors, which by construction preserve the original low-rank form up to o(1) corrections that vanish as N grows. We also include numerical checks for tanh activations across a range of initializations, confirming that the reduced ODEs match full-network trajectories for large N. These additions make the asymptotic exactness claim rigorous for the stated regime. revision: yes
Circularity Check
Derivation of overlap-space ODEs is self-contained with no circular reductions
full rationale
The paper starts from standard gradient descent on a loss function and reduces the dynamics to a low-dimensional system of ODEs in overlap space. This reduction is exact for linear RNNs by direct algebraic closure and asymptotically exact for nonlinear RNNs under the stated large-N Gaussian limit, which is an external modeling assumption rather than a quantity fitted or defined in terms of the target result. No equations are shown to be equivalent to their inputs by construction, no parameters are fitted to a subset and then relabeled as predictions, and no load-bearing steps rely on self-citations or imported uniqueness theorems. The visible/invisible overlap distinction follows directly from the low-rank connectivity premise without self-reference.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption RNN connectivity is low-rank
- domain assumption Large-N Gaussian limit for nonlinear RNNs
Lean theorems connected to this paper
-
Foundation/ArithmeticFromLogic.lean (orbit/embedding structure)embed_add (multiplicative homomorphism) — unrelated invariant structure unclearK = zz^⊤ + vv^⊤ − mm^⊤ − uu^⊤ ∈ R^{N×N} is conserved throughout learning ... gradient flow admits exact invariants of the learning dynamics.
-
Cost/FunctionalEquation.lean (J-cost uniqueness)washburn_uniqueness_aczel — not invoked; loss is generic squared error, not J(x)=½(x+x⁻¹)−1 unclearG(θ) acts as a preconditioner, reshaping ∇σ L according to the geometry inherited from parameter space.
Reference graph
Works this paper leans on
-
[1]
Embracing multiple definitions of learning.Trends in neurosciences, 38(7):405–407, 2015
Andrew B Barron, Eileen A Hebets, Thomas A Cleland, Courtney L Fitzpatrick, Mark E Hauber, and Jeffrey R Stevens. Embracing multiple definitions of learning.Trends in neurosciences, 38(7):405–407, 2015
2015
-
[2]
How learning unfolds in the brain: toward an optimization view.Neuron, 109(23):3720–3735, 2021
Jay A Hennig, Emily R Oby, Darby M Losey, Aaron P Batista, Byron M Yu, and Steven M Chase. How learning unfolds in the brain: toward an optimization view.Neuron, 109(23):3720–3735, 2021
2021
-
[3]
If deep learning is the answer, what is the question?Nature Reviews Neuroscience, 22(1):55–67, 2021
Andrew Saxe, Stephanie Nelli, and Christopher Summerfield. If deep learning is the answer, what is the question?Nature Reviews Neuroscience, 22(1):55–67, 2021
2021
-
[4]
The neurobiology of learning and memory.Science, 233(4767):941–947, 1986
Richard F Thompson. The neurobiology of learning and memory.Science, 233(4767):941–947, 1986
1986
-
[5]
Synaptic plasticity forms and functions.Annual review of neuroscience, 43(1):95–117, 2020
Jeffrey C Magee and Christine Grienberger. Synaptic plasticity forms and functions.Annual review of neuroscience, 43(1):95–117, 2020
2020
-
[6]
Neural constraints on learning
Patrick T Sadtler, Kristin M Quick, Matthew D Golub, Steven M Chase, Stephen I Ryu, Elizabeth C Tyler-Kabara, Byron M Yu, and Aaron P Batista. Neural constraints on learning. Nature, 512(7515):423–426, 2014
2014
-
[7]
The next generation of approaches to investigate the link between synaptic plasticity and learning.Nature neuroscience, 22(10):1536–1543, 2019
Yann Humeau and Daniel Choquet. The next generation of approaches to investigate the link between synaptic plasticity and learning.Nature neuroscience, 22(10):1536–1543, 2019
2019
-
[8]
On simplicity and complexity in the brave new world of large-scale neuroscience.Current opinion in neurobiology, 32:148–155, 2015
Peiran Gao and Surya Ganguli. On simplicity and complexity in the brave new world of large-scale neuroscience.Current opinion in neurobiology, 32:148–155, 2015
2015
-
[9]
Systematic errors in connectivity inferred from activity in strongly recurrent networks.Nature Neuroscience, 23(10):1286–1296, 2020
Abhranil Das and Ila R Fiete. Systematic errors in connectivity inferred from activity in strongly recurrent networks.Nature Neuroscience, 23(10):1286–1296, 2020
2020
-
[10]
Degeneracy and complexity in biological systems
Gerald M Edelman and Joseph A Gally. Degeneracy and complexity in biological systems. Proceedings of the national academy of sciences, 98(24):13763–13768, 2001
2001
-
[11]
Similar network activity from disparate circuit parameters.Nature neuroscience, 7(12):1345–1352, 2004
Astrid A Prinz, Dirk Bucher, and Eve Marder. Similar network activity from disparate circuit parameters.Nature neuroscience, 7(12):1345–1352, 2004
2004
-
[12]
The brain’s best kept secret is its degenerate structure.Journal of Neuroscience, 44(40), 2024
Larissa Albantakis, Christophe Bernard, Naama Brenner, Eve Marder, and Rishikesh Narayanan. The brain’s best kept secret is its degenerate structure.Journal of Neuroscience, 44(40), 2024
2024
-
[13]
For neural networks, function determines form
Francesca Albertini and Eduardo D Sontag. For neural networks, function determines form. Neural networks, 6(7):975–990, 1993
1993
-
[14]
On linear identifiability of learned rep- resentations
Geoffrey Roeder, Luke Metz, and Durk Kingma. On linear identifiability of learned rep- resentations. InInternational Conference on Machine Learning, pages 9030–9039. PMLR, 2021
2021
-
[15]
Not all solutions are created equal: An analytical dissociation of functional and representational similarity in deep linear neural networks
Lukas Braun, Erin Grant, and Andrew M Saxe. Not all solutions are created equal: An analytical dissociation of functional and representational similarity in deep linear neural networks. In F orty-second International Conference on Machine Learning, 2025. 10
2025
-
[16]
Linking connectivity, dynamics, and computa- tions in low-rank recurrent neural networks.Neuron, 99(3):609–623, 2018
Francesca Mastrogiuseppe and Srdjan Ostojic. Linking connectivity, dynamics, and computa- tions in low-rank recurrent neural networks.Neuron, 99(3):609–623, 2018
2018
-
[17]
Dynamics of random recurrent networks with correlated low-rank structure.Physical Review Research, 2(1):013111, 2020
Friedrich Schuessler, Alexis Dubreuil, Francesca Mastrogiuseppe, Srdjan Ostojic, and Omri Barak. Dynamics of random recurrent networks with correlated low-rank structure.Physical Review Research, 2(1):013111, 2020
2020
-
[18]
Shaping dynamics with multiple populations in low-rank recurrent networks.Neural computation, 33(6):1572–1615, 2021
Manuel Beiran, Alexis Dubreuil, Adrian Valente, Francesca Mastrogiuseppe, and Srdjan Os- tojic. Shaping dynamics with multiple populations in low-rank recurrent networks.Neural computation, 33(6):1572–1615, 2021
2021
-
[19]
Neural networks and physical systems with emergent collective computational abilities.Proceedings of the national academy of sciences, 79(8):2554–2558, 1982
John J Hopfield. Neural networks and physical systems with emergent collective computational abilities.Proceedings of the national academy of sciences, 79(8):2554–2558, 1982
1982
-
[20]
MIT press, 2003
Chris Eliasmith and Charles H Anderson.Neural engineering: Computation, representation, and dynamics in neurobiological systems. MIT press, 2003
2003
-
[21]
A theory of multi-task computation and task selection.bioRxiv, pages 2025–12, 2025
Owen Marschall, David G Clark, and Ashok Litwin-Kumar. A theory of multi-task computation and task selection.bioRxiv, pages 2025–12, 2025
2025
-
[22]
The interplay between randomness and structure during learning in rnns.Advances in neural information processing systems, 33:13352–13362, 2020
Friedrich Schuessler, Francesca Mastrogiuseppe, Alexis Dubreuil, Srdjan Ostojic, and Omri Barak. The interplay between randomness and structure during learning in rnns.Advances in neural information processing systems, 33:13352–13362, 2020
2020
-
[23]
The role of population structure in computations through neural dynamics.Nature neuroscience, 25(6):783–794, 2022
Alexis Dubreuil, Adrian Valente, Manuel Beiran, Francesca Mastrogiuseppe, and Srdjan Ostojic. The role of population structure in computations through neural dynamics.Nature neuroscience, 25(6):783–794, 2022
2022
-
[24]
Extracting computational mechanisms from neural data using low-rank rnns.Advances in Neural Information Processing Systems, 35:24072–24086, 2022
Adrian Valente, Jonathan W Pillow, and Srdjan Ostojic. Extracting computational mechanisms from neural data using low-rank rnns.Advances in Neural Information Processing Systems, 35:24072–24086, 2022
2022
-
[25]
Dynamically learning to integrate in recurrent neural networks.arXiv preprint arXiv:2503.18754, 2025
Blake Bordelon, Jordan Cotler, Cengiz Pehlevan, and Jacob A Zavatone-Veth. Dynamically learning to integrate in recurrent neural networks.arXiv preprint arXiv:2503.18754, 2025
-
[26]
Learning dynamics in linear recurrent neural networks
Alexandra Maria Proca, Clémentine Carla Juliette Dominé, Murray Shanahan, and Pedro AM Mediano. Learning dynamics in linear recurrent neural networks. InF orty-second International Conference on Machine Learning, 2025
2025
-
[27]
Chaos in random neural networks.Physical review letters, 61(3):259, 1988
Haim Sompolinsky, Andrea Crisanti, and Hans-Jurgen Sommers. Chaos in random neural networks.Physical review letters, 61(3):259, 1988
1988
-
[28]
Recurrent neural networks as versatile tools of neuroscience research.Current opinion in neurobiology, 46:1–6, 2017
Omri Barak. Recurrent neural networks as versatile tools of neuroscience research.Current opinion in neurobiology, 46:1–6, 2017
2017
-
[29]
Measuring and controlling solution degeneracy across task-trained recurrent neural networks
Ann Huang, Satpreet Harcharan Singh, Flavio Martinelli, and Kanaka Rajan. Measuring and controlling solution degeneracy across task-trained recurrent neural networks. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[30]
Memory by accident: a theory of learning as a byproduct of network stabilization
Basile Confavreux, Will Dorrell, Nishil Patel, and Andrew M Saxe. Memory by accident: a theory of learning as a byproduct of network stabilization. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[31]
Algorithmic regularization in learning deep homoge- neous models: Layers are automatically balanced.Advances in neural information processing systems, 31, 2018
Simon S Du, Wei Hu, and Jason D Lee. Algorithmic regularization in learning deep homoge- neous models: Layers are automatically balanced.Advances in neural information processing systems, 31, 2018
2018
-
[32]
Implicit regularization for deep neural networks driven by an ornstein-uhlenbeck like process
Guy Blanc, Neha Gupta, Gregory Valiant, and Paul Valiant. Implicit regularization for deep neural networks driven by an ornstein-uhlenbeck like process. InConference on learning theory, pages 483–513. PMLR, 2020
2020
-
[33]
Representational drift as a result of implicit regularization.Elife, 12:RP90069, 2024
Aviv Ratzon, Dori Derdikman, and Omri Barak. Representational drift as a result of implicit regularization.Elife, 12:RP90069, 2024. 11
2024
-
[34]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review arXiv 2014
-
[35]
Opening the black box: low-dimensional dynamics in high- dimensional recurrent neural networks.Neural computation, 25(3):626–649, 2013
David Sussillo and Omri Barak. Opening the black box: low-dimensional dynamics in high- dimensional recurrent neural networks.Neural computation, 25(3):626–649, 2013
2013
-
[36]
Re- verse engineering recurrent networks for sentiment classification reveals line attractor dynamics
Niru Maheswaranathan, Alex Williams, Matthew Golub, Surya Ganguli, and David Sussillo. Re- verse engineering recurrent networks for sentiment classification reveals line attractor dynamics. Advances in neural information processing systems, 32, 2019
2019
-
[37]
Speech recognition with deep recurrent neural networks
Alex Graves, Abdel-rahman Mohamed, and Geoffrey Hinton. Speech recognition with deep recurrent neural networks. In2013 IEEE international conference on acoustics, speech and signal processing, pages 6645–6649. Ieee, 2013
2013
-
[38]
On the difficulty of training recurrent neural networks
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. On the difficulty of training recurrent neural networks. InInternational conference on machine learning, pages 1310–1318. Pmlr, 2013
2013
-
[39]
Resurrecting recurrent neural networks for long sequences
Antonio Orvieto, Samuel L Smith, Albert Gu, Anushan Fernando, Caglar Gulcehre, Razvan Pascanu, and Soham De. Resurrecting recurrent neural networks for long sequences. In International Conference on Machine Learning, pages 26670–26698. PMLR, 2023
2023
-
[40]
Con- nectivity structure and dynamics of nonlinear recurrent neural networks.Physical Review X, 15(4):041019, 2025
David G Clark, Owen Marschall, Alexander Van Meegen, and Ashok Litwin-Kumar. Con- nectivity structure and dynamics of nonlinear recurrent neural networks.Physical Review X, 15(4):041019, 2025
2025
-
[41]
Trained recurrent neural networks de- velop phase-locked limit cycles in a working memory task.PLOS Computational Biology, 20(2):e1011852, 2024
Matthijs Pals, Jakob H Macke, and Omri Barak. Trained recurrent neural networks de- velop phase-locked limit cycles in a working memory task.PLOS Computational Biology, 20(2):e1011852, 2024
2024
-
[42]
Learning dynamics of RNNs in closed-loop environments
Yoav Ger and Omri Barak. Learning dynamics of RNNs in closed-loop environments. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[43]
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
Andrew M Saxe, James L McClelland, and Surya Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks.arXiv preprint arXiv:1312.6120, 2013
work page Pith review arXiv 2013
-
[44]
A mathematical theory of semantic development in deep neural networks.Proceedings of the National Academy of Sciences, 116(23):11537–11546, 2019
Andrew M Saxe, James L McClelland, and Surya Ganguli. A mathematical theory of semantic development in deep neural networks.Proceedings of the National Academy of Sciences, 116(23):11537–11546, 2019
2019
-
[45]
On the implicit bias of initialization shape: Beyond infinitesimal mirror descent
Shahar Azulay, Edward Moroshko, Mor Shpigel Nacson, Blake E Woodworth, Nathan Srebro, Amir Globerson, and Daniel Soudry. On the implicit bias of initialization shape: Beyond infinitesimal mirror descent. InInternational Conference on Machine Learning, pages 468–477. PMLR, 2021
2021
-
[46]
Neural tangent kernel: Convergence and generalization in neural networks.Advances in neural information processing systems, 31, 2018
Arthur Jacot, Franck Gabriel, and Clément Hongler. Neural tangent kernel: Convergence and generalization in neural networks.Advances in neural information processing systems, 31, 2018
2018
-
[47]
On lazy training in differentiable program- ming.Advances in neural information processing systems, 32, 2019
Lenaic Chizat, Edouard Oyallon, and Francis Bach. On lazy training in differentiable program- ming.Advances in neural information processing systems, 32, 2019
2019
-
[48]
Natural gradient works efficiently in learning.Neural computation, 10(2):251– 276, 1998
Shun-Ichi Amari. Natural gradient works efficiently in learning.Neural computation, 10(2):251– 276, 1998
1998
-
[49]
Razvan Pascanu and Yoshua Bengio. Revisiting natural gradient for deep networks.arXiv preprint arXiv:1301.3584, 2013
-
[50]
Daniel Kunin, Javier Sagastuy-Brena, Surya Ganguli, Daniel LK Yamins, and Hidenori Tanaka. Neural mechanics: Symmetry and broken conservation laws in deep learning dynamics.arXiv preprint arXiv:2012.04728, 2020
-
[51]
Noether’s learning dynamics: Role of symmetry breaking in neural networks.Advances in Neural Information Processing Systems, 34:25646–25660, 2021
Hidenori Tanaka and Daniel Kunin. Noether’s learning dynamics: Role of symmetry breaking in neural networks.Advances in Neural Information Processing Systems, 34:25646–25660, 2021. 12
2021
-
[52]
arXiv preprint arXiv:2110.06914 , year=
Zhiyuan Li, Tianhao Wang, and Sanjeev Arora. What happens after sgd reaches zero loss?–a mathematical framework.arXiv preprint arXiv:2110.06914, 2021
-
[53]
Residual dynamics resolves recurrent contributions to neural computation.Nature Neuroscience, 26(2):326–338, 2023
Aniruddh R Galgali, Maneesh Sahani, and Valerio Mante. Residual dynamics resolves recurrent contributions to neural computation.Nature Neuroscience, 26(2):326–338, 2023
2023
-
[54]
Neural dynamics outside task-coding dimensions drive decision trajectories through transient amplifi- cation.bioRxiv, pages 2025–11, 2025
Ulises Pereira-Obilinovic, Kayvon Daie, Susu Chen, Karel Svoboda, and Ran Darshan. Neural dynamics outside task-coding dimensions drive decision trajectories through transient amplifi- cation.bioRxiv, pages 2025–11, 2025
2025
-
[55]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
A Paszke. Pytorch: An imperative style, high-performance deep learning library.arXiv preprint arXiv:1912.01703, 2019. 13 Appendix The appendix is organized as follows: • Section A– Full derivation of the linear rank-1 RNN: reduced activity dynamics, overlap learning dynamics, filter task and training details, gradient-flow invariants, and experiments usin...
work page internal anchor Pith review arXiv 1912
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.