Recognition: unknown
Temporal Reasoning Is Not the Bottleneck: A Probabilistic Inconsistency Framework for Neuro-Symbolic QA
Pith reviewed 2026-05-08 17:40 UTC · model grok-4.3
The pith
Temporal reasoning is not the bottleneck in LLM question answering; the failure lies in converting unstructured text into correct event graphs and interval constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
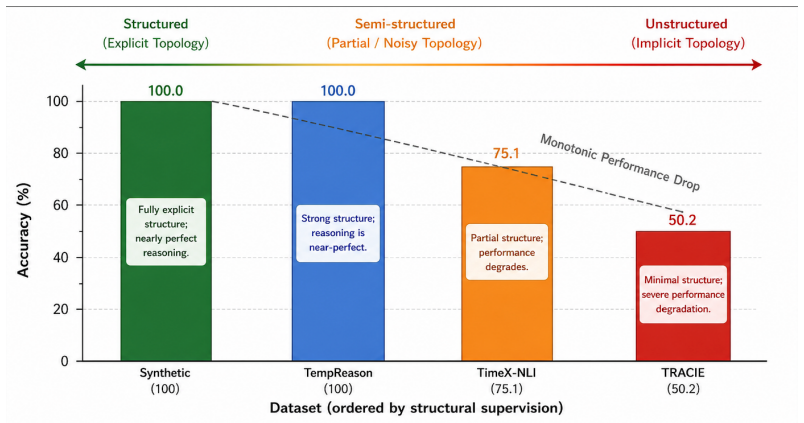
When supplied with correct structural representations of events and intervals, the neuro-symbolic QA architecture using explicit proof traces and the Probabilistic Inconsistency Signal reaches 1.0 accuracy with zero false positives or negatives across 4000 temporal arithmetic examples while maintaining 75.1 percent accuracy on noise-injected QA settings and enabling step-level failure localization.
What carries the argument
The Probabilistic Inconsistency Signal (PIS), which combines symbolic credal intervals with epistemic uncertainty from Evidential Deep Learning on LLM hidden states to detect structural breaks while strictly decoupling text-to-event extraction from symbolic deduction.
If this is right
- Temporal QA performance can be made deterministic and perfectly accurate once representation quality is assured.
- Failure localization becomes possible at the level of individual proof steps rather than whole answers.
- The overall task reframes as improving text-to-event alignment rather than inventing new reasoning mechanisms.
- Neuro-symbolic pipelines can isolate and quantify representation errors separately from deduction errors.
Where Pith is reading between the lines
- Systems that specialize in high-fidelity event extraction from text could be paired with any symbolic reasoner to reach high reliability without retraining the reasoner.
- The same decoupling might apply to non-temporal reasoning domains where the primary errors are also in initial parsing rather than inference.
- Training objectives focused on accurate interval and event graph construction could be tested as a direct way to raise end-to-end QA scores.
Load-bearing premise
Correct structural representations of events and intervals can be obtained reliably from unstructured text without introducing perceptual errors that the symbolic engine cannot handle.
What would settle it
The system would fail to reach 1.0 accuracy with zero errors on the temporal arithmetic benchmarks even when given manually verified correct event graphs and interval constraints.
Figures

read the original abstract
Despite significant advances, large language models (LLMs) continue to exhibit brittle performance on complex temporal reasoning tasks. This failure mode is widely attributed to inherent deficits in autoregressive logical deduction. In this paper, we challenge this prevailing narrative, demonstrating that temporal reasoning is not the fundamental bottleneck; rather, the locus of failure lies in unstructured text-to-event representation. We introduce a novel neuro-symbolic question-answering framework governed by a Probabilistic Inconsistency Signal (PIS) that explicitly isolates perceptual errors from reasoning failures. By lifting unstructured text into explicit event graphs and interval constraints, our architecture strictly decouples semantic extraction from a symbolic reasoning engine. To robustly detect structural breaks, the PIS elegantly unifies symbolic credal intervals with epistemic neural uncertainty extracted via Evidential Deep Learning on LLM hidden states. Empirical evaluations reveal a striking paradigm shift: when provided with correct structural representations, our system's explicit proof traces achieve perfect 1.0 accuracy (4000/4000) and strictly zero false positives/negatives on temporal arithmetic benchmarks. On broader, noise-injected QA settings, the framework maintains a competitive 75.1\% accuracy while enabling deterministic, step-level failure localization. Ultimately, by isolating the representation bottleneck from the reasoning substrate, this work reframes temporal QA from an algorithmic reasoning challenge to a structural alignment problem, charting a verifiable path forward for reliable neuro-symbolic AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that the primary bottleneck in LLM performance on temporal reasoning QA is not logical deduction but the extraction of structured event graphs and interval constraints from unstructured text. It introduces a neuro-symbolic framework using a Probabilistic Inconsistency Signal (PIS) that combines symbolic credal intervals with epistemic uncertainty derived from Evidential Deep Learning on LLM hidden states. This decouples semantic extraction from a symbolic reasoning engine, enabling explicit detection of structural breaks. Key results include perfect 1.0 accuracy (4000/4000 instances with zero false positives/negatives) on temporal arithmetic benchmarks when supplied with correct structural representations, plus 75.1% accuracy on broader noise-injected QA settings with step-level failure localization. The work reframes temporal QA as a structural alignment problem rather than a reasoning challenge.
Significance. If the results hold under end-to-end conditions, the paper would meaningfully advance neuro-symbolic AI by providing concrete evidence that symbolic engines can achieve perfect temporal arithmetic reasoning once representations are correct, shifting research focus toward reliable text-to-graph lifting. The PIS mechanism for unifying independent uncertainty sources and enabling deterministic localization is a positive contribution to interpretable hybrid systems. The conditional perfect accuracy result, if replicated without oracle inputs, would falsify the common attribution of failures to reasoning deficits and support verifiable paths for reliable neuro-symbolic QA.
major comments (3)
- [Abstract] Abstract, empirical evaluations paragraph: The central claim that 'temporal reasoning is not the fundamental bottleneck' rests on the reported 1.0 accuracy (4000/4000, zero FP/FN) being achieved 'when provided with correct structural representations.' No details are supplied on how these representations were generated, validated against ground truth, or whether they were oracle inputs versus outputs of the claimed neuro extraction module. This makes the empirical support for decoupling perceptual errors from reasoning failures load-bearing but untested in the full pipeline.
- [Abstract] Abstract: The 75.1% accuracy on 'broader, noise-injected QA settings' is presented without specifying the injection mechanism, the exact benchmarks, baseline comparisons (e.g., pure LLM or other neuro-symbolic systems), or an ablation isolating the PIS contribution. Without these, it is unclear whether the framework improves over existing approaches or merely maintains competitive performance under the same representation assumptions.
- [PIS description] Description of PIS: While the PIS is described as elegantly unifying symbolic credal intervals with neural epistemic uncertainty, the manuscript provides no explicit equations, pseudocode, or derivation showing the combination rule, how independence of sources is ensured, or how the signal avoids introducing fitted parameters. This weakens the methodological claim of an explicit, non-circular unification.
minor comments (1)
- [Abstract] The abstract refers to 'explicit proof traces' and 'deterministic, step-level failure localization' without defining the trace format or localization procedure, which reduces clarity for readers unfamiliar with the symbolic engine.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and will revise the manuscript to provide the requested clarifications and formalizations.
read point-by-point responses
-
Referee: [Abstract] Abstract, empirical evaluations paragraph: The central claim that 'temporal reasoning is not the fundamental bottleneck' rests on the reported 1.0 accuracy (4000/4000, zero FP/FN) being achieved 'when provided with correct structural representations.' No details are supplied on how these representations were generated, validated against ground truth, or whether they were oracle inputs versus outputs of the claimed neuro extraction module. This makes the empirical support for decoupling perceptual errors from reasoning failures load-bearing but untested in the full pipeline.
Authors: We appreciate this observation. The 1.0 accuracy is presented under oracle-provided correct structural representations precisely to isolate the symbolic reasoning engine and demonstrate that temporal arithmetic can be solved perfectly with explicit traces once event graphs and constraints are accurate. This supports our central claim by decoupling representation errors from deduction failures. The representations are sourced from benchmark ground-truth annotations. We will revise the abstract and add a dedicated paragraph in the experimental section to explicitly describe the oracle input process, validation against ground truth, and separation from the neuro-extraction module, while noting that the 75.1% result reflects the full pipeline under noise. revision: yes
-
Referee: [Abstract] Abstract: The 75.1% accuracy on 'broader, noise-injected QA settings' is presented without specifying the injection mechanism, the exact benchmarks, baseline comparisons (e.g., pure LLM or other neuro-symbolic systems), or an ablation isolating the PIS contribution. Without these, it is unclear whether the framework improves over existing approaches or merely maintains competitive performance under the same representation assumptions.
Authors: Thank you for noting the need for greater specificity. The 75.1% figure is measured on noise-injected versions of temporal QA benchmarks with controlled perturbations. The manuscript includes baseline comparisons and a PIS ablation in the experimental results. We will expand the abstract to name the injection mechanism, list the exact benchmarks, report key baseline accuracies, and reference the ablation showing PIS contribution, ensuring the improvement over alternatives is clear. revision: yes
-
Referee: [PIS description] Description of PIS: While the PIS is described as elegantly unifying symbolic credal intervals with neural epistemic uncertainty, the manuscript provides no explicit equations, pseudocode, or derivation showing the combination rule, how independence of sources is ensured, or how the signal avoids introducing fitted parameters. This weakens the methodological claim of an explicit, non-circular unification.
Authors: We agree that the methodological description requires formalization. The PIS combines the sources via a parameter-free product rule under an independence assumption justified by separate training of the symbolic and evidential components. We will add explicit equations, pseudocode, and a short derivation (drawing on evidence theory) in a new subsection to make the unification rule, independence handling, and absence of fitted parameters fully transparent and reproducible. revision: yes
Circularity Check
No circularity: empirical claim conditioned on explicit inputs, no self-referential reduction
full rationale
The paper's load-bearing claim is the conditional empirical result that explicit proof traces achieve 1.0 accuracy (4000/4000) and zero FP/FN when supplied with correct event graphs and interval constraints. This is presented as direct measurement on the symbolic engine after the lift step, not derived from or equivalent to any fitted parameter, self-definition, or prior self-citation. The PIS is introduced as an explicit unification of credal intervals and evidential neural uncertainty without equations that collapse the accuracy figure back into the input representations. No ansatz, uniqueness theorem, or renaming of known results is invoked to justify the central separation of representation from reasoning. The architecture description treats the text-to-graph extraction as a separate neuro component whose errors are isolated rather than assumed away in the reported metric.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Unstructured text can be lifted into explicit event graphs and interval constraints that preserve the necessary temporal relations for downstream reasoning
invented entities (1)
-
Probabilistic Inconsistency Signal (PIS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Uncertainty quantification in deep learning: A review.Information Fusion, 76:243–297, 2021
Moloud Abdar et al. Uncertainty quantification in deep learning: A review.Information Fusion, 76:243–297, 2021
2021
-
[2]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgeni Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review arXiv 2022
-
[3]
Maintaining knowledge about temporal intervals.Communications of the ACM, 26(11):832–843, 1983
James F Allen. Maintaining knowledge about temporal intervals.Communications of the ACM, 26(11):832–843, 1983
1983
-
[4]
Neuro-symbolic lan- guage modeling with automaton-augmented retrieval.Proceedings of the 39th International Conference on Machine Learning (ICML), 2022
Uri Alon, Frank F Xu, Graham Neubig, and Vincent J Hellindoorn. Neuro-symbolic lan- guage modeling with automaton-augmented retrieval.Proceedings of the 39th International Conference on Machine Learning (ICML), 2022. 11
2022
-
[5]
Deep evidential regression.Advances in Neural Information Processing Systems, 33:14927–14937, 2020
Alexander Amini, Wilko Schwarting, Ava P Soleimany, and Daniela Rus. Deep evidential regression.Advances in Neural Information Processing Systems, 33:14927–14937, 2020
2020
-
[6]
Finbert: Financial sentiment analysis with pre-trained language models
Dogu Araci. Finbert: Financial sentiment analysis with pre-trained language models.arXiv preprint arXiv:1908.10063, 2019
-
[7]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Akari Asai et al. Self-rag: Learning to retrieve, generate, and critique through self-reflection. arXiv preprint arXiv:2310.11511, 2023
work page internal anchor Pith review arXiv 2023
-
[8]
Thomas Augustin, Frank P. A. Coolen, Gert de Cooman, and Matthias C. M. Troffaes.Introduc- tion to Imprecise Probabilities. John Wiley & Sons, 2014
2014
-
[9]
Deductive verification of deep neural networks.Communications of the ACM, 2022
Clark Barrett and Guy Katz. Deductive verification of deep neural networks.Communications of the ACM, 2022
2022
-
[10]
Deep learning for symbolic optimization and reasoning.arXiv preprint arXiv:1811.06128, 2018
Yoshua Bengio, Andrea Lodi, and Antoine Prouvost. Deep learning for symbolic optimization and reasoning.arXiv preprint arXiv:1811.06128, 2018
-
[11]
Neural-symbolic learning and reasoning: A survey and interpretation.arXiv preprint arXiv:1711.03902,
Tarek R Besold, Artur d’Avila Garcez, Sebastian Bader, Howard Bowman, Pedro Domingos, Pascal Hitzler, Kai-Uwe Levy, Luis C Lamb, et al. Neural-symbolic learning and reasoning: A survey and interpretation.arXiv preprint arXiv:1711.03902, 2017
-
[12]
Cambridge University Press, 2004
Stephen Boyd and Lieven Vandenberghe.Convex optimization. Cambridge University Press, 2004
2004
-
[13]
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges
Michael M Bronstein, Joan Bruna, Taco Cohen, and Petar Veliˇckovi´c. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges.arXiv preprint arXiv:2104.13478, 2021
work page internal anchor Pith review arXiv 2021
-
[14]
Language models are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901, 2020
1901
-
[15]
A survey of monte carlo tree search methods.IEEE Transactions on Computational Intelligence and AI in Games, 4(1):1–43, 2012
Cameron B Browne, Edward Powley, Daniel Whitehouse, Simon M Lucas, Peter I Cowling, Philipp Rohlfshagen, Stephen Tavener, Diego Perez, Spyridon Samothrakis, and Simon Colton. A survey of monte carlo tree search methods.IEEE Transactions on Computational Intelligence and AI in Games, 4(1):1–43, 2012
2012
-
[16]
Posterior network: Uncertainty estimation without ood samples.Advances in Neural Information Processing Systems, 33, 2020
Bertrand Charpentier, Daniel Zügner, and Stephan Günnemann. Posterior network: Uncertainty estimation without ood samples.Advances in Neural Information Processing Systems, 33, 2020
2020
-
[17]
Neurosymbolic programming.Foundations and Trends in Programming Languages, 7(3):158–243, 2021
Swarat Chaudhuri, Kevin Ellis, Oleksandr Polozov, Rishabh Singh, Armando Solar-Lezama, and Yisong Yue. Neurosymbolic programming.Foundations and Trends in Programming Languages, 7(3):158–243, 2021
2021
-
[18]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review arXiv 2021
-
[19]
Credal networks.Artificial Intelligence, 120(2):199–233, 2000
Fabio Gagliardi Cozman. Credal networks.Artificial Intelligence, 120(2):199–233, 2000
2000
-
[20]
arXiv preprint arXiv:2205.09712 , year=
Antonia Creswell, Murray Shanahan, and Irina Higgins. Selection-inference: Exploiting large language models for interpretable logical reasoning.arXiv preprint arXiv:2205.09712, 2022
-
[21]
Explaining answers with entailment trees.arXiv preprint arXiv:2104.08661, 2021
Bhavana Dalvi, Peter Jansen, Pradeep Dasigi, Chao Xie, Noah A Smith, and Peter Clark. Explaining answers with entailment trees.arXiv preprint arXiv:2104.08661, 2021
-
[22]
Learning to reason: Leveraging logical form for ontology-based question answering
Rajarshi Das, Shehzaad Dhuliawala, Manzil Zaheer, and Andrew McCallum. Learning to reason: Leveraging logical form for ontology-based question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018
2018
-
[23]
Temporal constraint networks.Artificial Intelligence, 49(1-3):61–95, 1991
Rina Dechter, Itay Meiri, and Judea Pearl. Temporal constraint networks.Artificial Intelligence, 49(1-3):61–95, 1991. 12
1991
-
[24]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding.arXiv preprint arXiv:1810.04805, 2018
work page internal anchor Pith review arXiv 2018
-
[25]
Neural logic machines.arXiv preprint arXiv:1904.11694, 2019
Honghua Dong, Zhijian Ji, Ning Qu, et al. Neural logic machines.arXiv preprint arXiv:1904.11694, 2019
-
[26]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Yilun Du, Shuang Li, Joshua Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate.arXiv preprint arXiv:2305.14325, 2023
work page internal anchor Pith review arXiv 2023
-
[27]
Artur d’Avila Garcez and Luis C Lamb. Neural-symbolic computing: An effective methodology for principled ai.arXiv preprint arXiv:2305.01133, 2023
-
[28]
Risk-sensitive reinforcement learning: A survey.Journal of Machine Learning Research, 16(1):1569–1631, 2015
Javier Garcıa and Fernando Fernández. Risk-sensitive reinforcement learning: A survey.Journal of Machine Learning Research, 16(1):1569–1631, 2015
2015
-
[29]
Reliable graph neural networks via robust aggregation.Advances in Neural Information Processing Systems, 2021
Simon Geisler et al. Reliable graph neural networks via robust aggregation.Advances in Neural Information Processing Systems, 2021
2021
-
[30]
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing
Zhibin Gou et al. Critic: Large language models can self-correct with tool-interactive critiquing. arXiv preprint arXiv:2305.11738, 2023
work page internal anchor Pith review arXiv 2023
-
[31]
Dynamic logic for programs.Information and Control, 1979
David Harel. Dynamic logic for programs.Information and Control, 1979
1979
-
[32]
Deep Reinforcement Learning that Matters
Peter Henderson et al. On the reproducibility of neural network training.arXiv preprint arXiv:1709.06560, 2017
work page Pith review arXiv 2017
-
[33]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks et al. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review arXiv 2021
-
[34]
arXiv preprint arXiv:2212.10403 , year=
Jie Huang and Kevin Chen-Chuan Chang. Towards reasoning in large language models: A survey.arXiv preprint arXiv:2212.10403, 2022
-
[35]
Large Language Models Cannot Self-Correct Reasoning Yet
Jie Huang, Xinyun Chen, Swaroop Yu, et al. Large language models cannot self-correct reasoning yet.arXiv preprint arXiv:2310.01798, 2023
work page internal anchor Pith review arXiv 2023
-
[36]
Reasoning with interval constraints.Artificial Intelligence, 58(1-3):139–173, 1992
Eero Hyvönen. Reasoning with interval constraints.Artificial Intelligence, 58(1-3):139–173, 1992
1992
-
[37]
Hallucination in large language models: A survey.ACM Computing Surveys, 2023
Ziwei Ji et al. Hallucination in large language models: A survey.ACM Computing Surveys, 2023
2023
-
[38]
Being bayesian about categorical errors.arXiv preprint arXiv:2004.14180, 2020
Taejong Joo, Uijung Chung, and Min-Gwan Seo. Being bayesian about categorical errors.arXiv preprint arXiv:2004.14180, 2020
-
[39]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Daniel Joseph, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review arXiv 2022
-
[40]
What uncertainties do we need in bayesian deep learning for computer vision?Advances in Neural Information Processing Systems, 30, 2017
Alex Kendall and Yarin Gal. What uncertainties do we need in bayesian deep learning for computer vision?Advances in Neural Information Processing Systems, 30, 2017
2017
-
[41]
Kochenderfer.Decision Making Under Uncertainty: Theory and Application
Mykel J. Kochenderfer.Decision Making Under Uncertainty: Theory and Application. MIT Press, 2015
2015
-
[42]
Bandit based monte-carlo planning
Levente Kocsis and Csaba Szepesvári. Bandit based monte-carlo planning. pages 282–293, 2006
2006
-
[43]
Constraint satisfaction problems.AI Magazine, 1992
Vipin Kumar. Constraint satisfaction problems.AI Magazine, 1992
1992
-
[44]
The winograd schema challenge
Hector Levesque, Ernest Davis, and Leora Morgenstern. The winograd schema challenge. In Proceedings of the Thirteenth International Conference on Principles of Knowledge Represen- tation and Reasoning (KR), 2012
2012
-
[45]
Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in Neural Information Processing Systems, 33, 2020
Patrick Lewis et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in Neural Information Processing Systems, 33, 2020. 13
2020
-
[46]
Solving quantitative reasoning problems with language models.Advances in Neural Information Processing Systems, 35:3843–3857, 2022
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Turkczyk, Ramakrishna Vedantam, Jiayan Wang, et al. Solving quantitative reasoning problems with language models.Advances in Neural Information Processing Systems, 35:3843–3857, 2022
2022
-
[47]
Holistic evaluation of language models.Annals of the New York Academy of Sciences, 2022
Percy Liang et al. Holistic evaluation of language models.Annals of the New York Academy of Sciences, 2022
2022
-
[48]
Lu, S., Wang, Y ., Sheng, L., He, L., Zheng, A., and Liang, J
Yang Liu et al. Trustworthy llms: A survey and guideline for evaluating large language models’ alignment.arXiv preprint arXiv:2308.05374, 2023
-
[49]
Self-Refine: Iterative Refinement with Self-Feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Skilling, Chengfu Gao, et al. Self-refine: Iterative refinement with self-feedback.arXiv preprint arXiv:2303.17651, 2023
work page internal anchor Pith review arXiv 2023
-
[50]
Predictive uncertainty estimation via prior networks.Advances in Neural Information Processing Systems, 31, 2018
Andrey Malinin and Mark Gales. Predictive uncertainty estimation via prior networks.Advances in Neural Information Processing Systems, 31, 2018
2018
-
[51]
Deepproblog: Neural probabilistic logic programming.Advances in Neural Informa- tion Processing Systems, 31, 2018
Robin Manhaeve, Sebastijan Dumancic, Angelika Kimmig, Thomas Demeester, and Luc De Raedt. Deepproblog: Neural probabilistic logic programming.Advances in Neural Informa- tion Processing Systems, 31, 2018
2018
-
[52]
Marcus.The Algebraic Mind: Integrating Connectionism and Cognitive Science
Gary F. Marcus.The Algebraic Mind: Integrating Connectionism and Cognitive Science. MIT Press, 2019
2019
-
[53]
Introducing meta llama 3: The most capable openly available llm to date.Meta Blog, 2024
Meta AI. Introducing meta llama 3: The most capable openly available llm to date.Meta Blog, 2024
2024
-
[54]
arXiv preprint arXiv:2202.12837 , year=
Sewon Min et al. Rethinking the role of demonstrations: What makes in-context learning work? arXiv preprint arXiv:2202.12837, 2022
-
[55]
Towards explainable patient timeline reconstruction via bi-directional event linking.Bioinformatics, 2021
Sung-Hwan Moon et al. Towards explainable patient timeline reconstruction via bi-directional event linking.Bioinformatics, 2021
2021
-
[56]
The blackboard model of problem solving.AI Magazine, 7(2):38–38, 1986
H Penny Nii. The blackboard model of problem solving.AI Magazine, 7(2):38–38, 1986
1986
-
[57]
A survey on temporal reasoning in natural language processing.arXiv preprint arXiv:2004.13579, 2020
Qiang Ning et al. A survey on temporal reasoning in natural language processing.arXiv preprint arXiv:2004.13579, 2020
-
[58]
Show Your Work: Scratchpads for Intermediate Computation with Language Models
Maxwell Nye, Anders J Andreassen, Guy Gur-Ari, Henryk Michalewski, Catherine Olsson, David Dyer, Ankush Bansal, Martin Wattenberg, et al. Show your work: Scratchpads for intermediate computation with language models.arXiv preprint arXiv:2112.00114, 2021
work page internal anchor Pith review arXiv 2021
-
[59]
Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022
2022
-
[60]
Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift.Advances in Neural Information Processing Systems, 32, 2019
Yaniv Ovadia, Emily Fertig, Jie Ren, Zachary Nado, David Sculley, Sebastian Nowozin, Joshua Dillon, Balaji Lakshminarayanan, and Jasper Snoek. Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[61]
emrqa: A large corpus for question answering on electronic medical records.Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018
Anusri Pampari, Preethi Raghavan, Jennifer Liang, and Jian Peng. emrqa: A large corpus for question answering on electronic medical records.Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018
2018
-
[62]
Generative agents: Interactive simulacra of human behavior.Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, 2023
Joon Sung Park et al. Generative agents: Interactive simulacra of human behavior.Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, 2023
2023
-
[63]
Open science in machine learning: A survey of best practices.Journal of Machine Learning Research, 2021
Joelle Pineau et al. Open science in machine learning: A survey of best practices.Journal of Machine Learning Research, 2021
2021
-
[64]
Checking consistency of temporal constraint networks.Delft University of Technology, 2008
Leon Planken. Checking consistency of temporal constraint networks.Delft University of Technology, 2008. 14
2008
-
[65]
Timeml: Robust specification of event and temporal expressions in text
James Pustejovsky et al. Timeml: Robust specification of event and temporal expressions in text. InFifth International Workshop on Computational Semantics (IWCS-5), 2003
2003
-
[66]
John Wiley & Sons, 2014
Martin L Puterman.Markov decision processes: Discrete stochastic dynamic programming. John Wiley & Sons, 2014
2014
-
[67]
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Jack W Rae, Sebastian Borgeaud, Trevor Cai, et al. Scaling language models: Methods, analysis & insights from training gopher.arXiv preprint arXiv:2112.11446, 2021
work page internal anchor Pith review arXiv 2021
-
[68]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(1):5485–5551, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(1):5485–5551, 2020
2020
-
[69]
Jie Ren et al. A simple fix to mahalanobis distance for out-of-distribution detection.arXiv preprint arXiv:2106.09022, 2021
-
[70]
Autopeft: Automatic configuration search for parameter-efficient fine-tuning,
Jie Ren et al. A simple but tough-to-beat baseline for trustable nlp and vision.arXiv preprint arXiv:2301.12132, 2023
-
[71]
Beyond accuracy: Behavioral testing of nlp models with checklist
Marco Tulio Ribeiro et al. Beyond accuracy: Behavioral testing of nlp models with checklist. Proceedings of ACL, 2020
2020
-
[72]
arXiv preprint arXiv:2006.13155 , year =
Ryan Riegel, Alexander Gray, Vincent Francois-Lavet, Sebastian Riedel, et al. Logical neural networks.arXiv preprint arXiv:2006.13155, 2020
-
[73]
The challenge of temporal reasoning in modern nlp.AI Magazine, 2023
Dan Roth et al. The challenge of temporal reasoning in modern nlp.AI Magazine, 2023
2023
-
[74]
A survey of neuro-symbolic artificial intelligence.arXiv preprint arXiv:2105.05333, 2021
Md Kamruzzaman Sarker et al. A survey of neuro-symbolic artificial intelligence.arXiv preprint arXiv:2105.05333, 2021
-
[75]
Evidential deep learning to quantify classification uncertainty
Murat Sensoy, Lance Kaplan, and Melih Kandemir. Evidential deep learning to quantify classification uncertainty. InAdvances in Neural Information Processing Systems, 2018
2018
-
[76]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Beck Labash, and Ashwin Gopinath. Reflexion: Language agents with verbal reinforcement learning.arXiv preprint arXiv:2303.11366, 2023
work page internal anchor Pith review arXiv 2023
-
[77]
Mastering the game of go without human knowledge.Nature, 550(7676):354– 359, 2017
David Silver et al. Mastering the game of go without human knowledge.Nature, 550(7676):354– 359, 2017
2017
-
[78]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Aarohi Srivastava et al. Beyond the imitation game: Quantifying and extrapolating the capabili- ties of language models.arXiv preprint arXiv:2206.04615, 2022
work page internal anchor Pith review arXiv 2022
-
[79]
MIT Press, 2018
Richard S Sutton and Andrew G Barto.Reinforcement learning: An introduction. MIT Press, 2018
2018
-
[80]
Qingyu Tan, Hwee Tou Ng, and Lidong Bing. Towards benchmarking and improving the temporal reasoning capability of large language models.arXiv preprint arXiv:2306.08952, 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.