Recognition: unknown
Root-Cause-Driven Automated Vulnerability Repair
Pith reviewed 2026-05-08 17:25 UTC · model grok-4.3
The pith
Kumushi directs LLM repair agents to root causes of vulnerabilities rather than symptoms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By combining diversified dynamic fault localization with evidence-weighted ranking, Kumushi produces more root-cause fixes and fewer superficial patches than prior agents on 178 C/C++ vulnerabilities, matches frontier commercial performance, and is preferred by experts in pairwise comparisons.
What carries the argument
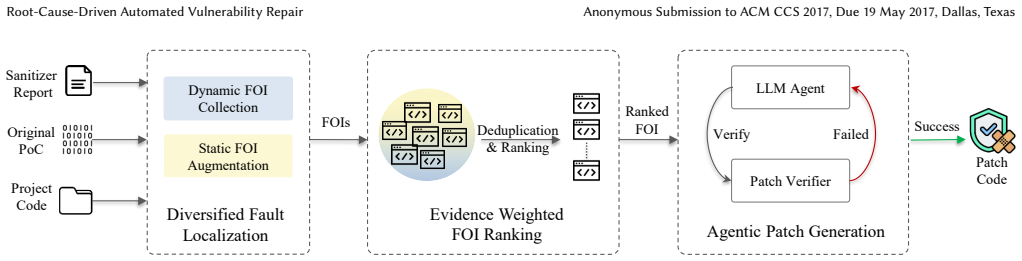
Diversified dynamic fault localization paired with evidence-weighted ranking, which narrows the LLM's attention to code locations most relevant to the defect origin.
If this is right
- Root-cause localization improves patch quality beyond what test-passing oracles can detect.
- Expert assessment uncovers differences in repair depth that automated metrics miss.
- Automated vulnerability repair benefits from richer signals about defect location rather than broader context alone.
- Matching commercial agents on root-cause quality is achievable with targeted localization techniques.
Where Pith is reading between the lines
- The same localization-plus-ranking approach could extend to non-security bugs where symptom fixes are common.
- If the two-tier metric is adopted more widely, future repair papers would need to report both oracle and expert results to claim superiority.
- Combining Kumushi's fault localization with static analysis tools might further reduce the context noise for the LLM.
Load-bearing premise
Expert human judgment can reliably separate root-cause fixes from superficial symptom patches, and the 178 vulnerabilities form a representative sample without selection bias.
What would settle it
Independent developer teams, blind to patch origin, rate a new set of Kumushi versus baseline patches and produce the same preference distribution for root-cause quality.
Figures


read the original abstract
Recent LLM-based systems have made automated vulnerability repair increasingly practical, but two challenges remain. First, without strong signals about where a bug originates, repair agents drift toward shallow edits that silence the observed failure while leaving the underlying defect unresolved. Second, finding the root cause for bugs is hard: even developers familiar with the codebase frequently produce fixes that address symptoms rather than the root cause, and LLM-based agents, operating with noisier context and less program understanding, are no exception. We present Kumushi, a root-cause-driven patching agent that addresses both challenges by combining diversified dynamic fault localization with evidence-weighted ranking to focus the LLM on the code most relevant to the defect. To rigorously measure whether Kumushi produces genuinely better patches, we also introduce a two-tier patch quality metric that pairs automated oracle validation with structured expert assessment of patches. Evaluated on 178 C/C++ vulnerabilities, Kumushi substantially outperforms prior specialized repair agents under automated evaluation while matching a frontier commercial coding agent. Expert assessment then reveals differences that oracles cannot: Kumushi produces more root-cause fixes and fewer superficial patches, and is preferred in the majority of decisive pairwise comparisons. Together, these results demonstrate that progress in automated vulnerability repair requires not only stronger patching systems, but also richer evaluation methods capable of distinguishing genuine fixes from oracle-passing ones.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Kumushi, an LLM-based automated vulnerability repair agent that combines diversified dynamic fault localization with evidence-weighted ranking to direct repairs toward root causes rather than superficial symptom fixes. It introduces a two-tier patch quality metric consisting of automated oracle validation paired with structured expert assessment. On a dataset of 178 C/C++ vulnerabilities, Kumushi is reported to outperform prior specialized repair agents under automated evaluation, match a frontier commercial coding agent, produce more root-cause fixes and fewer superficial patches per expert judgment, and win the majority of decisive pairwise expert comparisons.
Significance. If the central claims hold after addressing the noted gaps, the work would meaningfully advance automated vulnerability repair by demonstrating that root-cause signals improve patch quality beyond what oracles alone can detect, while also advancing evaluation methodology through the two-tier metric. The emphasis on distinguishing genuine fixes from oracle-passing edits addresses a recognized limitation in the field and could influence both system design and benchmarking practices.
major comments (2)
- [two-tier patch quality metric] Description of the two-tier patch quality metric (expert tier): The manuscript provides no details on the structured expert assessment protocol, including explicit criteria for classifying a patch as addressing the root cause versus a superficial edit, whether experts were blinded to patch origin, the number of raters, or any measure of inter-rater agreement (e.g., Cohen's kappa or Fleiss' kappa). Because the paper itself states that automated oracles are insufficient to separate these cases, the headline result that Kumushi produces more root-cause fixes and wins pairwise comparisons rests on this unverified expert layer and cannot be fully assessed from the provided information.
- [Evaluation] Evaluation on 178 vulnerabilities: The abstract and results claim clear outperformance and expert preference, yet no information is given on statistical significance tests for the reported differences, the precise baseline implementations and versions used, or the rules for including/excluding vulnerabilities from the 178-sample set. These omissions directly affect the verifiability of the central claim that Kumushi yields superior root-cause repairs.
minor comments (2)
- [Abstract] The abstract states that Kumushi 'substantially outperforms prior specialized repair agents' but does not include any quantitative deltas or specific metrics; adding one or two key numbers would improve immediate readability.
- [Evaluation] The paper would benefit from a brief discussion of potential selection bias in the 178-vulnerability corpus and how it relates to the representativeness of the expert preference results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments correctly identify areas where additional methodological transparency will strengthen the paper. We address each major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [two-tier patch quality metric] Description of the two-tier patch quality metric (expert tier): The manuscript provides no details on the structured expert assessment protocol, including explicit criteria for classifying a patch as addressing the root cause versus a superficial edit, whether experts were blinded to patch origin, the number of raters, or any measure of inter-rater agreement (e.g., Cohen's kappa or Fleiss' kappa). Because the paper itself states that automated oracles are insufficient to separate these cases, the headline result that Kumushi produces more root-cause fixes and wins pairwise comparisons rests on this unverified expert layer and cannot be fully assessed from the provided information.
Authors: We agree that the current manuscript lacks sufficient detail on the expert assessment protocol, which limits verifiability of the root-cause claims. In the revised version we will add a dedicated subsection (under Evaluation Methodology) that specifies: the explicit criteria experts used to classify patches as root-cause versus superficial; the blinding procedure (experts received only the vulnerable code, the patch, and the failing test, without origin labels); the number of raters (three security researchers with C/C++ experience); and inter-rater agreement (Fleiss' kappa). We will also report how disagreements were resolved. These additions directly address the referee's concern and allow readers to assess the reliability of the expert judgments. revision: yes
-
Referee: [Evaluation] Evaluation on 178 vulnerabilities: The abstract and results claim clear outperformance and expert preference, yet no information is given on statistical significance tests for the reported differences, the precise baseline implementations and versions used, or the rules for including/excluding vulnerabilities from the 178-sample set. These omissions directly affect the verifiability of the central claim that Kumushi yields superior root-cause repairs.
Authors: We acknowledge that the manuscript should have included these details for full reproducibility. In the revision we will expand the Evaluation Setup section to report: (1) statistical significance tests (McNemar's test for paired proportions and bootstrap confidence intervals) with p-values for all key differences; (2) exact baseline versions, repositories, and any configuration parameters used; and (3) the precise inclusion/exclusion criteria and data sources for the 178 vulnerabilities (a curated subset of public CVE and synthetic benchmarks with explicit filtering rules). These changes will make the comparative claims verifiable without altering the experimental results. revision: yes
Circularity Check
No circularity: empirical claims rest on independent oracles and expert judgment
full rationale
The paper is an empirical systems paper whose central claims (Kumushi yields more root-cause fixes and wins pairwise comparisons) are derived from evaluation on 178 vulnerabilities. This evaluation combines an automated oracle (external to the system) with structured expert assessment of patch quality. No equations, fitted parameters, or predictions are defined in terms of the target results. No self-citation chains or uniqueness theorems are invoked to justify the method or metric. The two-tier metric is presented as a new contribution but is not self-referential; expert judgment serves as an independent oracle rather than being constructed from the system's own outputs or prior self-citations. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rui Abreu, Peter Zoeteweij, Rob Golsteijn, and Arjan J. C. van Gemund. 2009. A practical evaluation of spectrum-based fault localization.J. Syst. Softw.82 (2009), 1780–1792
2009
-
[2]
anthropic. 2025. Effective context engineering for AI agents. https:// www.anthropic.com/engineering/effective-context-engineering-for-ai-agents. (2025). Accessed: 2026-04-20
2025
-
[3]
Anthropic. 2026. Claude Code. https://github.com/anthropics/claude-code. (2026). Accessed: 2026-03-31
2026
-
[4]
Anthropic. 2026. Project Glasswing. https://www .anthropic.com/glasswing. (2026)
2026
-
[5]
Tim Blazytko, Moritz Schlögel, Cornelius Aschermann, Ali Abbasi, Joel Frank, Simon Wörner, and Thorsten Holz. 2020. AURORA: statistical crash analysis for automated root cause explanation. InProceedings of the 29th USENIX Conference on Security Symposium (SEC’20). USENIX Association, USA, Article 14, 18 pages
2020
-
[6]
Tim Blazytko, Moritz Schlögel, Cornelius Aschermann, Ali Reza Abbasi, Joel Cameron Frank, Simon Wörner, and Thorsten Holz. 2020. AURORA: Statis- tical Crash Analysis for Automated Root Cause Explanation. InUSENIX Security Symposium
2020
-
[7]
Ted Byrt, Janet Bishop, and John B Carlin. 1993. Bias, prevalence and kappa. Journal of clinical epidemiology46, 5 (1993), 423–429
1993
-
[8]
Zimin Chen, Steve Kommrusch, and Monperrus Martin. 2022. Neural Transfer Learning for Repairing Security Vulnerabilities in C Code.IEEE Transactions on Software Engineering49 (2022), 147–165
2022
-
[9]
Jianlei Chi, YunHuan Qu, Ting Liu, Qinghua Zheng, and Heng Yin. 2022. Seq- Trans: Automatic Vulnerability Fix Via Sequence to Sequence Learning.IEEE Transactions on Software Engineering49 (2022), 564–585
2022
-
[10]
Tejinder Dhaliwal, Foutse Khomh, and Ying Zou. 2011. Classifying field crash reports for fixing bugs: A case study of Mozilla Firefox. InProceedings of the 2011 27th IEEE International Conference on Software Maintenance (ICSM ’11). IEEE Computer Society, USA, 333–342. https://doi.org/10.1109/ICSM.2011.6080800
-
[11]
Andrea Fioraldi, Dominik Maier, Heiko Eißfeldt, and Marc Heuse. 2020. AFL++: combining incremental steps of fuzzing research. InProceedings of the 14th USENIX Conference on Offensive Technologies (WOOT’20). USENIX Association, USA, Article 10, 1 pages
2020
-
[12]
Joseph L Fleiss. 1971. Measuring nominal scale agreement among many raters. Psychological bulletin76, 5 (1971), 378
1971
-
[13]
Phung, and Trung Le
Michael Fu, Van-Anh Nguyen, Chakkrit Kla Tantithamthavorn, Dinh Q. Phung, and Trung Le. 2024. Vision Transformer Inspired Automated Vulnerability Repair. ACM Transactions on Software Engineering and Methodology33 (2024), 1 – 29
2024
-
[14]
Michael Fu, Chakkrit Kla Tantithamthavorn, Trung Le, Van Nguyen, and Dinh Q. Phung. 2022. VulRepair: a T5-based automated software vulnerability repair. Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering(2022)
2022
-
[15]
Fengjuan Gao, Linzhang Wang, and Xuandong Li. 2016. BovInspector: Automatic inspection and repair of buffer overflow vulnerabilities.2016 31st IEEE/ACM International Conference on Automated Software Engineering (ASE)(2016), 786– 791
2016
-
[16]
Qing Gao, Yingfei Xiong, Yaqing Mi, Lu Zhang, Weikun Yang, Zhao fa Zhou, Bing Xie, and Hong Mei. 2015. Safe Memory-Leak -Fixing for C Programs.2015 IEEE/ACM 37th IEEE International Conference on Software Engineering1 (2015), 459–470
2015
-
[17]
Xiang Gao, Sergey Mechtaev, and Abhik Roychoudhury. 2019. Crash-avoiding program repair.Proceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis(2019)
2019
-
[18]
Xiang Gao, Bo Wang, Gregory J Duck, Ruyi Ji, Yingfei Xiong, and Abhik Roy- choudhury. 2021. Beyond tests: Program vulnerability repair via crash constraint extraction.ACM Transactions on Software Engineering and Methodology (TOSEM) 30, 2 (2021), 1–27
2021
-
[19]
Github. 2026. CodeQL. https://codeql .github.com/. (2026). Accessed: 2026-03-31
2026
-
[20]
google. 2026. Google OSS-Fuzz. https://github .com/google/oss-fuzz. (2026). Accessed: 2026-04-20
2026
-
[21]
Claire Le Goues, Thanhvu Nguyen, Stephanie Forrest, and Westley Weimer. 2012. GenProg: A Generic Method for Automatic Software Repair.IEEE Transactions on Software Engineering38 (2012), 54–72
2012
-
[22]
Harer, Onur Ozdemir, Tomo Lazovich, Christopher P
Jacob A. Harer, Onur Ozdemir, Tomo Lazovich, Christopher P. Reale, Rebecca L. Russell, Louis Y. Kim, and Peter Chin. 2018. Learning to Repair Software Vul- nerabilities with Generative Adversarial Networks.The Thirty-Second Annual Conference on Neural Information Processing Systems (NIPS)(2018)
2018
-
[23]
Seongjoon Hong, Junhee Lee, Jeongsoo Lee, and Hakjoo Oh. 2020. SAVER: Scal- able, Precise, and Safe Memory-Error Repair.2020 IEEE/ACM 42nd International Conference on Software Engineering (ICSE)(2020), 271–283
2020
-
[24]
Yiwei Hu, Zhen Li, Kedie Shu, Sheng Guan, Deqing Zou, Shouhuai Xu, Bin Yuan, and Hai Jin. 2025. SoK: Automated Vulnerability Repair: Methods, Tools, and Assessments. InUSENIX Security Symposium
2025
-
[25]
Zhen Huang, David Lie, Gang Tan, and Trent Jaeger. 2019. Using Safety Properties to Generate Vulnerability Patches.2019 IEEE Symposium on Security and Privacy (SP)(2019), 539–554
2019
-
[26]
Zhi Yu Jiang, Shuitao Gan, Adrián Herrera, Flavio Toffalini, Lucio Romerio, Chaojing Tang, Manuel Egele, Chao Zhang, and Mathias Payer. 2022. Evocatio: Conjuring Bug Capabilities from a Single PoC.Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security(2022)
2022
-
[27]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-World GitHub Issues?The Twelfth International Conference on Learning Representationsabs/2310.06770 (2024)
work page internal anchor Pith review arXiv 2024
-
[28]
Jones and Mary Jean Harrold
James A. Jones and Mary Jean Harrold. 2005. Empirical evaluation of the taran- tula automatic fault-localization technique.Proceedings of the 20th IEEE/ACM International Conference on Automated Software Engineering(2005)
2005
-
[29]
Dongsun Kim, Jaechang Nam, Jaewoo Song, and Sunghun Kim. 2013. Automatic patch generation learned from human-written patches.2013 35th International Conference on Software Engineering (ICSE)(2013), 802–811
2013
-
[30]
Youngjoon Kim, Sunguk Shin, Hyoungshick Kim, and J. Yoon. 2025. Logs In, Patches Out: Automated Vulnerability Repair via Tree-of-Thought LLM Analysis. InUSENIX Security Symposium
2025
-
[31]
Hwiwon Lee, Ziqi Zhang, Hanxiao Lu, and Lingming Zhang. 2025. SEC-bench: Automated Benchmarking of LLM Agents on Real-World Software Security Tasks. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https://sec-bench.github.io/index.html
2025
-
[32]
Li and Vern Paxson
Frank H. Li and Vern Paxson. 2017. A Large-Scale Empirical Study of Security Patches.Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security(2017)
2017
-
[33]
Yeting Li, Yecheng Sun, Zhiwu Xu, Jialun Cao, Yuekang Li, Rongchen Li, Haiming Chen, Shing Chi Cheung, Yang Liu, and Yang Xiao. 2022. RegexScalpel: Regular Expression Denial of Service (ReDoS) Defense by Localize-and-Fix. InUSENIX Security Symposium. 13 Anonymous Submission to ACM CCS 2017, Due 19 May 2017, Dallas, Texas Hulin Wang, Zion Leonahenahe Basqu...
2022
-
[34]
Yu Nong, Haoran Yang, Long Cheng, Hongxin Hu, and Haipeng Cai. 2025. AP- PATCH: Automated Adaptive Prompting Large Language Models for Real-World Software Vulnerability Patching. InUSENIX Security Symposium
2025
-
[35]
NVD. 2026. CVE-2022-1286. https://nvd .nist.gov/vuln/detail/cve-2022-1286. (2026). Accessed: 2026-03-31
2026
-
[36]
nvd. 2026. national vulnerability database. https://nvd.nist.gov/. (2026). Accessed: 2026-04-20
2026
-
[37]
OpenAI. 2025. Codex. https://github .com/openai/codex. (2025). Accessed: 2026-03-31
2025
-
[38]
OpenAI. 2026. Introducing GPT-5.2. https://openai .com/index/introducing-gpt- 5-2/. (2026). Accessed: 2026-03-31
2026
-
[39]
OpenHands. 2026. OpenHands. https://github .com/OpenHands/OpenHands. (2026). Accessed: 2026-03-31
2026
- [40]
-
[41]
Younggi Park, Hwiwon Lee, Jinho Jung, Hyungjoon Koo, and Huy Kang Kim. 2024. Benzene: A Practical Root Cause Analysis System with an Under-Constrained State Mutation.2024 IEEE Symposium on Security and Privacy (SP)(2024), 1865– 1883
2024
-
[42]
Pearce, Benjamin Tan, Baleegh Ahmad, Ramesh Karri, and Bren- dan Dolan-Gavitt
Hammond A. Pearce, Benjamin Tan, Baleegh Ahmad, Ramesh Karri, and Bren- dan Dolan-Gavitt. 2023. Examining Zero-Shot Vulnerability Repair with Large Language Models.2023 IEEE Symposium on Security and Privacy (SP)(2023), 2339–2356
2023
-
[43]
2014.Probabilistic reasoning in intelligent systems: networks of plausi- ble inference
Judea Pearl. 2014.Probabilistic reasoning in intelligent systems: networks of plausi- ble inference. Elsevier
2014
-
[44]
Ridwan Shariffdeen, Yannic Noller, Lars Grunske, and Abhik Roychoudhury. 2021. Concolic program repair.Proceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation(2021)
2021
-
[45]
Yan Shoshitaishvili, Ruoyu Wang, Christopher Salls, Nick Stephens, Mario Polino, Audrey Dutcher, John Grosen, Siji Feng, Christophe Hauser, Christopher Kruegel, and Giovanni Vigna. 2016. SoK: (State of) The Art of War: Offensive Techniques in Binary Analysis. InIEEE Symposium on Security and Privacy
2016
-
[46]
McKinley, and Vitaly Shmatikov
Sooel Son, Kathryn S. McKinley, and Vitaly Shmatikov. 2013. Fix Me Up: Repairing Access-Control Bugs in Web Applications. InNetwork and Distributed System Security Symposium
2013
-
[47]
Yida Tao, Jindae Kim, Sunghun Kim, and Chang Xu. 2014. Automatically gen- erated patches as debugging aids: a human study.Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering(2014)
2014
-
[48]
Rijnard van Tonder and Claire Le Goues. 2018. Static Automated Program Repair for Heap Properties.2018 IEEE/ACM 40th International Conference on Software Engineering (ICSE)(2018), 151–162
2018
-
[49]
arXiv preprint arXiv:2109.00859 , year=
Yue Wang, Weishi Wang, Shafiq R. Joty, and Steven C. H. Hoi. 2021. CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Under- standing and Generation.ArXivabs/2109.00859 (2021)
-
[50]
Zhun Wang, Tianneng Shi, Jingxuan He, Matthew Cai, Jialin Zhang, and Dawn Song. 2026. CyberGym: Evaluating AI Agents’ Real-World Cybersecurity Capabil- ities at Scale.The Fourteenth International Conference on Learning Representations (2026)
2026
-
[51]
Haolai Wei, Liwei Chen, Zhijie Zhang, Gang Shi, and Dan Meng. 2024. Sleuth: A Switchable Dual-Mode Fuzzer to Investigate Bug Impacts Following a Single PoC. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA 2024). Association for Computing Machinery, New York, NY, USA, 730–742. https://doi.org/10.1145/36...
-
[52]
Xuezheng Xu, Yulei Sui, Hua Yan, and Jingling Xue. 2019. VFix: Value-Flow- Guided Precise Program Repair for Null Pointer Dereferences.2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE)(2019), 512–523
2019
-
[53]
Carter Yagemann, Simon Pak Ho Chung, Brendan Saltaformaggio, and Wenke Lee. 2021. Automated Bug Hunting With Data-Driven Symbolic Root Cause Analysis.Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security(2021)
2021
-
[54]
Carter Yagemann, Matthew Pruett, Simon Pak Ho Chung, Kennon Bittick, Bren- dan Saltaformaggio, and Wenke Lee. 2021. ARCUS: Symbolic Root Cause Analysis of Exploits in Production Systems. InUSENIX Security Symposium
2021
-
[55]
R.R. Yager. 1988. On ordered weighted averaging aggregation operators in multicriteria decisionmaking.IEEE Transactions on Systems, Man, and Cybernetics 18, 1 (1988), 183–190. https://doi.org/10.1109/21.87068
-
[56]
Zhenlei Ye, Xiaobing Sun, Sicong Cao, Lili Bo, and Bin Li. 2026. Well Begun is Half Done: Location-Aware and Trace-Guided Iterative Automated Vulnerability Repair.Proceedings of the IEEE/ACM 48th International Conference on Software Engineering(2026)
2026
-
[57]
Zheng Yu, Ziyi Guo, Yuhang Wu, Jiahao Yu, Meng Xu, Dongliang Mu, Yan Chen, and Xinyu Xing. 2025. PATCHAGENT: A Practical Program Repair Agent Mimicking Human Expertise. InUSENIX Security Symposium
2025
-
[58]
Zheng Yu, Wenxuan Shi, Xin Sun, Zheyun Feng, Meng Xu, and Xinyu Xing
-
[59]
https://arxiv .org/pdf/ 2603.06858
Patch Validation in Automated Vulnerability Repair. https://arxiv .org/pdf/ 2603.06858
-
[60]
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Reddy Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, Urmish Thakker, James Zou, and Kunle Olukotun. 2026. Agentic Context Engi- neering: Evolving Contexts for Self-Improving Language Models. InProceedings of the Fourteenth International Conference on Learning Repres...
2026
-
[61]
Duck, and Abhik Roychoudhury
Yuntong Zhang, Xiang Gao, Gregory J. Duck, and Abhik Roychoudhury. 2022. Program vulnerability repair via inductive inference.Proceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis(2022)
2022
-
[62]
Yuntong Zhang, Jiawei Wang, Dominic Berzin, Martin Mirchev, and Abhik Roy- choudhury. 2026. Fixing Security Vulnerabilities with Agentic AI in OSS-Fuzz. InProceedings of the 48th IEEE/ACM International Conference on Software Engi- neering: Software Engineering in Practice (ICSE-SEIP ’26). ACM, Rio de Janeiro, Brazil
2026
-
[63]
Xin Zhou, Kisub Kim, Bowen Xu, Donggyun Han, and David Lo. 2024. Out of Sight, Out of Mind: Better Automatic Vulnerability Repair by Broadening Input Ranges and Sources.2024 IEEE/ACM 46th International Conference on Software Engineering (ICSE)(2024), 1071–1083
2024
-
[64]
Aleksandr Zverianskii, Ashley Zhang, Jacob Clyne, Antía Garcia, Fazl Barez, and Shriyash Upadhyay. 2026. Code Review Bench. (2026). https://github .com/ withmartian/code-review-benchmark A Repair Strategies Definition The definition of root cause fix strategies is in Table 8. The definition of symptom fix strategies is in Table 9. B Benchmark Table 10 sho...
2026
-
[65]
These are the highest-confidence candidates -- they are directly on the crash path
**Stack Trace Analysis** (source: STACK_TRACE) -- Parses the ASAN/sanitizer crash report to extract the exact crash location and call stack. These are the highest-confidence candidates -- they are directly on the crash path
-
[66]
Functions are ranked by their distance from the crash site (closer = more relevant) and call frequency
**Dynamic Call Tracing** (source: CALL_TRACE) -- Instruments the binary and replays the crashing input to record every function called at runtime. Functions are ranked by their distance from the crash site (closer = more relevant) and call frequency
-
[67]
These may reveal upstream allocation, sizing, or validation functions that are the true root cause
**Static Variable Dependencies** (source: VAR_DEP) -- Performs static data-flow analysis to find functions that handle data flowing toward the crash location. These may reveal upstream allocation, sizing, or validation functions that are the true root cause
-
[68]
Each FOI (Function of Interest) cluster groups related functions from these analyses
**Fuzzing Coverage Analysis** (source: AURORA) -- Uses fuzzer corpus and crash coverage to score functions by how strongly their coverage correlates with crashes. Each FOI (Function of Interest) cluster groups related functions from these analyses. Clusters are ranked by a combination of how many independent analyses flagged them and the priority of those...
-
[69]
Use` get_rca_results(index)`to view source for any additional clusters listed compactly
**Study the RCA clusters**: The most relevant clusters are shown above with full source code -- review them first. Use` get_rca_results(index)`to view source for any additional clusters listed compactly. Pay attention to the source of each cluster -- clusters flagged by multiple analyses deserve extra attention
-
[70]
Identify the exact memory operation that fails and what value/pointer is invalid
**Understand the crash mechanism**: From the crash report, identify the bug type (buffer overflow, use-after-free, null dereference, etc.). Identify the exact memory operation that fails and what value/pointer is invalid
-
[71]
Use`read_source_file`to see surrounding context -- macros, struct definitions, buffer allocation sites, size computations
**Trace the call chain**: Use`view_function`to read each function in the crash stack -- it shows the function source, its callees, and global variables. Use`read_source_file`to see surrounding context -- macros, struct definitions, buffer allocation sites, size computations. Look ABOVE the crash function for where the faulty data originates. Also inspect ...
-
[72]
Use`list_functions_in_file`to see what else is defined in the same file
**Explore related code**: Use`search_functions`to find related functions by name pattern -- it also searches source file text when the function index has no match, so it can locate macros, struct definitions, and typedefs too. Use`list_functions_in_file`to see what else is defined in the same file. Use`read_source_file`to read struct definitions, macros, ...
-
[73]
**Form a concrete hypothesis**: Before editing, state clearly: - The bug type and the specific memory operation that fails - The exact data-flow path from allocation/input to the crash - Which function contains the root cause (may differ from crash location) - What the minimal fix is and WHY it addresses the root cause ### Phase 2: Implement the Fix
-
[74]
You may make multiple related edits before validating -- batch them together since validation is expensive (~30 seconds per attempt)
**Make all necessary edits**: Apply your fix using`edit_file`. You may make multiple related edits before validating -- batch them together since validation is expensive (~30 seconds per attempt)
-
[75]
PASS" = exit code 0 OR non-zero with no sanitizer errors = crash is fixed -
**Validate**: Call`validate_patch`to run build + crash reproduction + tests. ### Phase 3: Diagnose and Iterate (if validation fails) 17 Anonymous Submission to ACM CCS 2017, Due 19 May 2017, Dallas, Texas Hulin Wang, Zion Leonahenahe Basque, Jie Hu, Ati Priya Bajaj, Yibo Liu, Samuel Zhu, Giorgi Kobakhia, Nikhil Chapre, Will Rosenberg, Siddharth Mishra, Ad...
2017
-
[76]
For example, an OOM in a helper function may not set an error flag, so the caller continues with invalid state
**Fix error propagation / missing checks**: The bug often exists because an error condition is not properly propagated or handled. For example, an OOM in a helper function may not set an error flag, so the caller continues with invalid state. Fix the propagation chain so errors are caught and handled before they cause the crash
-
[77]
**Fix the logic that produces bad state**: Add missing validation, bounds checks, or null checks at the point where bad data is created or accepted -- not where it is consumed
-
[78]
This is the weakest fix -- it stops this specific crash but may leave the underlying bug exploitable through other code paths
**Harden the crash site (last resort)**: Only if you cannot identify the upstream root cause should you add a guard at the crash site. This is the weakest fix -- it stops this specific crash but may leave the underlying bug exploitable through other code paths. **Never** enlarge buffers, add padding, or use oversized sentinels as a fix strategy. These mas...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.