Recognition: unknown
NoisyCausal: A Benchmark for Evaluating Causal Reasoning Under Structured Noise
Pith reviewed 2026-05-08 16:47 UTC · model grok-4.3
The pith
Prompting large language models to extract and use an explicit causal graph from noisy text improves their causal reasoning accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
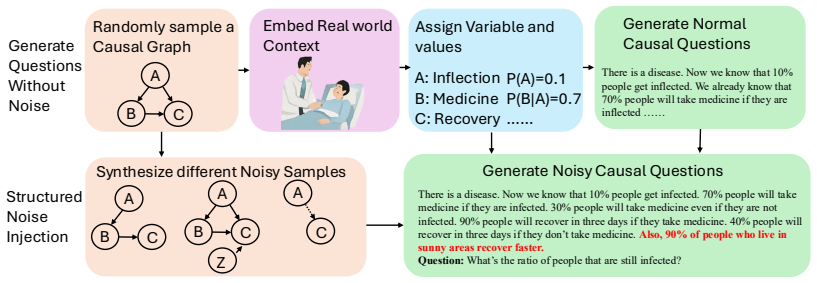
NoisyCausal generates test cases from ground-truth causal graphs and injects controllable noise including distractors, value perturbations, confounding, and partial observability. The proposed framework has the LLM extract variables and construct an explicit causal graph from the noisy context, then reformulates the reasoning task as a structured prompt grounded in that graph. This yields significantly higher accuracy than standard prompting or reasoning baselines on NoisyCausal and generalizes to external benchmarks such as Cladder without additional tuning.
What carries the argument
The modular reasoning framework that prompts an LLM to extract variables and build a causal graph from noisy text, then grounds all subsequent inference in the resulting symbolic structure.
If this is right
- LLMs achieve more reliable answers about interventions and effects once an explicit causal graph guides their reasoning.
- The same graph-guided prompting transfers to other causal reasoning benchmarks without task-specific tuning.
- Combining language-driven extraction with symbolic causal structure produces more interpretable and robust causal inferences than statistical patterns alone.
- Performance gains are largest precisely when noise types such as distractors or partial observability are present.
Where Pith is reading between the lines
- If the extracted graphs prove reliable on synthetic noise, the same pipeline could be tested on real-world texts from medicine or policy where causal claims must be separated from confounders.
- The approach suggests that future models may need an internal step that builds and maintains causal structure rather than relying solely on end-to-end pattern matching.
- Success on NoisyCausal implies that benchmarks focused only on clean text underestimate the value of explicit causal abstractions.
Load-bearing premise
That an LLM prompted to extract variables and construct a causal graph from noisy natural-language text will produce a sufficiently accurate graph to support the downstream reasoning step.
What would settle it
An experiment that measures the accuracy of the causal graphs the LLM extracts and checks whether reasoning performance drops sharply when those graphs contain errors or when graph extraction is disabled.
Figures


read the original abstract
Causal reasoning in natural language requires identifying relevant variables, understanding their interactions, and reasoning about effects and interventions, often under noisy or ambiguous conditions. While large language models (LLMs) exhibit strong general reasoning abilities, they struggle to disentangle correlation from causation, particularly when observations are partially incorrect or irrelevant information is present. In this work, we introduce NoisyCausal, a new benchmark designed to evaluate causal reasoning under structured noise. Each instance is generated from a ground-truth causal graph and contextualized with a natural language scenario by injecting controllable forms of noise, such as irrelevant distractors, value perturbations, confounding, and partial observability. Moreover, we propose a modular reasoning framework that combines LLMs with explicit causal structure to address these challenges. Our method prompts the LLM to extract variables, construct a causal graph from context, and then reformulates the reasoning task as a structured prompt grounded in this graph. Rather than relying on statistical patterns alone, the LLM is guided by symbolic structure, enabling more interpretable and robust inference. Experimental results show that our method significantly outperforms standard prompting and reasoning baselines on NoisyCausal. Furthermore, it generalizes well to external benchmarks such as Cladder without task-specific tuning. Our findings highlight the importance of combining causal abstractions with language-driven reasoning to achieve faithful and robust causal understanding in LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NoisyCausal, a benchmark for evaluating LLM causal reasoning under structured noise (irrelevant distractors, value perturbations, confounding, partial observability), with each instance generated from a ground-truth causal graph and natural-language scenario. It proposes a modular pipeline in which an LLM extracts variables, constructs an explicit causal graph from the noisy text, and then performs downstream reasoning grounded in that graph structure rather than relying solely on statistical patterns. The central empirical claims are that this approach significantly outperforms standard prompting and reasoning baselines on NoisyCausal and generalizes well to the external Cladder benchmark without task-specific tuning.
Significance. If the performance claims are substantiated, the work would be significant for providing a controlled benchmark that isolates causal reasoning challenges under noise and for demonstrating a hybrid LLM-plus-explicit-structure approach that could improve robustness and interpretability over pure prompting methods. The modular design and cross-benchmark generalization are potentially valuable contributions to the growing literature on causal capabilities in language models.
major comments (3)
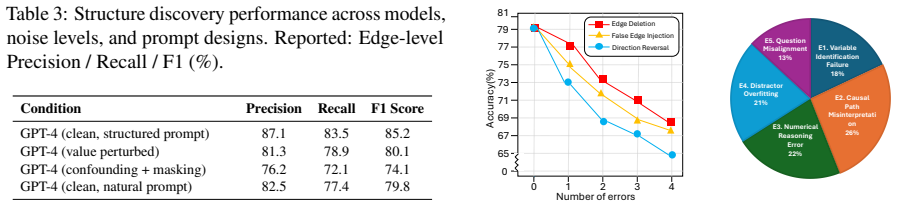
- [§4] §4 (Experiments) and Table 1 (main results): The paper reports significant outperformance of the proposed modular method over baselines, yet provides no quantitative metrics on the accuracy of the LLM's causal graph extraction step (e.g., edge precision, recall, or structural Hamming distance relative to the ground-truth graphs that generated each NoisyCausal instance). This is load-bearing for the central claim that gains arise from 'faithful and robust causal understanding' via explicit structure rather than from prompt formatting effects alone.
- [§4.2] §4.2 (Ablation studies): No ablation is presented that isolates the contribution of the graph-construction module (e.g., full pipeline vs. structured prompting without an explicit graph, or vs. a version that uses a random or noisy graph). Without this, it remains unclear whether the reported gains on NoisyCausal and Cladder are attributable to the causal abstraction or to other aspects of the prompting strategy.
- [§3] §3 (Method): The description of the graph-construction prompt does not specify how the LLM is instructed to handle cases of partial observability or conflicting information in the noisy text, nor does it report failure rates or fallback mechanisms; this directly affects the reliability of the downstream structured-reasoning step that the paper positions as its key advantage.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one or two key quantitative results (e.g., accuracy deltas or statistical significance) rather than the purely qualitative statement of 'significant outperformance.'
- [§2] Notation for the noise injection parameters (e.g., distractor rate, perturbation magnitude) is introduced in §2 but could be more consistently referenced in the experimental setup and tables.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects for strengthening the empirical support of our claims. We will revise the manuscript to incorporate additional analyses and clarifications as detailed below.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and Table 1 (main results): The paper reports significant outperformance of the proposed modular method over baselines, yet provides no quantitative metrics on the accuracy of the LLM's causal graph extraction step (e.g., edge precision, recall, or structural Hamming distance relative to the ground-truth graphs that generated each NoisyCausal instance). This is load-bearing for the central claim that gains arise from 'faithful and robust causal understanding' via explicit structure rather than from prompt formatting effects alone.
Authors: We agree that quantitative metrics on graph extraction accuracy are necessary to substantiate that performance improvements derive from explicit causal structure. In the revised manuscript, we will add these metrics (edge precision, recall, F1, and structural Hamming distance) computed against the ground-truth graphs for all NoisyCausal instances, presented in a new table within §4. revision: yes
-
Referee: [§4.2] §4.2 (Ablation studies): No ablation is presented that isolates the contribution of the graph-construction module (e.g., full pipeline vs. structured prompting without an explicit graph, or vs. a version that uses a random or noisy graph). Without this, it remains unclear whether the reported gains on NoisyCausal and Cladder are attributable to the causal abstraction or to other aspects of the prompting strategy.
Authors: We will expand §4.2 with the suggested ablations, including comparisons of the full pipeline to (i) structured prompting without explicit graph output, (ii) the pipeline using a random graph, and (iii) the pipeline using a noisy graph. Results will be reported on both NoisyCausal and Cladder to isolate the role of the graph-construction module. revision: yes
-
Referee: [§3] §3 (Method): The description of the graph-construction prompt does not specify how the LLM is instructed to handle cases of partial observability or conflicting information in the noisy text, nor does it report failure rates or fallback mechanisms; this directly affects the reliability of the downstream structured-reasoning step that the paper positions as its key advantage.
Authors: We will revise §3 to include the specific prompt instructions for handling partial observability and conflicting information, along with reported failure rates for graph extraction and any fallback mechanisms used in the pipeline. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external validation
full rationale
The paper introduces a new benchmark (NoisyCausal) generated from ground-truth causal graphs plus controllable noise, then evaluates a modular LLM pipeline that extracts variables/graphs and reasons over the explicit structure. Central claims are experimental outperformance versus baselines on NoisyCausal plus generalization to the external Cladder benchmark without task-specific tuning. No equations, fitted parameters, or derivations appear in the provided text. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The use of an independent external benchmark means the reported gains do not reduce to self-referential fitting or renaming of inputs. No step equates a claimed result to its construction by definition.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Ground-truth causal graphs can be turned into natural-language scenarios and then controllably corrupted while preserving the original causal structure for evaluation.
- domain assumption Prompting an LLM to list variables and draw causal links from noisy text yields a graph accurate enough to improve downstream inference.
Reference graph
Works this paper leans on
-
[1]
, author=
Choice of Plausible Alternatives: An Evaluation of Commonsense Causal Reasoning. , author=. AAAI spring symposium: logical formalizations of commonsense reasoning , pages=
-
[2]
arXiv preprint arXiv:1805.06939 , year=
Event2mind: Commonsense inference on events, intents, and reactions , author=. arXiv preprint arXiv:1805.06939 , year=
-
[3]
Proceedings of the 29th International Conference on Computational Linguistics , pages=
CausalQA: A benchmark for causal question answering , author=. Proceedings of the 29th International Conference on Computational Linguistics , pages=
-
[4]
Proceedings of the AAAI conference on artificial intelligence , volume=
Atomic: An atlas of machine commonsense for if-then reasoning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[5]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[6]
Journal of Machine Learning Research , volume=
Palm: Scaling language modeling with pathways , author=. Journal of Machine Learning Research , volume=
-
[7]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review arXiv
-
[8]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[9]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[10]
International Conference on Learning Representations (ICLR) , year=
React: Synergizing reasoning and acting in language models , author=. International Conference on Learning Representations (ICLR) , year=
-
[11]
arXiv preprint arXiv:2305.12295 , year=
Logic-lm: Empowering large language models with symbolic solvers for faithful logical reasoning , author=. arXiv preprint arXiv:2305.12295 , year=
-
[12]
Solving challenging math word problems using gpt-4 code interpreter with code-based self-verification , author=. arXiv preprint arXiv:2308.07921 , year=
-
[13]
arXiv preprint arXiv:2401.06201 , year=
Easytool: Enhancing llm-based agents with concise tool instruction , author=. arXiv preprint arXiv:2401.06201 , year=
-
[14]
arXiv preprint arXiv:2405.00708 , year=
Interactive analysis of llms using meaningful counterfactuals , author=. arXiv preprint arXiv:2405.00708 , year=
-
[15]
arXiv preprint arXiv:2312.17122 , year=
Large language model for causal decision making , author=. arXiv preprint arXiv:2312.17122 , year=
-
[16]
2009 , publisher=
Causality , author=. 2009 , publisher=
2009
-
[17]
Proceedings of the AAAI conference on artificial intelligence , volume=
Causalgnn: Causal-based graph neural networks for spatio-temporal epidemic forecasting , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[18]
International conference on machine learning , pages=
Structure-aware transformer for graph representation learning , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[19]
Proceedings of the IEEE , volume=
Toward causal representation learning , author=. Proceedings of the IEEE , volume=. 2021 , publisher=
2021
-
[20]
Philosophy Compass , volume=
Causal discovery algorithms: A practical guide , author=. Philosophy Compass , volume=. 2018 , publisher=
2018
-
[21]
Advances in Neural Information Processing Systems , volume=
Counterfactual fairness with partially known causal graph , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
arXiv preprint arXiv:1901.08162 , year=
Causal reasoning from meta-reinforcement learning , author=. arXiv preprint arXiv:1901.08162 , year=
-
[23]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review arXiv
-
[24]
Stanford Center for Research on Foundation Models
Alpaca: A strong, replicable instruction-following model , author=. Stanford Center for Research on Foundation Models. https://crfm. stanford. edu/2023/03/13/alpaca. html , volume=
2023
-
[25]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Advances in Neural Information Processing Systems , volume=
Cladder: Assessing causal reasoning in language models , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
Procesamiento del Lenguaje Natural , volume=
Interventional and Counterfactual Causal Reasoning for LLM-based AI Agents: A Dataset and Evaluation in Portuguese , author=. Procesamiento del Lenguaje Natural , volume=
-
[28]
arXiv preprint arXiv:2501.14892 , year=
Causal Graphs Meet Thoughts: Enhancing Complex Reasoning in Graph-Augmented LLMs , author=. arXiv preprint arXiv:2501.14892 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.