Recognition: unknown
Science discussions of retracted articles on Bluesky: public scrutiny or misinformation spreading?
Pith reviewed 2026-05-08 16:41 UTC · model grok-4.3
The pith
Bluesky posts about retracted articles show good practices far more often than bad ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Of the Bluesky posts discussing retracted articles, 89.9 percent demonstrated good practice while 10.1 percent demonstrated bad practice. Good-practice posts also attracted higher user engagement. In the pre-retraction phase good-practice posts formed a slight minority at 43.0 percent, but after retraction they rose to 94.2 percent. Most negative posts before retraction reflected good practice, whereas only a small share of positive posts after retraction showed bad practice. The authors conclude that Bluesky supports responsible scientific communication, public scrutiny, and research integrity.
What carries the argument
Manual classification of individual Bluesky posts into good-practice versus bad-practice categories, performed on a sample of posts linked to retracted articles.
If this is right
- Good-practice posts receive more engagement than bad-practice posts.
- Negative sentiment before retraction often signals good practice in identifying flaws.
- Positive sentiment after retraction rarely indicates bad practice.
- Bluesky discussions become strongly dominated by good practice once retractions are announced.
Where Pith is reading between the lines
- If the observed pattern generalizes, platforms with similar public threading may reduce the persistence of retracted claims more effectively than closed academic channels.
- Combining sentiment filters with human review could create early-warning systems for papers that later retract.
- The higher engagement for good-practice posts suggests users reward accurate scrutiny, which could shape future platform norms.
Load-bearing premise
The assumption that human coders can reliably and consistently label social media posts as good or bad practice without bias or disagreement.
What would settle it
Independent coders reclassifying the same collection of posts and obtaining a good-practice share below 70 percent.
Figures

read the original abstract
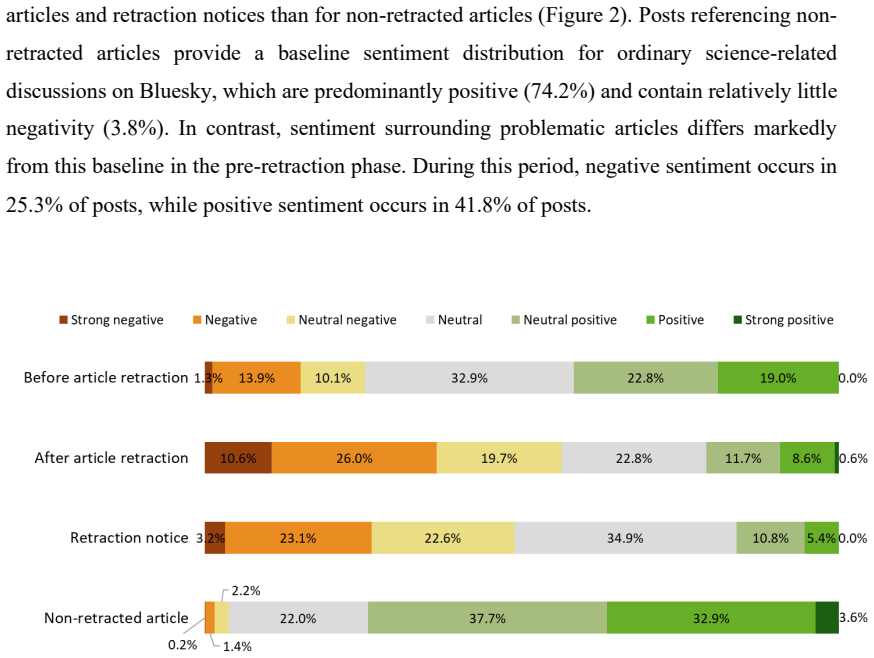
Post-publication peer review (PPPR) has emerged as an important supplement to traditional peer review, with social media playing a growing role in publicising potential problems in published research. However, it remains unclear whether social media discussions of retracted articles primarily reflect good practices, such as exposing flaws and acknowledging retraction status, or bad practices, such as overlooking retractions and continuing to disseminate scientific misinformation. In this study, we collected Bluesky posts referencing scholarly articles from Altmetric and retrieved metadata for the referenced articles using OpenAlex. The final dataset included 284 retracted articles with 79 pre-retraction posts and 857 post-retraction posts, 59 retraction notices with 186 posts, and 609,461 non-retracted articles with 1,344,756 posts. We manually coded Bluesky posts discussing retracted articles to identify instances of good and bad practice. The results show that posts demonstrating good practice (89.9%) substantially outnumbered those demonstrating bad practice (10.1%). Posts reflecting good practice also had more user engagement. In the pre-retraction phase, good practice posts constituted a slight minority (43.0%), whereas in the post-retraction phase they were dominant (94.2%). Most negative posts in the pre-retraction phase (90.0%) had good practice while only 17.3% positive posts in the post-retraction phase showed bad practice. Thus, sentiment analysis can be helpful to filter posts that could flag potential flaws before retraction, but it may struggle to accurately identify the spread of misinformation after retraction. More broadly, this study highlights the potential of Bluesky to support responsible scientific communication, public scrutiny, and research integrity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines Bluesky discussions of retracted scholarly articles to determine whether they primarily reflect good practices (e.g., exposing flaws or acknowledging retractions) or bad practices (e.g., overlooking retractions and spreading misinformation). Drawing on Altmetric to identify 936 Bluesky posts linked to 284 retracted articles (79 pre-retraction and 857 post-retraction), plus metadata from OpenAlex, the authors manually coded the posts and report that 89.9% demonstrate good practice versus 10.1% bad practice, with good-practice posts showing higher engagement; the proportion of good-practice posts rises from 43.0% pre-retraction to 94.2% post-retraction. They conclude that Bluesky largely supports responsible scientific communication and that sentiment analysis may help flag potential issues before retraction.
Significance. If the manual coding proves reliable and the Altmetric sample representative, the study offers timely empirical evidence on the quality of post-publication scrutiny on an emerging platform, documenting a clear shift toward constructive discourse after retraction and higher engagement for good-practice posts. The large-scale linkage of retraction metadata with social-media posts is a methodological strength that could inform research-integrity monitoring and platform policies.
major comments (2)
- [Methods] Methods (manual coding): The central claims rest on binary classification of 936 posts into good vs. bad practice (89.9% vs. 10.1% overall; 43.0% vs. 94.2% pre-/post-retraction). No codebook, inter-rater reliability statistic, description of ambiguous-case resolution, or bias checks are provided, leaving it unclear whether the operational definitions were applied consistently.
- [Data collection] Data collection and sampling: The study relies exclusively on Altmetric-indexed Bluesky posts without quantifying Altmetric's coverage completeness or potential skew toward high-visibility accounts. This directly affects the representativeness of the 936-post sample and the generalizability of the reported good-practice dominance.
minor comments (2)
- [Abstract] The abstract states precise percentages but does not explicitly report the total number of coded posts (936) or the exact criteria used to distinguish pre- from post-retraction phases.
- [Results] Results on engagement differences would be strengthened by reporting statistical tests (e.g., t-tests or Wilcoxon ranks) rather than qualitative statements that good-practice posts 'had more user engagement.'
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We have revised the manuscript to improve methodological transparency and to better contextualize the data limitations. Below we respond point by point.
read point-by-point responses
-
Referee: [Methods] Methods (manual coding): The central claims rest on binary classification of 936 posts into good vs. bad practice (89.9% vs. 10.1% overall; 43.0% vs. 94.2% pre-/post-retraction). No codebook, inter-rater reliability statistic, description of ambiguous-case resolution, or bias checks are provided, leaving it unclear whether the operational definitions were applied consistently.
Authors: We agree that greater detail on the coding process is required. In the revised manuscript we have added the complete codebook as Supplementary Material S1, including explicit operational definitions, decision rules, and examples for good- and bad-practice categories. Ambiguous cases were resolved by consensus discussion among the authors after consulting the retraction notice and article metadata. Although primary coding was performed by one author, we have now conducted an independent second coding of a random subsample of 100 posts and report the resulting inter-rater reliability statistic in the Methods section. We have also added explicit bias checks (stratification by post timing, sentiment, and article subject area) to demonstrate consistency of application. These changes are incorporated in the updated Methods and supplementary files. revision: yes
-
Referee: [Data collection] Data collection and sampling: The study relies exclusively on Altmetric-indexed Bluesky posts without quantifying Altmetric's coverage completeness or potential skew toward high-visibility accounts. This directly affects the representativeness of the 936-post sample and the generalizability of the reported good-practice dominance.
Authors: We recognize that reliance on Altmetric introduces potential coverage limitations. Detailed platform-wide coverage statistics for Bluesky are not publicly released by Altmetric, so we cannot provide a precise quantification of completeness or skew. In the revised manuscript we have substantially expanded the Limitations section to discuss this issue explicitly, noting that the sample may under-represent posts from low-visibility accounts. To partially address generalizability, we have added a comparison of the 284 retracted articles in our sample against the full set of retracted articles in OpenAlex on key metadata (subject areas, citation counts, journal prestige). The distributions are broadly comparable, suggesting that article-level selection bias is limited, though we cannot fully rule out platform-visibility effects. revision: partial
- Quantifying Altmetric's coverage completeness or potential skew toward high-visibility accounts, as this information is not available from the data provider.
Circularity Check
No significant circularity in empirical observational study
full rationale
This paper performs a standard observational analysis: it retrieves external data via Altmetric and OpenAlex, manually codes a finite set of posts into binary good/bad practice categories, and reports direct counts and percentages (e.g., 89.9 % good practice overall). No equations, fitted parameters, predictions, or self-referential definitions appear. The central results are empirical tallies from the coded sample rather than any derivation that reduces to its own inputs by construction. No load-bearing self-citations or uniqueness claims are present. The study is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Manual coding can reliably and unbiasedly classify social media posts as demonstrating good or bad practice regarding retractions.
Reference graph
Works this paper leans on
-
[1]
https://doi.org/10.1007/s11948-015-9680-y Brainard, J. (2018). Rethinking retractions. Science, 362(6413), 390–393. https://doi.org/10.1126/science.362.6413.390 Braun, V., & Clarke, V. (2006). Using thematic analysis in psychology. Qualitative Research in Psychology, 3(2), 77–101. https://doi.org/10.1191/1478088706qp063oa Breuning, M., Backstrom, J., Bran...
-
[2]
https://doi.org/10.1126/science.aas9490 Phuljhele, S. (2024). Reviewer fatigue is real. Indian Journal of Ophthalmology, 72(Suppl 5), S719. https://doi.org/10.4103/IJO.IJO_2465_24 Quelle, D., Denker, F., Garg, P., & Bovet, A. (2025). Why Academics Are Leaving Twitter for Bluesky (arXiv:2505.24801). arXiv. https://doi.org/10.48550/arXiv.2505.24801 Riad, M....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.