Recognition: unknown
InterFuserDVS: Event-Enhanced Sensor Fusion for Safe RL-Based Decision Making
Pith reviewed 2026-05-08 16:57 UTC · model grok-4.3
The pith
Adding event cameras to InterFuser fusion raises route completion to 100 percent on CARLA benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that integrating DVS data through a novel token-based fusion strategy into the transformer backbone of InterFuser produces a more robust driving policy. This policy leverages the complementary strengths of RGB, LiDAR, and asynchronous event streams to maintain performance where conventional sensors degrade. On the CARLA Leaderboard the resulting agent records a competitive Driving Score of 77.2 and perfect Route Completion of 100 percent, indicating that event-based vision supplies useful information precisely in adverse lighting and dynamic conditions.
What carries the argument
Token-based fusion strategy that converts accumulated event frames into tokens and merges them with RGB and LiDAR tokens inside the transformer backbone of the extended InterFuser model.
If this is right
- The agent maintains higher reliability when traditional cameras suffer motion blur at high speeds.
- Perception stays effective in scenes with extreme brightness changes where RGB saturates or loses detail.
- The same fusion approach can be applied to other reinforcement-learning driving policies that already use transformer backbones.
- Event data reduces dependence on perfect synchronization between RGB and LiDAR streams.
Where Pith is reading between the lines
- The method may generalize to real-vehicle hardware if event cameras are mounted alongside existing sensors.
- Further gains could appear if the fusion tokens are weighted dynamically according to scene conditions.
- Similar token fusion could be tested in other domains that need low-latency vision such as drone navigation.
- Longer evaluation runs on CARLA might reveal whether the 100 percent route completion holds across more weather and traffic variations.
Load-bearing premise
The token-based fusion method actually succeeds in letting the transformer use event information in a way that measurably improves robustness over RGB-plus-LiDAR alone.
What would settle it
Re-running the same CARLA evaluation with the DVS branch removed and observing that the Driving Score and Route Completion stay statistically unchanged or improve.
Figures

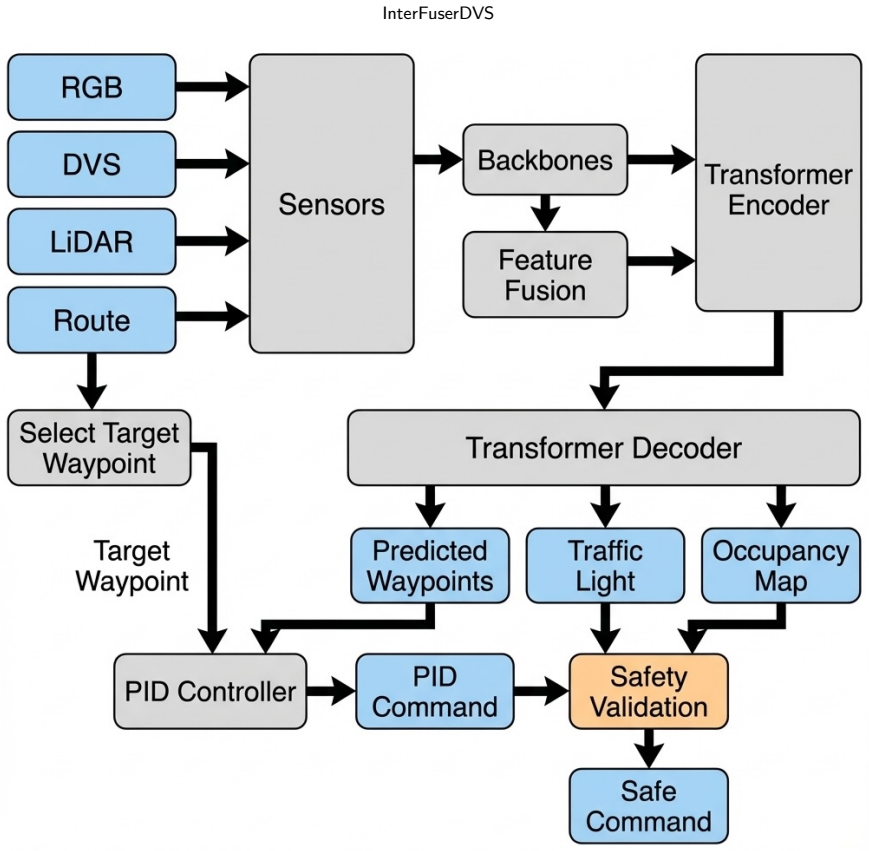


read the original abstract
Autonomous driving systems rely heavily on robust sensor fusion to perceive complex envi- ronments. Traditional setups using RGB cameras and LiDAR often struggle in high-dynamic- range scenes or high-speed scenarios due to motion blur and latency. Dynamic Vision Sensors (DVS), or event cameras, offer a paradigm shift by capturing asynchronous brightness changes with microsecond temporal resolution and high dynamic range. In this paper, we propose an extended architecture of the state-of-the-art InterFuser model, integrating DVS as an additional modality to enhance perception reliability. We introduce a novel token-based fusion strategy that incorporates accumulated event frames into the transformer-based backbone of InterFuser. Our method leverages the complementary nature of RGB, LiDAR, and DVS data. We evaluate our approach on the Car Learning to Act (CARLA) Leaderboard benchmarks, demonstrating that the inclusion of DVS improves the robustness of the driving agent, achieving a competitive Driving Score of 77.2 and a superior Route Completion of 100%. The results indicate that event-based vision is a promising direction for improving safety and performance in adverse lighting and dynamic conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes InterFuserDVS, an extension of the InterFuser architecture that adds Dynamic Vision Sensors (DVS) as a third modality. It introduces a token-based fusion mechanism to incorporate accumulated event frames into the transformer backbone alongside RGB and LiDAR inputs. The central empirical claim is that this fusion improves robustness in high-dynamic-range and high-speed driving scenarios, as evidenced by a Driving Score of 77.2 and 100% Route Completion on the CARLA Leaderboard.
Significance. If the reported gains can be isolated to the DVS modality through controlled experiments, the work would provide concrete evidence that event-based sensing complements conventional cameras and LiDAR in RL-based autonomous driving, particularly under motion blur and lighting extremes. The absence of such controls currently prevents any assessment of whether the result advances the state of multi-modal fusion.
major comments (3)
- [Abstract] Abstract: The reported Driving Score of 77.2 and Route Completion of 100% are presented without any matched baseline run of the original InterFuser or an ablation that removes only the DVS branch while holding architecture, RL training procedure, and CARLA scenario distribution fixed. Given the high variance typical of RL driving agents, a single scalar score does not establish that the token-based fusion produces measurable robustness gains.
- [Methods] Methods / fusion description: The token-based fusion strategy is introduced at a conceptual level but supplies no equations, pseudocode, or architectural diagram showing how accumulated event frames are tokenized, embedded, and cross-attended with RGB and LiDAR tokens inside the transformer backbone. Without these details the claim that DVS data are “effectively incorporated” cannot be evaluated.
- [Experiments] Experiments: No implementation details, training hyperparameters, random seeds, error bars, statistical tests, or leaderboard comparison table are provided. The manuscript therefore offers no way to determine whether the 77.2 score differs from prior InterFuser results by more than training stochasticity.
minor comments (1)
- [Abstract] Abstract: The phrase “competitive Driving Score” is used without stating the current leaderboard rank or the exact metric definitions employed by CARLA.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. We agree that the current manuscript lacks the necessary controls, technical details, and experimental rigor to substantiate the claimed benefits of DVS integration. We will perform a major revision to address all points raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported Driving Score of 77.2 and Route Completion of 100% are presented without any matched baseline run of the original InterFuser or an ablation that removes only the DVS branch while holding architecture, RL training procedure, and CARLA scenario distribution fixed. Given the high variance typical of RL driving agents, a single scalar score does not establish that the token-based fusion produces measurable robustness gains.
Authors: We acknowledge the validity of this criticism. The revised manuscript will include a matched baseline evaluation of the original InterFuser under identical training conditions, random seeds, and CARLA scenario distributions. We will also add an ablation study that isolates the DVS branch by removing it while keeping all other components fixed. These additions will enable direct quantification of the contribution of the token-based fusion beyond training stochasticity. revision: yes
-
Referee: [Methods] Methods / fusion description: The token-based fusion strategy is introduced at a conceptual level but supplies no equations, pseudocode, or architectural diagram showing how accumulated event frames are tokenized, embedded, and cross-attended with RGB and LiDAR tokens inside the transformer backbone. Without these details the claim that DVS data are “effectively incorporated” cannot be evaluated.
Authors: We agree that the fusion mechanism requires precise specification. In the revision we will add the full mathematical formulation for event-frame accumulation, tokenization, embedding, and the cross-attention equations within the transformer. We will also include pseudocode for the fusion module and a detailed architectural diagram that illustrates the data flow from DVS events through to the shared backbone. revision: yes
-
Referee: [Experiments] Experiments: No implementation details, training hyperparameters, random seeds, error bars, statistical tests, or leaderboard comparison table are provided. The manuscript therefore offers no way to determine whether the 77.2 score differs from prior InterFuser results by more than training stochasticity.
Authors: We accept this observation. The revised experiments section will report complete implementation details, the full set of training hyperparameters, the number of random seeds, standard deviations across runs, results of statistical significance tests, and a comparison table that places the 77.2 score against the original InterFuser and other published CARLA leaderboard entries under consistent evaluation protocols. revision: yes
Circularity Check
No significant circularity; empirical simulation results with no derivations or self-referential reductions.
full rationale
The manuscript describes an architectural extension of InterFuser that adds a DVS branch and a token-based fusion module, then reports CARLA leaderboard metrics (Driving Score 77.2, Route Completion 100%). No equations, parameter-fitting procedures, or derivation steps appear in the provided text. The central claim rests on direct simulation outcomes rather than any quantity that is defined in terms of itself or obtained by renaming a fitted input. Self-citations, if present, are not load-bearing for any mathematical result. The evaluation chain is therefore self-contained against the external CARLA benchmark and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption RGB, LiDAR, and DVS modalities are complementary for perception in adverse conditions
Reference graph
Works this paper leans on
-
[1]
Expert drivers for autonomous driving
, 2021. Expert drivers for autonomous driving. urlhttps://kait0.github.io/files/master_thesis_bernhard_jaeger.pdf
2021
-
[2]
End to End Learning for Self-Driving Cars
Bojarski, M., Del Testa, D., Dworakowski, D., Firner, B., Flepp, B., Goyal, P., Jackel, L.D., Monfort, M., Muller, U., Zhang, J., et al., 2016. End to end learning for self-driving cars. arXiv preprint arXiv:1604.07316 URL:https://arxiv.org/abs/1604.07316
work page internal anchor Pith review arXiv 2016
-
[3]
arXiv preprint arXiv:1903.11027 (2019)
Caesar,H.,Bankiti,V.,Lang,A.H.,Vora,S.,Liong,V.E.,Xu,Q.,Krishnan,A.,Pan,Y.,Baldan,G.,Beijbom,O.,2019.nuscenes:Amultimodal dataset for autonomous driving. CoRR abs/1903.11027. URL:http://arxiv.org/abs/1903.11027,arXiv:1903.11027
-
[4]
GRI:GeneralReinforcedImitationanditsApplicationtoVision- Based Autonomous Driving,
Chekroun, R., Toromanoff, M., Hornauer, S., Moutarde, F., 2021. Gri: General reinforced imitation and its application to vision-based autonomous driving. arXiv preprint arXiv:2111.08575
-
[5]
Learningtodrivefromaworldonrails,in:ProceedingsoftheIEEE/CVFInternationalConference on Computer Vision, pp
Chen,D.,Koltun,V.,Krähenbühl,P.,2021. Learningtodrivefromaworldonrails,in:ProceedingsoftheIEEE/CVFInternationalConference on Computer Vision, pp. 15590–15599
2021
-
[6]
Learning from all vehicles, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp
Chen, D., Krähenbühl, P., 2022. Learning from all vehicles, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 17222–17231
2022
-
[7]
Chen, D., Zhou, B., Koltun, V., Krähenbühl, P., 2020. Learning by cheating, in: Conference on Robot Learning, PMLR. pp. 66–75. URL: https://arxiv.org/abs/1912.12294
-
[8]
End-to-end autonomous driving: Challenges and frontiers
Chen, L., Wu, P., Chitta, K., Jaeger, B., Geiger, A., Li, H., 2024. End-to-end autonomous driving: Challenges and frontiers. arXiv preprint arXiv:2306.16927 URL:https://arxiv.org/abs/2306.16927,arXiv:2306.16927
-
[9]
Multi-view 3d object detection network for autonomous driving
Chen, X., Ma, H., Wan, J., Li, B., Xia, T., 2016. Multi-view 3d object detection network for autonomous driving. CoRR abs/1611.07759. URL:http://arxiv.org/abs/1611.07759,arXiv:1611.07759
-
[10]
Chitta, K., Prakash, A., Geiger, A., 2021. Neat: Neural attention fields for end-to-end autonomous driving, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 15793–15803. URL:https://arxiv.org/abs/2109.04456
-
[11]
Transfuser: Imitation with transformer-based sensor fu- sion for autonomous driving,
Chitta, K., Prakash, A., Jaeger, B., Yu, Z., Renz, K., Geiger, A., 2022. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving. arXiv preprint arXiv:2205.15997 URL:https://arxiv.org/abs/2205.15997,arXiv:2205.15997
-
[12]
End-to-end driving via conditional imitation learn- ing,
Codevilla, F., Müller, M., López, A., Koltun, V., Dosovitskiy, A., 2018. End-to-end driving via conditional imitation learning, in: 2018 IEEE International Conference on Robotics and Automation (ICRA), IEEE. pp. 4693–4700. URL:https://arxiv.org/abs/1710.02410
-
[13]
Codevilla, F., Santana, E., Lopez, A., Gaidon, A., 2019. Exploring the limitations of behavior cloning for autonomous driving, in: 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 9328–9337. doi:10.1109/ICCV.2019.00942
-
[14]
Deepreinforcementandilforautonomousdriving:Areviewinthecarlasimulation environment
Czechowski,P.,Kawa,B.,Sakhai,M.,Wielgosz,M.,2025. Deepreinforcementandilforautonomousdriving:Areviewinthecarlasimulation environment. Applied Sciences 15, 8972. URL:https://doi.org/10.3390/app15168972, doi:10.3390/app15168972
-
[15]
Loihi: A neuromorphic manycore processor with on-chip learning
Davies, M., Srinivasa, N., Lin, T.H., Chinya, G., Cao, Y., Choday, S.H., Dimou, G., Joshi, P., Imam, N., Jain, S., Liao, Y., Lin, C.K., Lines, A., Liu, R., Mathaikutty, D., McCoy, S., Paul, A., Tse, J., Venkataramanan, G., Weng, Y.H., Wild, A., Yang, Y., Wang, H., 2018. Loihi: A neuromorphic manycore processor with on-chip learning. IEEE Micro 38, 82–99. ...
-
[16]
Temporal efficient training of spiking neural network via gradient re-weighting
Deng, S., Li, Y., Zhang, S., Gu, S., 2022. Temporal efficient training of spiking neural network via gradient re-weighting. URL:https: //openreview.net/forum?id=_XNtisL32jv
2022
-
[17]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit,J.,Houlsby,N.,2020. Animageisworth16x16words:Transformersforimagerecognitionatscale. CoRRabs/2010.11929. URL: https://arxiv.org/abs/2010.11929,arXiv:2010.11929
work page internal anchor Pith review arXiv 2020
-
[18]
CARLA: An open urban driving simulator, in: Levine, S., Vanhoucke, V., Goldberg, K
Dosovitskiy, A., Ros, G., Codevilla, F., Lopez, A., Koltun, V., 2017. CARLA: An open urban driving simulator, in: Levine, S., Vanhoucke, V., Goldberg, K. (Eds.), Proceedings of the 1st Annual Conference on Robot Learning, PMLR. pp. 1–16. URL:https://proceedings. mlr.press/v78/dosovitskiy17a.html
2017
-
[19]
Fang,W.,Yu,Z.,Chen,Y.,Masquelier,T.,Huang,T.,Tian,Y.,2021. IncorporatingLearnableMembraneTimeConstanttoEnhanceLearning of Spiking Neural Networks , in: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE Computer Society, Los Alamitos, CA, USA. pp. 2641–2651. URL:https://doi.ieeecomputersociety.org/10.1109/ICCV48922.2021.00266, doi:10. ...
-
[20]
Gallego, G., Delbruck, T., Orchard, G., Bartolozzi, C., Taba, B., Censi, A., Leutenegger, S., Davison, A.J., Conradt, J., Daniilidis, K., Scaramuzza, D., 2019. Event-based vision: A survey. CoRR abs/1904.08405. URL:http://arxiv.org/abs/1904.08405, arXiv:1904.08405
-
[21]
Gehrig, D., Rüegg, M., Gehrig, M., Hidalgo-Carrió, J., Scaramuzza, D., 2021. Combining events and frames using recurrent asyn- chronous multimodal networks for monocular depth prediction. CoRR abs/2102.09320. URL:https://arxiv.org/abs/2102.09320, arXiv:2102.09320
-
[22]
Geiger, A., Lenz, P., Stiller, C., Urtasun, R., 2013. Vision meets robotics: The kitti dataset. The International Journal of Robotics Research 32, 1231–1237. URL:https://doi.org/10.1177/0278364913491297, doi:10.1177/0278364913491297, arXiv:https://doi.org/10.1177/0278364913491297
-
[23]
Deep residual learning for image recognition, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp
He, K., Zhang, X., Ren, S., Sun, J., 2016. Deep residual learning for image recognition, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778
2016
-
[24]
V2E: from video frames to realistic DVS event camera streams
Hu, Y., Liu, S., Delbruck, T., 2020. V2E: from video frames to realistic DVS event camera streams. CoRR abs/2006.07722. URL: https://arxiv.org/abs/2006.07722,arXiv:2006.07722
-
[25]
Planning-oriented autonomous driving
Hu, Y., Yang, J., Chen, L., Li, K., Sima, C., Zhu, X., Chai, S., Du, S., Lin, T., Wang, W., Lu, L., Jia, X., Liu, Q., Dai, J., Qiao, Y., Li, H., 2023. Planning-oriented autonomous driving. arXiv preprint arXiv:2212.10156 URL:https://arxiv.org/abs/2212.10156, arXiv:2212.10156
-
[26]
Huang, J., Huang, G., Zhu, Z., Du, D., 2021. Bevdet: High-performance multi-camera 3d object detection in bird-eye-view. CoRR abs/2112.11790. URL:https://arxiv.org/abs/2112.11790,arXiv:2112.11790
-
[27]
Computer vision for autonomous vehicles: Problems, datasets and state-of-the-art
Janai, J., Güney, F., Behl, A., Geiger, A., 2017. Computer vision for autonomous vehicles: Problems, datasets and state-of-the-art. CoRR abs/1704.05519. URL:http://arxiv.org/abs/1704.05519,arXiv:1704.05519. Sakhai et al.:Preprint submitted to ElsevierPage 15 of 17 InterFuserDVS
- [28]
-
[29]
Kalra, N., Paddock, S.M., 2016. Driving to safety: How many miles of driving would it take to demonstrate autonomous vehicle reliability? Transportation Research Part A: Policy and Practice 94, 182–193. URL:https://www.sciencedirect.com/science/article/pii/ S0965856416302129, doi:https://doi.org/10.1016/j.tra.2016.09.010
-
[30]
Challenges in autonomous vehicle testing and validation
Koopman, P., Wagner, M.D., 2016. Challenges in autonomous vehicle testing and validation. SAE International journal of transportation safety 4, 15–24. URL:https://api.semanticscholar.org/CorpusID:35473171
2016
-
[31]
arXiv preprint arXiv:2203.17270 (2022)
Li, Z., Wang, W., Li, H., Xie, E., Sima, C., Lu, T., Yu, Q., Dai, J., 2022. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. arXiv preprint arXiv:2203.17270 URL:https://arxiv.org/abs/2203.17270, arXiv:2203.17270
-
[32]
Bevfusion:Asimpleandrobustlidar-camerafusion framework
Liang,T.,Xie,H.,Yu,K.,Xia,Z.,Lin,Z.,Wang,Y.,Tang,T.,Wang,B.,Tang,Z.,2022. Bevfusion:Asimpleandrobustlidar-camerafusion framework. arXiv preprint arXiv:2205.13790 URL:https://arxiv.org/abs/2205.13790,arXiv:2205.13790
-
[33]
Lichtsteiner,P.,Posch,C.,Delbruck,T.,2008. A128×128120db15𝜇slatencyasynchronoustemporalcontrastvisionsensor. IEEEJournal of Solid-State Circuits 43, 566–576. doi:10.1109/JSSC.2007.914337
-
[34]
Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) , year =
Liu, Z., Tang, H., Amini, A., Yang, X., Mao, H., Rus, D.L., Han, S., 2023. Bevfusion: Multi-task multi-sensor fusion with unified bird’s- eye view representation, in: 2023 IEEE International Conference on Robotics and Automation (ICRA), pp. 2774–2781. doi:10.1109/ ICRA48891.2023.10160968
-
[35]
Event-based vision meets deep learning on steering prediction for self-driving cars, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp
Maqueda, A.I., Loquercio, A., Gallego, G., García, N., Scaramuzza, D., 2018. Event-based vision meets deep learning on steering prediction for self-driving cars, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5419–5427. URL:https: //openaccess.thecvf.com/content_cvpr_2018/papers/Maqueda_Event-Based_Vision_Meets_CVPR...
2018
-
[36]
Event-based asynchronous sparse convolutional networks
Messikommer, N., Gehrig, D., Loquercio, A., Scaramuzza, D., 2020. Event-based asynchronous sparse convolutional networks. CoRR abs/2003.09148. URL:https://arxiv.org/abs/2003.09148,arXiv:2003.09148
-
[37]
Visual-inertial monocular SLAM with map reuse
Mur-Artal, R., Tardós, J.D., 2016. Visual-inertial monocular SLAM with map reuse. CoRR abs/1610.05949. URL:http://arxiv.org/ abs/1610.05949,arXiv:1610.05949
-
[38]
Lmdrive dataset: 64k instruction-sensor-control data clips for autonomous driving.https://openxlab.org.cn/ datasets/deepcs233/LMDrive
OpenXLab, 2024. Lmdrive dataset: 64k instruction-sensor-control data clips for autonomous driving.https://openxlab.org.cn/ datasets/deepcs233/LMDrive. Multi-modal dataset collected in CARLA simulator with navigation instructions
2024
-
[39]
Deep learning with spiking neurons: Opportunities and challenges
Pfeiffer, M., Pfeil, T., 2018. Deep learning with spiking neurons: Opportunities and challenges. Frontiers in Neuroscience 12. URL: https://api.semanticscholar.org/CorpusID:53086859
2018
-
[40]
Alvinn: An autonomous land vehicle in a neural network, in: Advances in Neural Information Processing Systems, pp
Pomerleau, D.A., 1989. Alvinn: An autonomous land vehicle in a neural network, in: Advances in Neural Information Processing Systems, pp. 305–313. URL:https://proceedings.neurips.cc/paper/1988/file/812b4ba287f5ee0bc9d43bbf5bbe87fb-Paper.pdf
1989
- [41]
-
[42]
Pointnet:Deeplearningonpointsetsfor3dclassificationandsegmentation,in:Proceedingsof the IEEE conference on computer vision and pattern recognition, pp
Qi,C.R.,Su,H.,Mo,K.,Guibas,L.J.,2017a. Pointnet:Deeplearningonpointsetsfor3dclassificationandsegmentation,in:Proceedingsof the IEEE conference on computer vision and pattern recognition, pp. 652–660
-
[43]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space, in: Advances in Neural Information Processing Systems, pp
Qi, C.R., Yi, L., Su, H., Guibas, L.J., 2017b. Pointnet++: Deep hierarchical feature learning on point sets in a metric space, in: Advances in Neural Information Processing Systems, pp. 5099–5108
-
[44]
Rebecq, H., Ranftl, R., Koltun, V., Scaramuzza, D., 2019. Events-to-video: Bringing modern computer vision to event cameras, in: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3852–3861. doi:10.1109/CVPR.2019.00398
-
[45]
Towards spike-based machine intelligence with neuromorphic computing
Roy, K., Jaiswal, A.R., Panda, P., 2019. Towards spike-based machine intelligence with neuromorphic computing. Nature 575, 607 – 617. URL:https://api.semanticscholar.org/CorpusID:208329736
2019
-
[46]
Sakhai, M., Mazurek, S., Caputa, J., Argasiński, J.K., Wielgosz, M., 2024. Spiking neural networks for real-time pedestrian street-crossing detection using dynamic vision sensors in simulated adverse weather conditions. Electronics 13. URL:https://www.mdpi.com/ 2079-9292/13/21/4280, doi:10.3390/electronics13214280
-
[47]
Evaluatingsyntheticvs.realdynamicvisionsensordataforsnn-based objectdetectionclassification
Sakhai,M.,Sithu,K.,Oke,M.K.S.,Mazurek,S.,Wielgosz,M.,2025a. Evaluatingsyntheticvs.realdynamicvisionsensordataforsnn-based objectdetectionclassification. Availableat:https://events.plgrid.pl/event/70/attachments/143/364/PROCEEDINGS%202025_ na%20www%20bez%20notatek.pdf
-
[48]
Cyberattack resilience of autonomous vehicle sensor systems: Evaluating rgb vs
Sakhai, M., Sithu, K., Oke, M.K.S., Wielgosz, M., 2025b. Cyberattack resilience of autonomous vehicle sensor systems: Evaluating rgb vs. dynamic vision sensors in carla. Applied Sciences 15, 7493. URL:https://doi.org/10.3390/app15137493, doi:10.3390/ app15137493
-
[49]
Dvs-pedx: Synthetic-and-real event-based pedestrian dataset
Sakhai, M., Sithu, K., Oke, M.K.S., Wielgosz, M., 2026. Dvs-pedx: Synthetic-and-real event-based pedestrian dataset. Scientific Data 13,
2026
-
[50]
URL:https://doi.org/10.1038/s41597-026-06969-y, doi:10.1038/s41597-026-06969-y
-
[51]
Computing spatial image convolutions for event cameras
Scheerlinck, C., Barnes, N., Mahony, R.E., 2018. Computing spatial image convolutions for event cameras. CoRR abs/1812.00438. URL: http://arxiv.org/abs/1812.00438,arXiv:1812.00438
-
[52]
Opportunities for neuromorphic computing algorithms and applications
Schuman, C.D., Kulkarni, S.R., Parsa, M., Mitchell, J.P., Date, P., Kay, B., 2022. Opportunities for neuromorphic computing algorithms and applications. NatureComputationalScience2. URL:https://www.osti.gov/biblio/1881146,doi:10.1038/s43588-021-00184-y
-
[53]
Safety-enhancedautonomousdrivingusinginterpretablesensorfusiontransformer
Shao,H.,Wang,L.,Chen,R.,Li,H.,Liu,Y.,2022. Safety-enhancedautonomousdrivingusinginterpretablesensorfusiontransformer. arXiv preprint arXiv:2207.14024 URL:https://arxiv.org/abs/2207.14024,arXiv:2207.14024
-
[54]
Reasonnet:End-to-enddriving withtemporaland globalreasoning,in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp
Shao,H., Wang,L.,Chen, R.,Waslander,S.L., Liu,Y.,Ma, H.,2023. Reasonnet:End-to-enddriving withtemporaland globalreasoning,in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13723–13733
2023
-
[55]
Pcla: A framework for testing autonomous agents in the carla simulator
Tehrani, M.J., Kim, J., Tonella, P., 2025. Pcla: A framework for testing autonomous agents in the carla simulator. arXiv preprint arXiv:2503.09385 URL:https://arxiv.org/abs/2503.09385,arXiv:2503.09385
-
[56]
End-to-end model-free reinforcement learning for urban driving using implicit affordances, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp
Toromanoff, M., Wirbel, E., Moutarde, F., 2020. End-to-end model-free reinforcement learning for urban driving using implicit affordances, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7153–7162. Sakhai et al.:Preprint submitted to ElsevierPage 16 of 17 InterFuserDVS
2020
-
[57]
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser,L.,Polosukhin,I.,2017. Attentionisallyouneed. CoRR abs/1706.03762. URL:http://arxiv.org/abs/1706.03762,arXiv:1706.03762
work page internal anchor Pith review arXiv 2017
-
[58]
Vidal, A.R., Rebecq, H., Horstschaefer, T., Scaramuzza, D., 2018. The ultimate slam? combining events, images, and imu for robust visual slam in hdr and high-speed scenarios. IEEE Robotics and Automation Letters 3, 2942–2949. URL:https://ieeexplore.ieee.org/ document/8337777
-
[59]
DETR3D:3dobjectdetectionfrommulti-viewimagesvia3d-to-2d queries
Wang,Y.,Guizilini,V.,Zhang,T.,Wang,Y.,Zhao,H.,Solomon,J.,2021. DETR3D:3dobjectdetectionfrommulti-viewimagesvia3d-to-2d queries. CoRR abs/2110.06922. URL:https://arxiv.org/abs/2110.06922,arXiv:2110.06922
-
[60]
Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline
Wu, P., Jia, X., Chen, L., Yan, J., Li, H., Qiao, Y., 2022. Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline. arXiv preprint arXiv:2206.08129 URL:https://arxiv.org/abs/2206.08129,arXiv:2206.08129
-
[61]
Xu, D., Li, H., Wang, Q., Song, Z., Chen, L., Deng, H., 2024. M2da: Multi-modal fusion transformer incorporating driver attention for autonomous driving. arXiv preprint arXiv:2403.12552
-
[62]
A survey of autonomous driving: Common practices and emerging technologies
Yurtsever, E., Lambert, J., Carballo, A., Takeda, K., 2020. A survey of autonomous driving: Common practices and emerging technologies. IEEE Access 8, 58443–58469. doi:10.1109/ACCESS.2020.2983149
-
[63]
Learning to see in the dark with events, in: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M
Zhang, S., Zhang, Y., Jiang, Z., Zou, D., Ren, J., Zhou, B., 2020. Learning to see in the dark with events, in: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M. (Eds.), Computer Vision – ECCV 2020, Springer International Publishing, Cham. pp. 666–682
2020
-
[64]
In: Proceedings of the IEEE/CVF ICCV, pp
Zhang, Z., Liniger, A., Dai, D., Yu, F., Van Gool, L., 2021. End-to-end urban driving by imitating a reinforcement learning coach, in: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 15202–15212. doi:10.1109/ICCV48922.2021.01494
-
[65]
Unsupervised event-based learning of optical flow, depth, and egomotion
Zhu, A.Z., Yuan, L., Chaney, K., Daniilidis, K., 2018. Unsupervised event-based learning of optical flow, depth, and egomotion. CoRR abs/1812.08156. URL:http://arxiv.org/abs/1812.08156,arXiv:1812.08156. Sakhai et al.:Preprint submitted to ElsevierPage 17 of 17
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.