Recognition: unknown
Joint Semantic Token Selection and Prompt Optimization for Interpretable Prompt Learning
Pith reviewed 2026-05-08 17:35 UTC · model grok-4.3
The pith
IPL alternates discrete semantic token selection with continuous prompt optimization to boost both interpretability and accuracy in vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
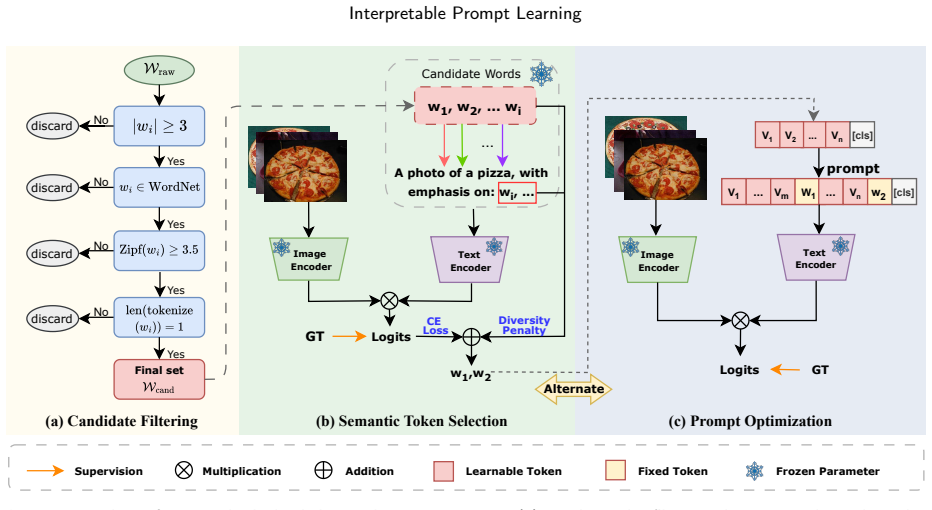
The paper claims that IPL, by casting semantic token selection as an approximate submodular optimization problem that promotes understandable and diverse tokens and then alternating this discrete step with continuous prompt optimization, delivers a plug-and-play extension that raises interpretability while preserving or improving accuracy on downstream tasks across five existing prompt learning methods and multiple benchmarks.
What carries the argument
Approximate submodular optimization for semantic token selection, which balances human understandability and semantic diversity, integrated through an alternating optimization loop with continuous prompt parameters.
If this is right
- Existing continuous prompt methods can be extended with IPL to gain interpretability as a modular add-on.
- The discrete tokens selected by the submodular step supply explicit, human-readable components for the adapted prompt.
- Task performance on vision-language benchmarks improves or holds steady rather than degrading under the hybrid schedule.
- The method avoids the computational burden of large external models required by prior discrete prompt approaches.
- The alternating strategy maintains adaptability to new downstream tasks while adding the discrete interpretability layer.
Where Pith is reading between the lines
- The same alternating discrete-continuous pattern could be tested on prompt adaptation for pure language models or other multimodal systems.
- If the submodular selection proves robust, it may suggest a broader design principle for choosing discrete building blocks inside continuous optimization loops.
- One direct extension would be to measure whether the improved interpretability reduces user error when humans debug or audit the resulting prompts.
- The framework implicitly raises the question of whether similar submodular criteria can be derived for other token-level decisions in vision-language pipelines.
Load-bearing premise
That approximate submodular optimization will reliably produce human-understandable and semantically diverse tokens that integrate cleanly with continuous prompt tuning without creating new overfitting or scalability problems.
What would settle it
Human or automated evaluations showing that the selected tokens are no more understandable or diverse than those from baseline prompt methods, or that accuracy fails to improve on the reported benchmarks when IPL is added to the five tested methods.
Figures



read the original abstract
Vision-language models such as CLIP achieve strong visual-textual alignment, but often suffer from overfitting and limited interpretability when adapted through continuous prompt learning. While discrete prompt optimization improves interpretability, it usually depends on large external models, leading to high computational costs and limited scalability. In this paper, we propose Interpretable Prompt Learning (IPL), a hybrid framework that alternates between discrete semantic token selection and continuous prompt optimization. Specifically, IPL formulates semantic token selection as an approximate submodular optimization problem, encouraging tokens that are both human-understandable and semantically diverse. It further adopts an alternating optimization strategy to integrate discrete token selection with continuous prompt tuning, improving interpretability while preserving adaptability to downstream tasks. Our framework is plug-and-play, allowing seamless integration with existing prompt learning methods. Extensive experiments on multiple benchmarks show that IPL consistently improves both interpretability and accuracy across five representative prompt learning methods, providing an effective and scalable extension to existing frameworks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Interpretable Prompt Learning (IPL), a plug-and-play hybrid framework for adapting vision-language models such as CLIP. IPL alternates between discrete semantic token selection (formulated as approximate submodular optimization to promote human-understandable and diverse tokens) and continuous prompt optimization. It integrates with existing prompt learning methods and reports consistent gains in both interpretability and accuracy across multiple benchmarks and five representative baselines.
Significance. If the central claims hold, IPL offers a scalable, low-cost extension to continuous prompt tuning that avoids heavy reliance on external models for discrete optimization while addressing overfitting and limited interpretability. The alternating strategy and submodular formulation could serve as a template for hybrid discrete-continuous prompt methods if the understandability mechanism is robust.
major comments (3)
- [§3] §3 (Method), semantic token selection formulation: the approximate submodular objective is described as selecting tokens that are both human-understandable and semantically diverse, yet the set function appears to consist only of coverage/diversity terms based on token embeddings or similarities. Human-understandability is not a submodular property and requires an explicit proxy (e.g., alignment to a fixed interpretable vocabulary or concept-level entropy); without it, the discrete step may select diverse but opaque tokens, rendering the interpretability gains non-causal.
- [§4 and §5] §4 (Alternating optimization) and §5 (Experiments): the integration of discrete selection with continuous tuning is presented as preserving adaptability, but no analysis is given on whether the continuous prompt compensates for the discrete choices (e.g., via ablation removing the submodular step or measuring token stability across iterations). This is load-bearing for the claim that IPL improves interpretability rather than merely adding a regularizer.
- [§5.2] §5.2 (Quantitative results): while accuracy improvements are reported across five prompt learning methods, the interpretability gains lack standardized metrics (e.g., human-rated concept clarity or alignment scores); reliance on qualitative examples alone weakens the cross-method claim that IPL provides a reliable extension.
minor comments (3)
- [Abstract] Abstract: the five representative prompt learning methods are not named; listing them (e.g., CoOp, CoCoOp, etc.) would improve clarity and allow readers to assess generality.
- [§3] Notation in §3: the submodular function and its approximation (e.g., greedy algorithm details or marginal gain computation) use symbols that are not fully defined on first use, making the formulation harder to follow.
- [Figure 2] Figure 2 (framework diagram): the alternating loop between discrete and continuous steps is shown schematically but lacks explicit indication of how the selected tokens are injected into the continuous prompt (e.g., as fixed embeddings or soft constraints).
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address each major comment below with clarifications and planned revisions to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method), semantic token selection formulation: the approximate submodular objective is described as selecting tokens that are both human-understandable and semantically diverse, yet the set function appears to consist only of coverage/diversity terms based on token embeddings or similarities. Human-understandability is not a submodular property and requires an explicit proxy (e.g., alignment to a fixed interpretable vocabulary or concept-level entropy); without it, the discrete step may select diverse but opaque tokens, rendering the interpretability gains non-causal.
Authors: We appreciate the referee's observation. The submodular objective relies on coverage and diversity terms computed from token embeddings and similarities. The coverage term is intended to favor tokens that span core semantic directions in the embedding space, which we posit correlates with human-understandability by avoiding opaque or low-relevance tokens. However, we acknowledge this is an implicit rather than explicit proxy. In the revision we will expand §3 to explicitly discuss this rationale, include selected token examples illustrating interpretability, and note the limitation while suggesting alignment to an interpretable vocabulary as a possible future enhancement. revision: partial
-
Referee: [§4 and §5] §4 (Alternating optimization) and §5 (Experiments): the integration of discrete selection with continuous tuning is presented as preserving adaptability, but no analysis is given on whether the continuous prompt compensates for the discrete choices (e.g., via ablation removing the submodular step or measuring token stability across iterations). This is load-bearing for the claim that IPL improves interpretability rather than merely adding a regularizer.
Authors: The referee correctly identifies a gap in the analysis. While the experiments demonstrate gains when IPL is integrated with existing methods, we did not include an ablation that isolates the submodular selection (e.g., by replacing it with random selection) or tracks token stability over iterations. We will add this analysis to the revised §5, including an ablation table and a stability plot, to confirm that the discrete step contributes to interpretability independently of the continuous optimization. revision: yes
-
Referee: [§5.2] §5.2 (Quantitative results): while accuracy improvements are reported across five prompt learning methods, the interpretability gains lack standardized metrics (e.g., human-rated concept clarity or alignment scores); reliance on qualitative examples alone weakens the cross-method claim that IPL provides a reliable extension.
Authors: We agree that reliance on qualitative examples limits the strength of the interpretability claims. Our current results include qualitative token visualizations and indirect measures such as diversity. To improve this, we will augment §5.2 with additional quantitative proxies, including average alignment scores of selected tokens to a held-out set of semantic concepts, reported across all baselines. We note that large-scale human ratings are resource-intensive and typically outside the scope of such papers, but the added proxies will provide more objective support. revision: partial
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents IPL as a hybrid method that applies standard approximate submodular optimization to semantic token selection (to encourage understandability and diversity) and alternates it with continuous prompt tuning. These steps are described as plug-and-play extensions using existing techniques rather than deriving new results by construction from fitted parameters or self-referential definitions. Interpretability and accuracy improvements are asserted via experiments on benchmarks across five methods, with no evident load-bearing self-citations, ansatzes smuggled via prior work, or predictions that reduce tautologically to inputs. The derivation chain remains self-contained against external validation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Approximate submodularity and its implications in discrete optimization. arXiv:1901.09209 . Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Mensch, A., Millican, K., Reynolds, M., et al.,
-
[2]
Flamingo: a visual language model for few-shot learning. Proc. Adv. Neural Inf. Process. Syst. 35, 23716–23736. Bian,A.A.,Buhmann,J.M.,Krause,A.,Tschiatschek,S.,2017. Guaranteesforgreedymaximizationofnon-submodularfunctionswithapplications, in: Proc. Int. Conf. Mach. Learn., pp. 498–507. Bird, S., Klein, E., Loper, E.,
2017
-
[3]
Describing textures in the wild, in: Proc. IEEE Conf. Comput. Vis. Pattern Recognit., pp. 3606–3613. Cui,F.,Zhang,Y.,Wang, X.,Wang,X.,Xiao,L.,2025. Generalizableprompt learningofclip:Abriefoverview. arXivpreprintarXiv:2503.01263 . Danish, S., Sadeghi-Niaraki, A., Khan, S.U., Dang, L.M., Tightiz, L., Moon, H.,
-
[4]
Approximate submodularity and its applications: Subset selection, sparse approximation and dictionary selection. J. Mach. Learn. Res. 19, 1–34. Deng,J.,Dong,W.,Socher,R.,Li,L.J.,Li,K.,Fei-Fei,L.,2009. Imagenet:Alarge-scalehierarchicalimagedatabase,in:Proc.IEEEConf.Comput. Vis. Pattern Recognit., pp. 248–255. Ding, T., Li, W., Miao, Z., Pfister, H.,
2009
-
[5]
Tree of attributes prompt learning for vision-language models. arXiv:2410.11201 . Du, Y., Sun, W., Snoek, C.,
- [6]
-
[7]
Intcoop: Interpretability-aware vision-language prompt tuning. arXiv:2406.13683 . Golovin,D.,Krause,A.,2011. Adaptivesubmodularity:Theoryandapplicationsinactivelearningandstochasticoptimization. J.Artif.Intell.Res. 42, 427–486. Helber,P.,Bischke,B.,Dengel,A.,Borth,D.,2019. Eurosat:Anoveldatasetanddeeplearningbenchmarkforlanduseandlandcoverclassification. ...
-
[8]
IEEE/CVF Int
3d object representations for fine-grained categorization, in: Proc. IEEE/CVF Int. Conf. Comput. Vis. Workshops, pp. 554–561. Li,J.,Li,D.,Savarese,S.,Hoi,S.,2023. Blip-2:Bootstrappinglanguage-imagepre-trainingwithfrozenimageencodersandlargelanguagemodels, in: Proc. Int. Conf. Mach. Learn., pp. 19730–19742. Li, J., Li, D., Xiong, C., Hoi, S.,
2023
-
[9]
Lost in the Middle: How Language Models Use Long Contexts
Lost in the middle: How language models use long contexts. arXiv:2307.03172 . Liu, S., Cheng, H., Liu, H., Zhang, H., Li, F., Ren, T., Zou, X., Yang, J., Su, H., Zhu, J., et al.,
work page internal anchor Pith review arXiv
-
[10]
Fine-Grained Visual Classification of Aircraft
Fine-grained visual classification of aircraft. arXiv:1306.5151 . Miller, G.A.,
work page internal anchor Pith review arXiv
-
[11]
Communications of the ACM 38, 39–41
Wordnet: A lexical database for english. Communications of the ACM 38, 39–41. doi:10.1145/219717.219748. Wang et al.:Preprint Page 14 of 15 Interpretable Prompt Learning Mitrovic, M., Kazemi, E., Zadimoghaddam, M., Karbasi, A.,
-
[12]
An analysis of approximations for maximizing submodular set functions—i. Math. Program. 14, 265–294. Nilsback,M.E.,Zisserman,A.,2008. Automatedflowerclassificationoveralargenumberofclasses,in:Proc.IEEE6thIndianConf.Comput.Vis. Graph. Image Process., pp. 722–729. Park, J., Ko, J., Kim, H.J.,
2008
-
[13]
IEEE Conf
Cats and dogs, in: Proc. IEEE Conf. Comput. Vis. Pattern Recognit., pp. 3498–3505. Radford,A.,Kim,J.W.,Hallacy,C.,Ramesh,A.,Goh,G.,Agarwal,S.,Sastry,G.,Askell,A.,Mishkin,P.,Clark,J.,etal.,2021.Learningtransferable visual models from natural language supervision, in: Proc. Int. Conf. Mach. Learn., pp. 8748–8763. Recht, B., Roelofs, R., Schmidt, L., Shankar, V.,
2021
-
[14]
apricot: Submodular selection for data summarization in python. J. Mach. Learn. Res. 21, 1–6. Shinde,G.,Ravi,A.,Dey,E.,Sakib,S.,Rampure,M.,Roy,N.,2025. Asurveyonefficientvision-languagemodels. WileyInterdisciplinaryReviews: Data Mining and Knowledge Discovery 15, e70036. Soomro, K., Zamir, A.R., Shah, M.,
2025
-
[15]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv:1212.0402 . Sung,Y.L.,Cho,J.,Bansal,M.,2022. Vl-adapter:Parameter-efficienttransferlearningforvision-and-languagetasks,in:Proc.IEEEConf.Comput. Vis. Pattern Recognit., pp. 5227–5237. Tschiatschek, S., Iyer, R.K., Wei, H., Bilmes, J.A.,
work page internal anchor Pith review arXiv 2022
-
[16]
Sun database: Large-scale scene recognition from abbey to zoo, in: Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., pp. 3485–3492. Xing,Y.,Wu,Q.,Cheng,D.,Zhang,S.,Liang,G.,Wang,P.,Zhang,Y.,2024. Dualmodalityprompttuningforvision-languagepre-trainedmodel. IEEE Trans. Multimedia 26, 2056–2068. doi:10.1109/TMM.2023.3291588. Yang,L.,Zhang,R.Y.,Wa...
-
[17]
Filip: Fine-grained interactive language-image pre-training
Filip: Fine-grained interactive language-image pre-training. arXiv:2111.07783 . Yu, J., Wang, Z., Vasudevan, V., Yeung, L., Seyedhosseini, M., Wu, Y.,
-
[18]
Coca: Contrastive captioners are image- text foundation models
Coca: Contrastive captioners are image-text foundation models. arXiv:2205.01917 . Yuan, L., Chen, D., Chen, Y.L., Codella, N., Dai, X., Gao, J., Hu, H., Huang, X., Li, B., Li, C., et al.,
-
[19]
Florence: A new foundation model for computer vision
Florence: A new foundation model for computer vision. arXiv:2111.11432 . Zhai,X.,Wang,X.,Mustafa,B.,Steiner,A.,Keysers,D.,Kolesnikov,A.,Beyer,L.,2022. Lit:Zero-shottransferwithlocked-imagetexttuning,in: Proc. IEEE Conf. Comput. Vis. Pattern Recognit., pp. 18123–18133. Zhang, W., Wu, L., Zhang, Z., Yu, T., Ma, C., Jin, X., Yang, X., Zeng, W.,
-
[20]
Unleash the power of vision-language models by visual attention prompt and multimodal interaction. IEEE Trans. Multimedia 27, 2399–2411. doi:10.1109/TMM.2024.3521785. Zheng, Y., Wang, S., Gao, Y.,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.