Recognition: 2 theorem links
· Lean TheoremGround4D: Spatially-Grounded Feedforward 4D Reconstruction for Unstructured Off-Road Scenes
Pith reviewed 2026-05-08 18:42 UTC · model grok-4.3
The pith
Ground4D resolves temporal conflicts in off-road 4D reconstruction by partitioning Gaussians into spatial voxels for localized temporal attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
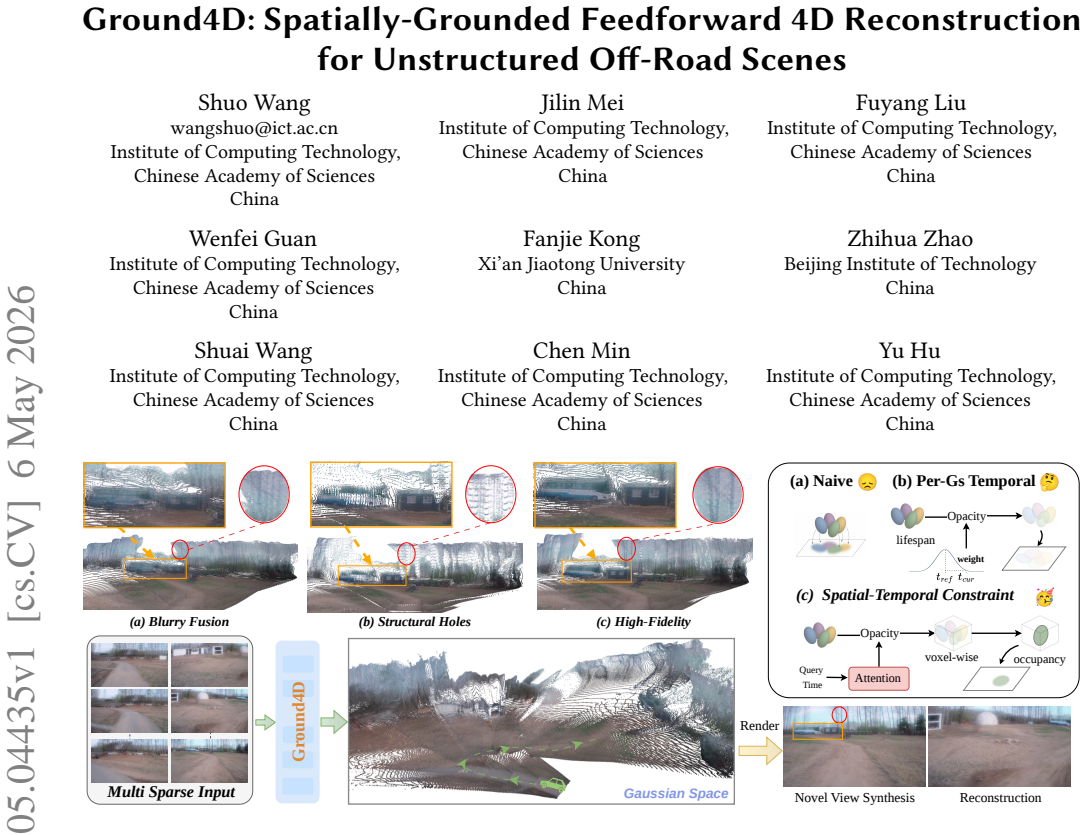
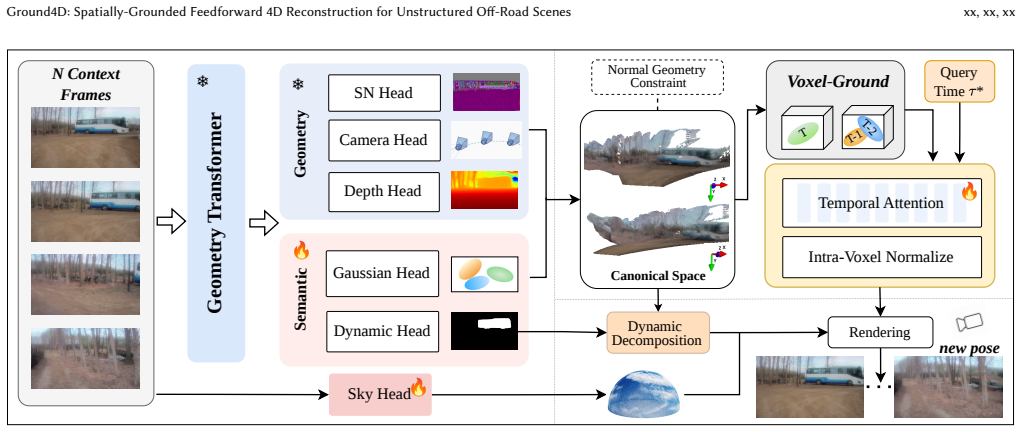
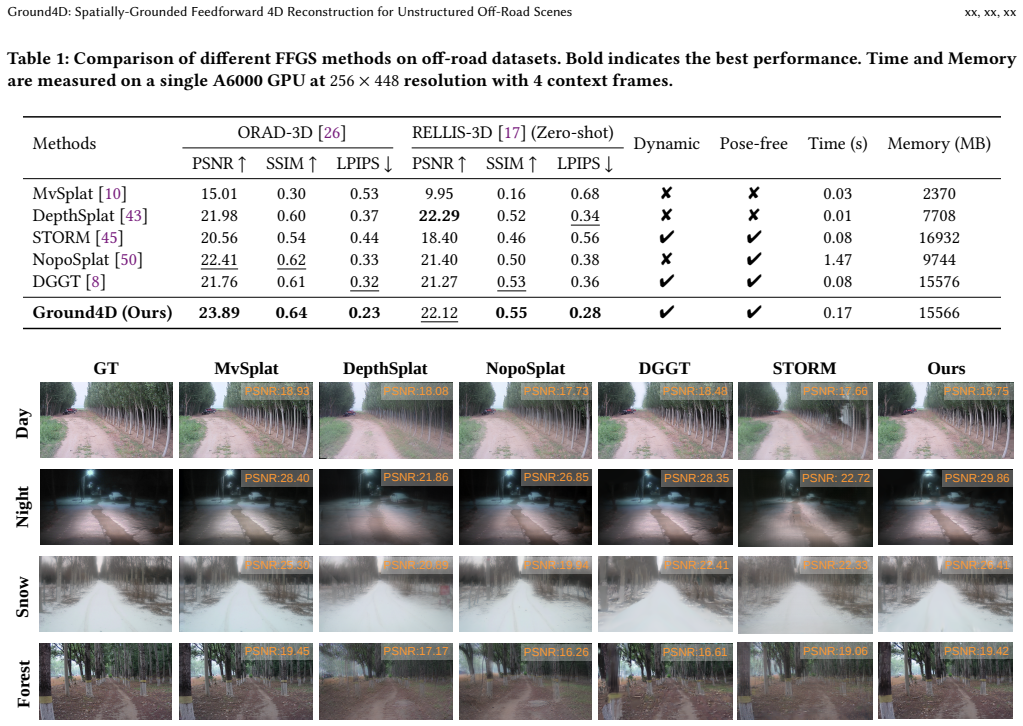
Ground4D is a spatially-grounded 4D feedforward framework that resolves conflicting Gaussian observations across timestamps in pose-free off-road scenes. It does so by introducing voxel-grounded temporal Gaussian aggregation, which divides the canonical space into voxels and applies query-conditioned temporal attention inside each voxel with intra-voxel softmax normalization. Surface normal cues are added as auxiliary guidance to regularize Gaussian geometry. Experiments on ORAD-3D and RELLIS-3D show consistent outperformance over prior feedforward methods and zero-shot generalization to unseen domains.
What carries the argument
Voxel-grounded temporal Gaussian aggregation, which partitions the canonical Gaussian space into spatial voxels and performs query-conditioned temporal attention within each voxel using intra-voxel softmax normalization to make temporal selectivity and spatial occupancy reinforce each other, aided by surface normal cues.
If this is right
- Reconstruction quality improves over existing feedforward Gaussian methods on off-road datasets.
- The model generalizes zero-shot to unseen off-road domains without retraining.
- Temporal conflicts from ego-motion and non-rigid motion are reduced, avoiding both over-smoothing and structural breaks.
- Pose-free operation becomes feasible in unstructured terrain where camera calibration is unreliable.
Where Pith is reading between the lines
- The same voxel-localized conditioning could be tested on other dynamic settings such as forests or construction sites to check whether the spatial partitioning transfers.
- Because the method works without poses, it might support mapping pipelines that rely only on visual odometry in GPS-denied areas.
- Intra-voxel normalization could be adapted to other attention-based 3D models to enforce locality without full global recomputation.
Load-bearing premise
That localizing temporal attention inside spatial voxels together with surface normal guidance can remove conflicting observations across time without introducing new inconsistencies or requiring scene-specific tuning.
What would settle it
Persistent structural artifacts or over-smoothed surfaces appearing in renderings from a high-jitter off-road sequence when the voxel aggregation and normal cues are applied would show that the method does not resolve temporal conflicts as claimed.
Figures

read the original abstract
Feedforward Gaussian Splatting has recently emerged as an efficient paradigm for 4D reconstruction in autonomous driving. However, in unstructured off-road scenes, its performance degrades due to high-frequency geometry, ego-motion jitter, and increased non-rigid dynamics. These factors introduce conflicting Gaussian observations across timestamps, leading to either over-smoothed renderings or structural artifacts. To address this issue, we propose Ground4D, a spatially-grounded 4D feedforward framework for pose-free off-road reconstruction. The key idea is to resolve temporal conflicts through spatially localized conditioning. Specifically, we introduce voxel-grounded temporal Gaussian aggregation, which partitions the canonical Gaussian space into spatial voxels and performs query-conditioned temporal attention within each voxel. Intra-voxel softmax normalization ensures that temporal selectivity and spatial occupancy become mutually reinforcing rather than conflicting. We furthermore introduce surface normal cues as auxiliary geometric guidance to regularize the geometry of Gaussian primitives. Extensive experiments on ORAD-3D and RELLIS-3D demonstrate that Ground4D consistently outperforms existing feedforward methods in reconstruction quality and generalizes zero-shot to unseen off-road domains. Project page and code:https://github.com/wsnbws/Ground4D.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Ground4D, a spatially-grounded feedforward 4D Gaussian Splatting framework for pose-free reconstruction in unstructured off-road scenes. It introduces voxel-grounded temporal Gaussian aggregation that partitions canonical space into voxels and applies query-conditioned temporal attention within each voxel, combined with intra-voxel softmax normalization to resolve conflicting Gaussian observations arising from high-frequency geometry, ego-motion, and non-rigid dynamics. Surface normal cues are added as auxiliary guidance for geometry regularization. Experiments on ORAD-3D and RELLIS-3D are reported to show consistent outperformance over existing feedforward methods together with zero-shot generalization to unseen off-road domains.
Significance. If the quantitative results hold, the work would advance feedforward 4D reconstruction for challenging unstructured environments relevant to off-road autonomy and robotics. The explicit spatial localization of temporal attention and the release of code and project page are positive features that support reproducibility and allow direct testing of the proposed components.
major comments (1)
- [§3.2] §3.2 (voxel-grounded temporal aggregation and intra-voxel softmax): the claim that intra-voxel softmax makes temporal selectivity and spatial occupancy mutually reinforcing is load-bearing for the central contribution, yet the manuscript provides no targeted analysis or visualization demonstrating that the normalization avoids occupancy discontinuities or over-smoothing when Gaussians straddle voxel boundaries under non-rigid motion and high-frequency off-road geometry. This assumption directly affects whether the reported quality gains are attributable to the mechanism rather than trading one class of artifacts for another.
minor comments (1)
- The abstract states outperformance and zero-shot generalization but does not report any numerical metrics, error bars, or baseline comparisons; adding a concise quantitative highlight would improve readability without altering the technical content.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address the major comment point by point below and will revise the paper to incorporate additional analysis as suggested.
read point-by-point responses
-
Referee: [§3.2] §3.2 (voxel-grounded temporal aggregation and intra-voxel softmax): the claim that intra-voxel softmax makes temporal selectivity and spatial occupancy mutually reinforcing is load-bearing for the central contribution, yet the manuscript provides no targeted analysis or visualization demonstrating that the normalization avoids occupancy discontinuities or over-smoothing when Gaussians straddle voxel boundaries under non-rigid motion and high-frequency off-road geometry. This assumption directly affects whether the reported quality gains are attributable to the mechanism rather than trading one class of artifacts for another.
Authors: We agree that the manuscript lacks targeted visualizations or ablation analysis specifically demonstrating the effect of intra-voxel softmax on occupancy discontinuities and over-smoothing at voxel boundaries, particularly under non-rigid motion and high-frequency geometry. The design rationale in §3.2 is that performing query-conditioned temporal attention and softmax normalization strictly within each voxel localizes the temporal selection, preventing global conflicts from propagating across space and thereby making selectivity and occupancy mutually reinforcing. However, without explicit boundary-focused visualizations (e.g., Gaussian occupancy heatmaps or before/after renderings in dynamic off-road sequences), it is difficult for readers to verify that the gains are not simply trading one artifact class for another. In the revised version we will add a dedicated analysis subsection (or expanded figure in §3.2 and §4) containing: (i) side-by-side occupancy maps with and without intra-voxel softmax on sequences exhibiting non-rigid dynamics, (ii) zoomed renderings highlighting voxel-boundary regions, and (iii) quantitative boundary-consistency metrics. This will directly substantiate the load-bearing claim. revision: yes
Circularity Check
No significant circularity; method is a novel architectural proposal with independent components
full rationale
The paper presents Ground4D as a new feedforward framework introducing voxel-grounded temporal Gaussian aggregation, intra-voxel softmax normalization, and surface normal cues as explicit, non-reductive mechanisms to address temporal conflicts in off-road scenes. No equations or claims reduce a 'prediction' or result to fitted inputs by construction, nor do self-citations bear the central load; the derivation chain consists of proposed architectural choices justified by problem analysis rather than tautological redefinitions or renamings. The reported outperformance on ORAD-3D/RELLIS-3D is positioned as empirical validation of the new components, not a forced outcome of prior fits. This is the common case of a self-contained technical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jonathan T Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P Srinivasan. 2021. Mip-nerf: A multiscale repre- sentation for anti-aliasing neural radiance fields. InProceedings of the IEEE/CVF international conference on computer vision. 5855–5864
2021
-
[2]
Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. 2022. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5470–5479
2022
-
[3]
Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Pe- ter Hedman. 2023. Zip-nerf: Anti-aliased grid-based neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 19697– 19705
2023
-
[4]
Yohann Cabon, Lucas Stoffl, Leonid Antsfeld, Gabriela Csurka, Boris Chidlovskii, Jerome Revaud, and Vincent Leroy. 2025. Must3r: Multi-view network for stereo 3d reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1050–1060
2025
-
[5]
David Charatan, Sizhe Lester Li, Andrea Tagliasacchi, and Vincent Sitzmann
-
[6]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 19457–19467
-
[7]
Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su. 2022. Tensorf: Tensorial radiance fields. InEuropean conference on computer vision. Springer, 333–350
2022
-
[8]
Anpei Chen, Zexiang Xu, Fuqiang Zhao, Xiaoshuai Zhang, Fanbo Xiang, Jingyi Yu, and Hao Su. 2021. Mvsnerf: Fast generalizable radiance field reconstruction from multi-view stereo. InProceedings of the IEEE/CVF international conference on computer vision. 14124–14133
2021
- [9]
-
[10]
Yue Chen, Xingyu Chen, Anpei Chen, Gerard Pons-Moll, and Yuliang Xiu. 2025. Feat2gs: Probing visual foundation models with gaussian splatting. InProceedings of the Computer Vision and Pattern Recognition Conference. 6348–6361
2025
-
[11]
Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, and Jianfei Cai. 2024. Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. InEuropean conference on computer vision. Springer, 370–386
2024
- [12]
- [13]
-
[14]
Sara Fridovich-Keil, Alex Yu, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. 2022. Plenoxels: Radiance fields without neural net- works. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5501–5510
2022
-
[15]
Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao
-
[16]
InACM SIGGRAPH 2024 conference papers
2d gaussian splatting for geometrically accurate radiance fields. InACM SIGGRAPH 2024 conference papers. 1–11
2024
- [17]
-
[18]
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, et al. 2025. Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.ACM Transactions on Graphics (TOG)44, 6 (2025), 1–16
2025
-
[19]
Peng Jiang, Philip Osteen, Maggie Wigness, and Srikanth Saripalli. 2021. Rellis-3d dataset: Data, benchmarks and analysis. In2021 IEEE international conference on robotics and automation (ICRA). IEEE, 1110–1116
2021
-
[20]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al
-
[21]
Graph.42, 4 (2023), 139–1
3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph.42, 4 (2023), 139–1
2023
-
[22]
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. 2024. Grounding image matching in 3d with mast3r. InEuropean conference on computer vision. Springer, 71–91
2024
-
[23]
Yang Liu, Chuanchen Luo, Zimo Tang, Junran Peng, and Zhaoxiang Zhang
- [24]
- [25]
-
[26]
Tao Lu, Mulin Yu, Linning Xu, Yuanbo Xiangli, Limin Wang, Dahua Lin, and Bo Dai. 2024. Scaffold-gs: Structured 3d gaussians for view-adaptive rendering. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 20654–20664
2024
-
[27]
Xiaoyang Lyu, Yang-Tian Sun, Yi-Hua Huang, Xiuzhe Wu, Ziyi Yang, Yilun Chen, Jiangmiao Pang, and Xiaojuan Qi. 2024. 3dgsr: Implicit surface reconstruction with 3d gaussian splatting.ACM Transactions on Graphics (TOG)43, 6 (2024), 1–12
2024
-
[28]
Ricardo Martin-Brualla, Noha Radwan, Mehdi SM Sajjadi, Jonathan T Barron, Alexey Dosovitskiy, and Daniel Duckworth. 2021. Nerf in the wild: Neural radiance fields for unconstrained photo collections. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 7210–7219
2021
-
[29]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2021. Nerf: Representing scenes as neural radiance fields for view synthesis.Commun. ACM65, 1 (2021), 99–106
2021
- [30]
-
[31]
Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. 2022. In- stant neural graphics primitives with a multiresolution hash encoding.ACM transactions on graphics (TOG)41, 4 (2022), 1–15
2022
-
[32]
Julian Ost, Fahim Mannan, Nils Thuerey, Julian Knodt, and Felix Heide. 2021. Neural scene graphs for dynamic scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2856–2865
2021
-
[33]
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. 2021. Vision transformers for dense prediction. InProceedings of the IEEE/CVF international conference on computer vision. 12179–12188
2021
-
[34]
Konstantinos Rematas, Andrew Liu, Pratul P Srinivasan, Jonathan T Barron, Andrea Tagliasacchi, Thomas Funkhouser, and Vittorio Ferrari. 2022. Urban radiance fields. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 12932–12942
2022
-
[35]
Johannes L Schonberger and Jan-Michael Frahm. 2016. Structure-from-motion revisited. InProceedings of the IEEE conference on computer vision and pattern recognition. 4104–4113
2016
- [36]
- [37]
-
[38]
Matthew Tancik, Vincent Casser, Xinchen Yan, Sabeek Pradhan, Ben Mildenhall, Pratul P Srinivasan, Jonathan T Barron, and Henrik Kretzschmar. 2022. Block- nerf: Scalable large scene neural view synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 8248–8258
2022
-
[39]
Zhenggang Tang, Yuchen Fan, Dilin Wang, Hongyu Xu, Rakesh Ranjan, Alexan- der Schwing, and Zhicheng Yan. 2025. Mv-dust3r+: Single-stage scene recon- struction from sparse views in 2 seconds. InProceedings of the Computer Vision and Pattern Recognition Conference. 5283–5293
2025
-
[40]
Qijian Tian, Xin Tan, Yuan Xie, and Lizhuang Ma. 2025. Drivingforward: Feed- forward 3d gaussian splatting for driving scene reconstruction from flexible surround-view input. InProceedings of the AAAI Conference on Artificial Intelli- gence, Vol. 39. 7374–7382
2025
-
[41]
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rup- precht, and David Novotny. 2025. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference. 5294– 5306
2025
-
[42]
Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul P Srinivasan, Howard Zhou, Jonathan T Barron, Ricardo Martin-Brualla, Noah Snavely, and Thomas Funkhouser. 2021. Ibrnet: Learning multi-view image-based rendering. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4690–4699
2021
-
[43]
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. 2024. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 20697–20709
2024
-
[44]
Dongxu Wei, Zhiqi Li, and Peidong Liu. 2025. Omni-scene: Omni-gaussian representation for ego-centric sparse-view scene reconstruction. InProceedings of the Computer Vision and Pattern Recognition Conference. 22317–22327
2025
-
[45]
Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, and Xinggang Wang. 2024. 4d gaussian splatting for real-time dynamic scene rendering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 20310–20320
2024
-
[46]
Zirui Wu, Tianyu Liu, Liyi Luo, Zhide Zhong, Jianteng Chen, Hongmin Xiao, Chao Hou, Haozhe Lou, Yuantao Chen, Runyi Yang, et al. 2023. Mars: An instance- aware, modular and realistic simulator for autonomous driving. InCAAI Interna- tional Conference on Artificial Intelligence. Springer, 3–15
2023
-
[47]
Haofei Xu, Songyou Peng, Fangjinhua Wang, Hermann Blum, Daniel Barath, Andreas Geiger, and Marc Pollefeys. 2025. Depthsplat: Connecting gaussian splatting and depth. InProceedings of the Computer Vision and Pattern Recognition Conference. 16453–16463
2025
-
[48]
Yunzhi Yan, Haotong Lin, Chenxu Zhou, Weijie Wang, Haiyang Sun, Kun Zhan, Xianpeng Lang, Xiaowei Zhou, and Sida Peng. 2024. Street gaussians: Model- ing dynamic urban scenes with gaussian splatting. InEuropean Conference on Computer Vision. Springer, 156–173
2024
- [49]
- [50]
-
[51]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. 2024. Depth anything v2.Advances in Neural Information Processing Systems37 (2024), 21875–21911
2024
-
[52]
Ze Yang, Yun Chen, Jingkang Wang, Sivabalan Manivasagam, Wei-Chiu Ma, Anqi Joyce Yang, and Raquel Urtasun. 2023. Unisim: A neural closed-loop sensor simulator. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1389–1399
2023
-
[53]
Ziyi Yang, Xinyu Gao, Wen Zhou, Shaohui Jiao, Yuqing Zhang, and Xiaogang Jin. 2024. Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 20331–20341
2024
- [54]
-
[55]
Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. 2021. pixelnerf: Neural radiance fields from one or few images. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4578–4587
2021
-
[56]
Zehao Yu, Anpei Chen, Binbin Huang, Torsten Sattler, and Andreas Geiger. 2024. Mip-splatting: Alias-free 3d gaussian splatting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 19447–19456
2024
-
[57]
Zehao Yu, Torsten Sattler, and Andreas Geiger. 2024. Gaussian opacity fields: Efficient adaptive surface reconstruction in unbounded scenes.ACM Transactions on Graphics (ToG)43, 6 (2024), 1–13
2024
- [58]
- [59]
-
[60]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang
-
[61]
InProceedings of the IEEE conference on computer vision and pattern recognition
The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition. 586–595
-
[62]
Xiaoyu Zhou, Zhiwei Lin, Xiaojun Shan, Yongtao Wang, Deqing Sun, and Ming- Hsuan Yang. 2024. Drivinggaussian: Composite gaussian splatting for surround- ing dynamic autonomous driving scenes. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 21634–21643
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.