Recognition: unknown
DoGMaTiQ: Automated Generation of Question-and-Answer Nuggets for Report Evaluation
Pith reviewed 2026-05-08 17:26 UTC · model grok-4.3
The pith
An automated three-stage pipeline generates question-answer nuggets that enable reliable automatic evaluation of reports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
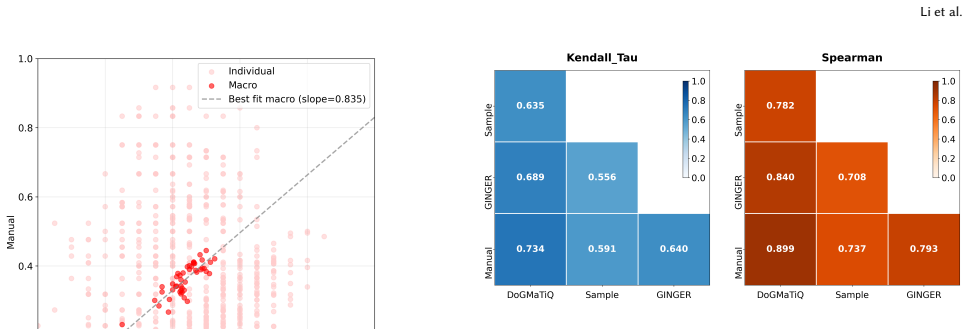
The authors claim that their three-stage DoGMaTiQ pipeline produces QA nugget sets whose quality is close enough to manual curation that they support fully automatic report evaluation, yielding strong rank correlations with human judgments on the NeuCLIR and RAGTIME cross-lingual shared tasks.
What carries the argument
The DoGMaTiQ three-stage pipeline that performs document-grounded nugget generation, paraphrase clustering, and principled subselection to create QA-based nuggets.
If this is right
- Report evaluation can be performed on entirely new topics without first collecting manual nuggets.
- Cross-lingual collections become practical to evaluate at scale because the pipeline operates on source documents in multiple languages.
- System rankings produced by the automatic method remain stable even when a few systems behave as outliers.
- The overall success of the evaluation depends primarily on the strength of the language model used in the first stage.
Where Pith is reading between the lines
- The same pipeline could be tested on evaluation tasks for generated summaries or answers outside the report domain.
- Replacing the current evaluation framework with other nugget-based scorers might produce different correlation patterns worth measuring.
- Making nugget creation fully automatic could let researchers build and refresh large test collections more frequently.
Load-bearing premise
That nuggets generated by large language models from documents, after clustering and quality filtering, match the reliability of manually curated nuggets for evaluation purposes.
What would settle it
A new cross-lingual test collection on which the rank correlation between DoGMaTiQ-based automatic scores and human judgments drops substantially below the levels reported in the experiments.
Figures




read the original abstract
Evaluation of long-form, citation-backed reports has lately received significant attention due to the wide-scale adoption of retrieval-augmented generation (RAG) systems. Core to many evaluation frameworks is the use of atomic facts, or nuggets, to assess a report's coverage of query-relevant information attested in the underlying collection. While nuggets have traditionally been represented as short statements, recent work has used question-answer (QA) representations, enabling fine-grained evaluations that decouple the information need (i.e. the question) from the potentially diverse content that satisfies it (i.e. its answers). A persistent challenge for nugget-based evaluation is the need to manually curate sets of nuggets for each topic in a test collection -- a laborious process that scales poorly to novel information needs. This challenge is acute in cross-lingual settings, where information is found in multilingual source documents. Accordingly, we introduce DoGMaTiQ, a pipeline for generating high-quality QA-based nugget sets in three stages: (1) document-grounded nugget generation, (2) paraphrase clustering, and (3) nugget subselection based on principled quality criteria. We integrate DoGMaTiQ nuggets with AutoArgue -- a recent nugget-based evaluation framework -- to enable fully automatic evaluation of generated reports. We conduct extensive experiments on two cross-lingual TREC shared tasks, NeuCLIR and RAGTIME, showing strong rank correlations with both human-in-the-loop and fully manual judgments. Finally, detailed analysis of our pipeline reveals that a strong LLM nugget generator is key, and that the system rankings induced by DoGMaTiQ are robust to outlier systems. We facilitate future research in report evaluation by publicly releasing our code and artifacts at https://github.com/manestay/dogmatiq.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DoGMaTiQ, a three-stage pipeline for automatically generating QA-based nugget sets to support evaluation of long-form, citation-backed reports produced by RAG systems. The stages consist of document-grounded nugget generation using LLMs, paraphrase clustering, and subselection according to quality criteria. These nuggets are integrated with the existing AutoArgue framework to enable fully automatic evaluation. Experiments on the cross-lingual TREC tasks NeuCLIR and RAGTIME demonstrate strong rank correlations with both human-in-the-loop and fully manual judgments; additional analysis highlights the importance of a strong LLM generator and robustness to outlier systems. Code and artifacts are publicly released.
Significance. If the reported correlations hold under the full experimental protocol, the work is significant because it directly tackles the scalability bottleneck of manual nugget curation in report evaluation, particularly in cross-lingual settings where human effort is especially costly. The public release of code and artifacts is a clear strength that enables reproducibility and follow-on research. The approach of decoupling information needs (questions) from answers via QA nuggets, combined with principled subselection, offers a practical advance over purely statement-based nuggets for fine-grained automatic assessment.
minor comments (3)
- [Abstract] The abstract states that 'a strong LLM nugget generator is key' and that rankings are 'robust to outlier systems,' but does not report the specific correlation coefficients, p-values, or the exact set of systems tested. Adding these quantitative details (or directing readers to the relevant table/figure) would strengthen the central empirical claim.
- The three-stage pipeline is described at a high level. A schematic diagram illustrating the flow from document-grounded generation through clustering to subselection, including the inputs and outputs at each stage, would improve clarity for readers unfamiliar with nugget-based evaluation.
- The integration with AutoArgue is mentioned but not detailed; a short subsection or paragraph clarifying how DoGMaTiQ nuggets are formatted and fed into the existing framework (e.g., any required adaptations to the nugget representation) would help readers replicate the end-to-end evaluation.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of DoGMaTiQ and for recommending minor revision. The provided summary correctly captures the three-stage pipeline, its integration with AutoArgue, the experimental results on NeuCLIR and RAGTIME, and the public release of code and artifacts. Since the report lists no major comments, we have no specific points requiring rebuttal or defense.
Circularity Check
No significant circularity; pipeline validated on external benchmarks
full rationale
The paper presents a three-stage pipeline (document-grounded nugget generation, paraphrase clustering, and quality-based subselection) for creating QA nuggets, integrates it with the cited AutoArgue framework, and evaluates via rank correlations on two independent TREC shared tasks (NeuCLIR and RAGTIME) against human judgments. No equations, fitted parameters renamed as predictions, or self-definitional reductions appear in the described derivation. The central claim rests on empirical results from external collections rather than reducing to inputs by construction or self-citation chains. Minor self-citations (if any for AutoArgue) are not load-bearing for the novelty or validation of DoGMaTiQ itself.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large language models can reliably produce document-grounded questions and answers that capture query-relevant information from source documents.
- domain assumption Paraphrase clustering followed by quality-based subselection yields a representative nugget set comparable to human curation.
Reference graph
Works this paper leans on
-
[1]
2024.Introducing Claude 3.5 Sonnet
Anthropic. 2024.Introducing Claude 3.5 Sonnet. https://www.anthropic.com/ news/claude-3-5-sonnet Accessed: 2026-01-20
2024
-
[2]
Negar Arabzadeh and Charles L. A. Clarke. 2025. Benchmarking LLM-Based Relevance Judgment Methods. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’25). ACM. doi:10.1145/3726302.3744382
- [3]
-
[4]
Daniel Deutsch, Tania Bedrax-Weiss, and Dan Roth. 2021. Towards question- answering as an automatic metric for evaluating the content quality of a summary. Transactions of the Association for Computational Linguistics9 (2021), 774–789
2021
-
[5]
Laura Dietz. 2024. A workbench for autograding retrieve/generate systems. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1963–1972
2024
-
[6]
Laura Dietz, Bryan Li, Gabrielle Liu, Jia-Huei Ju, Eugene Yang, Dawn Lawrie, William Walden, and James Mayfield. 2026. Incorporating Q&A Nuggets into Retrieval-Augmented Generation. InProceedings of the 48th European Conference on Information Retrieval (ECIR 2026)
2026
-
[7]
Laura Dietz, Bryan Li, Eugene Yang, Dawn Lawrie, William Walden, and James Mayfield. 2026. Insider Knowledge: How Much Can RAG Systems Gain from Evaluation Secrets?. InProceedings of the 48th European Conference on Information Retrieval (ECIR 2026)
2026
-
[8]
Matan Eyal, Tal Baumel, and Michael Elhadad. 2019. Question answering as an automatic evaluation metric for news article summarization. In2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL HLT 2019. Association for Computational Linguistics (ACL), 3938–3948
2019
-
[9]
Naghmeh Farzi and Laura Dietz. 2024. Exam++: Llm-based answerability met- rics for ir evaluation. InProceedings of LLM4Eval: The First Workshop on Large Language Models for Evaluation in Information Retrieval
2024
-
[10]
Naghmeh Farzi and Laura Dietz. 2024. Pencils down! automatic rubric-based evaluation of retrieve/generate systems. InProceedings of the 2024 ACM SIGIR International Conference on Theory of Information Retrieval. 175–184
2024
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schel- ten, Alex Vaughan, et al . 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review arXiv 2024
-
[12]
Shash Guo, Lizi Liao, Cuiping Li, and Tat-Seng Chua. 2024. A survey on neural question generation: methods, applications, and prospects. InProceedings of the Li et al. Thirty-Third International Joint Conference on Artificial Intelligence(Jeju, Korea) (IJCAI ’24). Article 889, 10 pages. doi:10.24963/ijcai.2024/889
- [13]
-
[14]
Kalpesh Krishna and Mohit Iyyer. 2019. Generating Question-Answer Hi- erarchies. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Anna Korhonen, David Traum, and Lluís Màrquez (Eds.). Association for Computational Linguistics, Florence, Italy, 2321–2334. doi:10.18653/v1/P19-1224
-
[15]
Weronika Łajewska and Krisztian Balog. 2025. Ginger: Grounded information nugget-based generation of responses. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2723–2727
2025
- [16]
-
[17]
Dawn Lawrie, Sean MacAvaney, James Mayfield, Luca Soldaini, Eugene Yang, and Andrew Yates. 2025. Overview of the trec 2025 RAGTIME track.The Thirty-Fourth Text REtrieval Conference Proceedings (TREC2025)(2025)
2025
-
[18]
Bryan Li and Chris Callison-Burch. 2023. PAXQA: Generating Cross-lingual Question Answering Examples at Training Scale. InFindings of the Association for Computational Linguistics: EMNLP 2023. 439–454
2023
-
[19]
Jimmy Lin and Dina Demner-Fushman. 2006. Will pyramids built of nuggets topple over?. InProceedings of the Human Language Technology Conference of the NAACL, Main Conference. 383–390
2006
-
[20]
Zefeng Lin, Weidong Chen, Yan Song, and Yongdong Zhang. 2024. Prompting Few-shot Multi-hop Question Generation via Comprehending Type-aware Se- mantics. InFindings of the Association for Computational Linguistics: NAACL 2024, Kevin Duh, Helena Gomez, and Steven Bethard (Eds.). Association for Computational Linguistics, Mexico City, Mexico, 3730–3740. doi:...
-
[21]
Wei Liu, Sony Trenous, Leonardo F. R. Ribeiro, Bill Byrne, and Felix Hieber. 2025. XRAG: Cross-lingual Retrieval-Augmented Generation. InFindings of the Associ- ation for Computational Linguistics: EMNLP 2025. Association for Computational Linguistics, Suzhou, China, 15669–15690. https://aclanthology.org/2025.findings- emnlp.849/
2025
-
[22]
Sean MacAvaney and Luca Soldaini. 2023. One-shot labeling for automatic rele- vance estimation. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2230–2235
2023
-
[23]
James Mayfield, Eugene Yang, Dawn Lawrie, Sean MacAvaney, Paul McNamee, Douglas W. Oard, Luca Soldaini, Ian Soboroff, Orion Weller, Efsun Kayi, Kate Sanders, Marc Mason, and Noah Hibbler. 2024. On the Evaluation of Machine- Generated Reports. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval(...
-
[24]
Ani Nenkova, Rebecca Passonneau, and Kathleen McKeown. 2007. The pyramid method: Incorporating human content selection variation in summarization evaluation.ACM Transactions on Speech and Language Processing (TSLP)4, 2 (2007), 4–es
2007
- [25]
-
[26]
Ronak Pradeep, Nandan Thakur, Shivani Upadhyay, Daniel Campos, Nick Craswell, Ian Soboroff, Hoa Trang Dang, and Jimmy Lin. 2025. The great nugget recall: Automating fact extraction and rag evaluation with large language models. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 180–190
2025
-
[27]
Shahzad K Rajput, V Pavlu, and Javed A Aslam. 2011. A nugget-based evaluation paradigm to address the scalability and reusability issues of information retrieval test collections. InProceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval. ACM, 1003–1012
2011
- [28]
-
[29]
Yuichi Sasazawa, Sho Takase, and Naoaki Okazaki. 2019. Neural Question Generation using Interrogative Phrases. InProceedings of the 12th International Conference on Natural Language Generation, Kees van Deemter, Chenghua Lin, and Hiroya Takamura (Eds.). Association for Computational Linguistics, Tokyo, Japan, 106–111. doi:10.18653/v1/W19-8613
- [30]
- [31]
-
[32]
Voorhees
Ellen M. Voorhees. 2003. Evaluating Answers to Definition Questions. InCom- panion Volume of the Proceedings of HLT-NAACL 2003 - Short Papers. 109–111. https://aclanthology.org/N03-2037/
2003
-
[33]
Ellen M Voorhees and Hoa Trang Dang. 2003. Overview of the TREC 2003 question answering track.. InTrec, Vol. 2003. 54–68
2003
-
[34]
William Walden, Marc Mason, Orion Weller, Laura Dietz, John Conroy, Neil Molino, Hannah Recknor, Bryan Li, Gabrielle Kaili-May Liu, Yu Hou, et al
-
[35]
Auto-argue: Llm-based report generation evaluation.arXiv preprint arXiv:2509.26184(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Eugene Yang, Dawn Lawrie, James Mayfield, Douglas W Oard, and Scott Miller
-
[37]
InEuropean Conference on Information Retrieval
Translate-distill: learning cross-language dense retrieval by translation and distillation. InEuropean Conference on Information Retrieval. Springer, 50–65
- [38]
-
[39]
Chao Zhou, Cheng Qiu, Lizhen Liang, and Daniel E Acuna. 2025. Paraphrase identification with deep learning: A review of datasets and methods.IEEE Access (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.