Recognition: unknown
KEET: Explaining Performance of GPU Kernels Using LLM Agents
Pith reviewed 2026-05-09 16:44 UTC · model grok-4.3
The pith
LLM agents can turn detailed GPU kernel performance profiles into natural language explanations that improve optimization quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
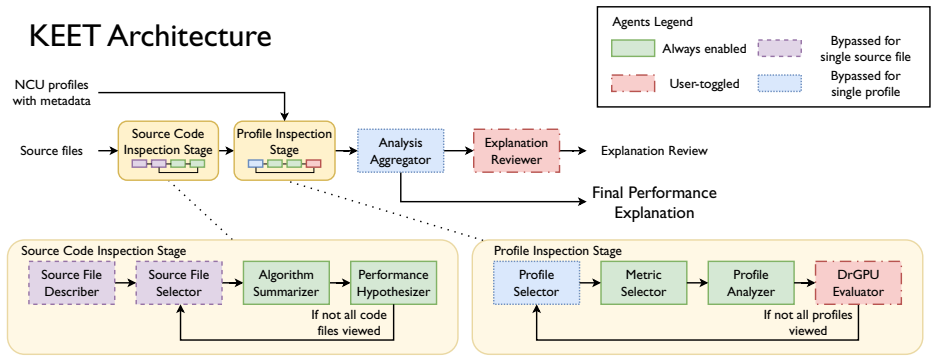
KEET is an LLM-based agentic framework that accepts Nsight Compute profiles of CUDA kernels and produces natural language explanations of performance issues together with optimization suggestions. The explanations are evaluated by supplying them as context to LLMs, where they measurably improve both code optimization outcomes and multiple-choice question answering performance. The framework additionally demonstrates utility when applied to large sets of profiles, yielding higher-quality optimization suggestions than would be obtained without the aggregated analysis.
What carries the argument
The LLM-based agentic framework that ingests profile data, reasons over it, and outputs grounded natural language explanations plus optimization suggestions.
If this is right
- Supplying the generated explanations as context measurably improves the quality of LLM-driven code optimizations for the evaluated CUDA kernels.
- The same explanations raise accuracy on multiple-choice questions about kernel performance.
- Processing large collections of profiles through the framework produces higher-quality optimization suggestions than single-profile analysis.
- Kernel developers receive automated natural language interpretations of data that would otherwise require extended manual inspection of graphical interfaces.
Where Pith is reading between the lines
- The approach could be extended to other profiling tools and GPU architectures beyond the NVIDIA H100 and Nsight Compute combination tested here.
- Embedding the generated explanations directly into development environments might enable interactive, profile-driven tuning loops.
- If the grounding holds, the method could lower the expertise barrier for achieving high performance in GPU programming.
- Aggregating explanations across many kernels might surface architecture-specific patterns that are difficult to detect from individual profiles.
Load-bearing premise
The LLM agents produce accurate interpretations of the profile data that are sufficiently grounded to improve real optimization results without introducing new errors or hallucinations.
What would settle it
A controlled comparison in which the same LLM optimization or question-answering tasks are run once with KEET explanations provided as context and once without them, showing no improvement or a decline in measured performance or accuracy.
Figures






read the original abstract
Performance profiles of GPU kernels generated by tools such as Nsight Compute are rich in detail but are often challenging to interpret. To achieve the best performance possible on a given GPU architecture, kernel developers need to spend significant time analyzing and comparing profiles in the tool's graphical interface to identify and understand kernel performance bottlenecks. Large Language Models (LLMs) have shown promise in understanding complex data and generating natural language explanations. In this paper, we propose the Kernel Execution Explanation Toolkit (KEET), an LLM-based agentic framework for interpreting Nsight Compute profiles to generate useful and data-grounded natural language explanations of performance issues in GPU kernels, and suggestions for optimizations. We evaluate \toolname using several CUDA kernels of varying complexity on NVIDIA H100 GPUs. We find that the generated explanations, when provided as context, improve the quality of LLM code optimization and multiple-choice question answering in downstream tasks. We further demonstrate that the tool can be used to interpret performance data from large sets of profiles to improve the quality of optimization suggestions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces KEET, an LLM-agentic framework that ingests Nsight Compute profiles of CUDA kernels and produces natural-language explanations of performance bottlenecks together with optimization suggestions. The authors evaluate the system on several kernels of varying complexity running on NVIDIA H100 GPUs and report that feeding the generated explanations as context improves the quality of LLM-driven code optimization and multiple-choice question answering; they further claim the tool scales to large profile collections.
Significance. If the central claim holds, the work offers a practical aid for kernel developers who currently spend substantial manual effort interpreting detailed performance counters. The agentic design and use of real hardware profiles are positive features; however, the significance is currently limited by the absence of quantitative evidence that the reported downstream gains arise from faithful, profile-specific interpretations rather than from the mere addition of plausible text.
major comments (2)
- [Evaluation] Evaluation section: the abstract states that explanations improve downstream tasks, yet supplies no concrete metrics for optimization quality or MCQA accuracy, no baselines (e.g., generic performance advice or no-context prompts), no statistical significance tests, and no independent measure of explanation factual correctness or grounding in the Nsight counters. This absence prevents verification of the headline empirical result.
- [Framework] Framework and evaluation description: no ablation or counterfactual experiment (e.g., real profiles versus hallucinated counters, or explanations versus generic advice) is reported to establish that any observed gains are causally attributable to accurate interpretation of the specific kernel metrics rather than to the presence of additional context.
minor comments (1)
- The abstract would benefit from a brief quantitative summary of the observed improvements (e.g., percentage gains or accuracy deltas) to allow readers to gauge effect size immediately.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important gaps in the evaluation that we will address through revisions to strengthen the empirical claims.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the abstract states that explanations improve downstream tasks, yet supplies no concrete metrics for optimization quality or MCQA accuracy, no baselines (e.g., generic performance advice or no-context prompts), no statistical significance tests, and no independent measure of explanation factual correctness or grounding in the Nsight counters. This absence prevents verification of the headline empirical result.
Authors: We acknowledge that the current manuscript presents the downstream improvements at a high level without reporting specific numerical metrics, baselines, statistical tests, or independent factual grounding checks. In the revised version we will expand the Evaluation section to include concrete metrics (e.g., mean percentage reduction in kernel runtime for the optimization task and accuracy percentages for MCQA), explicit baselines (no-context prompts and generic performance-advice prompts), paired statistical significance tests, and a manual verification of explanation factual correctness against the original Nsight Compute counters for a sampled subset of kernels. revision: yes
-
Referee: [Framework] Framework and evaluation description: no ablation or counterfactual experiment (e.g., real profiles versus hallucinated counters, or explanations versus generic advice) is reported to establish that any observed gains are causally attributable to accurate interpretation of the specific kernel metrics rather than to the presence of additional context.
Authors: We agree that the absence of ablations leaves open the possibility that gains stem from additional text rather than profile-specific interpretations. We will add two counterfactual experiments to the revised manuscript: (1) real Nsight profiles versus hallucinated or randomized counter values, and (2) KEET-generated explanations versus generic optimization advice, measuring the differential impact on the same downstream tasks to isolate the contribution of accurate, profile-grounded reasoning. revision: yes
Circularity Check
No circularity: empirical tool proposal with external evaluation
full rationale
The paper presents KEET as an LLM-agent framework for generating natural-language explanations from Nsight Compute profiles and evaluates its value via downstream tasks (LLM code optimization and MCQA). No mathematical derivations, equations, fitted parameters, or self-referential definitions appear in the provided text. Claims rest on empirical measurements against external benchmarks rather than any internal reduction to inputs or self-citation chains. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
November 2025 top500,
TOP500.org, “November 2025 top500,” 2025. [Online]. Available: https://www.top500.org/lists/top500/2025/11/
2025
-
[2]
Nvidia nsight compute,
NVIDIA, “Nvidia nsight compute,” https://developer.nvidia.com/nsight- compute
-
[3]
MLIR: Scaling Compiler Infrastructure for Domain Specific Computation
K. Zhou, X. Meng, R. Sai, and J. Mellor-Crummey, “Gpa: A gpu performance advisor based on instruction sampling,” in 2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). IEEE, 2021, pp. 115–125. [Online]. Available: https://doi.org/10.1109/CGO51591.2021.9370339
-
[4]
Lightweight kubernetes distributions: A performance comparison of microk8s, k3s, k0s, and microshift
Y . Hao, N. Jain, R. Van der Wijngaart, N. Saxena, Y . Fan, and X. Liu, “Drgpu: A top-down profiler for gpu applications,” inProceedings of the 2023 ACM/SPEC International Conference on Performance Engineering, 2023, pp. 43–53. [Online]. Available: https://doi.org/10.1145/3578244.3583736
-
[5]
Loki: A system for serving ml inference pipelines with hardware and accuracy scaling,
D. Nichols, J. H. Davis, Z. Xie, A. Rajaram, and A. Bhatele, “Can large language models write parallel code?” inProceedings of the 33rd International Symposium on High-Performance Parallel and Distributed Computing, ser. HPDC ’24. New York, NY , USA: Association for Computing Machinery, 2024. [Online]. Available: https://doi.org/10.1145/3625549.3658689
-
[6]
Large language model evaluation for high-performance computing software development,
W. F. Godoy, P. Valero-Lara, K. Teranishi, P. Balaprakash, and J. S. Vetter, “Large language model evaluation for high-performance computing software development,”Concurrency and Computation: Practice and Experience, vol. 36, no. 26, p. e8269, 2024. [Online]. Available: https://doi.org/10.1002/cpe.8269
-
[7]
P. Valero-Lara, W. F. Godoy, K. Teranishi, P. Balaprakash, and J. S. Vetter, “Chatblas: The first ai-generated and portable blas library,” inSC24-W: Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2024, pp. 19–24. [Online]. Available: https://doi.org/10.1109/SCW63240.2024.00010
-
[8]
R.i.p. geomean speedup use equal-work (or equal-time) harmonic mean speedup instead,
L. Eeckhout, “R.i.p. geomean speedup use equal-work (or equal-time) harmonic mean speedup instead,”IEEE Computer Architecture Letters, vol. 23, no. 1, pp. 78–82, 2024
2024
-
[9]
An automated tool for analysis and tuning of gpu-accelerated code in hpc applications,
K. Zhou, X. Meng, R. Sai, D. Grubisic, and J. Mellor-Crummey, “An automated tool for analysis and tuning of gpu-accelerated code in hpc applications,”IEEE Transactions on Parallel and Distributed Systems, vol. 33, no. 4, pp. 854–865, 2021. [Online]. Available: https://doi.org/10.1109/TPDS.2021.3094169
-
[10]
Gpcnet: designing a benchmark suite for inducing and measuring contention in hpc networks,
A. Bhatele, S. Brink, and T. Gamblin, “Hatchet: Pruning the overgrowth in parallel profiles,” inProceedings of the ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’19, Nov. 2019, lLNL-CONF-772402. [Online]. Available: http://doi.acm.org/10.1145/3295500.3356219
-
[11]
Pipit: Scripting the analysis of parallel execution traces,
A. Bhatele, R. Dhakal, A. Movsesyan, A. K. Ranjan, and O. Cankur, “Pipit: Scripting the analysis of parallel execution traces,” 2023
2023
-
[12]
Hpctoolkit: Tools for performance anal- ysis of optimized parallel programs,
L. Adhianto, S. Banerjee, M. Fagan, M. Krentel, G. Marin, J. Mellor- Crummey, and N. R. Tallent, “Hpctoolkit: Tools for performance anal- ysis of optimized parallel programs,”Concurrency and Computation: Practice and Experience, vol. 22, no. 6, pp. 685–701, 2010
2010
-
[13]
Refining hpctoolkit for application performance analysis at exascale,
L. Adhianto, J. Anderson, R. M. Barnett, D. Grbic, V . Indic, M. Krentel, Y . Liu, S. Milakovi ´c, W. Phan, and J. Mellor-Crummey, “Refining hpctoolkit for application performance analysis at exascale,”The Inter- national Journal of High Performance Computing Applications, vol. 38, no. 6, pp. 612–632, 2024
2024
-
[14]
Rocm compute profiler,
“Rocm compute profiler,” accessed: 2026-04-09. [On- line]. Available: https://rocm.docs.amd.com/projects/rocprofiler- compute/en/latest/index.html
2026
-
[15]
Paraver: A tool to visualize and analyze parallel code,
V . Pillet, J. Labarta, T. Cortes, and S. Girona, “Paraver: A tool to visualize and analyze parallel code,”WoTUG-18, vol. 44, 03 1995
1995
-
[16]
Easyview: Bringing performance profiles into integrated development environments,
Q. Zhao, M. Chabbi, and X. Liu, “Easyview: Bringing performance profiles into integrated development environments,” in2024 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). IEEE, 2024, pp. 386–398
2024
-
[17]
Automated performance analysis tools framework for hpc programs,
M. Keiff, F. V oigt, A. Fuchs, M. Kuhn, J. Squar, and T. Ludwig, “Automated performance analysis tools framework for hpc programs,” Procedia Computer Science, vol. 207, pp. 1067–1076, 2022
2022
-
[18]
Holistic trace analysis (hta): A library to an- alyze pytorch traces,
“Holistic trace analysis (hta): A library to an- alyze pytorch traces,” 2023. [Online]. Available: https://github.com/facebookresearch/HolisticTraceAnalysis
2023
-
[19]
The scalasca performance toolset architecture,
M. Geimer, F. Wolf, B. J. Wylie, E. Ábrahám, D. Becker, and B. Mohr, “The scalasca performance toolset architecture,”Concurrency and com- putation: Practice and experience, vol. 22, no. 6, pp. 702–719, 2010
2010
-
[20]
Cats: Memory and control flow tracing for whole-program performance analysis,
P. Schaad, T. Ben-Nun, and T. Hoefler, “Cats: Memory and control flow tracing for whole-program performance analysis,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2025, pp. 331–348
2025
-
[21]
Do large language models understand performance optimization?
B. Cui, T. Ramesh, O. Hernandez, and K. Zhou, “Do large language models understand performance optimization?” 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2503.13772
-
[22]
R. T. Lange, Q. Sun, A. Prasad, M. Faldor, Y . Tang, and D. Ha, “Towards robust agentic cuda kernel benchmarking, verification, and optimization,”arXiv preprint arXiv:2509.14279, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2509.14279
-
[23]
Opal: A modular framework for optimizing performance using analytics and llms,
M. Zaeed, T. Z. Islam, and V . In ¯di´c, “Opal: A modular framework for optimizing performance using analytics and llms,”arXiv preprint arXiv:2510.00932, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2510.00932
-
[24]
Towards automated kernel generation in the era of llms.arXiv preprint arXiv:2601.15727,
Y . Yu, P. Zang, C. H. Tsai, H. Wu, Y . Shen, J. Zhang, H. Wang, Z. Xiao, J. Shi, Y . Luoet al., “Towards automated kernel generation in the era of llms,”arXiv preprint arXiv:2601.15727, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2601.15727v1
-
[25]
W. Dai, H. Wu, Q. Yu, H.-a. Gao, J. Li, C. Jiang, W. Lou, Y . Song, H. Yu, J. Chenet al., “Cuda agent: Large-scale agentic rl for high- performance cuda kernel generation,”arXiv preprint arXiv:2602.24286,
-
[26]
[Online]. Available: https://doi.org/10.48550/arXiv.2602.24286
-
[27]
Cudaforge: An agent framework with hardware feedback for cuda kernel optimization, 2025
Z. Zhang, R. Wang, S. Li, Y . Luo, M. Hong, and C. Ding, “Cudaforge: An agent framework with hardware feedback for cuda kernel optimization,”arXiv preprint arXiv:2511.01884, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2511.01884
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.