Recognition: 2 theorem links
· Lean TheoremPen-Strategist: A Reasoning Framework for Penetration Testing Strategy Formation and Analysis
Pith reviewed 2026-05-08 17:44 UTC · model grok-4.3
The pith
Pen-Strategist improves automated penetration testing by deriving strategies through logical reasoning and converting them to precise actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
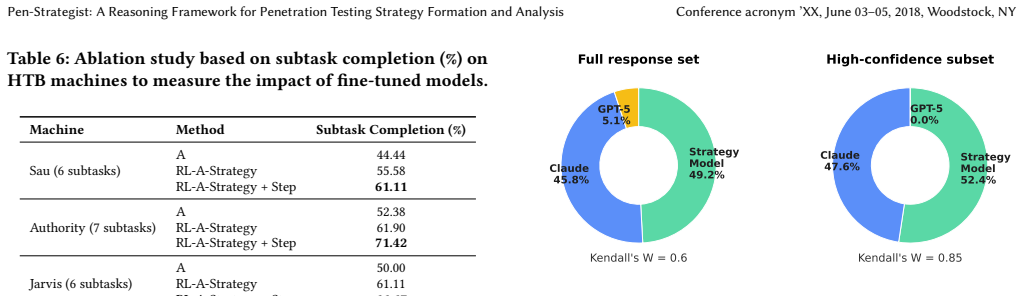
A domain-specific reasoning model fine-tuned on a custom dataset of logical explanations for pentesting scenarios derives more effective strategies, and when combined with a semantic CNN classifier for step selection, boosts performance in automated penetration testing tasks compared to standard large language models.
What carries the argument
Fine-tuned Qwen-3-14B model trained with reinforcement learning on a reasoning dataset for strategy generation, together with a CNN classifier for predicting actionable steps.
Load-bearing premise
The specific vulnerable machines and custom dataset used for evaluation accurately reflect the variety and complexity of real-world penetration testing scenarios.
What would settle it
Running the integrated Pen-Strategist framework on a new set of vulnerable machines outside the original test environment and observing whether the 47.5% improvement in subtask completion persists.
Figures











read the original abstract
Cyber threats are rapidly increasing, expanding their impact from large-scale enterprises to government services and individual users, making robust security systems increasingly essential. However, a significant shortage of skilled cybersecurity professionals exacerbates this challenge. While recent research has explored automating tasks such as penetration testing using LLM-based agents, existing frameworks often perform poorly due to limited capability in strategy formulation, domain-specific reasoning, and accurate action and tool selection. To overcome these limitations, we propose Pen-Strategist framework, consisting of a novel domain-specific reasoning model that derives pentesting strategies via logical reasoning and a classifier that converts the strategies into actionable steps. First, we construct a reasoning dataset containing logical explanations for both strategy derivation and step selection in pentesting scenarios. We then fine-tune a Qwen-3-14B model for strategy generation using reinforcement learning. Evaluation on the test split of the dataset demonstrates a 87% improvement in strategy derivation performance compared to the baseline. Furthermore, we integrate the fine-tuned Pen-Strategist model into existing automated pentesting frameworks, such as PentestGPT, and evaluate its performance on vulnerable machines, achieving a 47.5% improvement in subtask completion while surpassing the baseline GPT-5. Further experiments on the CTFKnow benchmark show an 18% performance gain over the base model. For step prediction, we train a semantic-based CNN classifier, which outperforms commercial LLMs by 28% and enhances execution stability. Finally, we conduct a user study to qualitatively assess the generated strategies, and Pen-Strategist demonstrates superior performance compared to the Claude-4.6-Sonnet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Pen-Strategist, a framework with a Qwen-3-14B model fine-tuned via reinforcement learning on a custom-constructed reasoning dataset to derive pentesting strategies through logical reasoning, paired with a semantic CNN classifier to map strategies to actionable steps. It reports an 87% improvement in strategy derivation on the dataset test split versus baseline, a 47.5% gain in subtask completion (surpassing GPT-5) when integrated into PentestGPT and tested on vulnerable machines, an 18% gain on CTFKnow, a 28% gain in step prediction versus commercial LLMs, and superior qualitative results versus Claude-4.6-Sonnet in a user study.
Significance. If the quantitative claims hold under rigorous scrutiny, the work could meaningfully advance LLM-based automation of penetration testing by addressing gaps in strategy formulation and tool selection, with potential to mitigate the cybersecurity skills shortage. The integration experiments with PentestGPT and evaluation on CTFKnow provide partial external grounding beyond the authors' dataset, and the user study adds qualitative support; however, the absence of public data or code release limits immediate reproducibility and broader adoption.
major comments (3)
- [Abstract] Abstract: The headline claims of 87% improvement in strategy derivation, 47.5% in subtask completion, 18% on CTFKnow, and 28% in step prediction are presented without defining the underlying metrics (e.g., exact formula for 'strategy derivation performance' or 'subtask completion'), baseline configurations, statistical tests, error bars, or ablation results. This prevents verification of the numbers and raises the possibility of post-hoc metric selection or dataset-specific gaming.
- [Dataset construction and evaluation] Dataset and evaluation sections: The central results depend on a privately constructed reasoning dataset whose construction process (generation and validation of logical explanations), train/test split criteria, and leakage controls are not described. Without these details or public release, it is impossible to assess whether the 87% gain on the held-out split reflects genuine generalization or overfitting to the authors' data-construction choices.
- [Integration and evaluation] Integration experiments: The 47.5% subtask-completion gain is measured on an unspecified set of 'vulnerable machines' whose selection criteria and representativeness of real-world pentesting targets are not justified. This makes it difficult to determine whether the improvement when plugged into PentestGPT would hold on a broader distribution of targets.
minor comments (2)
- [Abstract and Methods] The abstract and results sections would benefit from explicit statements of the reward function and RL hyperparameters used in fine-tuning, as these are free parameters that could influence the reported gains.
- [Figures and tables] Figure and table captions should include the exact definitions of all plotted metrics and the number of runs or seeds used to compute averages.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important areas for improving clarity, transparency, and reproducibility, and we address each major comment point by point below, indicating the specific revisions we will make in the next version of the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims of 87% improvement in strategy derivation, 47.5% in subtask completion, 18% on CTFKnow, and 28% in step prediction are presented without defining the underlying metrics (e.g., exact formula for 'strategy derivation performance' or 'subtask completion'), baseline configurations, statistical tests, error bars, or ablation results. This prevents verification of the numbers and raises the possibility of post-hoc metric selection or dataset-specific gaming.
Authors: We agree that the abstract would benefit from greater precision to make the claims more verifiable. Strategy derivation performance is measured as the accuracy of generated logical reasoning chains against expert-annotated ground truth on the test split. Subtask completion is the fraction of required subtasks successfully executed by the integrated agent on the target machines. In the revised manuscript we will update the abstract with concise definitions of all reported metrics and add explicit references to the evaluation sections. We will also expand the main evaluation section to include baseline configurations, error bars on all quantitative results, statistical significance tests (paired t-tests with p-values), and ablation studies. These additions will directly address concerns about metric selection and strengthen the evidential basis for the reported gains. revision: yes
-
Referee: [Dataset construction and evaluation] Dataset and evaluation sections: The central results depend on a privately constructed reasoning dataset whose construction process (generation and validation of logical explanations), train/test split criteria, and leakage controls are not described. Without these details or public release, it is impossible to assess whether the 87% gain on the held-out split reflects genuine generalization or overfitting to the authors' data-construction choices.
Authors: We acknowledge that the dataset construction description in the current manuscript is too concise. In the revision we will substantially expand Section 3 to detail the full pipeline: the expert-crafted and LLM-assisted prompts used to generate logical explanations for both strategy derivation and step selection; the multi-expert validation process together with inter-annotator agreement statistics; the train/test split procedure (an 80/20 split performed at the level of distinct pentesting scenarios with explicit checks to ensure no shared vulnerabilities, tools, or reasoning patterns); and leakage-prevention measures such as scenario diversity sampling and manual overlap audits. While we cannot release the complete dataset because it incorporates proprietary pentesting knowledge, we will include a detailed appendix with representative examples, the full generation methodology, and sanitized sample data to enable independent reproduction of the approach. revision: partial
-
Referee: [Integration and evaluation] Integration experiments: The 47.5% subtask-completion gain is measured on an unspecified set of 'vulnerable machines' whose selection criteria and representativeness of real-world pentesting targets are not justified. This makes it difficult to determine whether the improvement when plugged into PentestGPT would hold on a broader distribution of targets.
Authors: We agree that additional justification is required. The machines were deliberately chosen from publicly documented vulnerable environments (Metasploitable 2/3, DVWA, and standard CTF challenges) to cover a representative distribution of common vulnerability classes including web application flaws, network misconfigurations, and privilege-escalation vectors. In the revised manuscript we will add a new subsection and accompanying table that lists each machine, its primary vulnerabilities, the rationale for inclusion, and a brief discussion of how the set reflects real-world pentesting targets. This will clarify the scope of the 47.5% improvement and support claims of practical relevance. revision: yes
Circularity Check
No significant circularity; empirical evaluations on held-out splits and external benchmarks remain independent of inputs
full rationale
The paper constructs a custom reasoning dataset, fine-tunes Qwen-3-14B via RL for strategy generation, and reports an 87% improvement on the dataset's test split plus 47.5% subtask gains when integrated into PentestGPT on vulnerable machines and CTFKnow. These are standard empirical measurements against baselines on held-out data and external targets; the reported numbers are not equivalent to the dataset construction or fine-tuning inputs by definition. No self-citations, uniqueness theorems, ansatzes, or renamings reduce the central claims to tautologies. The derivation chain is self-contained with independent validation steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL fine-tuning hyperparameters and reward function
axioms (1)
- domain assumption The constructed reasoning dataset accurately captures logical explanations for pentesting strategy derivation and step selection
Lean theorems connected to this paper
-
IndisputableMonolith.Cost.FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We then fine-tune a Qwen-3-14B model for strategy generation using reinforcement learning... GRPO... reward functions: semantic similarity, pattern, generation length, language reward.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Hessa Mohammed Zaher Al Shebli and Babak D Beheshti. 2018. A study on pen- etration testing process and tools. In2018 IEEE Long Island Systems, Applications and Technology Conference. 1–7
2018
-
[2]
Alibaba Cloud. 2025. Qwen3-14B. https://huggingface.co/Qwen/Qwen3-14B
2025
-
[3]
Alibaba Cloud. 2025. Qwen3-8B. https://huggingface.co/Qwen/Qwen3-8B
2025
-
[4]
Anthropic. 2025. Agent Skills Overview. https://platform.claude.com/docs/en/ agents-and-tools/agent-skills/overview
2025
-
[5]
Anthropic. 2026. Claude Code. https://code.claude.com/docs/en/quickstart
2026
- [6]
-
[7]
Dipkamal Bhusal, Md Tanvirul Alam, Le Nguyen, Ashim Mahara, Zachary Light- cap, Rodney Frazier, Romy Fieblinger, Grace Long Torales, Benjamin A Blakely, and Nidhi Rastogi. 2024. SECURE: Benchmarking large language models for cybersecurity. In2024 Annual Computer Security Applications Conference (ACSAC). IEEE, 15–30
2024
-
[8]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, et al. 2020. Language models are few-shot learners.Advances in Neural Information Processing Systems 33 (2020), 1877–1901
2020
-
[9]
Alibaba Cloud. 2025. Qwen/Qwen3-235B-A22B·Hugging Face. https:// huggingface.co/Qwen/Qwen3-235B-A22B
2025
- [10]
- [11]
-
[12]
Gelei Deng, Yi Liu, Víctor Mayoral-Vilches, Peng Liu, Yuekang Li, Yuan Xu, Tianwei Zhang, Yang Liu, Martin Pinzger, and Stefan Rass. 2024. PentestGPT: Evaluating and harnessing large language models for automated penetration testing. In33rd USENIX Security Symposium (USENIX Security 24). 847–864
2024
-
[13]
FedRAMP. 2024. FedRAMP Penetration Test Guidance. https: //www.fedramp.gov/assets/resources/documents/CSP_Penetration_Test_ Guidance_public_comment.pdf
2024
-
[14]
Yasod Ginige, Akila Niroshan, Sajal Jain, and Suranga Seneviratne. 2025. Au- topentester: An LLM agent-based framework for automated pentesting. In2025 IEEE 24th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom). IEEE, 163–174
2025
-
[15]
Yasod Ginige, Bhanuka Silva, Thilini Dahanayaka, and Suranga Seneviratne. 2025. TrafficLLM: LLMs for improved open-set encrypted traffic analysis.Computer Networks(2025), 111847
2025
-
[16]
Hack The Box. 2024. Hack The Box. https://www.hackthebox.com/
2024
-
[17]
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The Curious Case of Neural Text Degeneration. InInternational Conference on Learning Representations
2020
-
[18]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, and Weizhu Chen. 2022. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations
2022
-
[19]
Zhenguo Hu, Razvan Beuran, and Yasuo Tan. 2020. Automated penetration testing using deep reinforcement learning. InIEEE European Symposium on Security and Privacy Workshops (EuroS&PW). 2–10
2020
-
[20]
Zimo Ji, Daoyuan Wu, Wenyuan Jiang, Pingchuan Ma, Zongjie Li, and Shuai Wang. 2025. Measuring and augmenting large language models for solving capture-the-flag challenges. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security. 603–617
2025
- [21]
-
[22]
Solomon Kullback. 1951. Kullback–Leibler divergence.Encyclopedia of Machine Learning(1951), 581–583
1951
-
[23]
Gordon H Lewis and Richard G Johnson. 1971. Kendall’s Coefficient of Concor- dance for sociometric rankings with self excluded.Sociometry(1971), 496–503
1971
-
[24]
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng, et al
-
[25]
GDPO: Group reward-decoupled normalization policy optimization for multi-reward RL optimization.arXiv preprint arXiv:2601.05242(2026)
work page internal anchor Pith review arXiv 2026
-
[26]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-Eval: NLG evaluation using GPT-4 with better human alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2511–2522
2023
- [27]
-
[28]
Mistral AI. 2025. Ministral-3-14B-Reasoning-2512. https://huggingface.co/ mistralai/Ministral-3-14B-Reasoning-2512
2025
-
[29]
NVIDIA. 2026. Nemotron-Cascade-14B-Thinking. https://huggingface.co/nvidia/ Nemotron-Cascade-14B-Thinking
2026
-
[30]
openclaw. 2025. GitHub - openclaw/openclaw: Your own personal AI assistant. Any OS. Any Platform. The lobster way. https://github.com/openclaw/openclaw
2025
- [31]
-
[32]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model.Advances in Neural Information Processing Systems36 (2023), 53728–53741
2023
-
[33]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review arXiv 2024
-
[34]
Xiangmin Shen, Lingzhi Wang, Zhenyuan Li, Yan Chen, Wencheng Zhao, Dawei Sun, Jiashui Wang, and Wei Ruan. 2025. Pentestagent: Incorporating LLM agents to automated penetration testing. InProceedings of the 20th ACM Asia Conference on Computer and Communications Security. 375–391
2025
-
[35]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, et al
-
[36]
Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805(2023)
work page internal anchor Pith review arXiv 2023
-
[37]
Xumeng Wen, Zihan Liu, Shun Zheng, Shengyu Ye, Zhirong Wu, Yang Wang, Zhijian Xu, Xiao Liang, Junjie Li, Ziming Miao, et al. 2025. Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base LLMs. arXiv preprint arXiv:2506.14245(2025)
work page internal anchor Pith review arXiv 2025
-
[38]
Yiran Wu, Mauricio Velazco, Andrew Zhao, Manuel Raúl Meléndez Luján, Srisuma Movva, Yogesh K Roy, Quang Nguyen, Roberto Rodriguez, Qingyun Wu, Michael Albada, et al. 2025. ExCyTIn-Bench: Evaluating LLM agents on cyber threat investigation.arXiv preprint arXiv:2507.14201(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [39]
-
[40]
testing 123!
Hao Zhang, Tingmin Wu, Tianqing Zhu, Sheng Wen, and Yang Xiang. 2025. CyberLlama: A fine-tuned large language model for cybersecurity named entity recognition.Knowledge-Based Systems(2025), 114183. Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Trovato et al. A Open Science We published our dataset and codes in an anonymous GitHub repos- itory (h...
2025
-
[41]
We have sudo privileges to run commands as scriptmanager (no password required)
-
[42]
We can modify test.py (owned by scriptmanager with rw permissions)
-
[43]
test.py appears to be executed automatically by root (evidenced by root-owned output) The strategy should be to:
-
[44]
First, switch to scriptmanager user using our sudo privileges
-
[45]
Modify test.py to include a reverse shell or privilege escalation payload
-
[46]
Wait for the automated execution (likely a cron job) to run the script as root
-
[47]
Exploit this by:
Gain root access Final strategy: 1.4.4 Exploit automated script execution for privilege escalation Since test.py is owned by scriptmanager but creates files owned by root, this indicates the script is being executed by root automatically (likely via cron). Exploit this by:
-
[48]
Switch to scriptmanager user: `sudo -u scriptmanager /bin/bash`
-
[49]
Modify test.py to include a reverse shell payload that will execute as root
-
[50]
Set up a new netcat listener on the attacking machine (different port, e.g., 5555)
-
[51]
Replace test.py content with a Python reverse shell connecting to attacker IP
-
[52]
Wait for the automated execution (monitor for incoming connection) Strategy: Exploit potential vulnerabilities within the `test.py` script or use it as a stepping stone to escalate privileges from the compromised `www-data` user. Steps:
-
[53]
Analyze `test.py`: - Inspect the code of `test.py` to identify if it contains any insecure functionalities, such as hardcoded credentials, misconfigured logging, or unintended side effects when executed with elevated privileges
-
[54]
Check for SUID/SGID Bits: - Verify if any files in `/scripts` have the setuid/setgid bits enabled, which could allow execution with higher privileges
-
[55]
Test Execution of `test.py`: - Execute `test.py` under different contexts (e.g., as `root`, via cron jobs, or through web access) to observe its behavior and check if it leads to privilege escalation
-
[56]
Look for Path Manipulation or Environment Variables: - Search for environment variables that might be manipulated to execute arbitrary code when `test.py` runs
-
[57]
Consider Web Context: - If the target has exposed web endpoints related to `/scripts`, attempt to trigger `test.py` via a crafted request to see if it behaves differently than locally
-
[58]
Escalate Privileges via Sudo Rights: - Since `www-data` has sudo rights, focus on escalating from there first before moving into other users
-
[59]
The previous reconnaissance and privilege escalation steps provided key insights
Review System Logs: - Look for clues in system logs (if accessible) regarding failed login attempts or processes that might indicate misconfigurations. The previous reconnaissance and privilege escalation steps provided key insights. We have accessed the 'scripts' directory intended for the 'scriptmanager' user, revealing files with varied permissions. 't...
-
[60]
Verifying execution contexts or triggering conditions
-
[61]
Preparing a backdoor or alternative command within 'test.py' to escalate privileges or explore further
-
[62]
Managing access to quickly test modifications in 'test.py'
-
[63]
Focus on gaining 'scriptmanager' privileges to increase system control, permitting further system exploration or access
Checking periodic execution schedules (cron jobs) that might allow leveraging the modified script. Focus on gaining 'scriptmanager' privileges to increase system control, permitting further system exploration or access. Final strategy: Modify 'test.py' within /scripts to include a command that provides a backdoor (e.g., spawn a reverse shell) or logs 'scr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.