Recognition: 1 theorem link
· Lean TheoremEfficient Geometry-Controlled High-Resolution Satellite Image Synthesis
Pith reviewed 2026-05-14 22:03 UTC · model grok-4.3
The pith
A lightweight control method using windowed cross-attention on skip connections lets pre-trained diffusion models synthesize high-resolution satellite images that follow a given geometry map.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
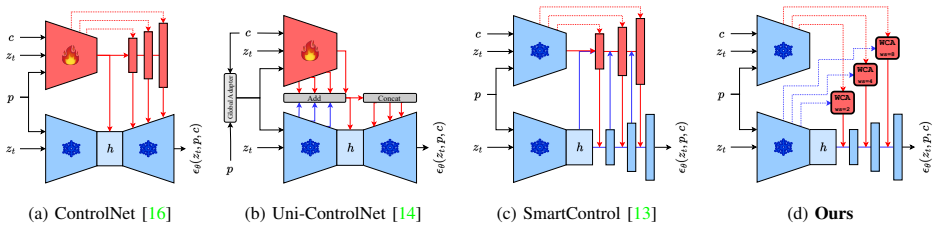
By restricting control to skip-connection features via windowed cross-attention modules, a pre-trained diffusion model can be steered to generate high-resolution satellite images whose spatial layout matches a provided geometry control map, delivering performance on par with established control techniques yet with measurably better geometric fidelity and without any additional training of the base model.
What carries the argument
Windowed cross-attention modules applied exclusively to skip-connection features to inject geometry information from a control map into the diffusion synthesis process.
If this is right
- Synthetic high-resolution satellite images become available for data-scarce regions and rare events to augment training sets for land-cover and change-detection models.
- The control overhead remains low because the base diffusion model stays frozen and only lightweight attention modules are added.
- Geometry adherence improves over prior techniques, reducing spatial inconsistencies that could mislead downstream remote-sensing algorithms.
- Current image-quality metrics alone are shown to be inadequate, pushing the field toward explicit alignment evaluation between output and control map.
Where Pith is reading between the lines
- The same skip-connection control pattern could transfer to other structured image domains where layout fidelity matters, such as generating maps or floor plans.
- If the method preserves alignment at even higher resolutions, it could support fine-grained simulation of infrastructure changes for urban planning models.
- Because the base model is untouched, the technique can immediately adopt future improvements in general-purpose diffusion models without re-engineering the control layer.
Load-bearing premise
That controlling only the skip-connection features via windowed cross-attention is sufficient to enforce geometry alignment without degrading image quality or requiring any retraining of the base diffusion model.
What would settle it
A set of generated images that receive high standard quality scores but show clear mismatches with the geometry map, such as roads or buildings placed in positions forbidden by the control layout.
Figures


read the original abstract
High-resolution satellite images are often scarce and costly, especially for remote areas or infrequent events. This shortage hampers the development and testing of machine learning models for land-cover classification, change detection, and disaster monitoring. In this paper, we tackle the problem of geometry-controlled high-resolution satellite image synthesis by adding control over existing pre-trained diffusion models. We propose a simple yet efficient method for controlling the synthesis process by leveraging only skip connection features using windowed cross-attention modules. Several previously established control techniques are compared, indicating that our method achieves comparable performance while leading to a better alignment with the geometry control map. We also discuss the limitations in current evaluation approaches, amplifying the necessity of a consistent alignment assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an efficient method to add geometry control to pre-trained diffusion models for high-resolution satellite image synthesis. Control is injected solely via windowed cross-attention modules applied to the skip-connection features of the U-Net, without retraining the base model. The central claim is that this yields performance comparable to prior control techniques while achieving better alignment with the input geometry control map; the paper also discusses shortcomings of existing alignment metrics.
Significance. If the results are substantiated, the approach could enable scalable generation of synthetic satellite imagery for data-scarce remote-sensing tasks such as land-cover classification, change detection, and disaster monitoring. The efficiency of operating on frozen pre-trained models without full retraining is a practical strength relative to methods that require end-to-end fine-tuning.
major comments (3)
- [Method] Method section: the load-bearing assumption that restricting windowed cross-attention to skip-connection features is sufficient for global geometric fidelity is not demonstrated; in high-resolution satellite scenes, local windows can fail to enforce long-range consistency (e.g., continuous road networks or field boundaries), and no ablation on window size or propagation across scales is provided.
- [Experiments] Experiments section: the abstract asserts 'comparable performance' and 'better alignment,' yet the manuscript supplies neither quantitative tables, specific metrics (e.g., alignment error, FID, or geometry-consistency scores), nor details on the baselines and evaluation protocol, rendering the central claim unverifiable.
- [Evaluation] Evaluation discussion: while limitations of current alignment metrics are noted, the paper neither adopts nor proposes a more reliable metric, so any reported improvement rests on the same unverified measures whose shortcomings are acknowledged.
minor comments (2)
- [Abstract] Abstract: the datasets, exact quantitative gains, and control-map encoding should be stated explicitly rather than left at a high-level claim.
- [Notation] Notation: the geometry control map and its encoding into the attention modules should be defined with equations or a clear diagram at first use.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address each major comment below and will revise the manuscript to improve clarity, add missing details, and strengthen the supporting evidence where possible.
read point-by-point responses
-
Referee: [Method] Method section: the load-bearing assumption that restricting windowed cross-attention to skip-connection features is sufficient for global geometric fidelity is not demonstrated; in high-resolution satellite scenes, local windows can fail to enforce long-range consistency (e.g., continuous road networks or field boundaries), and no ablation on window size or propagation across scales is provided.
Authors: We agree that explicit validation of long-range consistency is necessary. The design relies on the U-Net's hierarchical skip connections to propagate information from local windows across scales, but we acknowledge the lack of supporting ablation. In the revision we will add an ablation study on window sizes (e.g., 8×8, 16×16, 32×32) together with qualitative examples demonstrating continuity of roads and field boundaries, and we will include a short analysis of cross-scale propagation. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts 'comparable performance' and 'better alignment,' yet the manuscript supplies neither quantitative tables, specific metrics (e.g., alignment error, FID, or geometry-consistency scores), nor details on the baselines and evaluation protocol, rendering the central claim unverifiable.
Authors: We apologize for the incomplete presentation in the submitted version. The full experimental section does contain quantitative comparisons, but to make every claim immediately verifiable we will insert a dedicated results table reporting FID, alignment error, and geometry-consistency scores, plus a clear subsection describing the evaluation protocol, dataset splits, and exact baselines used. revision: yes
-
Referee: [Evaluation] Evaluation discussion: while limitations of current alignment metrics are noted, the paper neither adopts nor proposes a more reliable metric, so any reported improvement rests on the same unverified measures whose shortcomings are acknowledged.
Authors: We discuss metric limitations to contextualize our results rather than to claim a new metric. In the revision we will expand the evaluation section with (i) explicit reporting of multiple complementary metrics, (ii) a detailed description of how we combine them to mitigate individual weaknesses, and (iii) additional qualitative side-by-side comparisons. We do not introduce a new metric in this work, as our focus is on the control method itself. revision: partial
Circularity Check
No significant circularity; additive method on pre-trained models
full rationale
The paper describes a practical addition of windowed cross-attention modules to control geometry via skip connections in existing pre-trained diffusion models. No derivation chain, equation, or claim reduces by construction to its own inputs, fitted parameters, or self-citation load-bearing premises. Comparisons to prior control techniques are presented as empirical evaluations, and the text explicitly discusses limitations in current alignment metrics rather than asserting uniqueness via internal definitions. The approach is self-contained against external benchmarks and pre-trained bases.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we propose a simple yet efficient method for controlling the synthesis process by leveraging only skip connection features using windowed cross-attention modules
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Image augmentation for satellite images,
O. Adedeji, P. Owoade, O. Ajayi, and O. Arowolo, “Image augmentation for satellite images,”arXiv preprint arXiv:2207.14580, 2022
-
[2]
Disastergan: Generative adversarial networks for remote sensing disaster image generation,
X. Rui, Y . Cao, X. Yuan, Y . Kang, and W. Song, “Disastergan: Generative adversarial networks for remote sensing disaster image generation,”Remote Sensing, vol. 13, no. 21, p. 4284, 2021
work page 2021
-
[3]
U. Lagap and S. Ghaffarian, “Predicting post-disaster damage levels and generating post-disaster imagery from pre-disaster satellite images using pix2pix,”The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, vol. 48, pp. 861–867, 2025
work page 2025
-
[4]
Reconstruction of missing data in satellite imagery using sn-gans,
P. Panchal, V . C. Raman, T. Baraskar, S. Sinha, S. Purohit, and J. Modi, “Reconstruction of missing data in satellite imagery using sn-gans,” inSmart Trends in Computing and Communi- cations: Proceedings of SmartCom 2021. Springer, 2021, pp. 629–638
work page 2021
-
[5]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
B. F. Labs, S. Batifol, A. Blattmann, F. Boesel, S. Consul, C. Diagne, T. Dockhorn, J. English, Z. English, P. Esseret al., “Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space,”arXiv preprint arXiv:2506.15742, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
work page 2022
-
[7]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. M ¨uller, J. Penna, and R. Rombach, “Sdxl: Improving latent diffusion models for high-resolution image synthesis,”arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Multispectral satellite image generation using stylegan3,
M. Alibani, N. Acito, and G. Corsini, “Multispectral satellite image generation using stylegan3,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 17, pp. 4379–4391, 2024
work page 2024
-
[9]
Gan generation of synthetic multispectral satellite images,
L. Abady, M. Barni, A. Garzelli, and B. Tondi, “Gan generation of synthetic multispectral satellite images,” inImage and signal processing for remote sensing XXVI, vol. 11533. SPIE, 2020, pp. 122–133
work page 2020
-
[10]
Geosynth: Contextually-aware high-resolution satellite image synthesis,
S. Sastry, S. Khanal, A. Dhakal, and N. Jacobs, “Geosynth: Contextually-aware high-resolution satellite image synthesis,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 460–470
work page 2024
-
[11]
Satgan: Satellite image generation using conditional adversarial networks,
M. Shah, M. Gupta, and P. Thakkar, “Satgan: Satellite image generation using conditional adversarial networks,” in2021 International Conference on Communication information and Computing Technology (ICCICT). IEEE, 2021, pp. 1–6
work page 2021
-
[12]
Changen2: Multi-temporal remote sensing generative change foundation model,
Z. Zheng, S. Ermon, D. Kim, L. Zhang, and Y . Zhong, “Changen2: Multi-temporal remote sensing generative change foundation model,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[13]
Smartcontrol: Enhancing controlnet for handling rough visual conditions,
X. Liu, Y . Wei, M. Liu, X. Lin, P. Ren, X. Xie, and W. Zuo, “Smartcontrol: Enhancing controlnet for handling rough visual conditions,” inEuropean Conference on Computer Vision, 2024, pp. 1–17
work page 2024
-
[14]
Uni-controlnet: All-in-one control to text- to-image diffusion models,
S. Zhao, D. Chen, Y .-C. Chen, J. Bao, S. Hao, L. Yuan, and K.-Y . K. Wong, “Uni-controlnet: All-in-one control to text- to-image diffusion models,”Advances in Neural Information Processing Systems, vol. 36, pp. 11 127–11 150, 2023
work page 2023
-
[15]
Sketch-guided text-to-image diffusion models,
A. V oynov, K. Aberman, and D. Cohen-Or, “Sketch-guided text-to-image diffusion models,” inACM SIGGRAPH 2023 conference proceedings, 2023, pp. 1–11
work page 2023
-
[16]
Adding conditional control to text-to-image diffusion models,
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 3836–3847
work page 2023
-
[17]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,”Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020
work page 2020
-
[18]
Ledits++: Limitless image editing using text-to-image models,
M. Brack, F. Friedrich, K. Kornmeier, L. Tsaban, P. Schramowski, K. Kersting, and A. Passos, “Ledits++: Limitless image editing using text-to-image models,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 8861–8870
work page 2024
-
[19]
A 3d generative model for structure-based drug design,
S. Luo, J. Guan, J. Ma, and J. Peng, “A 3d generative model for structure-based drug design,”Advances in Neural Information Processing Systems, vol. 34, pp. 6229–6239, 2021
work page 2021
-
[20]
Multidiffusion: Fusing diffusion paths for controlled image generation,
O. Bar-Tal, L. Yariv, Y . Lipman, and T. Dekel, “Multidiffusion: Fusing diffusion paths for controlled image generation,”Pro- ceedings of Machine Learning Research, vol. 202, pp. 1737– 1752, 2023
work page 2023
-
[21]
Masksketch: Unpaired structure-guided masked image genera- tion,
D. Bashkirova, J. Lezama, K. Sohn, K. Saenko, and I. Essa, “Masksketch: Unpaired structure-guided masked image genera- tion,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 1879–1889
work page 2023
-
[22]
C. Mou, X. Wang, L. Xie, Y . Wu, J. Zhang, Z. Qi, and Y . Shan, “T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models,” inProceedings of the AAAI conference on artificial intelligence, vol. 38, no. 5, 2024, pp. 4296–4304
work page 2024
-
[23]
Lora: Low-rank adaptation of large language models,
E. J. Hu, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models,” inInternational Conference on Learning Representa- tions, 2022
work page 2022
-
[24]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation,
N. Ruiz, Y . Li, V . Jampani, Y . Pritch, M. Rubinstein, and K. Aberman, “Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, 2023, pp. 22 500–22 510
work page 2023
-
[25]
Scaling local self-attention for parameter efficient visual backbones,
A. Vaswani, P. Ramachandran, A. Srinivas, N. Parmar, B. Hecht- man, and J. Shlens, “Scaling local self-attention for parameter efficient visual backbones,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12 894–12 904
work page 2021
-
[26]
Cbam: Convolu- tional block attention module,
S. Woo, J. Park, J.-Y . Lee, and I. S. Kweon, “Cbam: Convolu- tional block attention module,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 3–19
work page 2018
-
[27]
Exploring clip for assessing the look and feel of images,
J. Wang, K. C. Chan, and C. C. Loy, “Exploring clip for assessing the look and feel of images,” inProceedings of the AAAI conference on artificial intelligence, vol. 37, no. 2, 2023, pp. 2555–2563
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.