Recognition: unknown
A Queueing-Theoretic Framework for Stability Analysis of LLM Inference with KV Cache Memory Constraints
Pith reviewed 2026-05-08 17:23 UTC · model grok-4.3
The pith
A queueing model with KV cache memory states yields exact stability conditions for LLM inference services to avoid unbounded queue growth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce the first queueing-theoretic framework that explicitly incorporates both computation and GPU memory constraints into the analysis of LLM inference. Based on this framework, we derive rigorous stability and instability conditions that determine whether an LLM inference service can sustain incoming demand without unbounded queue growth. This result offers a powerful tool for system deployment, potentially addressing the core challenge of GPU provisioning. By combining an estimated request arrival rate with our derived stable service rate, operators can calculate the necessary cluster size to avoid both costly over-purchasing and performance-violating under-provisioning.
What carries the argument
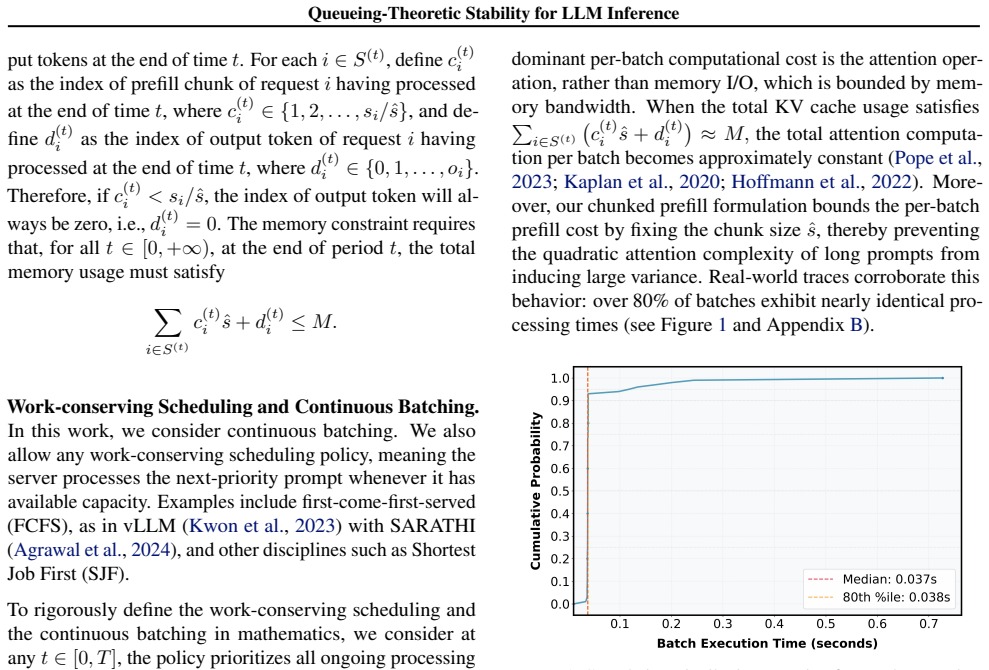
A queueing process whose state tracks the number of active requests together with their cumulative KV cache memory occupancy, producing stability criteria via comparison of arrival rate against an effective service rate that shrinks under memory pressure.
Load-bearing premise
The queueing model assumptions about arrival processes, service time distributions, and memory consumption dynamics accurately represent real LLM inference workloads on production GPUs.
What would settle it
Run an LLM inference server at the exact critical arrival rate predicted by the model and measure whether average queue length stays bounded over long time horizons or grows without limit.
Figures







read the original abstract
The rapid adoption of large language models (LLMs) has created significant challenges for efficient inference at scale. Unlike traditional workloads, LLM inference is constrained by both computation and the memory overhead of key-value (KV) caching, which accelerates decoding but quickly exhausts GPU memory. In this paper, we introduce the first queueing-theoretic framework that explicitly incorporates both computation and GPU memory constraints into the analysis of LLM inference. Based on this framework, we derive rigorous stability and instability conditions that determine whether an LLM inference service can sustain incoming demand without unbounded queue growth. This result offers a powerful tool for system deployment, potentially addressing the core challenge of GPU provisioning. By combining an estimated request arrival rate with our derived stable service rate, operators can calculate the necessary cluster size to avoid both costly over-purchasing and performance-violating under-provisioning. We further validate our theoretical predictions through extensive experiments in real GPU production environments. Our results show that the predicted stability conditions are highly accurate, with deviations typically within 10%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the first queueing-theoretic framework for LLM inference that jointly models computational and KV-cache memory constraints. It derives rigorous stability and instability conditions determining whether an inference service can sustain a given arrival rate without unbounded queue growth, and validates the predictions via experiments on real GPU production hardware showing typical deviations within 10%.
Significance. If the derived conditions are predictive, the work supplies a practical provisioning rule: combine an observed arrival rate with the paper's stable service rate to compute the minimum cluster size that avoids both over-provisioning and SLA violations. The explicit experimental validation in production environments is a clear strength and distinguishes the contribution from purely theoretical queueing analyses.
major comments (2)
- §3 (Queueing Model): The stability conditions rest on the assumption that effective service rate remains stationary once memory occupancy is accounted for. In continuous-batching systems with paged KV cache, prefix sharing, and eviction, service time and memory footprint become history-dependent; the manuscript does not demonstrate that the Markovian ergodicity conditions used in the derivation continue to hold under these dynamics.
- §5 (Experimental Validation): The reported deviations are typically within 10%, yet the text provides no breakdown of how arrival processes, sequence-length distributions, or KV-cache eviction policies were matched between the model and the production traces. Without this mapping, it is unclear whether the agreement validates the core stability criterion or merely confirms a post-hoc fit.
minor comments (2)
- Notation for the memory-constrained service rate is introduced without an explicit equation number in the main text; cross-referencing would improve readability.
- The abstract claims the framework is 'the first'; a brief related-work paragraph citing prior queueing models for inference (even if they omit memory) would strengthen the novelty statement.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our paper. We address each major comment below and describe the revisions we plan to make to strengthen the manuscript.
read point-by-point responses
-
Referee: §3 (Queueing Model): The stability conditions rest on the assumption that effective service rate remains stationary once memory occupancy is accounted for. In continuous-batching systems with paged KV cache, prefix sharing, and eviction, service time and memory footprint become history-dependent; the manuscript does not demonstrate that the Markovian ergodicity conditions used in the derivation continue to hold under these dynamics.
Authors: The referee correctly identifies a key modeling assumption. Our framework models the system as a Markov chain where the state includes the current memory occupancy, and the service rate is a function of that state. While prefix sharing and eviction introduce dependencies, in practice for stability analysis, we use the long-run average effective rate, which preserves the ergodicity under standard conditions for state-dependent queues. We did not explicitly prove ergodicity for every possible eviction policy, as the paper focuses on the stability conditions derived from the model. In the revision, we will add a subsection in §3 discussing the validity of the Markovian assumption under common KV cache management policies and note the limitations. This will be a partial revision as the core derivation remains unchanged. revision: partial
-
Referee: §5 (Experimental Validation): The reported deviations are typically within 10%, yet the text provides no breakdown of how arrival processes, sequence-length distributions, or KV-cache eviction policies were matched between the model and the production traces. Without this mapping, it is unclear whether the agreement validates the core stability criterion or merely confirms a post-hoc fit.
Authors: We concur that a more explicit mapping is required to interpret the validation results. In the revised manuscript, we will augment §5 with a comprehensive description of the experimental setup, including how the arrival processes (using trace-driven or synthetic Poisson arrivals), sequence-length distributions (empirical from production data), and KV-cache eviction policies (modeled after the paged attention mechanism with LRU eviction) were aligned with the production traces. This addition will clarify that the observed agreement supports the predictive power of the stability conditions. revision: yes
Circularity Check
No circularity: standard queueing derivation applied to KV-cache constraints
full rationale
The paper introduces a queueing model that incorporates both compute and KV-cache memory constraints, then derives stability conditions (arrival rate below effective service rate under memory limits) using standard Markovian analysis. No step reduces a prediction to a fitted input by construction, nor does any load-bearing claim rest on self-citation of an unverified uniqueness theorem. The stability result is obtained from the model equations rather than being presupposed; experimental validation is presented as separate confirmation rather than part of the derivation. The central claim therefore remains independent of its inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Requests arrive according to a Poisson process and service times follow a distribution compatible with queueing stability analysis.
- domain assumption KV cache memory usage can be modeled as an additional capacity constraint that interacts with compute service rate.
Reference graph
Works this paper leans on
-
[1]
2020 , publisher=
Processing networks: fluid models and stability , author=. 2020 , publisher=
2020
-
[2]
2013 , publisher=
Markov chains: Gibbs fields, Monte Carlo simulation, and queues , author=. 2013 , publisher=
2013
-
[3]
arXiv preprint arXiv:2412.04504 , year=
Multi-bin batching for increasing LLM inference throughput , author=. arXiv preprint arXiv:2412.04504 , year=
-
[4]
Algorithmica , volume=
Bandwidth packing , author=. Algorithmica , volume=. 2001 , publisher=
2001
-
[5]
Queueing Systems , volume=
Asymptotic optimality of a greedy randomized algorithm in a large-scale service system with general packing constraints , author=. Queueing Systems , volume=. 2015 , publisher=
2015
-
[6]
ACM SIGMETRICS Performance Evaluation Review , volume=
A large-scale service system with packing constraints: Minimizing the number of occupied servers , author=. ACM SIGMETRICS Performance Evaluation Review , volume=. 2013 , publisher=
2013
-
[7]
Queueing systems , volume=
Stochastic bandwidth packing process: stability conditions via Lyapunov function technique , author=. Queueing systems , volume=. 2004 , publisher=
2004
-
[8]
Operations Research , volume=
An infinite server system with general packing constraints , author=. Operations Research , volume=. 2013 , publisher=
2013
-
[9]
ACM SIGMETRICS Performance Evaluation Review , volume=
Asymptotic optimality of BestFit for stochastic bin packing , author=. ACM SIGMETRICS Performance Evaluation Review , volume=. 2014 , publisher=
2014
-
[10]
ACM SIGMETRICS Performance Evaluation Review , volume=
Lagrangian-based online stochastic bin packing , author=. ACM SIGMETRICS Performance Evaluation Review , volume=. 2015 , publisher=
2015
-
[11]
2012 Proceedings IEEE Infocom , pages=
Stochastic models of load balancing and scheduling in cloud computing clusters , author=. 2012 Proceedings IEEE Infocom , pages=. 2012 , organization=
2012
-
[12]
Stability of queueing networks:
Bramson, Maury , year=. Stability of queueing networks:
-
[13]
Operations Research , year=
Orlm: A customizable framework in training large models for automated optimization modeling , author=. Operations Research , year=
-
[14]
Fast distributed inference serving for large language models,
Fast distributed inference serving for large language models , author=. arXiv preprint arXiv:2305.05920 , year=
-
[15]
arXiv preprint arXiv:2503.07545 , year=
Queueing, predictions, and llms: Challenges and open problems , author=. arXiv preprint arXiv:2503.07545 , year=
-
[16]
2024 22nd International Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks (WiOpt) , pages=
A queueing theoretic perspective on low-latency llm inference with variable token length , author=. 2024 22nd International Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks (WiOpt) , pages=. 2024 , organization=
2024
-
[17]
arXiv preprint arXiv:2508.06133 , year=
LLM Serving Optimization with Variable Prefill and Decode Lengths , author=. arXiv preprint arXiv:2508.06133 , year=
-
[18]
arXiv preprint arXiv:2508.14544 , year=
Adaptively Robust LLM Inference Optimization under Prediction Uncertainty , author=. arXiv preprint arXiv:2508.14544 , year=
-
[19]
arXiv preprint arXiv:2601.17855 , year=
A Universal Load Balancing Principle and Its Application to Large Language Model Serving , author=. arXiv preprint arXiv:2601.17855 , year=
-
[20]
Training Compute-Optimal Large Language Models
Training compute-optimal large language models , author=. arXiv preprint arXiv:2203.15556 , year=
work page internal anchor Pith review arXiv
-
[21]
arXiv preprint arXiv:2502.07115 , year=
Online Scheduling for LLM Inference with KV Cache Constraints , author=. arXiv preprint arXiv:2502.07115 , year=
-
[22]
arXiv preprint arXiv:2504.11320 , year=
Optimizing LLM Inference: Fluid-Guided Online Scheduling with Memory Constraints , author=. arXiv preprint arXiv:2504.11320 , year=
-
[23]
arXiv preprint arXiv:2504.07347 , year=
Throughput-optimal scheduling algorithms for llm inference and ai agents , author=. arXiv preprint arXiv:2504.07347 , year=
-
[24]
arXiv preprint arXiv:2410.01035 , year=
Don't Stop Me Now: Embedding Based Scheduling for LLMs , author=. arXiv preprint arXiv:2410.01035 , year=
-
[25]
Management Science , volume=
Appointment scheduling with limited distributional information , author=. Management Science , volume=. 2015 , publisher=
2015
-
[26]
Discrete Applied Mathematics , volume=
Parallel machine scheduling with splitting jobs , author=. Discrete Applied Mathematics , volume=. 2000 , publisher=
2000
-
[27]
Operations research , volume=
Scheduling arrivals to a stochastic service delivery system using copositive cones , author=. Operations research , volume=. 2013 , publisher=
2013
-
[28]
European journal of operational research , volume=
A survey of scheduling problems with setup times or costs , author=. European journal of operational research , volume=. 2008 , publisher=
2008
-
[29]
Journal of scheduling , volume=
Scheduling a batching machine , author=. Journal of scheduling , volume=. 1998 , publisher=
1998
-
[30]
Handbook of Combinatorial Optimization: Volume1--3 , pages=
A review of machine scheduling: Complexity, algorithms and approximability , author=. Handbook of Combinatorial Optimization: Volume1--3 , pages=. 1998 , publisher=
1998
-
[31]
2012 , publisher=
Scheduling , author=. 2012 , publisher=
2012
-
[32]
arXiv preprint arXiv:2402.08804 , year=
When Should you Offer an Upgrade: Online Upgrading Mechanisms for Resource Allocation , author=. arXiv preprint arXiv:2402.08804 , year=
-
[33]
Yao, Yuhang and Jin, Han and Shah, Alay Dilipbhai and Han, Shanshan and Hu, Zijian and Ran, Yide and Stripelis, Dimitris and Xu, Zhaozhuo and Avestimehr, Salman and He, Chaoyang , journal=
-
[34]
High-Dimensional Probability: An Introduction with Applications in Data Science , publisher=
Vershynin, Roman , year=. High-Dimensional Probability: An Introduction with Applications in Data Science , publisher=
-
[35]
European journal of operational research , volume=
Scheduling with batching: A review , author=. European journal of operational research , volume=. 2000 , publisher=
2000
-
[36]
Annals of Operations Research , volume=
Batch sizing and just-in-time scheduling with common due date , author=. Annals of Operations Research , volume=. 2014 , publisher=
2014
-
[37]
Journal of the Operational Research Society , volume=
Scheduling a single batch-processing machine with arbitrary job sizes and incompatible job families: an ant colony framework , author=. Journal of the Operational Research Society , volume=. 2008 , publisher=
2008
-
[38]
European Journal of Operational Research , volume=
Scheduling a single parallel-batching machine with non-identical job sizes and incompatible job families , author=. European Journal of Operational Research , volume=. 2022 , publisher=
2022
-
[39]
arXiv preprint arXiv:2210.07996 , year=
Degeneracy is ok: Logarithmic regret for network revenue management with indiscrete distributions , author=. arXiv preprint arXiv:2210.07996 , year=
-
[40]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[41]
Proceedings of the 37th International Conference on Neural Information Processing Systems , pages=
On optimal caching and model multiplexing for large model inference , author=. Proceedings of the 37th International Conference on Neural Information Processing Systems , pages=
-
[42]
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Li, Tianle and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Li, Zhuohan and Lin, Zi and Xing, Eric and others , journal=
-
[43]
Vidur: A Large-Scale Simulation Framework For
Agrawal, Amey and Kedia, Nitin and Mohan, Jayashree and Panwar, Ashish and Kwatra, Nipun and Gulavani, Bhargav and Ramjee, Ramachandran and Tumanov, Alexey , journal=. Vidur: A Large-Scale Simulation Framework For
-
[44]
Taming throughput-latency tradeoff in
Agrawal, Amey and Kedia, Nitin and Panwar, Ashish and Mohan, Jayashree and Kwatra, Nipun and Gulavani, Bhargav S and Tumanov, Alexey and Ramjee, Ramachandran , journal=. Taming throughput-latency tradeoff in
-
[45]
arXiv preprint arXiv:1804.05685 , year=
A discourse-aware attention model for abstractive summarization of long documents , author=. arXiv preprint arXiv:1804.05685 , year=
-
[46]
Sarathi: Efficient
Agrawal, Amey and Panwar, Ashish and Mohan, Jayashree and Kwatra, Nipun and Gulavani, Bhargav S and Ramjee, Ramachandran , journal=. Sarathi: Efficient
-
[47]
Splitwise: Efficient generative
Patel, Pratyush and Choukse, Esha and Zhang, Chaojie and Shah, Aashaka and Goiri,. Splitwise: Efficient generative. Power , volume=
-
[48]
arXiv preprint arXiv:2404.08509 , year=
Qiu, Haoran and Mao, Weichao and Patke, Archit and Cui, Shengkun and Jha, Saurabh and Wang, Chen and Franke, Hubertus and Kalbarczyk, Zbigniew T and Ba. Efficient interactive. arXiv preprint arXiv:2404.08509 , year=
-
[49]
Aladdin: Joint Placement and Scaling for SLO-Aware
Nie, Chengyi and Fonseca, Rodrigo and Liu, Zhenhua , journal=. Aladdin: Joint Placement and Scaling for SLO-Aware
-
[50]
ACM SIGMETRICS Performance Evaluation Review , volume=
The bayesian prophet: A low-regret framework for online decision making , author=. ACM SIGMETRICS Performance Evaluation Review , volume=. 2019 , publisher=
2019
-
[51]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[52]
Journal of Machine Learning Research , volume=
Palm: Scaling language modeling with pathways , author=. Journal of Machine Learning Research , volume=
-
[53]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review arXiv 2001
-
[54]
Achiam, Josh and Adler, Steven and Agarwal, Sandhini and Ahmad, Lama and Akkaya, Ilge and Aleman, Florencia Leoni and Almeida, Diogo and Altenschmidt, Janko and Altman, Sam and Anadkat, Shyamal and others , journal=
-
[55]
Emergent Abilities of Large Language Models
Emergent abilities of large language models , author=. arXiv preprint arXiv:2206.07682 , year=
work page internal anchor Pith review arXiv
-
[56]
Perplexity , title =
-
[57]
Nigel Cannings , title =
-
[58]
Replit Ghostwriter , howpublished =
-
[59]
2024 , url =
GilPress , title =. 2024 , url =
2024
-
[60]
2023 , url =
Sun, Yan , title =. 2023 , url =
2023
-
[61]
2024 , url =
Gordon, Cindy , title =. 2024 , url =
2024
-
[62]
Evaluating the feasibility of
Cascella, Marco and Montomoli, Jonathan and Bellini, Valentina and Bignami, Elena , journal=. Evaluating the feasibility of. 2023 , publisher=
2023
-
[63]
NPJ digital medicine , volume=
A study of generative large language model for medical research and healthcare , author=. NPJ digital medicine , volume=. 2023 , publisher=
2023
-
[64]
The utility of
Sallam, Malik , journal=. The utility of. 2023 , publisher=
2023
-
[65]
Efficient memory management for large language model serving with
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph and Zhang, Hao and Stoica, Ion , booktitle=. Efficient memory management for large language model serving with
-
[66]
Proceedings of Machine Learning and Systems , volume=
Efficiently scaling transformer inference , author=. Proceedings of Machine Learning and Systems , volume=
-
[67]
Flexgen: High-throughput generative inference of large language models with a single
Sheng, Ying and Zheng, Lianmin and Yuan, Binhang and Li, Zhuohan and Ryabinin, Max and Chen, Beidi and Liang, Percy and R. Flexgen: High-throughput generative inference of large language models with a single. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[68]
16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22) , pages=
Orca: A distributed serving system for \ Transformer-Based \ generative models , author=. 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22) , pages=
-
[69]
Distserve: Disaggregating prefill and decoding for goodput-optimized large language model serving , author=. arXiv preprint arXiv:2401.09670 , year=
-
[70]
SC20: International Conference for High Performance Computing, Networking, Storage and Analysis , pages=
Batch: Machine learning inference serving on serverless platforms with adaptive batching , author=. SC20: International Conference for High Performance Computing, Networking, Storage and Analysis , pages=. 2020 , organization=
2020
-
[71]
, author=
Online scheduling. , author=
-
[72]
Introduction to scheduling , pages=
Online scheduling , author=. Introduction to scheduling , pages=. 2009 , publisher=
2009
-
[73]
Advances in Neural Information Processing Systems , volume=
The power of optimization from samples , author=. Advances in Neural Information Processing Systems , volume=
-
[74]
Proceedings of the Twenty-Seventh Annual ACM-SIAM Symposium on Discrete Algorithms , pages =
Agrawal, Kunal and Li, Jing and Lu, Kefu and Moseley, Benjamin , title =. Proceedings of the Twenty-Seventh Annual ACM-SIAM Symposium on Discrete Algorithms , pages =. 2016 , isbn =
2016
-
[75]
Non-clairvoyant scheduling with precedence constraints , booktitle =
Julien Robert and Nicolas Schabanel , editor =. Non-clairvoyant scheduling with precedence constraints , booktitle =. 2008 , url =
2008
-
[76]
On-line scheduling with precedence constraints , journal =
Yossi Azar and Leah Epstein , abstract =. On-line scheduling with precedence constraints , journal =. 2002 , note =. doi:https://doi.org/10.1016/S0166-218X(01)00272-4 , url =
-
[77]
Non-Clairvoyant Precedence Constrained Scheduling , booktitle =
Naveen Garg and Anupam Gupta and Amit Kumar and Sahil Singla , editor =. Non-Clairvoyant Precedence Constrained Scheduling , booktitle =. 2019 , url =. doi:10.4230/LIPICS.ICALP.2019.63 , timestamp =
-
[78]
Beyond the Worst-Case Analysis of Algorithms , publisher =. 2020 , url =. doi:10.1017/9781108637435 , isbn =
-
[79]
2004 , url =
Handbook of Scheduling - Algorithms, Models, and Performance Analysis , publisher =. 2004 , url =
2004
-
[80]
Susanne Albers , title =. Math. Program. , volume =. 2003 , url =. doi:10.1007/S10107-003-0436-0 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.