Recognition: unknown
Reference-based Category Discovery: Unsupervised Object Detection with Category Awareness
Pith reviewed 2026-05-08 18:24 UTC · model grok-4.3
The pith
RefCD is an unsupervised object detector that uses feature similarity to unlabeled reference images to achieve category-aware detection without annotations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RefCD establishes that a carefully designed feature similarity loss between predicted objects and unlabeled reference images can explicitly guide the learning of potential category-specific features in an unsupervised object detector, enabling category-aware detection without any manually annotated labels or prior category knowledge.
What carries the argument
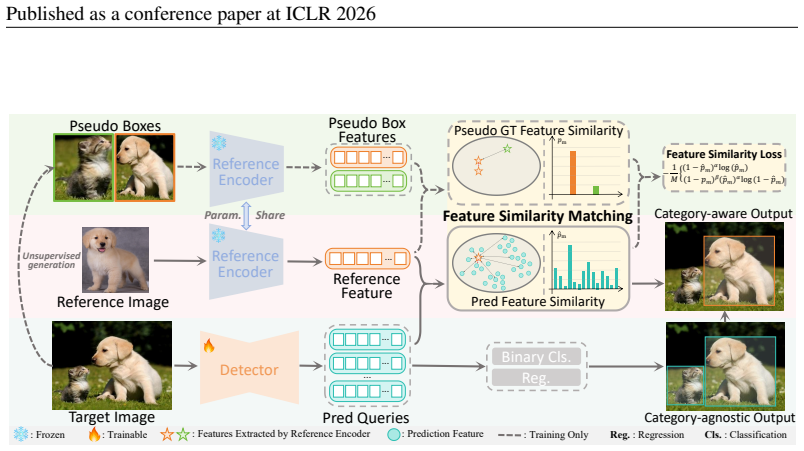
The feature similarity loss that matches features of predicted object regions to those of reference images to enforce category consistency during training.
If this is right
- Enables category-aware unsupervised object detection, unlike previous methods that only generate pseudo boxes without labels.
- Provides a single framework that works for both category-aware (with references) and category-agnostic detection.
- Demonstrates that category information can be learned unsupervisedly through reference-based feature matching.
- Improves detection performance by incorporating category guidance without supervision costs.
Where Pith is reading between the lines
- Reference images could be automatically selected or generated to further reduce human effort in setup.
- The approach might generalize to semi-supervised settings where few labels are available.
- It opens possibilities for incremental category discovery by adding new reference sets over time.
- Performance may depend on the diversity and relevance of the reference images provided.
Load-bearing premise
That similarities in deep features between predicted objects and unlabeled reference images can reliably signal shared category membership without any labels or prior knowledge.
What would settle it
Running the detector with the feature similarity loss disabled and observing no drop in category classification metrics compared to the full model.
Figures













read the original abstract
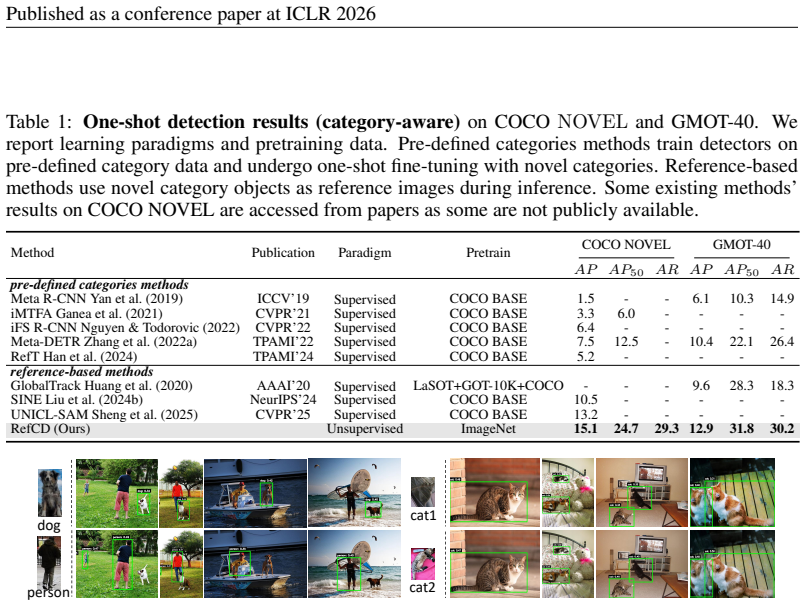
Traditional one-shot detection methods have addressed the closed-set problem in object detection, but the high cost of data annotation remains a critical challenge. General unsupervised methods generate pseudo boxes without category labels, thus failing to achieve category-aware classification. To overcome these limitations, we propose Reference-based Category Discovery (RefCD), an unsupervised detector that enables category-aware\footnotemark[1] detection without any manually annotated labels. It leverages feature similarity between predicted objects and unlabeled reference images. Unlike previous unsupervised methods that lack category guidance and one-shot methods which require labeled data, RefCD introduces a carefully designed feature similarity loss to explicitly guide the learning of potential category-specific features. Additionally, RefCD supports category-agnostic detection without reference images, serving as a unified framework. Comprehensive quantitative and qualitative analysis of category-aware and category-agnostic detection results demonstrates its effectiveness, and RefCD can learn category information in an unsupervised paradigm even without category labels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Reference-based Category Discovery (RefCD), an unsupervised object detection method that uses a carefully designed feature similarity loss between predicted objects and unlabeled reference images to induce category-specific features, enabling category-aware detection without manual annotations. It also supports a category-agnostic mode without references as a unified framework, with quantitative results, ablations, and qualitative examples on both modes.
Significance. If the results hold, this work is significant for reducing annotation costs in object detection by bridging unsupervised pseudo-box generation with category awareness. The manuscript provides ablations, quantitative results on category-aware and category-agnostic modes, and qualitative examples that directly support the central claim of reliable category guidance via feature similarity; these elements strengthen the evaluation and address concerns about the weakest assumption in the unsupervised setting.
minor comments (2)
- [Section 4] Section 4 (Experiments): the reference image selection process and its sensitivity analysis could be described with more explicit criteria or pseudocode to improve reproducibility.
- [Figures 4 and 5] Figure 4 and 5: the qualitative visualizations would benefit from consistent bounding-box color coding across category-aware and category-agnostic rows to aid direct comparison.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation for minor revision. The referee accurately captures the core contribution of Reference-based Category Discovery (RefCD) in bridging unsupervised pseudo-box generation with category awareness via feature similarity, as well as the unified support for both category-aware and category-agnostic modes. We are pleased that the evaluation elements (ablations, quantitative results, and qualitative examples) are viewed as strengthening the central claims.
Circularity Check
No significant circularity detected
full rationale
The paper introduces RefCD as a new unsupervised object detection framework that uses a designed feature similarity loss between predicted objects and unlabeled reference images to induce category-specific features. This construction is presented as an explicit design choice within the unsupervised paradigm, supported by ablations, quantitative results on both category-aware and category-agnostic modes, and qualitative examples. No load-bearing step reduces by construction to a fitted parameter, self-citation chain, or renamed input; the loss formulation and training pipeline remain internally consistent without self-definitional equivalence or imported uniqueness theorems. The central claim therefore retains independent content from the stated assumptions and experiments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Feature similarity between predicted objects and reference images can be used to infer category membership without labels
Reference graph
Works this paper leans on
-
[1]
Large Scale GAN Training for High Fidelity Natural Image Synthesis
Andrew Brock. Large scale gan training for high fidelity natural image synthesis.arXiv preprint arXiv:1809.11096,
work page internal anchor Pith review arXiv
-
[2]
Rad: A comprehensive dataset for bench- marking the robustness of image anomaly detection
11 Published as a conference paper at ICLR 2026 Yuqi Cheng, Yunkang Cao, Rui Chen, and Weiming Shen. Rad: A comprehensive dataset for bench- marking the robustness of image anomaly detection. InProceedings of the IEEE International Conference on Automation Science and Engineering, pp. 2123–2128. IEEE,
2026
-
[3]
arXiv preprint arXiv:1605.09782 , year=
Jeff Donahue, Philipp Kr¨ahenb¨uhl, and Trevor Darrell. Adversarial feature learning.arXiv preprint arXiv:1605.09782,
-
[4]
Van Gansbeke. Discovering object masks with transformers for unsupervised semantic segmenta- tion.arXiv preprint arXiv:2206.06363,
-
[5]
Focal loss for dense object detection
12 Published as a conference paper at ICLR 2026 Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll ´ar. Focal loss for dense object detection. InProceedings of the IEEE International Conference on Computer Vision, pp. 2980–2988,
2026
-
[6]
Siamese-detr for generic multi-object tracking
Qiankun Liu, Yichen Li, Yuqi Jiang, and Ying Fu. Siamese-detr for generic multi-object tracking. IEEE Transactions on Image Processing, pp. 3935–3949, 2024a. Yang Liu, Chenchen Jing, Hengtao Li, Muzhi Zhu, Hao Chen, Xinlong Wang, and Chunhua Shen. A simple image segmentation framework via in-context examples.arXiv preprint arXiv:2410.04842, 2024b. Anqi Ma...
-
[7]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review arXiv
-
[8]
arXiv preprint arXiv:2109.14279
Oriane Sim ´eoni, Gilles Puy, Huy V V o, Simon Roburin, Spyros Gidaris, Andrei Bursuc, Patrick P´erez, Renaud Marlet, and Jean Ponce. Localizing objects with self-supervised transformers and no labels.arXiv preprint arXiv:2109.14279,
-
[9]
Nenad Tomasev, Ioana Bica, Brian McWilliams, Lars Buesing, Razvan Pascanu, Charles Blundell, and Jovana Mitrovic. Pushing the limits of self-supervised resnets: Can we outperform supervised learning without labels on imagenet?arXiv preprint arXiv:2201.05119,
-
[10]
Large-scale unsuper- vised object discovery.Proceedings of the Advances in Neural Information Processing Systems, 34:16764–16778,
13 Published as a conference paper at ICLR 2026 Van Huy V o, Elena Sizikova, Cordelia Schmid, Patrick P´erez, and Jean Ponce. Large-scale unsuper- vised object discovery.Proceedings of the Advances in Neural Information Processing Systems, 34:16764–16778,
2026
-
[11]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Gongjie Zhang, Zhipeng Luo, Kaiwen Cui, Shijian Lu, and Eric P Xing. Meta-detr: Image-level few- shot detection with inter-class correlation exploitation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(11):12832–12843, 2022a. Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. Dino: Detr with...
work page internal anchor Pith review arXiv
-
[12]
Xingyi Zhou, Dequan Wang, and Philipp Kr ¨ahenb¨uhl. Objects as points.arXiv preprint arXiv:1904.07850,
-
[13]
The contents are organized as follows: •Section A.1 provides additional quantitative results of RefCD and presents some bad cases
14 Published as a conference paper at ICLR 2026 A APPENDIX The appendix provides more details and results that are not included in the main paper due to space limitations. The contents are organized as follows: •Section A.1 provides additional quantitative results of RefCD and presents some bad cases. •Section A.2 presents the impact of training data volu...
2026
-
[14]
Visualization and Analysis of Reference Images Only Contain Partial Views of An Object.Our detector faithfully detects objects similar to the reference images
As shown, RefCD demonstrates effective performance in most scenarios. Visualization and Analysis of Reference Images Only Contain Partial Views of An Object.Our detector faithfully detects objects similar to the reference images. As shown in Figure 8, detection results depend on reference images. If the reference image is a partial region of a car (e.g., ...
2026
-
[15]
Thus, we make some exploration in the weakly su- pervised domain. In this section, we first clarify the settings for weakly supervised training, then present experiments and analysis on the sensitivity of RefCD to box accuracy, and finally introduce two exploration methods for difficult cases. A.3.1 DATASET ANDSETTINGS COCOis a standard object detection b...
2010
-
[16]
17 Published as a conference paper at ICLR 2026 A.3.2 DISCUSSION ONTRAININGPSEUDOBOXESQUALITY This section focuses on exploring the impact of unreliable bounding boxes on the performance of object detectors, with a specific emphasis on comparing the behavior of RefCD with other detection methods. To provide concrete evidence for this analysis, experimenta...
2026
-
[17]
As noted in the main paper, RefCD adopts a unique training strategy that leverages pseudo boxes generated on the ImageNet dataset. A key characteristic of this approach is that the process of gener- ating these pseudo boxes, while valuable for training, is not without flaws and inevitably produces a certain number of unreliable results. As illustrated in ...
2026
-
[18]
Additionally, mask-level feature similarity assists the detector in better understanding the objects of interest
As illustrated, compared with unsupervised-trained RefCD, weakly super- vised training with higher-quality boxes enables more effective handling of crowded and occlusion scenarios. Additionally, mask-level feature similarity assists the detector in better understanding the objects of interest. Box-refinement mechanisms.RefCD uses multi-layer decoders to i...
2026
-
[19]
Since U2Seg does not provide runnable evaluation code, we report the results given in its original paper Niu et al. (2024). Please notethat the goal of this experiment does demonstrate better category-aware object detection performance of RefCD over U2Seg. A strictly fair comparison is not feasible. Existing unsuper- vised methods (e.g., U2Seg and CutLER)...
2024
-
[20]
Experiments are conducted on 2 RTX 3090 GPUs
In the data preprocessing stage, we generate local category feature embeddings for all pseudo boxes. Experiments are conducted on 2 RTX 3090 GPUs. The input image size is set to 560×560 (consistent with the inference stage), the batch size is set to 64, and the total running time is 20 hours. Please note that DINOv2 is a self-supervised trained feature ex...
2026
-
[21]
(2018) dataset
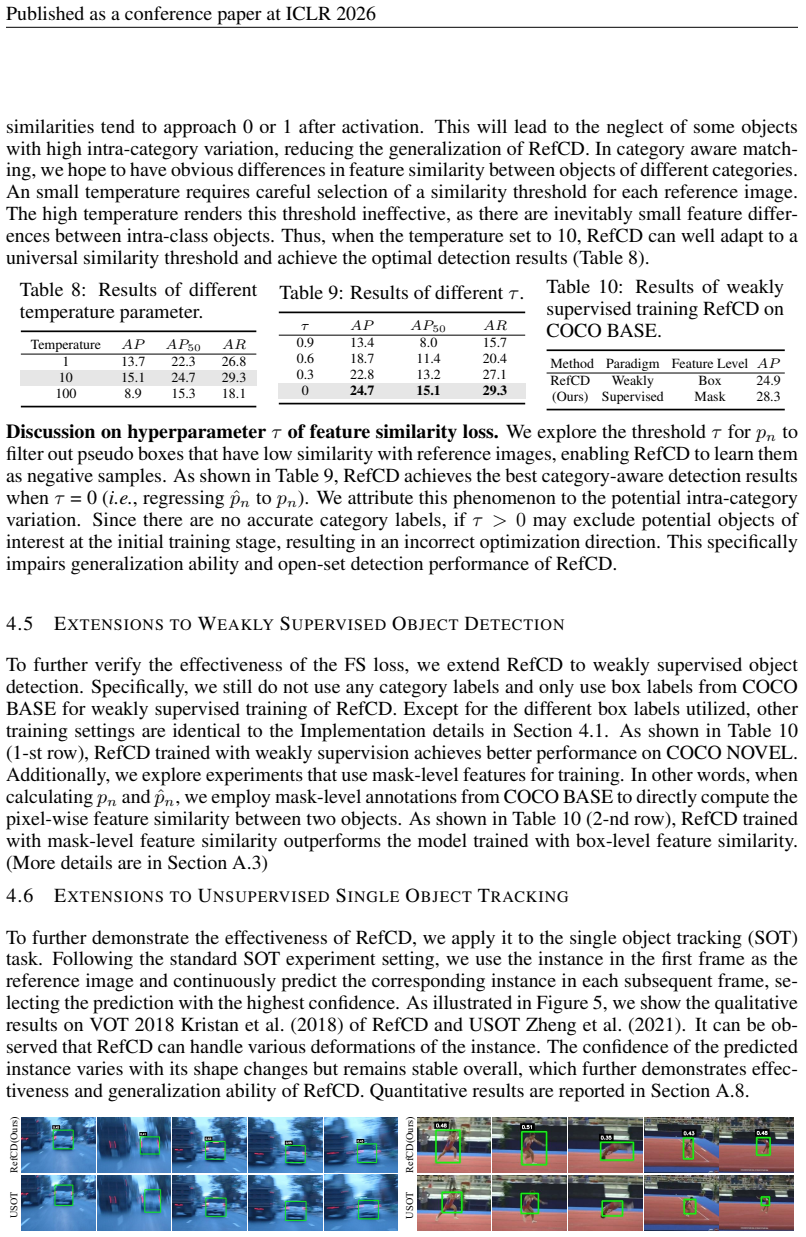
We conducted the SOT task evaluation on the VOT 2018 Kristan et al. (2018) dataset. It can be observed that RefCD achieves comparable performance on the SOT task compared to KCF Henriques et al. (2014) and USOT Zheng et al. (2021). KCF is a traditional tracker that achieves real-time object tracking based on kernelized correlation filtering. USOT leverage...
2018
-
[22]
orange” as Reference Image (d) “orange apple
However, in addition to intra-class variations, visually similar but semanti- cally distinct objects present another challenge for existing detectors. A similar limitation exists for both supervised and unsupervised detectors, as shown in Figure 14(a), DETR, which is supervised- trained on the COCO dataset, also struggles to distinguish between orange app...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.