Recognition: unknown
SWE-WebDevBench: Evaluating Coding Agent Application Platforms as Virtual Software Agencies
Pith reviewed 2026-05-08 16:22 UTC · model grok-4.3
The pith
AI coding platforms compress business needs into incomplete plans and fail to produce secure, production-ready full-stack applications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
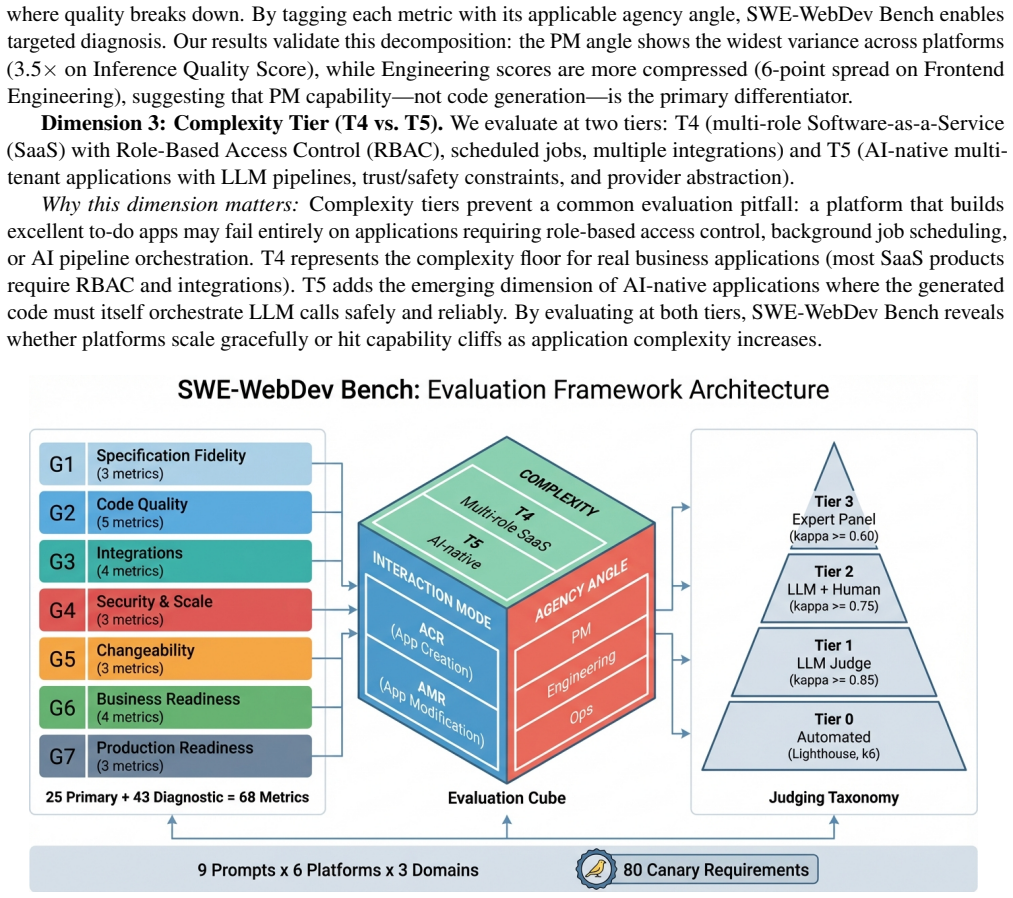
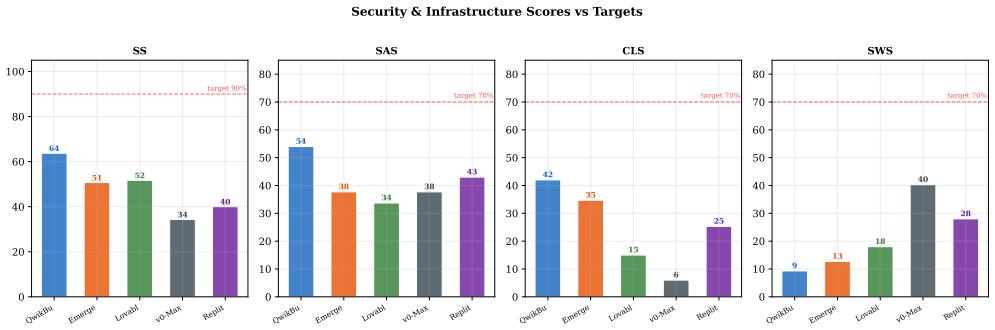
The authors present SWE-WebDevBench as a 68-metric framework organized along interaction mode (app creation versus modification), agency angle (product manager, engineering, operations), and complexity tier. When applied to six platforms in three domains, the evaluation shows recurring specification bottlenecks that reduce detailed business requirements to simplified plans, consistent frontend-backend decoupling where user interfaces appear complete but supporting infrastructure is missing or broken, engineering quality that never exceeds 60 percent, and security performance that stays below 65 percent against a 90 percent target with concurrency handling as low as 6 percent.
What carries the argument
The 68-metric evaluation framework (25 primary and 43 diagnostic metrics) that scores platforms on their ability to act as virtual software agencies across creation requests, modification requests, and multi-role complexity levels.
If this is right
- Platforms must expand their handling of business requirements to avoid compressing them into oversimplified technical plans.
- Generation processes need to enforce matching backend infrastructure for every generated user interface component.
- Engineering quality metrics must improve beyond the current ceiling of 60 percent to reduce required post-generation human effort.
- Security and infrastructure checks must reach closer to the 90 percent target, especially for concurrency and deployment readiness.
Where Pith is reading between the lines
- Future benchmarks could add metrics for long-term maintenance and iterative evolution of generated applications over multiple modification cycles.
- The observed gaps suggest platform builders should integrate more explicit checks for data consistency and access control during generation.
- Larger evaluations across additional domains would test whether the four shortcomings remain stable outside the current sample of six platforms.
Load-bearing premise
The chosen 68 metrics fully capture what these platforms can do as virtual agencies and the results from six platforms apply more broadly.
What would settle it
A platform that produces complete backend logic for every frontend feature, scores above 80 percent on engineering quality, and exceeds 85 percent on security and concurrency in the same benchmark cells would contradict the reported pattern of shortcomings.
Figures









read the original abstract
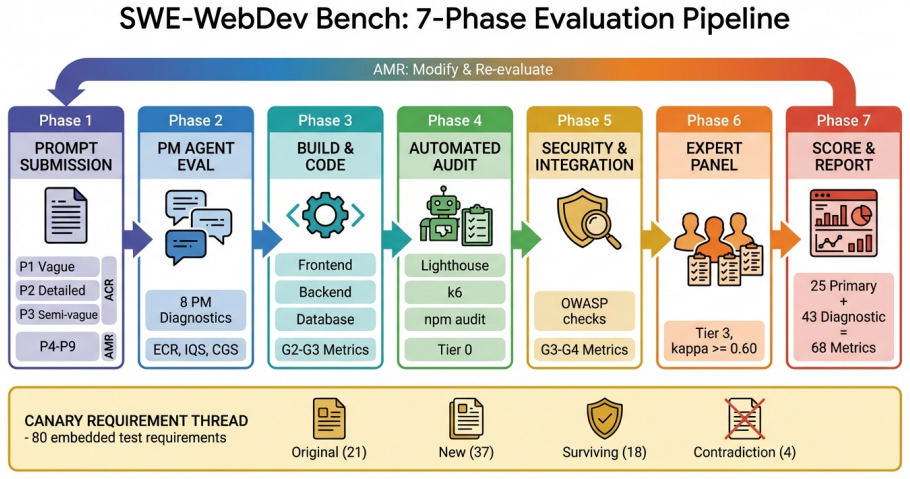
The emergence of "vibe coding" platforms, where users describe applications in natural language and AI agents autonomously generate full-stack software, has created a need for rigorous evaluation beyond code-level benchmarks. In order to assess them as virtual software development agencies on understanding business requirements, making architectural decisions, writing production code, handling iterative modifications, and maintaining business readiness, we introduce SWE-WebDev Bench, a 68-metric evaluation framework spanning 25 primary and 43 diagnostic metrics across seven groups, organized along three dimensions: Interaction Mode (App Creation Request (ACR) vs. App Modification Request (AMR)), Agency Angle (Product Manager (PM), Engineering, Ops), and Complexity Tier (T4 multi-role SaaS, T5 AI-native). Our evaluation (six platforms, three domains, 18 evaluation cells) reveals four recurring shortcomings in the current generation of AI app builders: (1) A specification bottleneck, where platforms compress rich business requirements into oversimplified technical plans, (2) A pervasive frontend-backend decoupling, where visually polished UIs mask absent or broken backend infrastructure, (3) A steep production-readiness cliff, where no platform scores above 60% on engineering quality and post-generation human effort varies substantially across platforms and (4) Widespread security and infrastructure failures, with no platform exceeding 65% Security Score against a 90% target and concurrency handling as low as 6%. These observations are descriptive of our sample and require larger-scale replication to establish generality. We release SWE-WebDev Bench as a community benchmark to enable such replication and help platform builders identify and address these gaps. Code and benchmark resources are available at: https://github.com/snowmountainAi/webdevbench and https://webdevbench.com/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SWE-WebDevBench, a 68-metric evaluation framework (25 primary + 43 diagnostic) organized along interaction mode (ACR/AMR), agency angle (PM/Engineering/Ops), and complexity tier (T4/T5). It evaluates six AI app-building platforms across three domains in 18 cells, identifying four recurring shortcomings in current platforms: specification bottleneck, frontend-backend decoupling, production-readiness cliff (no platform >60% engineering quality), and security/infrastructure failures (no platform >65% security score, concurrency as low as 6%). The authors release code, data, and the benchmark at GitHub and webdevbench.com, while explicitly stating that observations are descriptive of the sample and require larger-scale replication.
Significance. If the evaluation holds, this provides a structured, multi-dimensional benchmark for assessing AI coding agents as virtual software agencies, extending beyond code-level tests to business requirements, architecture, iterative modification, and production readiness. The public release of the full benchmark, code, and data is a clear strength supporting reproducibility and community extensions. This could help platform developers address identified gaps in 'vibe coding' systems.
major comments (2)
- [Evaluation Methodology] Evaluation Methodology (implied in abstract and results): Scoring methodology details for the 68 metrics are not provided, including rubrics for human-scored components, aggregation rules, or inter-rater reliability. This is load-bearing because quantitative thresholds (e.g., 'no platform scores above 60% on engineering quality', 'concurrency handling as low as 6%') cannot be verified or replicated without them.
- [Platform and Domain Selection] Platform and Domain Selection (implied in abstract): No justification is given for selecting the six platforms or three domains, nor sensitivity analysis on metric aggregation or selection bias. While the paper qualifies results as 'descriptive of our sample', the central claim of four 'recurring shortcomings' in 'the current generation' rests on this narrow sample (18 cells) without evidence of representativeness.
minor comments (2)
- [Introduction] The abstract and introduction should explicitly define 'vibe coding' and clarify how the 68 metrics map to the seven groups mentioned.
- [Appendix] Consider adding an appendix with example metric rubrics or sample evaluation cells to improve clarity for readers attempting replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript introducing SWE-WebDevBench. We address each major comment point by point below and describe the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: Evaluation Methodology (implied in abstract and results): Scoring methodology details for the 68 metrics are not provided, including rubrics for human-scored components, aggregation rules, or inter-rater reliability. This is load-bearing because quantitative thresholds (e.g., 'no platform scores above 60% on engineering quality', 'concurrency handling as low as 6%') cannot be verified or replicated without them.
Authors: We agree that comprehensive scoring details are essential for verification and replication. In the revised manuscript, we will add a dedicated 'Scoring Methodology' subsection that provides: (1) the complete rubrics for all 25 primary and 43 diagnostic metrics, including concrete examples and decision criteria for human-scored elements such as security posture and engineering quality; (2) the aggregation rules explaining how diagnostic metrics roll up into primary scores and the three agency angles; and (3) a description of the evaluation process, noting that scoring followed the predefined rubrics with internal consistency checks by the authors. The full rubrics, scoring scripts, and raw data are already released in the GitHub repository, and we will explicitly link to them from the paper. This directly addresses the replicability concern for the reported thresholds. revision: yes
-
Referee: Platform and Domain Selection (implied in abstract): No justification is given for selecting the six platforms or three domains, nor sensitivity analysis on metric aggregation or selection bias. While the paper qualifies results as 'descriptive of our sample', the central claim of four 'recurring shortcomings' in 'the current generation' rests on this narrow sample (18 cells) without evidence of representativeness.
Authors: We acknowledge that the original manuscript provides insufficient explicit justification for the sample. In the revision, we will insert a 'Platform and Domain Selection' paragraph in the Methods section explaining the criteria: the six platforms were selected as the most prominent publicly accessible AI app-building systems at the time of evaluation based on market visibility, feature completeness, and ability to handle full-stack generation; the three domains were chosen to span representative business use cases (e-commerce, productivity tools, and AI-native applications) at T4/T5 complexity. We will also report a basic sensitivity analysis on metric aggregation (e.g., re-computing overall scores under alternative weightings of the engineering-quality and security categories) and discuss potential selection biases. At the same time, we will strengthen the language to make clear that the four shortcomings are presented as observed patterns within this specific sample of 18 cells, consistent with the paper's existing statement that larger-scale replication is needed for generality. The public benchmark release is intended precisely to enable such broader validation. revision: partial
Circularity Check
No circularity: empirical benchmark with released code and data
full rationale
This is a pure empirical benchmark paper that defines 68 metrics across interaction modes, agency angles, and complexity tiers, then applies them to six platforms in three domains to produce descriptive scores. All central claims (specification bottleneck, frontend-backend decoupling, production-readiness cliff, security failures) are direct aggregates of those measured metrics; none reduce to fitted parameters, self-definitions, or self-citation chains. The authors explicitly label results as 'descriptive of our sample' and release code/data for replication, satisfying the self-contained criterion. No derivations or uniqueness theorems are invoked.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 68 metrics across seven groups adequately measure understanding of business requirements, architectural decisions, production code, iterative changes, and business readiness.
Reference graph
Works this paper leans on
-
[1]
The hottest new programming language is English
A. Karpathy. “The hottest new programming language is English.” Twitter/X, January 2023
2023
-
[2]
There’s a new kind of coding I call ‘vibe coding’
A. Karpathy. “There’s a new kind of coding I call ‘vibe coding’ . . . ” Twitter/X, February 2025
2025
-
[3]
M. Chen, J. Tworek, H. Jun, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review arXiv 2021
- [4]
-
[5]
C. E. Jimenez, J. Yang, A. Wettig, et al. SWE-bench: Can language models resolve real-world GitHub issues? InICLR, 2024
2024
-
[6]
L. Zhang, S. He, C. Zhang, et al. SWE-bench goes live!arXiv preprint arXiv:2505.23419, 2025
- [7]
-
[8]
H. Tran, L. Nashold, R. Krishnan, A. Bigeard, A. Gu. Vibe Code Bench: Evaluating AI models on end-to-end web application development.arXiv preprint arXiv:2603.04601, March 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [9]
-
[10]
M. Ortiz et al. From Prompt to Product: A human-centered benchmark of agentic app generation systems. arXiv preprint arXiv:2512.18080, December 2025
- [11]
-
[12]
Fullstack bench: Evaluating llms as full stack coders
ByteDance Seed Foundation Code Team. FullStack Bench: Evaluating LLMs as full stack coders.arXiv preprint arXiv:2412.00535, December 2024
- [13]
-
[14]
A review of OpenAI’s o1 and how we evaluate coding agents
Cognition Team. A review of OpenAI’s o1 and how we evaluate coding agents. Cognition AI Blog, September 2024
2024
-
[15]
Program Synthesis with Large Language Models
J. Austin, A. Odena, M. Nye, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review arXiv 2021
-
[16]
Closing the evaluation gap in agentic AI: Open Benchmarks Grant program
Snorkel AI. Closing the evaluation gap in agentic AI: Open Benchmarks Grant program. Snorkel AI Blog, February 2026
2026
- [17]
-
[18]
Zheng, W.-L
L. Zheng, W.-L. Chiang, Y . Sheng, et al. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. In NeurIPS, 2023
2023
-
[19]
S. Kim, J. Shin, Y . Cho, et al. Prometheus: Inducing fine-grained evaluation capability in language models. In ICLR, 2024
2024
-
[20]
Z. Li, X. Li, Y . Liu, et al. Generative judge for evaluating alignment. InICLR, 2024. 32
2024
-
[21]
Liang, R
P. Liang, R. Bommasani, T. Lee, et al. Holistic evaluation of language models.Transactions on Machine Learning Research, 2023
2023
-
[22]
Kiela, M
D. Kiela, M. Bartolo, Y . Nie, et al. Dynabench: Rethinking benchmarking in NLP. InNAACL, 2021
2021
-
[23]
Gebru, J
T. Gebru, J. Morgenstern, B. Vecchione, et al. Datasheets for datasets.Communications of the ACM, 64(12):86– 92, 2021. 33 Appendix A Complete Per-Metric Scores: P1 ExamEdge Table 16: All primary metrics for P1 ExamEdge Academy across five platforms. Grp Metric E1 L0 Q1 R3 V0 G1 BIF (Business Intent) 3/4 2/4 4/4 2/4 1/4 G1 FCS (Feature Complete) 65.0 35.0 ...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.