Recognition: 2 theorem links
· Lean TheoremCAST: Mitigating Object Hallucination in Large Vision-Language Models via Caption-Guided Visual Attention Steering
Pith reviewed 2026-05-08 17:58 UTC · model grok-4.3
The pith
Steering attention heads using patterns from caption queries reduces object hallucination in vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
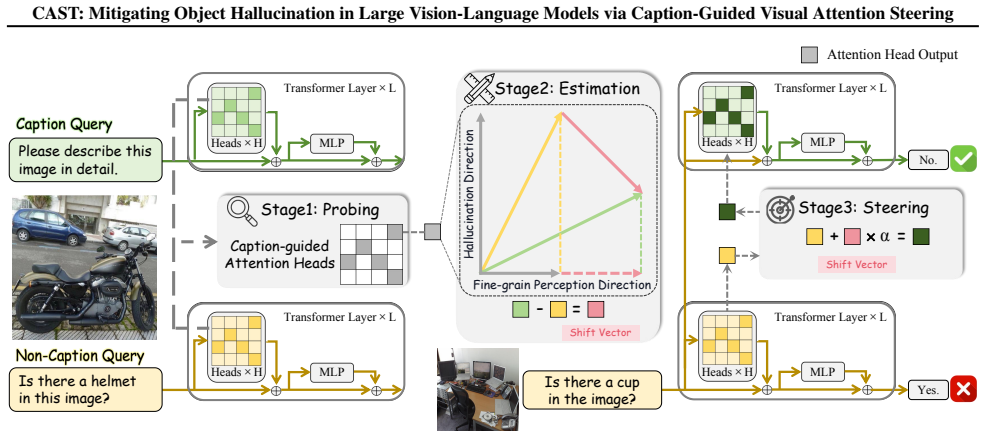
The central claim is that attention heads identified through probing as highly sensitive to caption queries can be steered in an optimized direction to enhance fine-grained visual perception, which in turn lowers the rate at which the model invents nonexistent objects.
What carries the argument
Caption-guided visual attention steering, which identifies caption-sensitive attention heads via probing and applies estimated steering directions to their outputs at inference time.
If this is right
- Object hallucination drops by an average of 6.03 percent across five models and five benchmarks that include both discriminative and generative tasks.
- The same steering works for multiple widely used large vision-language models.
- Inference time increases only slightly while the model's core capabilities on other tasks stay intact.
- No manual annotations or additional training are required to obtain the reported gains.
Where Pith is reading between the lines
- The same head-identification step could be reused to target other inconsistencies such as spatial or attribute errors.
- Running the probe on even larger models might show whether the sensitive heads remain stable as scale increases.
- Pairing the steering with existing decoding adjustments could produce additive reductions in hallucination rates.
Load-bearing premise
That the steering directions derived from caption-query patterns will reliably improve visual focus for arbitrary queries without creating new errors or harming other model abilities.
What would settle it
Apply the method to a previously untested vision-language model on a new benchmark and check whether object hallucination rates remain unchanged or other performance metrics decline.
Figures






read the original abstract
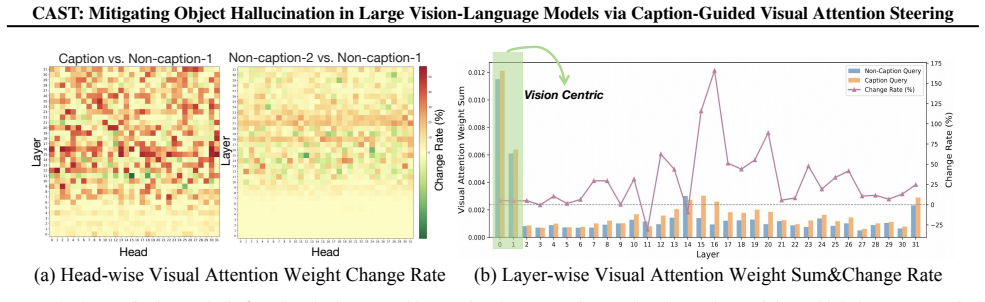
Although Large Vision-Language Models (LVLMs) have demonstrated remarkable performance on downstream tasks, they frequently produce contents that deviate from visual information, leading to object hallucination. To tackle this, recent works mostly depend on expensive manual annotations and training cost, or decoding strategies which significantly increase inference time. In this work, we observe that LVLMs' attention to visual information is significantly enhanced when answering caption queries compared to non-caption queries. Inspired by this phenomenon, we propose Caption-guided Visual Attention Steering (CAST), a training-free, plug-and-play hallucination mitigation method that leverages the attention activation pattern corresponding to caption queries to enhance LVLMs' visual perception capability. Specifically, we use probing techniques to identify attention heads that are highly sensitive to caption queries and estimate optimized steering directions for their outputs. This steering strengthens LVLM's fine-grained visual perception capabilities, thereby effectively mitigating object hallucination. CAST reduced object hallucination by an average of 6.03% across five widely used LVLMs and five benchmarks including both discriminative and generative tasks, demonstrating state-of-the-art performance while adding little inference cost and preserving other foundational capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CAST, a training-free, plug-and-play method to mitigate object hallucination in LVLMs. It starts from the observation that caption queries elicit stronger visual attention than non-caption queries. The approach uses probing to identify attention heads sensitive to caption queries, estimates steering directions for their outputs, and applies this steering at inference time to strengthen fine-grained visual perception. Experiments across five LVLMs and five benchmarks (discriminative and generative) report an average 6.03% reduction in object hallucination, state-of-the-art performance, negligible added inference cost, and preservation of other model capabilities.
Significance. If the quantitative results hold, CAST offers a practical, low-overhead solution to a central limitation of current LVLMs. The training-free design, multi-model/multi-benchmark evaluation, and reported ablations on head selection are concrete strengths that support claims of broad applicability and ease of adoption. The empirical grounding via probing rather than direct optimization on hallucination metrics reduces the risk of circularity.
minor comments (3)
- [Abstract] Abstract: the reported 6.03% average reduction would be more informative if the abstract briefly named the five LVLMs and five benchmarks and indicated whether the gains are accompanied by statistical significance tests or variance estimates.
- [§4] §4 (Experiments): while the manuscript includes ablations on head selection, adding explicit controls or sensitivity analysis for prompt phrasing would further address potential concerns about post-hoc head selection affecting the central quantitative claim.
- [Figure 3] Figure 3 or corresponding table: ensure that the steering direction estimation procedure is described with sufficient precision (e.g., exact optimization objective and number of probing samples) so that the method can be reproduced from the text alone.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. The recognition of CAST as a practical, training-free approach with strong multi-model and multi-benchmark results is appreciated. No specific major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper describes an empirical, training-free intervention: it observes stronger visual attention under caption queries, uses probing to locate sensitive heads, and applies estimated steering directions. All reported gains (6.03 % average reduction) are measured outcomes on held-out benchmarks across five LVLMs; no equation or derivation reduces the final performance metric to a fitted parameter or self-citation by construction. The method remains self-contained against external evaluation and does not invoke uniqueness theorems or prior self-work as load-bearing premises.
Axiom & Free-Parameter Ledger
free parameters (2)
- steering directions
- head selection threshold
axioms (1)
- domain assumption LVLMs exhibit significantly enhanced attention to visual information when processing caption queries versus non-caption queries.
Lean theorems connected to this paper
-
Foundation/AlphaCoordinateFixation, Cost/FunctionalEquationwashburn_uniqueness_aczel unclearWe use grid search to find the optimal value for both hyperparameters on the POPE dataset... alpha=1.5 and K=100 in the main experiments.
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[9]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[10]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[11]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[12]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[13]
Clancey and Glenn Rennels , abstract =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[14]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[15]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[16]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[17]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[18]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[19]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
-
[20]
Advances in neural information processing systems , volume=
Locating and editing factual associations in gpt , author=. Advances in neural information processing systems , volume=
-
[21]
arXiv preprint arXiv:2504.07898 , year=
How do Large Language Models Understand Relevance? A Mechanistic Interpretability Perspective , author=. arXiv preprint arXiv:2504.07898 , year=
-
[22]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Are vision-language transformers learning multimodal representations? a probing perspective , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[23]
arXiv preprint arXiv:2406.04236 , year=
Understanding information storage and transfer in multi-modal large language models , author=. arXiv preprint arXiv:2406.04236 , year=
-
[24]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Towards vision-language mechanistic interpretability: A causal tracing tool for blip , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[25]
What Do VLMs NOTICE? A Mechanistic Interpretability Pipeline for Gaussian-Noise-free Text-Image Corruption and Evaluation , author=. arXiv preprint arXiv:2406.16320 , year=
-
[26]
Towards interpreting visual information processing in vision-language models , author=. arXiv preprint arXiv:2410.07149 , year=
-
[27]
Mmneuron: Discovering neuron-level domain-specific interpretation in multimodal large language model , author=. arXiv preprint arXiv:2406.11193 , year=
-
[29]
A Survey on Hallucination in Large Vision-Language Models
A survey on hallucination in large vision-language models , author=. arXiv preprint arXiv:2402.00253 , year=
work page internal anchor Pith review arXiv
-
[30]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[31]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
A comprehensive survey of hallucination in large language, image, video and audio foundation models , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[32]
European conference on computer vision , pages=
A-okvqa: A benchmark for visual question answering using world knowledge , author=. European conference on computer vision , pages=. 2022 , organization=
2022
-
[33]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[34]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-vl: A frontier large vision-language model with versatile abilities , author=. arXiv preprint arXiv:2308.12966 , year=
work page internal anchor Pith review arXiv
-
[35]
Evaluating Object Hallucination in Large Vision-Language Models
Evaluating object hallucination in large vision-language models , author=. arXiv preprint arXiv:2305.10355 , year=
work page internal anchor Pith review arXiv
-
[36]
ArXiv , year=
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models , author=. ArXiv , year=
-
[37]
Aligning large multimodal models with factually augmented rlhf.arXiv preprint arXiv:2309.14525, 2023
Aligning large multimodal models with factually augmented rlhf , author=. arXiv preprint arXiv:2309.14525 , year=
-
[38]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Gqa: A new dataset for real-world visual reasoning and compositional question answering , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[39]
Computer Vision--ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13 , pages=
Microsoft coco: Common objects in context , author=. Computer Vision--ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13 , pages=. 2014 , organization=
2014
-
[40]
Object Hallucination in Image Captioning
Object hallucination in image captioning , author=. arXiv preprint arXiv:1809.02156 , year=
-
[41]
Alleviating Hallucinations in Large Vision-Language Models through Hallucination-Induced Optimization , author=. arXiv preprint arXiv:2405.15356 , year=
-
[42]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Detecting and preventing hallucinations in large vision language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[43]
The Twelfth International Conference on Learning Representations , year=
Mitigating hallucination in large multi-modal models via robust instruction tuning , author=. The Twelfth International Conference on Learning Representations , year=
-
[44]
RLAIF-V: Aligning mllms through open-source ai feedback for super gpt-4v trustworthiness
Rlaif-v: Aligning mllms through open-source ai feedback for super gpt-4v trustworthiness , author=. arXiv preprint arXiv:2405.17220 , year=
-
[45]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mitigating object hallucinations in large vision-language models through visual contrastive decoding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[46]
arXiv preprint arXiv:2403.00425 , year=
Halc: Object hallucination reduction via adaptive focal-contrast decoding , author=. arXiv preprint arXiv:2403.00425 , year=
-
[47]
Dola: Decoding by contrasting layers improves factuality in large language models
Dola: Decoding by contrasting layers improves factuality in large language models , author=. arXiv preprint arXiv:2309.03883 , year=
-
[48]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[49]
Science China Information Sciences , volume=
Woodpecker: Hallucination correction for multimodal large language models , author=. Science China Information Sciences , volume=. 2024 , publisher=
2024
-
[50]
V olcano: Mitigating multimodal hallucination through self-feedback guided revision
Volcano: mitigating multimodal hallucination through self-feedback guided revision , author=. arXiv preprint arXiv:2311.07362 , year=
-
[51]
arXiv preprint arXiv:2402.08680 , year=
Mitigating object hallucination in large vision-language models via classifier-free guidance , author=. arXiv preprint arXiv:2402.08680 , year=
-
[52]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[53]
Cogvlm2: Visual language models for image and video understanding , author=. arXiv preprint arXiv:2408.16500 , year=
-
[54]
Machine Learning , year=
Support-Vector Networks , author=. Machine Learning , year=
-
[55]
Analyzing and mitigating object hallucination in large vision-language models,
Analyzing and mitigating object hallucination in large vision-language models , author=. arXiv preprint arXiv:2310.00754 , year=
-
[56]
Mitigating object hallucination via concentric causal attention , author=. arXiv preprint arXiv:2410.15926 , year=
-
[57]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions , author=. arXiv preprint arXiv:2311.05232 , year=
work page internal anchor Pith review arXiv
-
[58]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[59]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , author=. arXiv preprint arXiv:2403.05530 , year=
work page internal anchor Pith review arXiv
-
[60]
Ferret: Refer and ground anything anywhere at any granularity.arXiv preprint arXiv:2310.07704, 2023
Ferret: Refer and ground anything anywhere at any granularity , author=. arXiv preprint arXiv:2310.07704 , year=
-
[61]
Attention heads of large language models: A survey.arXiv preprint arXiv:2409.03752,
Attention heads of large language models: A survey , author=. arXiv preprint arXiv:2409.03752 , year=
-
[62]
Retrieval head mechanistically explains long-context factuality , author=. arXiv preprint arXiv:2404.15574 , year=
-
[63]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae , month=. LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
-
[65]
2024 , eprint=
VDGD: Mitigating LVLM Hallucinations in Cognitive Prompts by Bridging the Visual Perception Gap , author=. 2024 , eprint=
2024
-
[66]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Multi-modal hallucination control by visual information grounding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[67]
arXiv preprint arXiv:2501.01926 , year=
Mitigating Hallucination for Large Vision Language Model by Inter-Modality Correlation Calibration Decoding , author=. arXiv preprint arXiv:2501.01926 , year=
-
[68]
arXiv preprint arXiv:2411.12713 , year=
CATCH: Complementary Adaptive Token-level Contrastive Decoding to Mitigate Hallucinations in LVLMs , author=. arXiv preprint arXiv:2411.12713 , year=
-
[69]
doi:10.48550/arXiv.2402.18476 , abstract =
Ibd: Alleviating hallucinations in large vision-language models via image-biased decoding , author=. arXiv preprint arXiv:2402.18476 , year=
-
[70]
Mitigating modality prior-induced hallucinations in multimodal large language models via deciphering attention causality , author=. arXiv preprint arXiv:2410.04780 , year=
-
[71]
Mitigating hallucinations in large vision-language models with instruction contrastive decoding , author=. arXiv preprint arXiv:2403.18715 , year=
-
[72]
2024 , eprint=
Investigating and Mitigating the Multimodal Hallucination Snowballing in Large Vision-Language Models , author=. 2024 , eprint=
2024
-
[73]
and Varoquaux, G
Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V. and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P. and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E. , journal=. Scikit-learn: Machine Learning in
-
[74]
arXiv preprint arXiv:2501.12206 , year=
Fixing Imbalanced Attention to Mitigate In-Context Hallucination of Large Vision-Language Model , author=. arXiv preprint arXiv:2501.12206 , year=
-
[75]
ArXiv , year=
Unveiling Visual Perception in Language Models: An Attention Head Analysis Approach , author=. ArXiv , year=
-
[76]
arXiv preprint arXiv:2406.12718 (2024)
Agla: Mitigating object hallucinations in large vision-language models with assembly of global and local attention , author=. arXiv preprint arXiv:2406.12718 , year=
-
[77]
arXiv preprint arXiv:2410.04514 , year=
Damro: Dive into the attention mechanism of lvlm to reduce object hallucination , author=. arXiv preprint arXiv:2410.04514 , year=
-
[78]
Advances in Neural Information Processing Systems , volume=
Mitigating object hallucination via concentric causal attention , author=. Advances in Neural Information Processing Systems , volume=
-
[79]
European Conference on Computer Vision , pages=
Paying more attention to image: A training-free method for alleviating hallucination in lvlms , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[80]
Reducing hallucinations in vision-language models via latent space steering , author=. arXiv preprint arXiv:2410.15778 , year=
-
[81]
arXiv preprint arXiv:2412.18108 , year=
Unveiling Visual Perception in Language Models: An Attention Head Analysis Approach , author=. arXiv preprint arXiv:2412.18108 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.