Recognition: 3 theorem links
CodeEvolve: LLM-Driven Evolutionary Optimization with Runtime-Enriched Target Selection for Multi-Language Code Enhancement
Pith reviewed 2026-05-08 17:43 UTC · model grok-4.3
The pith
Runtime-guided LLM evolution with layered validation produces 15x average speedups on enterprise Java code while keeping programs correct.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
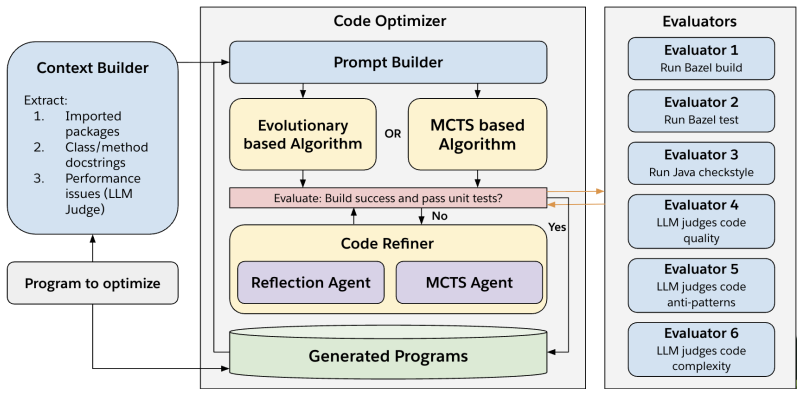
CodeEvolve extends evolutionary optimization by adding runtime-enriched target selection that builds weighted component graphs from Java Flight Recorder profiles to focus on high-cost sections, Monte Carlo Tree Search for generating edits, and a multi-stage pipeline of build validation, unit tests, performance checks, static analysis, and LLM review that retains only functionally correct variants. On a large enterprise Java codebase this produces an average 15.22 times speedup across seven hotspot functions and outperforms single-pass LLM optimization on five of them. An ablation study on Apex tasks shows the full configuration yields 19.5 valid programs out of 20 on average, with each added
What carries the argument
The runtime-enriched target selection that constructs weighted component graphs from execution profiles to prioritize code sections accounting for most runtime cost.
If this is right
- Performance gains become possible on multiple functions without requiring manual identification of bottlenecks.
- Multi-stage filtering maintains functional correctness across generated variants in both Java and Apex.
- The full search-plus-refinement configuration increases the fraction of valid optimized programs compared with simpler LLM edits.
- Language-specific evaluation pipelines allow the same core approach to apply to different programming environments.
Where Pith is reading between the lines
- If the validation layers hold up under broader testing, the method could support continuous integration pipelines that periodically optimize live codebases.
- The same runtime-guided selection idea might be adapted to other objectives such as reducing memory footprint or improving energy use.
- Further experiments could test whether the evolutionary loop scales to even larger codebases or to additional languages beyond the two demonstrated.
Load-bearing premise
The combination of build validation, unit tests, performance checks, static analysis, and LLM-based review is sufficient to guarantee functional correctness without missing subtle bugs or regressions in any generated variant.
What would settle it
A generated code variant that passes every validation step yet produces incorrect results or a performance regression when run on real production data or under unseen inputs.
Figures

read the original abstract
We present CodeEvolve, an evolutionary framework for improving program performance and code quality with Large Language Models (LLMs). CodeEvolve extends OpenEvolve with runtime-guided target selection, Monte Carlo Tree Search (MCTS), automated code refinement, and language-specific evaluation pipelines for Java and Salesforce Apex. The system uses Java Flight Recorder (JFR) profiles to build weighted component graphs and select optimization targets that account for most execution cost, reducing reliance on manual bottleneck identification. For each target, CodeEvolve generates candidate edits, evaluates them through build validation, unit tests, performance checks, static analysis, and LLM-based review, and retains only variants that preserve functional correctness. Across real-world optimization tasks, CodeEvolve improves performance and code metrics while maintaining correctness. On a large enterprise Java codebase, it achieves an average speedup of 15.22$\times$ across seven hotspot functions and outperforms single-pass LLM optimization on five of them. An ablation study on Apex optimization shows that the full MCTS-augmented configuration produces 19.5 valid programs out of 20 on average, indicating that search, filtering, and refinement each contribute to more reliable optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CodeEvolve, an evolutionary framework extending OpenEvolve that integrates LLM-based code editing with runtime-guided target selection via Java Flight Recorder profiles, Monte Carlo Tree Search, automated refinement, and language-specific validation pipelines for Java and Salesforce Apex. It claims that the system produces functionally correct optimizations, achieving an average 15.22× speedup across seven hotspot functions in a large enterprise Java codebase while outperforming single-pass LLM optimization on five of them, and reports an ablation on Apex showing the full MCTS configuration yields 19.5 valid programs out of 20 on average.
Significance. If the empirical claims are substantiated with rigorous methodology, the work offers a practical advance in automated performance optimization by combining runtime profiling for target selection with evolutionary search and multi-stage filtering. The multi-language support and explicit use of JFR-weighted graphs to reduce manual bottleneck identification are concrete strengths that could influence industrial tooling.
major comments (3)
- [Java evaluation results] Java results subsection: The central claim of a 15.22× average speedup across seven functions is reported without any description of measurement protocol (warm-up iterations, number of independent runs, hardware, statistical tests for significance, or variance across functions). This information is required to evaluate whether the reported factor is reproducible and load-bearing for the performance contribution.
- [Method, validation pipeline] Validation pipeline description: The pipeline (build validation, unit tests, performance checks, static analysis, LLM review) is asserted to retain only functionally correct variants, yet no coverage metrics, differential testing results, or handling of concurrency/numeric edge cases are provided. Because the speedup claim depends on equivalence, incomplete oracles constitute a correctness risk that must be addressed with concrete evidence.
- [Ablation study] Ablation study: The Apex ablation reports an average of 19.5 valid programs out of 20 for the full configuration but does not define 'valid' operationally, report per-component contributions with error bars, or state the total number of trials. This weakens the claim that search, filtering, and refinement each contribute measurably.
minor comments (2)
- [Experimental setup] The baseline 'single-pass LLM optimization' is referenced in the Java comparison but its exact prompt, temperature, and stopping criteria are not specified, hindering direct replication.
- [Figures and tables] Figure captions and table headers could more explicitly link each metric to the corresponding validation stage.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments highlight important areas for improving methodological transparency and empirical rigor in the manuscript. We address each major comment below and will revise the paper to incorporate the requested clarifications and evidence.
read point-by-point responses
-
Referee: [Java evaluation results] Java results subsection: The central claim of a 15.22× average speedup across seven functions is reported without any description of measurement protocol (warm-up iterations, number of independent runs, hardware, statistical tests for significance, or variance across functions). This information is required to evaluate whether the reported factor is reproducible and load-bearing for the performance contribution.
Authors: We agree that the measurement protocol was insufficiently detailed. In the revised manuscript, we will add a dedicated subsection under Experimental Setup that fully describes the warm-up iterations, number of independent runs, hardware specifications, statistical tests for significance, and variance reporting across functions and runs. These additions will allow readers to assess the reproducibility of the 15.22× average speedup. revision: yes
-
Referee: [Method, validation pipeline] Validation pipeline description: The pipeline (build validation, unit tests, performance checks, static analysis, LLM review) is asserted to retain only functionally correct variants, yet no coverage metrics, differential testing results, or handling of concurrency/numeric edge cases are provided. Because the speedup claim depends on equivalence, incomplete oracles constitute a correctness risk that must be addressed with concrete evidence.
Authors: We acknowledge that the validation pipeline description lacks quantitative supporting evidence. We will revise the relevant section to include coverage metrics, results from differential testing, and explicit descriptions of how concurrency and numeric edge cases are handled. This will provide concrete evidence that the pipeline retains only functionally correct variants. revision: yes
-
Referee: [Ablation study] Ablation study: The Apex ablation reports an average of 19.5 valid programs out of 20 for the full configuration but does not define 'valid' operationally, report per-component contributions with error bars, or state the total number of trials. This weakens the claim that search, filtering, and refinement each contribute measurably.
Authors: We agree that the ablation study requires clearer operational definitions and statistical presentation. In the revision, we will define 'valid' operationally, report per-component contributions with error bars, and state the total number of trials. This will strengthen the evidence that each component contributes measurably to the results. revision: yes
Circularity Check
No circularity: empirical speedups and validity counts are measured outcomes, not derived by construction
full rationale
The paper presents CodeEvolve as an applied evolutionary framework combining LLMs, MCTS, runtime profiling, and multi-stage validation pipelines. All load-bearing claims (15.22× average speedup on seven Java hotspots, outperformance vs single-pass LLM on five, 19.5/20 valid Apex programs in ablation) are reported as direct experimental measurements on external codebases after applying the system. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-referential definitions appear in the provided text. The validation pipeline (build, unit tests, performance checks, static analysis, LLM review) is described as an empirical filter rather than a mathematical identity. Self-citations are absent from the abstract and claims. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM-generated code edits that pass unit tests, static analysis, and LLM review preserve functional correctness for the evaluated workloads.
- domain assumption JFR-derived weighted component graphs identify the code sections whose optimization produces the largest end-to-end performance improvement.
Lean theorems connected to this paper
-
Contrast with Foundation/AlphaCoordinateFixation.lean (parameter-free α=1 forcing)alpha_pin_under_high_calibration unclearstage thresholds are τ1 = 0.5, τ2 = 0.75, and τ3 = 0.9, with LLM-based evaluator scores weighted by α=0.1
Reference graph
Works this paper leans on
-
[1]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large 11 Algorithm 3Evolutionary Code Optimization 1:Initialize population with the initial program 2:fori= 1tomax_iterationsdo 3:Select a parent program using island-based sampling 4:Gen...
work page internal anchor Pith review arXiv 2021
-
[2]
Thomas Ball and James R. Larus. Optimally profiling and tracing programs.ACM Transactions on Programming Languages and Systems (TOPLAS), 16(4):1319–1360, 1994
1994
-
[3]
Springer Science & Business Media, 2007
Markus Brameier and Wolfgang Banzhaf.Linear Genetic Programming. Springer Science & Business Media, 2007
2007
-
[4]
Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, volume 33, pages 1877–1901, 2020
1901
-
[5]
Cameron B. Browne, Edward J. Powley, Daniel Whitehouse, Simon Lucas, Peter I. Cowling, Philipp Rohlfshagen, Stewart Tavener, Diego Perez, Spyros Samothrakis, and Simon Colton. A survey of monte carlo tree search methods.IEEE Transactions on Computational Intelligence 12 and AI in Games, 4(1):1–49, March 2012. ISSN 1943-068X. doi: 10.1109/TCIAIG.2012. 2186810
-
[6]
Codet: Code generation with generated tests.arXiv preprint arXiv:2307.14987, 2023
Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. Codet: Code generation with generated tests.arXiv preprint arXiv:2307.14987, 2023
-
[7]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review arXiv 2021
-
[8]
Donald E. Knuth. An empirical study of fortran programs.Software: Practice and Experience, 1(2):105–133, 1971
1971
-
[9]
Koza.Genetic Programming: On the Programming of Computers by Means of Natural Selection
John R. Koza.Genetic Programming: On the Programming of Computers by Means of Natural Selection. MIT Press, Cambridge, MA, 1992. ISBN 0-262-11170-5
1992
-
[10]
Competition-level code generation with alphacode.Science, 378(6624):1092–1097, 2022
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with alphacode.Science, 378(6624):1092–1097, 2022
2022
-
[11]
Jinyu Mei, Yifan Li, Xin Zhang, Zhuo Wang, and Yu Yang. Llamea: Large language model evolutionary algorithm for automated algorithm design.arXiv preprint arXiv:2403.18646, 2024
-
[12]
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis
Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. Codegen: An open large language model for code with multi-turn program synthesis.arXiv preprint arXiv:2203.13474, 2023
work page internal anchor Pith review arXiv 2023
-
[13]
Alexander Novikov, Ngân V u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. Alphaevolve: A coding agent for scientific and algor...
work page internal anchor Pith review arXiv 2025
-
[14]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Flo- rencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Bern...
work page internal anchor Pith review arXiv 2024
-
[15]
Java flight recorder
Oracle Corporation. Java flight recorder. Oracle Documentation, 2023. URL https://docs. oracle.com/javacomponents/jmc-5-5/jfr-runtime-guide/
2023
-
[16]
Openevolve: an open-source evolutionary coding agent, 2025
Asankhaya Sharma. Openevolve: an open-source evolutionary coding agent, 2025. URL https://github.com/algorithmicsuperintelligence/openevolve
2025
-
[17]
Re- flexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Re- flexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[18]
Ldb: A large language model debugger for code generation.arXiv preprint arXiv:2401.15428, 2024
Kechi Zhang, Ge Li, Yongfei Jin, and Xianjie Wang. Ldb: A large language model debugger for code generation.arXiv preprint arXiv:2401.15428, 2024
-
[19]
Re- thinkmcts: Monte carlo tree search for code generation.arXiv preprint arXiv:2310.13500, 2023
Aojun Zhou, Kai Yan, Micah Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Yu. Re- thinkmcts: Monte carlo tree search for code generation.arXiv preprint arXiv:2310.13500, 2023. 14
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.