Recognition: unknown
From Pixels to Tokens: A Systematic Study of Latent Action Supervision for Vision-Language-Action Models
Pith reviewed 2026-05-08 17:38 UTC · model grok-4.3
The pith
Image-based latent actions improve long-horizon reasoning and scene generalization in vision-language-action models, while action-based latent actions enhance complex motor coordination, with direct discrete token supervision performing the
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
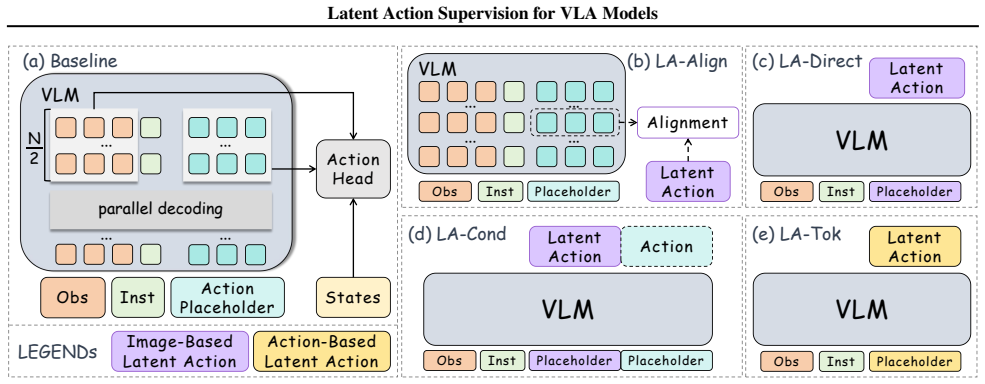
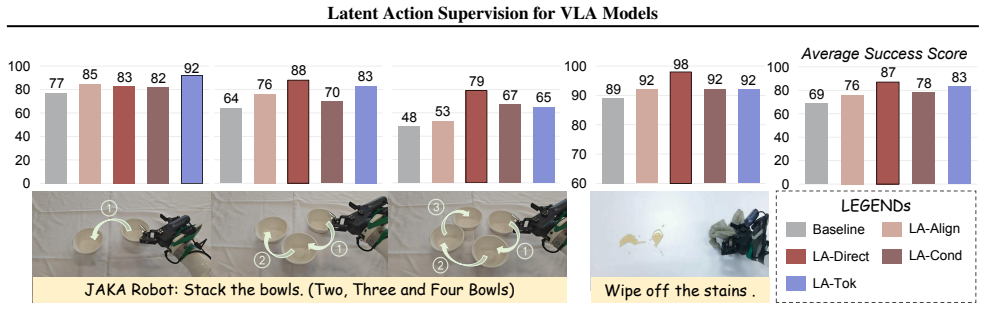
Under one unified VLA baseline, four representative strategies are tested. Image-based latent actions regularize trajectories and improve results on long-horizon reasoning and scene-level generalization. Action-based latent actions unify the target space and perform better on complex motor coordination. Directly supervising the VLM with discrete latent action tokens produces the most effective performance overall. Experiments also give early evidence that latent action supervision helps when training on mixed heterogeneous datasets.
What carries the argument
The two perspectives of latent action supervision: regularizing trajectories through image-based latent actions versus unifying target spaces through action-based latent actions, tested via four integration strategies under a shared VLA baseline.
If this is right
- Image-based latent actions support extended planning and adaptation to new environments in VLA models.
- Action-based latent actions improve accuracy on tasks that require intricate physical movements.
- Direct use of discrete latent action tokens for supervision outperforms other ways of incorporating the same information.
- Latent action methods enable more effective training when combining data from multiple robot sources.
Where Pith is reading between the lines
- The observed correspondence could inform hybrid supervision schemes that select or blend the two latent action types based on the mix of tasks in a dataset.
- Repeating the discrete-token experiments at larger model scales would test whether the performance edge holds beyond the current baselines.
- The mixed-data gains suggest latent actions could reduce the need for manual dataset alignment when scaling VLA training.
Load-bearing premise
The unified VLA baseline and four integration strategies represent the broader space of latent action methods, and observed performance gaps are not caused by unexamined implementation choices.
What would settle it
A new set of experiments on a different VLA architecture or with additional integration strategies in which image-based latent actions no longer show advantages on long-horizon tasks or action-based latent actions no longer show advantages on motor coordination tasks.
Figures








read the original abstract
Latent actions serve as an intermediate representation that enables consistent modeling of vision-language-action (VLA) models across heterogeneous datasets. However, approaches to supervising VLAs with latent actions are fragmented and lack a systematic comparison. This work structures the study of latent action supervision from two perspectives: (i) regularizing the trajectory via image-based latent actions, and (ii) unifying the target space with action-based latent actions. Under a unified VLA baseline, we instantiate and compare four representative integration strategies. Our results reveal a formulation-task correspondence: image-based latent actions benefit long-horizon reasoning and scene-level generalization, whereas action-based latent actions excel at complex motor coordination. Furthermore, we find that directly supervising the VLM with discrete latent action tokens yields the most effective performance. Finally, our experiments offer initial insights into the benefits of latent action supervision in mixed-data, suggesting a promising direction for VLA training. Code is available at https://github.com/RUCKBReasoning/From_Pixels_to_Tokens.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a systematic empirical comparison of latent action supervision strategies for Vision-Language-Action (VLA) models. It organizes approaches into two categories—image-based latent actions that regularize trajectories and action-based latent actions that unify the target space—and evaluates four representative integration strategies under a single unified VLA baseline. The central claims are a formulation-task correspondence (image-based supervision benefits long-horizon reasoning and scene-level generalization while action-based supervision excels at complex motor coordination) together with the superiority of directly supervising the VLM using discrete latent action tokens. Additional experiments explore benefits in mixed-data regimes.
Significance. If the reported patterns hold under rigorous controls, the work supplies actionable guidance for choosing latent-action formulations according to task characteristics and demonstrates that direct discrete-token supervision is particularly effective. The public code release is a clear strength that supports reproducibility and follow-on research on heterogeneous VLA datasets.
major comments (2)
- [§4] §4 (Experimental Setup) and Table 2: the four integration strategies are presented as representative, yet the manuscript does not include an explicit argument or ablation showing that they adequately cover the design space of possible latent-action supervision methods; performance differences could therefore be driven by unexamined implementation choices rather than the claimed formulation-task correspondence.
- [§5] §5 (Results) and Figure 3: the reported superiority of discrete-token supervision and the task-specific benefits are stated without accompanying statistical significance tests or confidence intervals on the performance deltas; this weakens the load-bearing claim that one formulation is “most effective.”
minor comments (2)
- [§3.2] The abstract and §3.2 use the term “unified VLA baseline” without a concise definition or pointer to the exact architectural modifications; a one-sentence clarification would improve readability.
- [Table 1] Table 1 caption and §4.1: dataset splits and preprocessing steps for the mixed-data experiments are described only at high level; adding the precise train/validation/test ratios would aid replication.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for minor revision. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup) and Table 2: the four integration strategies are presented as representative, yet the manuscript does not include an explicit argument or ablation showing that they adequately cover the design space of possible latent-action supervision methods; performance differences could therefore be driven by unexamined implementation choices rather than the claimed formulation-task correspondence.
Authors: We selected the four strategies to instantiate the two primary categories outlined in the paper (image-based trajectory regularization and action-based target unification) while varying the integration mechanism (e.g., reconstruction loss, prediction loss, and direct token supervision). These choices were intended to span the key axes of supervision type and VLM integration. We acknowledge that the manuscript does not contain an explicit subsection justifying coverage of the full design space. In the revision we will add a short discussion in §4 explaining the rationale for these representatives and noting that exhaustive enumeration of all possible variants lies outside the scope of the study; the observed formulation-task correspondence holds consistently across the evaluated tasks and environments. revision: partial
-
Referee: [§5] §5 (Results) and Figure 3: the reported superiority of discrete-token supervision and the task-specific benefits are stated without accompanying statistical significance tests or confidence intervals on the performance deltas; this weakens the load-bearing claim that one formulation is “most effective.”
Authors: We agree that quantitative assessment of variability would strengthen the claims. In the revised manuscript we will add confidence intervals (or standard deviations across seeds where multiple runs were performed) to the relevant tables and figures. We will also report the results of paired statistical tests on the performance differences for the key comparisons, while noting that some large-scale runs were conducted with a single seed due to compute limits. The trends remain consistent across the suite of tasks, but we will make the statistical support explicit. revision: yes
Circularity Check
No significant circularity in empirical comparison
full rationale
The paper is a controlled empirical study comparing four integration strategies for latent action supervision under a single unified VLA baseline. No mathematical derivations, equations, or parameter-fitting steps are present in the abstract or described structure. Claims about formulation-task correspondence and discrete-token superiority arise directly from reported experimental outcomes rather than from any self-referential definitions, fitted inputs renamed as predictions, or load-bearing self-citations. The work is self-contained against external benchmarks and does not reduce any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Emergence of Human to Robot Transfer in Vision-Language-Action Models , author=. arXiv preprint arXiv:2512.22414 , year=
-
[2]
OpenVLA: An Open-Source Vision-Language-Action Model
Openvla: An open-source vision-language-action model , author=. arXiv preprint arXiv:2406.09246 , year=
work page internal anchor Pith review arXiv
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
0: A vision-language-action flow model for general robot control. CoRR, abs/2410.24164, 2024. doi: 10.48550 , author=
work page internal anchor Pith review arXiv 2024
-
[4]
Zhou, Austin , year=. RT-2: Vision-Language-Action Models for Generalizable Robotic Control: A Comprehensive Review , volume=. Advances in Engineering Technology Research , publisher=. doi:10.56028/aetr.15.1.1423.2025 , number=
-
[5]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
0. 5: a vision-language-action model with open-world generalization, 2025 , author=. URL https://arxiv. org/abs/2504.16054 , volume=
work page internal anchor Pith review arXiv 2025
-
[6]
RT-1: Robotics Transformer for Real-World Control at Scale
Rt-1: Robotics transformer for real-world control at scale , author=. arXiv preprint arXiv:2212.06817 , year=
work page internal anchor Pith review arXiv
-
[7]
Conference on Robot Learning , pages=
Rt-2: Vision-language-action models transfer web knowledge to robotic control , author=. Conference on Robot Learning , pages=. 2023 , organization=
2023
-
[8]
Latent Action Pretraining from Videos
Latent action pretraining from videos , author=. arXiv preprint arXiv:2410.11758 , year=
-
[9]
Align-then-steer: Adapting the vision-language action models through unified latent guidance , author=. arXiv preprint arXiv:2509.02055 , year=
-
[10]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Univla: Learning to act anywhere with task-centric latent actions , author=. arXiv preprint arXiv:2505.06111 , year=
work page internal anchor Pith review arXiv
-
[11]
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
Video prediction policy: A generalist robot policy with predictive visual representations , author=. arXiv preprint arXiv:2412.14803 , year=
work page internal anchor Pith review arXiv
-
[12]
Advances in Neural Information Processing Systems , volume=
Video pretraining (vpt): Learning to act by watching unlabeled online videos , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Thinkact: Vision-language-action reasoning via reinforced visual latent planning , author=. arXiv preprint arXiv:2507.16815 , year=
-
[14]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Moto: Latent motion token as the bridging language for learning robot manipulation from videos , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[15]
Villa-x: enhancing latent action modeling in vision-language-action models , author=. arXiv preprint arXiv:2507.23682 , year=
-
[16]
Advances in Neural Information Processing Systems , volume=
Libero: Benchmarking knowledge transfer for lifelong robot learning , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation , author=. arXiv preprint arXiv:2506.18088 , year=
work page internal anchor Pith review arXiv
-
[18]
Vla-adapter: An effective paradigm for tiny-scale vision-language-action model , author=. arXiv preprint arXiv:2509.09372 , year=
-
[19]
Advances in neural information processing systems , volume=
Neural discrete representation learning , author=. Advances in neural information processing systems , volume=
-
[20]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Fast: Efficient action tokenization for vision-language-action models , author=. arXiv preprint arXiv:2501.09747 , year=
work page internal anchor Pith review arXiv
-
[21]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Gr00t n1: An open foundation model for generalist humanoid robots , author=. arXiv preprint arXiv:2503.14734 , year=
work page internal anchor Pith review arXiv
-
[22]
Universal manipula- tion interface: In-the-wild robot teaching without in-the- wild robots,
Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots , author=. arXiv preprint arXiv:2402.10329 , year=
-
[23]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Ego4d: Around the world in 3,000 hours of egocentric video , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[24]
Learning to act without actions.arXiv preprint arXiv:2312.10812, 2023
Learning to act without actions , author=. arXiv preprint arXiv:2312.10812 , year=
-
[25]
Behavior generation with latent actions.arXiv preprint arXiv:2403.03181, 2024
Behavior generation with latent actions , author=. arXiv preprint arXiv:2403.03181 , year=
-
[26]
Motus: A Unified Latent Action World Model
Motus: A Unified Latent Action World Model , author=. arXiv preprint arXiv:2512.13030 , year=
work page internal anchor Pith review arXiv
-
[27]
Forty-first International Conference on Machine Learning , year=
Genie: Generative interactive environments , author=. Forty-first International Conference on Machine Learning , year=
-
[28]
Latent action learning requires supervision in the presence of distractors , author=. arXiv preprint arXiv:2502.00379 , year=
-
[29]
LAOF: Robust Latent Action Learning with Optical Flow Constraints , author=. arXiv preprint arXiv:2511.16407 , year=
-
[30]
What do latent action models actually learn?arXiv preprint arXiv:2506.15691, 2025
What Do Latent Action Models Actually Learn? , author=. arXiv preprint arXiv:2506.15691 , year=
-
[31]
Advances in Neural Information Processing Systems , volume=
Quest: Self-supervised skill abstractions for learning continuous control , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[33]
Advances in Neural Information Processing Systems , volume=
Grounding multimodal large language models in actions , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Advances in Neural Information Processing Systems , volume=
Omnijarvis: Unified vision-language-action tokenization enables open-world instruction following agents , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
Igor: Image-goal representations are the atomic control units for foundation models in embodied ai , author=. arXiv preprint arXiv:2411.00785 , year=
-
[36]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Fine-tuning vision-language-action models: Optimizing speed and success , author=. arXiv preprint arXiv:2502.19645 , year=
work page internal anchor Pith review arXiv
-
[37]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Rdt-1b: a diffusion foundation model for bimanual manipulation , author=. arXiv preprint arXiv:2410.07864 , year=
work page internal anchor Pith review arXiv
-
[38]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Learning fine-grained bimanual manipulation with low-cost hardware , author=. arXiv preprint arXiv:2304.13705 , year=
work page internal anchor Pith review arXiv
-
[39]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations , author=. arXiv preprint arXiv:2403.03954 , year=
-
[40]
Spatial forcing: Implicit spatial representation alignment for vision-language-action model , author=. arXiv preprint arXiv:2510.12276 , year=
-
[41]
StarVLA: A Lego-like Codebase for Vision-Language-Action Model Developing , author =. 2025 , version =. doi:10.5281/zenodo.18264214 , howpublished =
-
[42]
ArXiv , year=
0.5: a Vision-Language-Action Model with Open-World Generalization , author=. ArXiv , year=
-
[43]
ArXiv , year=
0: A Vision-Language-Action Flow Model for General Robot Control , author=. ArXiv , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.