ULF-Loc: Unbiased Landmark Feature for Robust Visual Localization with 3D Gaussian Splatting
Pith reviewed 2026-05-08 17:22 UTC · model grok-4.3
The pith
Alpha-blending in 3D Gaussian Splatting creates biased features that cause mismatches in visual localization, which ULF-Loc corrects via geometry-weighted fusion and consensus sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
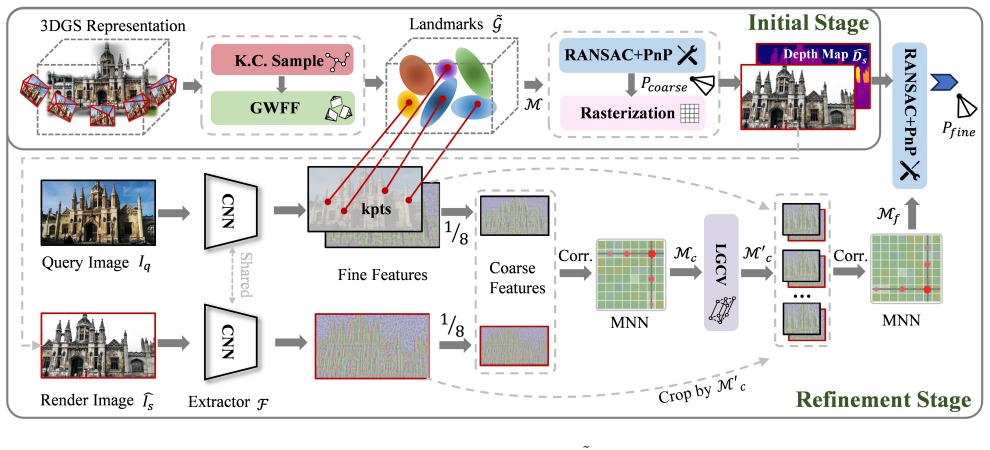
The central claim is that alpha-blending optimization in 3DGS inherently introduces bias into learned 3D point features through entanglement with neighboring Gaussians, rendering them unsuitable for precise matching. Replacing this process with geometry-weighted feature fusion produces unbiased landmark features, and supplementing it with keypoint-consensus sampling plus local geometric consistency verification yields robust visual localization.
What carries the argument
Geometry-weighted feature fusion, which decouples each Gaussian's feature from its neighbors by reweighting contributions according to geometric properties instead of alpha-blending weights.
If this is right
- On the Cambridge Landmarks dataset the approach reduces mean median translation error by 17 percent relative to prior state-of-the-art methods.
- Training requires only one-tenth the time and one-sixth the GPU memory of the previous leading method.
- The same pipeline supports reliable camera pose estimation for augmented reality and autonomous navigation tasks.
- Local geometric consistency verification removes mismatches that arise from rendering artifacts after fusion.
Where Pith is reading between the lines
- The same bias-correction principle may apply to feature learning inside other differentiable rendering pipelines beyond 3D Gaussian Splatting.
- Efficiency gains could enable on-device visual localization on hardware with limited compute and memory.
- Evaluating the method on datasets containing strong lighting changes or moving objects would test whether the unbiased features remain stable outside controlled landmark scenes.
Load-bearing premise
The assumption that alpha-blending entanglement is the dominant source of feature mismatches and that geometry-weighted fusion plus consensus sampling removes this bias without discarding useful information or introducing new artifacts.
What would settle it
If a controlled experiment learns Gaussian features without alpha-blending (for example by direct per-Gaussian supervision) and the proposed fusion method then shows no accuracy gain over simple matching, the claim that entanglement is the primary bias source would be falsified.
Figures





read the original abstract
Visual localization is a core technology for augmented reality and autonomous navigation. Recent methods combine the efficient rendering of 3D Gaussian Splatting (3DGS) with feature-based localization. These methods rely on direct matching between 2D query features and the 3D Gaussian feature field, but this often results in mismatches due to an inherent bias in the learned Gaussian feature. We theoretically analyze the feature learning process in 3DGS, revealing that the widely adopted $\alpha$-blending optimization inherently introduces bias into 3D point features. This bias stems from the entanglement between individual Gaussians and their neighboring Gaussians, making the learned features unsuitable for precise matching tasks. Motivated by these findings, we propose ULF-Loc, an unbiased landmark feature framework that replaces biased feature optimization with geometry-weighted feature fusion. We further introduce keypoint-consensus landmark sampling to select reliable Gaussians and local geometric consistency verification to reject mismatches caused by rendering artifacts. On the Cambridge Landmarks dataset, ULF-Loc reduces the mean median translation error by 17\% compared to the state-of-the-art, while achieving superior efficiency with only 1/10 the training time and 1/6 the GPU memory of STDLoc.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that α-blending optimization in 3D Gaussian Splatting inherently biases learned point features through entanglement with neighboring Gaussians, rendering them unsuitable for precise 2D-3D matching in visual localization. To correct this, ULF-Loc replaces direct feature optimization with geometry-weighted feature fusion, adds keypoint-consensus landmark sampling to select reliable Gaussians, and applies local geometric consistency verification to reject rendering artifacts. On the Cambridge Landmarks dataset the method reports a 17% reduction in mean median translation error versus prior state-of-the-art while using 1/10 the training time and 1/6 the GPU memory of STDLoc.
Significance. If the bias analysis is correct and the observed gains are shown to arise specifically from removal of α-blending entanglement rather than from the auxiliary sampling or verification stages, the work would supply a principled, efficient route to more reliable feature fields for 3DGS-based localization. The efficiency numbers, if reproducible, would also be practically valuable for AR and navigation pipelines that must train or update maps on modest hardware.
major comments (3)
- [§3] §3 (theoretical analysis): the claim that α-blending optimization is the dominant source of feature bias is asserted but the full derivation isolating the entanglement term from other optimization effects is not provided; without it the central premise that geometry-weighted fusion removes the primary mismatch cause cannot be verified.
- [§5] §5 / Table 1 (Cambridge Landmarks results): the 17% mean-median translation error reduction is reported without component-wise ablations (geometry-weighted fusion alone, consensus sampling alone, verification alone) or inlier-ratio measurements under controlled rendering; therefore it is impossible to attribute the gain to bias removal rather than to the sampling or verification modules.
- [§5] §5: no error bars, standard deviations, or statistical significance tests accompany the quantitative localization numbers, weakening confidence that the reported improvement is robust across random seeds or scene variations.
minor comments (1)
- [Abstract] Abstract: the phrase 'mean median translation error' is ambiguous; clarify whether it denotes the average of per-scene median errors or another aggregate.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for strengthening the theoretical grounding and empirical validation of our claims. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] §3 (theoretical analysis): the claim that α-blending optimization is the dominant source of feature bias is asserted but the full derivation isolating the entanglement term from other optimization effects is not provided; without it the central premise that geometry-weighted fusion removes the primary mismatch cause cannot be verified.
Authors: We agree that a more explicit isolation of the entanglement term would make the analysis more rigorous. Section 3 derives the bias from the α-blending formulation and shows how neighboring Gaussians affect the optimized features, but we will expand this section in the revision to include the complete step-by-step derivation that separates the entanglement contribution from other optimization dynamics. This will directly support the premise that geometry-weighted fusion targets the dominant bias source. revision: yes
-
Referee: [§5] §5 / Table 1 (Cambridge Landmarks results): the 17% mean-median translation error reduction is reported without component-wise ablations (geometry-weighted fusion alone, consensus sampling alone, verification alone) or inlier-ratio measurements under controlled rendering; therefore it is impossible to attribute the gain to bias removal rather than to the sampling or verification modules.
Authors: We recognize that component-wise ablations are necessary to attribute gains specifically to bias removal. The current results emphasize the full pipeline, but we will add these ablations in the revised manuscript, reporting performance for geometry-weighted fusion alone, consensus sampling alone, and verification alone, along with inlier-ratio measurements under controlled rendering to isolate the contribution of each module. revision: yes
-
Referee: [§5] §5: no error bars, standard deviations, or statistical significance tests accompany the quantitative localization numbers, weakening confidence that the reported improvement is robust across random seeds or scene variations.
Authors: We concur that variability measures would increase confidence in the results. In the revised version we will augment Table 1 and the §5 results with error bars, standard deviations computed over multiple random seeds, and statistical significance tests to demonstrate that the reported improvements hold robustly across seeds and scene variations. revision: yes
Circularity Check
No circularity: theoretical analysis and design choices remain independent of fitted outputs
full rationale
The paper's chain begins with a claimed theoretical analysis of α-blending bias in 3DGS feature learning, followed by independent proposals for geometry-weighted fusion, consensus sampling, and consistency verification. None of these steps reduce by construction to the input data or to quantities fitted from the same data; the methods are presented as motivated design choices rather than reparameterizations of the bias term. No self-citation load-bearing, self-definitional loops, or fitted-input-renamed-as-prediction patterns appear in the provided text. The 17% error reduction is reported as an empirical outcome of the full pipeline, not forced by the analysis itself. This is the common honest case of a self-contained proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Map-free visual relocalization: Metric pose relative to a single image
Eduardo Arnold, Jamie Wynn, Sara Vicente, Guillermo Garcia-Hernando, Aron Monszpart, Victor Prisacariu, Dani- yar Turmukhambetov, and Eric Brachmann. Map-free visual relocalization: Metric pose relative to a single image. In European Conference on Computer Vision, pages 690–708. Springer, 2022. 2
work page 2022
-
[2]
Gsloc: Visual localization with 3d gaussian splatting
Kazii Botashev, Vladislav Pyatov, Gonzalo Ferrer, and Sta- matios Lefkimmiatis. Gsloc: Visual localization with 3d gaussian splatting. In2024 IEEE/RSJ International Confer- ence on Intelligent Robots and Systems (IROS), pages 5664–
-
[3]
Eric Brachmann and Carsten Rother. Visual camera re- localization from rgb and rgb-d images using dsac.IEEE transactions on pattern analysis and machine intelligence, 44(9):5847–5865, 2021. 2, 6, 7, 12
work page 2021
-
[4]
On the limits of pseudo ground truth in vi- sual camera re-localisation
Eric Brachmann, Martin Humenberger, Carsten Rother, and Torsten Sattler. On the limits of pseudo ground truth in vi- sual camera re-localisation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6218– 6228, 2021. 6
work page 2021
-
[5]
Accelerated coordinate encoding: Learning to relocalize in minutes using rgb and poses
Eric Brachmann, Tommaso Cavallari, and Victor Adrian Prisacariu. Accelerated coordinate encoding: Learning to relocalize in minutes using rgb and poses. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5044–5053, 2023. 1, 2, 6, 7, 12
work page 2023
-
[6]
Leonard Bruns, Axel Barroso-Laguna, Tommaso Cavallari, Sowmya Munukutla, Victor Adrian Prisacariu, Eric Brach- mann, et al. Ace-g: Improving generalization of scene coor- dinate regression through query pre-training.arXiv preprint arXiv:2510.11605, 2025. 2
-
[7]
Quantifying and alleviating co-adaptation in sparse-view 3d gaussian splatting,
Kangjie Chen, Yingji Zhong, Zhihao Li, Jiaqi Lin, Youyu Chen, Minghan Qin, and Haoqian Wang. Quantifying and alleviating co-adaptation in sparse-view 3d gaussian splat- ting.arXiv preprint arXiv:2508.12720, 2025. 5
-
[8]
Leveraging neural radiance fields for uncertainty-aware vi- sual localization
Le Chen, Weirong Chen, Rui Wang, and Marc Pollefeys. Leveraging neural radiance fields for uncertainty-aware vi- sual localization. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6298–6305. IEEE,
-
[9]
Dfnet: Enhance absolute pose regression with direct feature matching
Shuai Chen, Xinghui Li, Zirui Wang, and Victor A Prisacariu. Dfnet: Enhance absolute pose regression with direct feature matching. InEuropean Conference on Com- puter Vision, pages 1–17. Springer, 2022. 2, 6, 7
work page 2022
-
[10]
Neural refine- ment for absolute pose regression with feature synthesis
Shuai Chen, Yash Bhalgat, Xinghui Li, Jia-Wang Bian, Kejie Li, Zirui Wang, and Victor Adrian Prisacariu. Neural refine- ment for absolute pose regression with feature synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 20987–20996, 2024. 1, 2, 6, 7
work page 2024
-
[11]
Map-relative pose regression for visual re-localization
Shuai Chen, Tommaso Cavallari, Victor Adrian Prisacariu, and Eric Brachmann. Map-relative pose regression for visual re-localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20665– 20674, 2024. 1, 2, 6, 7, 12
work page 2024
-
[12]
Masked-attention mask transformer for universal image segmentation
Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexan- der Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1290–1299, 2022. 11
work page 2022
-
[13]
Superpoint: Self-supervised interest point detection and description
Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabi- novich. Superpoint: Self-supervised interest point detection and description. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 224–236, 2018. 2, 6, 8
work page 2018
-
[14]
Yaqing Ding, Jian Yang, Viktor Larsson, Carl Olsson, and Kalle ˚Astr¨om. Revisiting the p3p problem. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4872–4880, 2023. 1, 6
work page 2023
-
[15]
Siyan Dong, Shuzhe Wang, Shaohui Liu, Lulu Cai, Qingnan Fan, Juho Kannala, and Yanchao Yang. Reloc3r: Large-scale training of relative camera pose regression for generalizable, fast, and accurate visual localization. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16739–16752, 2025. 1
work page 2025
-
[16]
D2- net: A trainable cnn for joint description and detection of local features
Mihai Dusmanu, Ignacio Rocco, Tomas Pajdla, Marc Polle- feys, Josef Sivic, Akihiko Torii, and Torsten Sattler. D2- net: A trainable cnn for joint description and detection of local features. InProceedings of the ieee/cvf conference on computer vision and pattern recognition, pages 8092–8101,
-
[17]
Martin A Fischler and Robert C Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 24(6):381–395, 1981. 1, 2, 5, 6
work page 1981
-
[18]
Zhiwei Huang, Hailin Yu, Yichun Shentu, Jin Yuan, and Guofeng Zhang. From sparse to dense: Camera relocaliza- tion with scene-specific detector from feature gaussian splat- ting. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 27059–27069, 2025. 1, 2, 3, 5, 6, 7, 11, 12
work page 2025
-
[19]
Robust image matching via local graph structure consensus
Xingyu Jiang, Yifan Xia, Xiao-Ping Zhang, and Jiayi Ma. Robust image matching via local graph structure consensus. Pattern Recognition, 126:108588, 2022. 5
work page 2022
-
[20]
Posenet: A convolutional network for real-time 6-dof cam- era relocalization
Alex Kendall, Matthew Grimes, and Roberto Cipolla. Posenet: A convolutional network for real-time 6-dof cam- era relocalization. InProceedings of the IEEE international conference on computer vision, pages 2938–2946, 2015. 1, 2, 6
work page 2015
-
[21]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1,
-
[22]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 4015–4026, 2023. 3
work page 2023
-
[23]
PoseLib - Minimal Solvers for Camera Pose Estimation, 2020
Viktor Larsson and contributors. PoseLib - Minimal Solvers for Camera Pose Estimation, 2020. 6
work page 2020
-
[24]
Vincent Lepetit, Francesc Moreno-Noguer, and Pascal Fua. Epnp: An accurate o(n) solution to the pnp problem.Inter- national journal of computer vision, 81(2):155–166, 2009. 1, 5, 6 16
work page 2009
-
[25]
Ground- ing image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and J´erˆome Revaud. Ground- ing image matching in 3d with mast3r. InEuropean Confer- ence on Computer Vision, pages 71–91. Springer, 2024. 2
work page 2024
-
[26]
Hierarchical scene coordinate classification and regression for visual localization
Xiaotian Li, Shuzhe Wang, Yi Zhao, Jakob Verbeek, and Juho Kannala. Hierarchical scene coordinate classification and regression for visual localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11983–11992, 2020. 2, 7, 12
work page 2020
-
[27]
Learning neural volumetric pose features for camera localization
Jingyu Lin, Jiaqi Gu, Bojian Wu, Lubin Fan, Renjie Chen, Ligang Liu, and Jieping Ye. Learning neural volumetric pose features for camera localization. InEuropean Conference on Computer Vision, pages 198–214. Springer, 2024. 2, 6, 7
work page 2024
-
[28]
Changkun Liu, Shuai Chen, Yukun Zhao, Huajian Huang, Victor Prisacariu, and Tristan Braud. Hr-apr: Apr-agnostic framework with uncertainty estimation and hierarchical re- finement for camera relocalisation. In2024 IEEE Inter- national Conference on Robotics and Automation (ICRA), pages 8544–8550. IEEE, 2024. 6, 7
work page 2024
-
[29]
GS-CPR: Efficient camera pose refinement via 3d gaussian splatting
Changkun Liu, Shuai Chen, Yash Sanjay Bhalgat, Siyan HU, Ming Cheng, Zirui Wang, Victor Adrian Prisacariu, and Tris- tan Braud. GS-CPR: Efficient camera pose refinement via 3d gaussian splatting. InThe Thirteenth International Confer- ence on Learning Representations, 2025. 2, 6, 7, 11, 12
work page 2025
-
[30]
Robust incremental structure-from-motion with hybrid fea- tures
Shaohui Liu, Yidan Gao, Tianyi Zhang, R ´emi Pautrat, Jo- hannes L Sch ¨onberger, Viktor Larsson, and Marc Pollefeys. Robust incremental structure-from-motion with hybrid fea- tures. InEuropean Conference on Computer Vision, pages 249–269. Springer, 2024. 1, 2
work page 2024
-
[31]
David G Lowe. Distinctive image features from scale- invariant keypoints.International journal of computer vi- sion, 60(2):91–110, 2004. 2
work page 2004
-
[32]
6dgs: 6d pose estimation from a single image and a 3d gaussian splatting model
Bortolon Matteo, Theodore Tsesmelis, Stuart James, Fabio Poiesi, and Alessio Del Bue. 6dgs: 6d pose estimation from a single image and a 3d gaussian splatting model. InEuropean Conference on Computer Vision, pages 420–436. Springer,
-
[33]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021. 1, 2
work page 2021
-
[34]
Lens: Localization enhanced by nerf synthesis
Arthur Moreau, Nathan Piasco, Dzmitry Tsishkou, Bogdan Stanciulescu, and Arnaud de La Fortelle. Lens: Localization enhanced by nerf synthesis. InConference on Robot Learn- ing, pages 1347–1356. PMLR, 2022. 2, 7
work page 2022
-
[35]
Crossfire: Camera relocalization on self-supervised features from an implicit representation
Arthur Moreau, Nathan Piasco, Moussab Bennehar, Dzmitry Tsishkou, Bogdan Stanciulescu, and Arnaud de La Fortelle. Crossfire: Camera relocalization on self-supervised features from an implicit representation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 252–262, 2023. 2, 7
work page 2023
-
[36]
Reassessing the limitations of cnn methods for camera pose regression
Tony Ng, Adrian Lopez-Rodriguez, Vassileios Balntas, and Krystian Mikolajczyk. Reassessing the limitations of cnn methods for camera pose regression. InInternational Con- ference on 3D Vision, 2021. 7, 12
work page 2021
-
[37]
Meshloc: Mesh-based visual localization
V ojtech Panek, Zuzana Kukelova, and Torsten Sattler. Meshloc: Mesh-based visual localization. InEuropean Con- ference on Computer Vision, pages 589–609. Springer, 2022. 2
work page 2022
-
[38]
Gaussian splatting feature fields for (privacy-preserving) vi- sual localization
Maxime Pietrantoni, Gabriela Csurka, and Torsten Sattler. Gaussian splatting feature fields for (privacy-preserving) vi- sual localization. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1082–1092, 2025. 6, 7, 12
work page 2025
-
[39]
Synthetic view generation for absolute pose regression and image syn- thesis
Pulak Purkait, Cheng Zhao, and Christopher Zach. Synthetic view generation for absolute pose regression and image syn- thesis. InBMVC, page 69, 2018. 2
work page 2018
-
[40]
Langsplat: 3d language gaussian splatting
Minghan Qin, Wanhua Li, Jiawei Zhou, Haoqian Wang, and Hanspeter Pfister. Langsplat: 3d language gaussian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20051–20060, 2024. 2
work page 2024
-
[41]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 3
work page 2021
-
[42]
Jerome Revaud, Cesar De Souza, Martin Humenberger, and Philippe Weinzaepfel. R2d2: Reliable and repeatable detec- tor and descriptor.Advances in neural information process- ing systems, 32, 2019. 2
work page 2019
-
[43]
From coarse to fine: Robust hierarchical localization at large scale
Paul-Edouard Sarlin, Cesar Cadena, Roland Siegwart, and Marcin Dymczyk. From coarse to fine: Robust hierarchical localization at large scale. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12716–12725, 2019. 1, 2, 6, 7, 12
work page 2019
-
[44]
Superglue: Learning feature matching with graph neural networks
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature matching with graph neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4938–4947, 2020. 2
work page 2020
-
[45]
Back to the feature: Learning robust camera localization from pixels to pose
Paul-Edouard Sarlin, Ajaykumar Unagar, Mans Larsson, Hugo Germain, Carl Toft, Viktor Larsson, Marc Pollefeys, Vincent Lepetit, Lars Hammarstrand, Fredrik Kahl, et al. Back to the feature: Learning robust camera localization from pixels to pose. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 3247–3257, 2021. 1, 2, 7
work page 2021
-
[46]
Fast image- based localization using direct 2d-to-3d matching
Torsten Sattler, Bastian Leibe, and Leif Kobbelt. Fast image- based localization using direct 2d-to-3d matching. In2011 International Conference on Computer Vision, pages 667–
-
[47]
Improving image-based localization by active correspondence search
Torsten Sattler, Bastian Leibe, and Leif Kobbelt. Improving image-based localization by active correspondence search. InEuropean conference on computer vision, pages 752–765. Springer, 2012. 6, 7
work page 2012
-
[48]
Structure- from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure- from-motion revisited. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 4104–4113, 2016. 1
work page 2016
-
[49]
Camera pose auto-encoders for improving pose regression
Yoli Shavit and Yosi Keller. Camera pose auto-encoders for improving pose regression. InEuropean Conference on Computer Vision, pages 140–157. Springer, 2022. 1, 2 17
work page 2022
-
[50]
Learning multi- scene absolute pose regression with transformers
Yoli Shavit, Ron Ferens, and Yosi Keller. Learning multi- scene absolute pose regression with transformers. InPro- ceedings of the IEEE/CVF International Conference on Computer Vision, pages 2733–2742, 2021. 2
work page 2021
-
[51]
Language embedded 3d gaussians for open- vocabulary scene understanding
Jin-Chuan Shi, Miao Wang, Hao-Bin Duan, and Shao- Hua Guan. Language embedded 3d gaussians for open- vocabulary scene understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5333–5343, 2024. 2
work page 2024
-
[52]
Scene co- ordinate regression forests for camera relocalization in rgb-d images
Jamie Shotton, Ben Glocker, Christopher Zach, Shahram Izadi, Antonio Criminisi, and Andrew Fitzgibbon. Scene co- ordinate regression forests for camera relocalization in rgb-d images. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2930–2937, 2013. 6
work page 2013
-
[53]
Gennady Sidorov, Malik Mohrat, Denis Gridusov, Ruslan Rakhimov, and Sergey Kolyubin. Gsplatloc: Grounding key- point descriptors into 3d gaussian splatting for improved vi- sual localization.arXiv preprint arXiv:2409.16502, 2024. 1, 2, 3, 6, 7, 12
-
[54]
Loftr: Detector-free local feature matching with transformers
Jiaming Sun, Zehong Shen, Yuang Wang, Hujun Bao, and Xiaowei Zhou. Loftr: Detector-free local feature matching with transformers. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 8922–8931, 2021. 2, 5
work page 2021
-
[55]
Yuan Sun, Xuan Wang, Yunfan Zhang, Jie Zhang, Caigui Jiang, Yu Guo, and Fei Wang. icomma: Inverting 3d gaus- sian splatting for camera pose estimation via comparing and matching.arXiv preprint arXiv:2312.09031, 2023. 2
-
[56]
Neumap: Neural coordinate map- ping by auto-transdecoder for camera localization
Shitao Tang, Sicong Tang, Andrea Tagliasacchi, Ping Tan, and Yasutaka Furukawa. Neumap: Neural coordinate map- ping by auto-transdecoder for camera localization. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 929–939, 2023. 1, 2, 6, 7
work page 2023
-
[57]
24/7 place recognition by view synthesis
Akihiko Torii, Relja Arandjelovic, Josef Sivic, Masatoshi Okutomi, and Tomas Pajdla. 24/7 place recognition by view synthesis. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1808–1817,
-
[58]
The unreasonable effectiveness of pre- trained features for camera pose refinement
Gabriele Trivigno, Carlo Masone, Barbara Caputo, and Torsten Sattler. The unreasonable effectiveness of pre- trained features for camera pose refinement. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 12786–12798, 2024. 6, 7
work page 2024
-
[59]
Learn- ing to navigate the energy landscape
Julien Valentin, Angela Dai, Matthias Nießner, Pushmeet Kohli, Philip Torr, Shahram Izadi, and Cem Keskin. Learn- ing to navigate the energy landscape. In2016 Fourth In- ternational Conference on 3D Vision (3DV), pages 323–332. IEEE, 2016. 6
work page 2016
-
[60]
Glace: Global local accelerated coordinate encoding
Fangjinhua Wang, Xudong Jiang, Silvano Galliani, Christoph V ogel, and Marc Pollefeys. Glace: Global local accelerated coordinate encoding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21562–21571, 2024. 1, 2, 6, 7, 12
work page 2024
-
[61]
Dgc-gnn: Leveraging geometry and color cues for visual descriptor- free 2d-3d matching
Shuzhe Wang, Juho Kannala, and Daniel Barath. Dgc-gnn: Leveraging geometry and color cues for visual descriptor- free 2d-3d matching. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 20881–20891, 2024. 1, 2
work page 2024
-
[62]
Freesplat++: Generalizable 3d gaussian splatting for efficient indoor scene reconstruction, 2025
Yunsong Wang, Tianxin Huang, Hanlin Chen, and Gim Hee Lee. Freesplat++: Generalizable 3d gaussian splatting for efficient indoor scene reconstruction.arXiv preprint arXiv:2503.22986, 2025. 13
-
[63]
Ml-semreg: Boosting point cloud registration with multi-level semantic consistency
Shaocheng Yan, Pengcheng Shi, and Jiayuan Li. Ml-semreg: Boosting point cloud registration with multi-level semantic consistency. InEuropean Conference on Computer Vision, pages 19–37. Springer, 2024. 5
work page 2024
-
[64]
Turboreg: Turboclique for robust and efficient point cloud registration,
Shaocheng Yan, Pengcheng Shi, Zhenjun Zhao, Kaixin Wang, Kuang Cao, Ji Wu, and Jiayuan Li. Turboreg: Turbo- clique for robust and efficient point cloud registration.arXiv preprint arXiv:2507.01439, 2025. 5
-
[65]
Hemora: Unsupervised heuristic consensus sampling for ro- bust point cloud registration
Shaocheng Yan, Yiming Wang, Kaiyan Zhao, Pengcheng Shi, Zhenjun Zhao, Yongjun Zhang, and Jiayuan Li. Hemora: Unsupervised heuristic consensus sampling for ro- bust point cloud registration. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1363– 1373, 2025. 4
work page 2025
-
[66]
inerf: Inverting neural radiance fields for pose estimation
Lin Yen-Chen, Pete Florence, Jonathan T Barron, Alberto Rodriguez, Phillip Isola, and Tsung-Yi Lin. inerf: Inverting neural radiance fields for pose estimation. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1323–1330. IEEE, 2021. 1, 2
work page 2021
-
[67]
Hongjia Zhai, Xiyu Zhang, Boming Zhao, Hai Li, Yijia He, Zhaopeng Cui, Hujun Bao, and Guofeng Zhang. Splatloc: 3d gaussian splatting-based visual localization for augmented reality.IEEE Transactions on Visualization and Computer Graphics, 2025. 2, 3, 7, 12
work page 2025
-
[68]
Pnerfloc: Visual localization with point- based neural radiance fields
Boming Zhao, Luwei Yang, Mao Mao, Hujun Bao, and Zhaopeng Cui. Pnerfloc: Visual localization with point- based neural radiance fields. InProceedings of the AAAI Conference on Artificial Intelligence, pages 7450–7459,
-
[69]
The nerfect match: Exploring nerf features for visual localization
Qunjie Zhou, Maxim Maximov, Or Litany, and Laura Leal- Taix´e. The nerfect match: Exploring nerf features for visual localization. InEuropean Conference on Computer Vision, pages 108–127. Springer, 2024. 2, 6, 7, 12
work page 2024
-
[70]
Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields
Shijie Zhou, Haoran Chang, Sicheng Jiang, Zhiwen Fan, Ze- hao Zhu, Dejia Xu, Pradyumna Chari, Suya You, Zhangyang Wang, and Achuta Kadambi. Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21676–21685, 2024. 2, 4, 8, 9 18
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.