Recognition: unknown
Reward-Decomposed Reinforcement Learning for Immersive Video Role-Playing
Pith reviewed 2026-05-08 17:35 UTC · model grok-4.3
The pith
EBM-RL decomposes rewards to ground video role-playing in visual scenes and character traits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
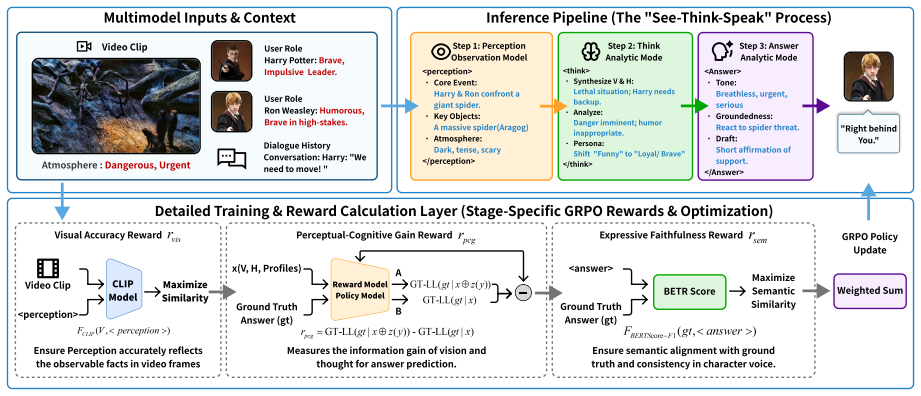
EBM-RL is a decoupled GRPO-based framework that separates observation in perception, reasoning in think, and utterance in answer. It uses four rewards including CLIP scene-text alignment for ambiance, perceptual-cognitive to increase likelihood of reference responses, answer accuracy for faithfulness, and dense format for structured output. This leads to better visual-atmosphere consistency and character authenticity compared to baselines.
What carries the argument
The decoupled structure of perception, think, and answer stages combined with the four complementary reward signals in the EBM-RL framework.
If this is right
- Outperforms text-only role-playing baselines and larger vision-language models on the immersive role-playing benchmark.
- Delivers simultaneous gains in visual-atmosphere consistency and character authenticity.
- Shows strong zero-shot generalization to out-of-domain VideoQA benchmarks without additional fine-tuning.
- Comes with an open-source dataset release for video-grounded role-playing dialogue.
Where Pith is reading between the lines
- The stage separation could be applied to other dialogue systems to improve multimodal consistency.
- Reward decomposition might allow smaller models to achieve performance close to larger ones in grounded tasks.
- Future work could test if these rewards transfer to real-time VR applications or different video domains.
Load-bearing premise
The assumption that the four specific rewards together encourage human-like sensory grounding and immersive responses without causing biases or overfitting to the benchmark data.
What would settle it
Testing EBM-RL on a newly collected immersive role-playing video dataset with unseen characters and scenes, where it does not show improvements over baselines, would falsify the performance claims.
Figures


read the original abstract
Text-based role-playing models can imitate character styles, yet they often fail to reflect a scene's atmosphere and evolving tension, both essential for immersive applications such as Virtual Reality (VR) games and interactive narratives. We study video-grounded role-playing dialogue and introduce EBM-RL (Eye-Brain-Mouth Reinforcement Learning), a decoupled GRPO-based framework that explicitly separates observation ([perception]), reasoning ([think]), and utterance ([answer]). This structure promotes human-like sensory grounding by compelling the model to first attend to visual cues, then form internal interpretations, and finally generate context-appropriate dialogue. EBM-RL integrates four complementary rewards: (i) CLIP-based scene-text alignment to improve ambiance and emotion; (ii) a Perceptual-Cognitive reward that encourages [perception] and [think] processes that increase the likelihood of the reference response; (iii) answer accuracy to ensure faithfulness; and (iv) a dense format reward to enforce the desired structured output. Extensive experiments demonstrate that EBM-RL substantially outperforms text-only role-playing baselines and larger-scale vision-language models on our immersive role-playing benchmark, delivering simultaneous gains in visual-atmosphere consistency and character authenticity. Beyond the role-playing domain, EBM-RL also exhibits strong zero-shot generalization: without any additional fine-tuning, it consistently improves performance on out-of-domain VideoQA benchmarks. We additionally release an open-source dataset for video-grounded role-playing dialogue.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EBM-RL, a decoupled GRPO-based reinforcement learning framework for video-grounded role-playing dialogue. It explicitly separates the process into [perception], [think], and [answer] stages and integrates four rewards: CLIP-based scene-text alignment, a perceptual-cognitive reward that boosts the likelihood of reference responses given perception and think outputs, answer accuracy, and a dense format reward. The central claims are substantial outperformance over text-only baselines and larger vision-language models on a custom immersive role-playing benchmark (with gains in visual-atmosphere consistency and character authenticity), plus zero-shot generalization to VideoQA tasks without further fine-tuning, accompanied by the release of an open-source dataset.
Significance. If the empirical results are robust, the decoupled structure and reward decomposition could provide a useful template for building more grounded multimodal agents in immersive applications such as VR narratives. The dataset release is a clear positive contribution that supports reproducibility and follow-on research.
major comments (1)
- The perceptual-cognitive reward is defined to encourage [perception] and [think] processes that increase the likelihood of the reference response (as stated in the abstract and method description). This directly ties the intermediate reasoning steps to benchmark-specific reference answers, creating a plausible pathway for the policy to optimize reference-matching patterns rather than emergent video-derived atmosphere or tension. Because this reward is load-bearing for the claims of human-like sensory grounding, simultaneous gains in visual-atmosphere consistency and character authenticity, and the zero-shot VideoQA transfer, the manuscript should include ablations that isolate its contribution and additional metrics that do not rely on reference likelihood to substantiate the central generalization claims.
minor comments (1)
- The abstract asserts 'substantial outperformance' and 'simultaneous gains' without naming the specific metrics, baselines, or statistical tests; adding these details would improve immediate readability while the full experimental section supplies the supporting evidence.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The concern about the perceptual-cognitive reward potentially encouraging reference-matching is a substantive point that merits additional analysis. We address it directly below and commit to revisions that strengthen the empirical grounding of our claims.
read point-by-point responses
-
Referee: The perceptual-cognitive reward is defined to encourage [perception] and [think] processes that increase the likelihood of the reference response (as stated in the abstract and method description). This directly ties the intermediate reasoning steps to benchmark-specific reference answers, creating a plausible pathway for the policy to optimize reference-matching patterns rather than emergent video-derived atmosphere or tension. Because this reward is load-bearing for the claims of human-like sensory grounding, simultaneous gains in visual-atmosphere consistency and character authenticity, and the zero-shot VideoQA transfer, the manuscript should include ablations that isolate its contribution and additional metrics that do not rely on reference likelihood to substantiate the central generalization claims.
Authors: We acknowledge that the perceptual-cognitive reward, by construction, increases the likelihood of reference responses given the [perception] and [think] outputs. This design choice could in principle allow the policy to exploit reference patterns rather than purely video-derived cues. However, the reward is applied only after the CLIP-based scene-text alignment reward has already enforced visual grounding in the perception stage, and it is further constrained by the separate answer accuracy reward that evaluates faithfulness to the input video. To isolate its effect, we will add an ablation in the revised manuscript that removes only the perceptual-cognitive reward while retaining the CLIP alignment, answer accuracy, and format rewards. We will report the resulting changes in visual-atmosphere consistency, character authenticity, and zero-shot VideoQA performance. In addition, we will introduce reference-independent metrics, including automated scene-description accuracy using an off-the-shelf vision model and targeted human ratings of visual grounding, to provide supporting evidence for the generalization claims. revision: yes
Circularity Check
No circularity: empirical method with externally defined rewards and benchmark evaluation.
full rationale
The paper introduces EBM-RL as a decoupled RL framework with four explicitly defined rewards (CLIP alignment, perceptual-cognitive using reference likelihood, accuracy, format) and evaluates it empirically on a new benchmark plus zero-shot transfer. No derivation chain, mathematical prediction, or first-principles result is claimed that reduces to its inputs by construction. Rewards rely on external components (CLIP, reference responses) rather than being fitted or renamed from the target metrics. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text to justify core choices. The outperformance claims rest on experimental results, not on any self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
let your characters tell their story
"let your characters tell their story": A dataset for character-centric narrative understanding. Preprint, arXiv:2109.05438. Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, and Xing Xie
-
[2]
A survey on evaluation of large language mod- els.Preprint, arXiv:2307.03109. Nuo Chen, Yan Wang, Yang Deng, and Jia Li. 2024. The oscars of AI theater: A survey on role-playing with language models.ArXiv, abs/2407.11484. Nuo Chen, Yan Wang, Yang Deng, and Jia Li. 2025a. The oscars of ai theater: A survey on role-playing with language models.Preprint, arX...
-
[3]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Large language models are superpositions of all characters: Attaining arbitrary role-play via self- alignment. InAnnual Meeting of the Association for Computational Linguistics. Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. 2024. Video-chatgpt: To- wards detailed video understanding via large vision and language models.Preprint, arX...
work page internal anchor Pith review arXiv 2024
-
[4]
Proximal Policy Optimization Algorithms
Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms.ArXiv, abs/1707.06347. Yunfan Shao, Linyang Li, Junqi Dai, and Xipeng Qiu
work page internal anchor Pith review arXiv 2017
-
[5]
Character-llm: A trainable agent for role-playing
Character-llm: A trainable agent for role- playing.Preprint, arXiv:2310.10158. 12 Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Jun- Mei Song, Mingchuan Zhang, Y . K. Li, Yu Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models. ArXiv, abs/2402.03300. Yunlong Tang, Jing Bi, Siting Xu, Luchuan Song, Su...
-
[6]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
CharacterEval: A Chinese benchmark for role- playing conversational agent evaluation. InAnnual Meeting of the Association for Computational Lin- guistics. Haibo Wang, Zhiyang Xu, Yu Cheng, Shizhe Diao, Yu- fan Zhou, Yixin Cao, Qifan Wang, Weifeng Ge, and Lifu Huang. 2025a. Grounded-VideoLLM: Sharpen- ing fine-grained temporal grounding in video large lang...
work page internal anchor Pith review arXiv 2021
-
[7]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
DAPO: An open-source LLM reinforcement learning system at scale.ArXiv, abs/2503.14476. Zhou Yu, D. Xu, Jun Yu, Ting Yu, Zhou Zhao, Yueting Zhuang, and Dacheng Tao. 2019. Activitynet-qa: A dataset for understanding complex web videos via question answering.ArXiv, abs/1906.02467. Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen...
work page internal anchor Pith review arXiv 2019
-
[8]
Character 1
NEVER use vague role labelssuch as “Character 1”, “the person on the left”, “the middle figure”, or “the third person”. These outputs are INV ALID. ### CHARACTER IDENTIFICATION RULES (ABSOLUTE REQUIREMENT) • If the scene contains one man and one woman: ALW AYS refer to them strictly as“the man”and“the woman”. • If multiple characters share the same gender...
-
[9]
A man wearing a gray jacket and a woman with long dark hair
[Visual Character Identification] • List each character with a unique, appearance-based identifier. • Example (GOOD): “A man wearing a gray jacket and a woman with long dark hair.”
-
[10]
The man stands very close in front of the woman, facing her directly
[Physical Proximity & Interaction Dynamics] • Describe distances and orientations based on VISUAL evidence only. • Example: “The man stands very close in front of the woman, facing her directly.”
-
[11]
He looks sad
[Facial Micro-expressions & Visible Emotions] • ForEACHcharacter, describe the specific facial muscle movements you SEE. •F orbidden: “He looks sad.” (Too abstract) •Required: “The man’s brows are tightly drawn and his jaw is tense.”
-
[12]
The woman folds her arms tightly against her chest
[Body Language] • Describe meaningful gestures: hand movements, posture changes, tension, hesitation. • Example: “The woman folds her arms tightly against her chest.”
-
[13]
THIRD PERSON
[Environment & Atmosphere] • Lighting, background, mood from camera framing. Constraint: Describe ONLY what is visible. No speech, no plot inference. If any spoken words or subtitles appear in your output, the task is failed. F.2 Dialogue Data Generation Prompt Prompt: LLM-Based Dialogue Data Augmentation You are an expert scriptwriter for an immersive Ro...
-
[14]
Personality
TIMELINE & CONSISTENCY: Respect characters’ current knowledge/emotions. Strictly adhere to the “Personality” and “Speech Style” defined in the Input Data
-
[15]
Visual Atmosphere
USE VISUAL CUES SILENTLY: Use the “Visual Atmosphere” to choose emotion/pacing, butMUST NOTquote or explicitly reference the description itself in the dialogue
-
[16]
camera”, “scene
NO META TALK: No “camera”, “scene”, or “script”. Write ONLY spoken dialogue. No stage directions (e.g., *sighs*). ### TASK STRATEGY (Choose ONE) •STRATEGY 1: The Seamless Interjection (Join the Flow): –{user_role} acts as physically present andcuts into continue the conversation. – Constraints: Strict continuity; address the context; no repetition. •STRAT...
2024
-
[17]
{target_utterance}
Drafting (Personality Filter): Internalize ASSISTANT-{assistant_name}’s mindset. Apply theTHE PERSONALITY ANALYSIS. Check: If Vision is dangerous, does character show bravery/nervousness instead of casual traits? </think> CRITICAL: Please stop generating immediately after </think>. Do NOT generate the <answer> part, as that part already exists. User Promp...
-
[18]
Object/Scene Integrity (30%): Does the response respect the physical limits of the scene? Penalize models mentioning invisible items
-
[19]
describing the video
Temporal Realism (20%): Does the utterance match the immediacy of visual perception? Real-time visual grounding is typically reactive and sharp. Penalize excessive length if it drifts into “describing the video” instead of “reacting to the video”. SCORING ANCHORS (5 Tiers): • 0-20 (Tier 1): Hallucinates elements not in video or provides AI refusal. • 21-4...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.