Recognition: unknown
Spatial-Magnifier: Spatial upsampling for multichannel speech enhancement
Pith reviewed 2026-05-08 15:57 UTC · model grok-4.3
The pith
A neural network generates virtual microphone signals from few real ones to nearly match full-array performance in speech enhancement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
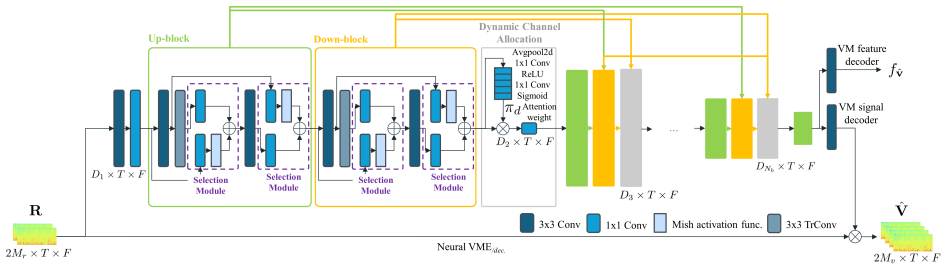
Spatial-Magnifier is a neural network designed to generate virtual microphone signals from limited real microphone measurements. The Spatial Audio Representation Learning framework then uses the estimated virtual signals and features to condition a downstream speech enhancement system, nearly recovering the oracle performance achieved with all microphones available.
What carries the argument
Spatial-Magnifier neural network that generates virtual microphone signals to provide additional spatial directivity information for enhancement algorithms.
Load-bearing premise
Neural-network-generated virtual microphone signals can faithfully supply the spatial directivity information needed by downstream enhancement systems as if the virtual mics were real physical sensors.
What would settle it
A side-by-side test in a real acoustic environment measuring whether speech enhancement quality with the generated virtual mics equals the quality obtained when the additional microphones are installed as physical sensors.
Figures

read the original abstract
While the spatial directivity of multichannel speech enhancement algorithms improves with the number of microphones, fitting large capture arrays into real-world edge devices is typically limited by physical constraints. To overcome this limitation, we propose Spatial-Magnifier, a neural network designed to generate virtual microphone (VM) signals from a limited set of real microphone (RM) measurements. Moreover, we introduce the Spatial Audio Representation Learning (SARL) framework, which leverages estimated VM signals and features to condition a downstream speech enhancement system. Experimental results demonstrate that the proposed framework outperforms existing spatial upsampling baselines across various speech extraction systems, including end-to-end multichannel speech enhancement and neural beamforming. The proposed method nearly recovers the oracle performance achieved when all microphones are available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Spatial-Magnifier, a neural network that generates virtual microphone (VM) signals from a limited number of real microphone (RM) inputs, together with the SARL framework that conditions downstream multichannel speech enhancement systems on the estimated VM signals and features. The central claim is that the approach outperforms existing spatial upsampling baselines and nearly recovers the oracle performance obtained when the full physical microphone array is available, across end-to-end enhancement and neural beamforming pipelines.
Significance. If the virtual signals are shown to preserve the necessary spatial statistics, the work would offer a practical route to high-performance spatial processing on edge devices whose physical microphone count is constrained, an important engineering limitation. The framework's compatibility with multiple downstream systems is a constructive design choice.
major comments (2)
- [Abstract] Abstract: the claim that the method 'nearly recovers the oracle performance achieved when all microphones are available' and 'outperforms existing spatial upsampling baselines' is stated without any numerical results, dataset description, statistical tests, or ablation data. This prevents evaluation of effect size or robustness.
- [SARL framework] SARL framework description: the headline result rests on the assumption that NN-generated VM signals supply the same inter-microphone phase, magnitude-squared coherence, and null directions that physical sensors would provide to beamformers or multichannel enhancers. No analysis, metric, or experiment is supplied showing that these spatial properties are preserved for sources at unseen angles or under reverberation; waveform or spectrogram fidelity alone does not guarantee this.
minor comments (1)
- [Notation] The acronyms RM/VM and SARL are introduced without an explicit table of notation or input/output tensor shapes for the Spatial-Magnifier network.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the SARL framework. We address each major comment below and will revise the manuscript accordingly to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the method 'nearly recovers the oracle performance achieved when all microphones are available' and 'outperforms existing spatial upsampling baselines' is stated without any numerical results, dataset description, statistical tests, or ablation data. This prevents evaluation of effect size or robustness.
Authors: We agree that the abstract would benefit from greater specificity to allow immediate assessment of the claims. In the revised manuscript we will add concise quantitative indicators (e.g., SI-SDR or PESQ gains relative to baselines and proximity to oracle performance) together with a brief reference to the evaluation dataset and metrics. Full tables, ablations, and any statistical details will remain in the body of the paper, consistent with typical abstract length constraints. revision: yes
-
Referee: [SARL framework] SARL framework description: the headline result rests on the assumption that NN-generated VM signals supply the same inter-microphone phase, magnitude-squared coherence, and null directions that physical sensors would provide to beamformers or multichannel enhancers. No analysis, metric, or experiment is supplied showing that these spatial properties are preserved for sources at unseen angles or under reverberation; waveform or spectrogram fidelity alone does not guarantee this.
Authors: This observation is correct: the current manuscript relies on downstream task performance to imply that spatial cues are preserved, without direct verification of phase, coherence, or null-direction fidelity under unseen angles or reverberation. In the revision we will add a dedicated analysis subsection that reports these spatial metrics (phase error, magnitude-squared coherence, and beam-pattern nulls) for both seen and unseen source angles in reverberant conditions, thereby providing explicit evidence for the assumption underlying SARL. revision: yes
Circularity Check
No circularity: empirical performance claims rest on external training data and standard benchmarks, not self-referential definitions or fitted inputs.
full rationale
The paper proposes a neural network (Spatial-Magnifier) and SARL framework to generate virtual microphone signals and condition downstream enhancement. All load-bearing claims are experimental: the network is trained on external multichannel data to minimize waveform/spectrogram losses, then evaluated on held-out test sets against baselines and oracle (all-mics) performance. No equations define the target metric in terms of the method's own outputs, no parameters are fitted to a subset and then called a prediction of a related quantity, and no uniqueness theorems or ansatzes are imported via self-citation to force the architecture. The derivation chain is therefore self-contained: inputs are real microphone signals plus training data; outputs are measured improvements on independent test distributions.
Axiom & Free-Parameter Ledger
free parameters (1)
- Neural network parameters
invented entities (2)
-
Spatial-Magnifier neural network
no independent evidence
-
SARL framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Introduction Increasing the spatial diversity of microphone arrays by ex- panding the physical distance between sensors or adding more capture points can significantly boost the performance of mul- tichannel speech enhancement (MC-SE) algorithms [1, 2, 3]. However, the spatial capture capabilities of consumer devices such as augmented reality (AR) glasses...
-
[2]
Proposed method 2.1. Mathematical modeling of neural beamforming MC-SE is the task of estimating a direct-path speech signal xref ∈R 1×N given multichannel noisy speechy∈R M×N consisting ofMchannels andNsamples, which can be ex- pressed as y=x+x rev +n, (1) wherex∈R M×N ,x rev ∈R M×N , andn∈R M×N denote the multichannel waveforms of the direct-path speech...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Experiments 3.1. Datasets We used the Interspeech 2020 DNS challenge speech and noise corpora [26] to simulate 50,000, 2,000, and 3,000 clips of 10 s duration for training, validation, and testing, respectively. Spa- tial data were simulated viaPyroomacoustics[27] using the im- age source method with an order of six. The six-channel array consisted of a f...
2020
-
[4]
Neural network computation load is reported as Multiply Accumulates per second (MAC/s)
Results For the ablation study and baseline comparison, we employed SpatialNet-small [21] as the MC-SE model combined with an MCWF [1, 13] beamformer. Neural network computation load is reported as Multiply Accumulates per second (MAC/s). 4.1. Ablation study This analysis focuses on the FoV-SE task suitable for MC- SE. First, in Table 1 we show that while...
-
[5]
The proposed method achieves high VM-BF performance by effectively leveraging spatial information to estimate multiple VM representations to condition a downstream task
Conclusion This paper introduces Spatial-Magnifier, a dedicated network for audio spatial upsampling, and SARL, a novel training framework for virtual microphone-based beamforming (VM- BF) and speech enhancement (VM-SE). The proposed method achieves high VM-BF performance by effectively leveraging spatial information to estimate multiple VM representation...
-
[6]
All scientific content, experimen- tal design, and results were produced by the authors
Generative AI Use Disclosure Generative AI tools (Gemini, ChatGPT) were used for editing and polishing the manuscript. All scientific content, experimen- tal design, and results were produced by the authors
-
[7]
Benesty, J
J. Benesty, J. Chen, and Y . Huang,Microphone array signal pro- cessing. Springer, 2008
2008
-
[8]
Beamforming: a versatile approach to spatial filtering,
B. Van Veen and K. Buckley, “Beamforming: a versatile approach to spatial filtering,”IEEE ASSP Magazine, vol. 5, no. 2, pp. 4–24, 1988
1988
-
[9]
Complex spectral mapping for single-and multi-channel speech enhancement and robust asr,
Z.-Q. Wang, P. Wang, and D. Wang, “Complex spectral mapping for single-and multi-channel speech enhancement and robust asr,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 28, pp. 1778–1787, 2020
2020
-
[10]
Neural network-based virtual microphone estima- tor,
T. Ochiai, M. Delcroix, T. Nakatani, R. Ikeshita, K. Kinoshita, and S. Araki, “Neural network-based virtual microphone estima- tor,” inProc. Int. Conf. Acoust. Speech, Signal Process., 2021, pp. 6114–6118
2021
-
[11]
Neural virtual microphone estimator: Application to multi-talker reverberant mixtures,
H. Segawa, T. Ochiai, M. Delcroix, T. Nakatani, R. Ikeshita, S. Araki, T. Yamada, and S. Makino, “Neural virtual microphone estimator: Application to multi-talker reverberant mixtures,” in Proc. Asia-Pacific Signal Inf. Process. Assoc. Annu. Summit Conf., 2022, pp. 293–299
2022
-
[12]
Neural network-based virtual microphone estimation with virtual microphone and beamformer-level multi-task loss,
H. Segawa, T. Ochiai, M. Delcroix, T. Nakatani, R. Ikeshita, S. Araki, T. Yamada, and S. Makino, “Neural network-based virtual microphone estimation with virtual microphone and beamformer-level multi-task loss,” inProc. Int. Conf. Acoust. Speech, Signal Process., 2024, pp. 11 021–11 025
2024
-
[13]
Robust DOA esti- mation from deep acoustic imaging,
A. S. Roman, I. R. Roman, and J. P. Bello, “Robust DOA esti- mation from deep acoustic imaging,” inProc. Int. Conf. Acoust. Speech, Signal Process., 2024, pp. 1321–1325
2024
-
[14]
Deep back-projection networks for super-resolution,
M. Haris, G. Shakhnarovich, and N. Ukita, “Deep back-projection networks for super-resolution,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 1664–1673
2018
-
[15]
Unsupervised training of neural network- based virtual microphone estimator,
J. Wang and T. Toda, “Unsupervised training of neural network- based virtual microphone estimator,” inProc. Eur. Signal Process. Conf., 2024, pp. 256–260
2024
-
[16]
Transformer- based virtual microphone estimator,
Z. Qiu, J. Wang, B. He, S. Zhang, and S. Makino, “Transformer- based virtual microphone estimator,” inProc. IEEE Int. Conf. Sig- nal Process., Commun. Comput., 2024, pp. 1–5
2024
-
[17]
On optimal frequency- domain multichannel linear filtering for noise reduction,
M. Souden, J. Benesty, and S. Affes, “On optimal frequency- domain multichannel linear filtering for noise reduction,”IEEE Trans. Audio, Speech, Lang. Process., vol. 18, no. 2, pp. 260–276, 2009
2009
-
[18]
Ultra low-compute complex spec- tral masking for multichannel speech enhancement,
A. Pandey and J. Azcarreta, “Ultra low-compute complex spec- tral masking for multichannel speech enhancement,” inProc. Int. Conf. Acoust. Speech, Signal Process., 2025, pp. 1–5
2025
-
[19]
STFT- Domain neural speech enhancement with very low algorithmic la- tency,
Z.-Q. Wang, G. Wichern, S. Watanabe, and J. Le Roux, “STFT- Domain neural speech enhancement with very low algorithmic la- tency,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 31, pp. 397–410, 2022
2022
-
[20]
Multi-microphone complex spectral mapping for speech dereverberation,
Z.-Q. Wang and D. Wang, “Multi-microphone complex spectral mapping for speech dereverberation,” inICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 486–490
2020
-
[21]
Neural network based spectral mask estimation for acoustic beamforming,
J. Heymann, L. Drude, and R. Haeb-Umbach, “Neural network based spectral mask estimation for acoustic beamforming,” in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2016, pp. 196–200
2016
-
[22]
Generative adver- sarial nets,
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde- Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adver- sarial nets,”Proc. Adv. Neural Inf. Process. Syst., vol. 27, 2014
2014
-
[23]
Dynamic convolution: Attention over convolution kernels,
Y . Chen, X. Dai, M. Liu, D. Chen, L. Yuan, and Z. Liu, “Dynamic convolution: Attention over convolution kernels,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2020, pp. 11 030–11 039
2020
-
[24]
Mish: A self regularized non-monotonic activation function,
D. Misra, “Mish: A self regularized non-monotonic activation function,” inProc. Brit. Mach. Vis. Conf., 2019
2019
-
[25]
DeFT-Mamba: universal multichannel sound separation and polyphonic audio classification,
D. Lee and J. Choi, “DeFT-Mamba: universal multichannel sound separation and polyphonic audio classification,” inProc. Int. Conf. Acoust. Speech, Signal Process., 2025, pp. 1–5
2025
-
[26]
CMGAN: Conformer-based metric-gan for monaural speech enhancement,
S. Abdulatif, R. Cao, and B. Yang, “CMGAN: Conformer-based metric-gan for monaural speech enhancement,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 32, pp. 2477–2493, 2024
2024
-
[27]
SpatialNet: Extensively learning spatial in- formation for multichannel joint speech separation, denoising and dereverberation,
C. Quan and X. Li, “SpatialNet: Extensively learning spatial in- formation for multichannel joint speech separation, denoising and dereverberation,”IEEE/ACM Trans. Audio, Speech, Lang. Pro- cess., vol. 32, pp. 1310–1323, 2024
2024
-
[28]
Conv-TasNet: Surpassing ideal time– frequency magnitude masking for speech separation,
Y . Luo and N. Mesgarani, “Conv-TasNet: Surpassing ideal time– frequency magnitude masking for speech separation,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 27, no. 8, pp. 1256– 1266, 2019
2019
-
[29]
DeFTAN-II: Efficient multichannel speech enhancement with subgroup processing,
D. Lee and J.-W. Choi, “DeFTAN-II: Efficient multichannel speech enhancement with subgroup processing,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 32, pp. 4850–4866, 2024
2024
-
[30]
Self-supervised learning of spatial acoustic representation with cross-channel signal reconstruction and multi- channel conformer,
B. Yang and X. Li, “Self-supervised learning of spatial acoustic representation with cross-channel signal reconstruction and multi- channel conformer,”IEEE/ACM Trans. Audio, Speech, Lang. Pro- cess., vol. 32, pp. 4211–4225, 2024
2024
-
[31]
Efficient audiovisual speech processing via mutud: Multimodal training and unimodal deployment,
J. Hong, S. Parekh, H. Chen, J. Donley, K. Tan, B. Xu, and A. Kumar, “Efficient audiovisual speech processing via mutud: Multimodal training and unimodal deployment,”arXiv preprint arXiv:2501.18157, 2025
-
[32]
The INTERSPEECH 2020 deep noise suppression challenge: Datasets, subjective testing frame- work, and challenge results,
C. K. Reddy, V . Gopal, R. Cutler, E. Beyrami, R. Cheng, H. Dubey, S. Matusevychet al., “The INTERSPEECH 2020 deep noise suppression challenge: Datasets, subjective testing frame- work, and challenge results,” inProc. Interspeech, 2020
2020
-
[33]
Pyroomacoustics: A python package for audio room simulation and array processing algorithms,
R. Scheibler, E. Bezzam, and I. Dokmani ´c, “Pyroomacoustics: A python package for audio room simulation and array processing algorithms,” inProc. Int. Conf. Acoust. Speech, Signal Process., 2018, pp. 351–355
2018
-
[34]
FoVNet: Configurable field-of-view speech enhance- ment with low computation and distortion for smart glasses,
Z. Xu, A. Aroudi, K. Tan, A. Pandey, J.-S. Lee, B. Xu, and F. Nesta, “FoVNet: Configurable field-of-view speech enhance- ment with low computation and distortion for smart glasses,” in Proc. Interspeech, 2024
2024
-
[35]
Sequential multi-frame neural beamforming for speech separation and enhancement,
Z.-Q. Wang, H. Erdogan, S. Wisdom, K. Wilson, D. Raj, S. Watanabe, Z. Chen, and J. R. Hershey, “Sequential multi-frame neural beamforming for speech separation and enhancement,” in 2021 IEEE Spoken Language Technology Workshop (SLT), 2021, pp. 905–911
2021
-
[36]
HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis,
J. Kong, J. Kim, and J. Bae, “HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis,”Proc. Adv. Neural Inf. Process. Syst., vol. 33, pp. 17 022–17 033, 2020
2020
-
[37]
Sdr–half- baked or well done?
J. Le Roux, S. Wisdom, H. Erdogan, and J. Hershey, “Sdr–half- baked or well done?” inProc. Int. Conf. Acoust. Speech, Signal Process., 2019, pp. 626–630
2019
-
[38]
Perceptual eval- uation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs,
A. Rix, J. Beerends, M. Hollier, and A. Hekstra, “Perceptual eval- uation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs,” inProc. Int. Conf. Acoust. Speech, Signal Process., vol. 2, 2001, pp. 749–752
2001
-
[39]
A short- time objective intelligibility measure for time-frequency weighted noisy speech,
C. Taal, R. Hendriks, R. Heusdens, and J. Jensen, “A short- time objective intelligibility measure for time-frequency weighted noisy speech,” inProc. Int. Conf. Acoust. Speech, Signal Process., 2010, pp. 4214–4217
2010
-
[40]
A simple RNN model for lightweight, low-compute and low-latency multichannel speech enhancement in the time domain,
A. Pandey, K. Tan, and B. Xu, “A simple RNN model for lightweight, low-compute and low-latency multichannel speech enhancement in the time domain,” inInterspeech, 2023, pp. 2478– 2482
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.