Recognition: unknown
VC-FeS: Viewpoint-Conditioned Feature Selection for Vehicle Re-identification in Thermal Vision
Pith reviewed 2026-05-08 17:10 UTC · model grok-4.3
The pith
Conditioning thermal vehicle features on viewpoint lets RGB vision transformers outperform prior methods on single-channel images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
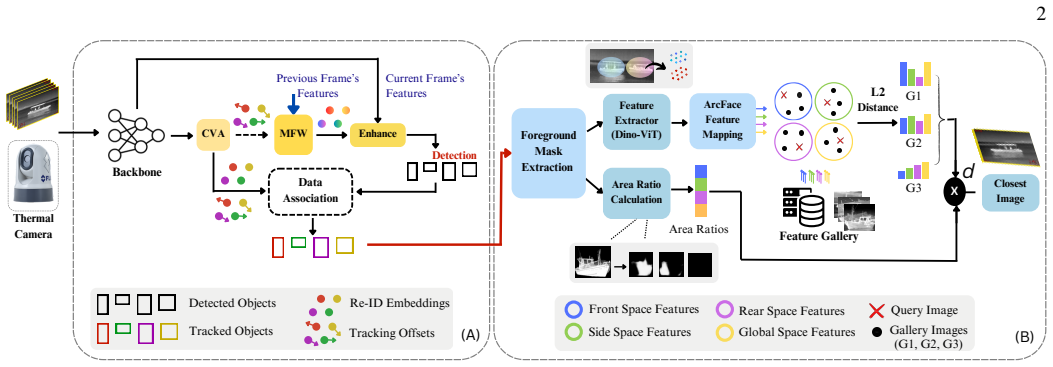
We address these issues by constructing viewpoint-conditioned feature vectors and area-specific feature comparisons in separate feature spaces. These interventions enable leveraging the advancements of existing RGB-pre-trained ViT feature extractors while effectively adapting them to address the challenges specific to the thermal domain.
What carries the argument
Viewpoint-conditioned feature vectors with area-specific comparisons executed in separate feature spaces.
If this is right
- The method exceeds prior state-of-the-art by 19.7 percent mAP on the RGBNT100 infrared vehicle dataset.
- It exceeds prior state-of-the-art by 12.8 percent mAP on the authors' thermal maritime vessel dataset.
- RGB-pretrained vision transformers can be transferred to thermal re-identification without domain-specific retraining from scratch.
- The same viewpoint and area interventions support practical deployment in surveillance and maritime monitoring that must rely on single-channel thermal cameras.
Where Pith is reading between the lines
- The same conditioning pattern could be tested on thermal pedestrian re-identification where viewpoint variation is also severe.
- Public release of the maritime thermal dataset would allow direct comparison of future methods on this previously unavailable benchmark.
- Viewpoint conditioning may reduce reliance on expensive multi-spectral or RGB-thermal paired data for other re-identification problems.
Load-bearing premise
Estimates of vehicle viewpoint and divisions into specific areas remain accurate enough that they do not create new errors larger than the gains from conditioning.
What would settle it
A controlled test on the same datasets in which viewpoint labels or area masks are deliberately perturbed to show the method falling below the performance of an unconditioned thermal baseline.
Figures




read the original abstract
Identification of less-articulated objects using single-channel images, such as thermal images, is important in many applications, such as surveillance. However, in this domain, existing methods show poor performance due to high similarity among objects of the same category in the absence of color information (overlooking shape information) and de-emphasized texture information. Furthermore, variability in viewpoint adds more complexity as the features vary from side to side. We address these issues by constructing viewpoint-conditioned feature vectors and area-specific feature comparisons in separate feature spaces. These interventions enable leveraging the advancements of existing RGB-pre-trained ViT feature extractors while effectively adapting them to address the challenges specific to the thermal domain. We test our system with RGBNT100 (IR) vehicle dataset and a thermal maritime dataset acquired by us. Our results surpass the state-of-the-art methods by 19.7% and 12.8% for the above datasets in mAP scores, respectively. We also plan to make our thermal dataset available, the first of its kind for maritime vessel identification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VC-FeS, a method for vehicle re-identification in thermal images. It constructs viewpoint-conditioned feature vectors and performs area-specific comparisons to adapt an RGB-pretrained ViT feature extractor to the thermal domain, addressing challenges of high intra-class similarity and viewpoint variability in single-channel thermal data. Experiments on the RGBNT100-IR dataset and a new author-collected thermal maritime vessel dataset report mAP gains of 19.7% and 12.8% over prior state-of-the-art methods, respectively, with plans to release the maritime dataset.
Significance. If the reported gains prove robust and reproducible, the work could meaningfully advance thermal-domain re-identification by providing a practical way to leverage large RGB-pretrained models without requiring full retraining from scratch. The release of the first maritime thermal re-ID dataset would also be a concrete community contribution for surveillance and maritime applications.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the claimed 19.7% and 12.8% mAP improvements are presented without any description of the exact baselines, statistical significance testing, variance across runs, or ablation studies that isolate the contribution of viewpoint conditioning versus area-specific comparison. These omissions make it impossible to verify whether the gains are load-bearing or could arise from other factors.
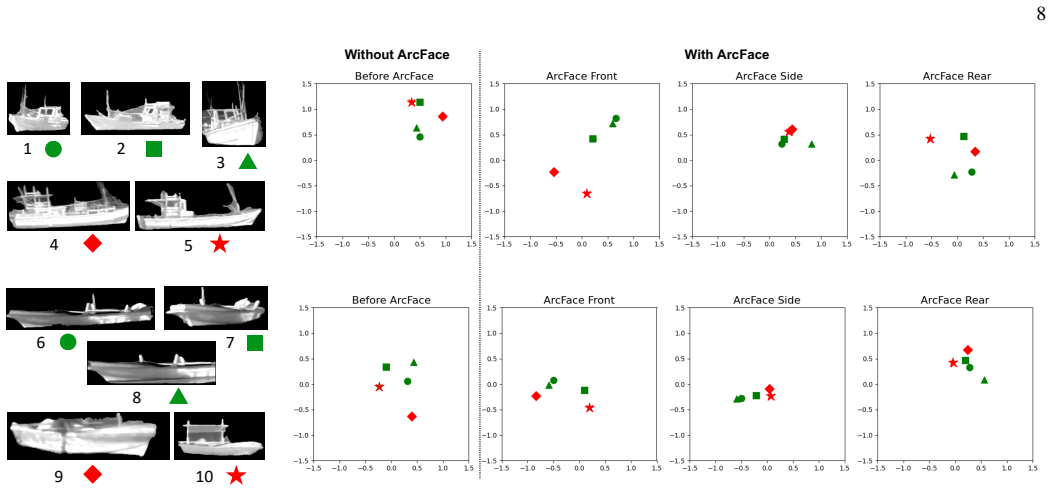
- [§3] §3 (Method): the approach depends on reliable viewpoint classification and region segmentation from thermal inputs, yet no quantitative validation (accuracy, confusion matrices, or comparison to ground-truth masks) is supplied for these modules. If viewpoint labels or area masks contain noise, the conditioning step may function primarily as regularization rather than domain-specific adaptation, undermining the central claim.
minor comments (2)
- [§2] §2 (Related Work): several recent thermal re-ID papers using attention or domain adaptation are cited only generically; explicit comparison of architectural differences with VC-FeS would strengthen positioning.
- [Figure 1 and §3.2] Figure 1 and §3.2: the diagram and text describing how viewpoint-conditioned vectors are formed and how area-specific comparisons are computed in separate feature spaces would benefit from an explicit equation or pseudocode block.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment point by point below, indicating the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the claimed 19.7% and 12.8% mAP improvements are presented without any description of the exact baselines, statistical significance testing, variance across runs, or ablation studies that isolate the contribution of viewpoint conditioning versus area-specific comparison. These omissions make it impossible to verify whether the gains are load-bearing or could arise from other factors.
Authors: We agree that the presentation of results in the abstract and §4 requires more explicit supporting details. In the revised manuscript we will expand the experimental section to include a table that explicitly lists all baseline methods with their reported mAP scores on both the RGBNT100-IR and maritime datasets. We will also report mean mAP together with standard deviation across multiple independent runs (using different random seeds) and add an ablation study that isolates the contribution of viewpoint conditioning from area-specific comparison. These additions will allow readers to assess whether the gains are attributable to the proposed components. revision: yes
-
Referee: [§3] §3 (Method): the approach depends on reliable viewpoint classification and region segmentation from thermal inputs, yet no quantitative validation (accuracy, confusion matrices, or comparison to ground-truth masks) is supplied for these modules. If viewpoint labels or area masks contain noise, the conditioning step may function primarily as regularization rather than domain-specific adaptation, undermining the central claim.
Authors: We acknowledge that quantitative validation of the viewpoint classification and region segmentation modules was omitted from the original submission. In the revision we will add accuracy figures, confusion matrices for viewpoint classification, and IoU scores for segmentation against available ground-truth masks on both datasets. To address the concern that noise could reduce the modules to generic regularization, the new ablation study will compare performance with and without the viewpoint-conditioned features while keeping other factors fixed, thereby demonstrating that the gains arise specifically from the conditioning mechanism rather than from regularization alone. revision: yes
Circularity Check
No circularity: engineering method with empirical validation, no derivation chain
full rationale
The paper describes an applied computer vision technique that constructs viewpoint-conditioned feature vectors and performs area-specific comparisons to adapt an RGB-pretrained ViT to thermal re-identification. No equations, fitted parameters, or closed-form derivations are presented in the abstract or described approach. Performance gains are reported as empirical results on specific datasets rather than predictions derived from the method itself. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing elements. The central claim reduces to an architectural intervention whose validity rests on external benchmarks and dataset testing, not on any reduction to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year =
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author =. International Conference on Learning Representations , year =
-
[2]
IEEE Conference on Computer Vision and Pattern Recognition , year =
Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun , title =. IEEE Conference on Computer Vision and Pattern Recognition , year =
-
[3]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops , year=
Bag of tricks and a strong baseline for deep person re-identification , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops , year=
-
[4]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Unsupervised pre-training for person re-identification , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[5]
IEEE International Conference on Image Processing (ICIP) , pages=
Simple online and realtime tracking , author=. IEEE International Conference on Image Processing (ICIP) , pages=
-
[6]
IEEE international conference on image processing (ICIP) , pages=
Simple online and realtime tracking with a deep association metric , author=. IEEE international conference on image processing (ICIP) , pages=
-
[7]
Computer Vision and Image Understanding , volume=
A survey of advances in vision-based vehicle re-identification , author=. Computer Vision and Image Understanding , volume=. 2019 , publisher=
2019
-
[8]
British Machive Vision Conference , pages=
Bicov: a novel image representation for person re-identification and face verification , author=. British Machive Vision Conference , pages=
-
[9]
IEEE transactions on pattern analysis and machine intelligence , volume=
Viewpoint invariant human re-identification in camera networks using pose priors and subject-discriminative features , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2014 , publisher=
2014
-
[10]
Pattern Recognition , volume=
Person re-identification: A retrospective on domain specific open challenges and future trends , author=. Pattern Recognition , volume=. 2023 , publisher=
2023
-
[11]
IEEE Transactions on Image Processing , volume=
Git: Graph interactive transformer for vehicle re-identification , author=. IEEE Transactions on Image Processing , volume=. 2023 , publisher=
2023
-
[12]
Electronics , volume=
Dual-Level Viewpoint-Learning for Cross-Domain Vehicle Re-Identification , author=. Electronics , volume=. 2024 , publisher=
2024
-
[13]
Pattern Recognition , volume=
A dual self-attention mechanism for vehicle re-identification , author=. Pattern Recognition , volume=. 2023 , publisher=
2023
-
[14]
Information Fusion , volume=
Deep learning for visible-infrared cross-modality person re-identification: A comprehensive review , author=. Information Fusion , volume=. 2023 , publisher=
2023
-
[15]
Journal of Mobile Multimedia , pages=
An Ensemble Approach To Face Recognition In Access Control Systems , author=. Journal of Mobile Multimedia , pages=
-
[16]
Information Fusion , volume=
Multi-view information integration and propagation for occluded person re-identification , author=. Information Fusion , volume=. 2024 , publisher=
2024
-
[17]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Multi-spectral vehicle re-identification: A challenge , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[18]
IEEE/CVF conference on computer vision and pattern recognition , pages=
Track to detect and segment: An online multi-object tracker , author=. IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[19]
IEEE conference on computer vision and pattern recognition , pages=
Efficient action localization with approximately normalized fisher vectors , author=. IEEE conference on computer vision and pattern recognition , pages=
-
[20]
IEEE international conference on computer vision , pages=
Learning to track for spatio-temporal action localization , author=. IEEE international conference on computer vision , pages=
-
[21]
Computer Vision--ECCV: European Conference, Amsterdam, The Netherlands, Part IV 14 , pages=
Multi-region two-stream R-CNN for action detection , author=. Computer Vision--ECCV: European Conference, Amsterdam, The Netherlands, Part IV 14 , pages=
-
[22]
IEEE International Conference on Computer Vision , pages=
Online real-time multiple spatiotemporal action localisation and prediction , author=. IEEE International Conference on Computer Vision , pages=
-
[23]
arXiv preprint arXiv:1911.06644 , year=
You only watch once: A unified cnn architecture for real-time spatiotemporal action localization , author=. arXiv preprint arXiv:1911.06644 , year=
-
[24]
IEEE Access , volume=
Marine vessel re-identification: a large-scale dataset and global-and-local fusion-based discriminative feature learning , author=. IEEE Access , volume=
-
[25]
IEEE Conference on Computer Vision and Pattern Recognition , pages=
Deep network flow for multi-object tracking , author=. IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[26]
IEEE conference on computer vision and pattern recognition , pages=
Multiple people tracking by lifted multicut and person re-identification , author=. IEEE conference on computer vision and pattern recognition , pages=
-
[27]
IEEE international conference on computer vision , pages=
Multiple hypothesis tracking revisited , author=. IEEE international conference on computer vision , pages=
-
[28]
IEEE/CVF international conference on computer vision , pages=
Centernet: Keypoint triplets for object detection , author=. IEEE/CVF international conference on computer vision , pages=
-
[29]
Pattern Recognition , volume=
Face re-identification challenge: Are face recognition models good enough? , author=. Pattern Recognition , volume=
-
[30]
Image and Vision Computing , volume=
IRANet: Identity-relevance aware representation for cloth-changing person re-identification , author=. Image and Vision Computing , volume=
-
[31]
IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Cloth-changing person re-identification with self-attention , author=. IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[32]
International Conference on Pattern Recognition (ICPR) , pages=
Closing the domain gap for cross-modal visible-infrared vehicle re-identification , author=. International Conference on Pattern Recognition (ICPR) , pages=
-
[33]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
A Meta-Learning Approach for Domain Generalisation Across Visual Modalities in Vehicle Re-Identification , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[34]
IEEE/CVF international conference on computer vision , pages=
Emerging properties in self-supervised vision transformers , author=. IEEE/CVF international conference on computer vision , pages=
-
[35]
IEEE/CVF conference on computer vision and pattern recognition , pages=
Arcface: Additive angular margin loss for deep face recognition , author=. IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[36]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep relative distance learning: Tell the difference between similar vehicles , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[37]
IEEE Transactions on Intelligent Transportation Systems , volume=
Video processing from electro-optical sensors for object detection and tracking in a maritime environment: A survey , author=. IEEE Transactions on Intelligent Transportation Systems , volume=. 2017 , publisher=
2017
-
[38]
IEEE/CVF international conference on computer vision , pages=
Vehicle re-identification with viewpoint-aware metric learning , author=. IEEE/CVF international conference on computer vision , pages=
-
[39]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Aware attentive multi-view inference for vehicle re-identification , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[40]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
UCF101: A dataset of 101 human actions classes from videos in the wild , author=. arXiv preprint arXiv:1212.0402 , year=
work page internal anchor Pith review arXiv
-
[41]
International Conf
Towards understanding action recognition , author =. International Conf. on Computer Vision (ICCV) , month = Dec, pages =
-
[42]
Computer Vision--ECCV : European Conference, Glasgow, UK, Part II 16 , pages=
Orientation-aware vehicle re-identification with semantics-guided part attention network , author=. Computer Vision--ECCV : European Conference, Glasgow, UK, Part II 16 , pages=
-
[43]
, author=
Visible thermal person re-identification via dual-constrained top-ranking. , author=. IJCAI , volume=
-
[44]
Journal of Intelligent
Human Re-identification with a robot thermal camera using entropy-based sampling , author=. Journal of Intelligent
-
[45]
Journal of Visual Communication and Image Representation , volume=
A review of video surveillance systems , author=. Journal of Visual Communication and Image Representation , volume=
-
[46]
Multimedia Tools and Applications , volume=
A smart camera for the surveillance of vehicles in intelligent transportation systems , author=. Multimedia Tools and Applications , volume=
-
[47]
International Conference on Electronics Computer Technology (ICECT) , volume=
SVM based biometric authorization system by video analysis of human gait , author=. International Conference on Electronics Computer Technology (ICECT) , volume=
-
[48]
Machine Vision and Applications , volume=
Recognizing 50 human action categories of web videos , author=. Machine Vision and Applications , volume=
-
[49]
Structure and Infrastructure Engineering , volume=
Automatic detection of falling hazard from surveillance videos based on computer vision and building information modeling , author=. Structure and Infrastructure Engineering , volume=
-
[50]
Multimedia Tools and Applications , volume=
Vehicle detection and recognition for intelligent traffic surveillance system , author=. Multimedia Tools and Applications , volume=
-
[51]
Microsoft
Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll. Microsoft. Computer Vision--ECCV : European Conference, Zurich, Switzerland, September, Part V 13 , pages=
-
[52]
IEEE Transactions on Multimedia , volume=
Provid: Progressive and multimodal vehicle reidentification for large-scale urban surveillance , author=. IEEE Transactions on Multimedia , volume=
-
[53]
EURASIP Journal on Image and Video Processing , volume=
Evaluating multiple object tracking performance: the clear mot metrics , author=. EURASIP Journal on Image and Video Processing , volume=. 2008 , publisher=
2008
-
[54]
Proceedings of the AAAI conference on artificial intelligence , volume=
Cross-modality earth mover’s distance for visible thermal person re-identification , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[55]
IEEE Transactions on Image Processing , volume=
Vehicle re-identification by deep hidden multi-view inference , author=. IEEE Transactions on Image Processing , volume=. 2018 , publisher=
2018
-
[56]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Body part-based representation learning for occluded person re-identification , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[57]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Towards grand unified representation learning for unsupervised visible-infrared person re-identification , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[58]
ACM Transactions on Graphics (TOG) , volume=
``GrabCut'' interactive foreground extraction using iterated graph cuts , author=. ACM Transactions on Graphics (TOG) , volume=
-
[59]
IEEE Transactions on Instrumentation and Measurement , year=
Global-local discriminative representation learning network for viewpoint-aware vehicle re-identification in intelligent transportation , author=. IEEE Transactions on Instrumentation and Measurement , year=
-
[60]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep layer aggregation , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.