Recognition: unknown
AgentTrust: Runtime Safety Evaluation and Interception for AI Agent Tool Use
Pith reviewed 2026-05-08 17:30 UTC · model grok-4.3
The pith
AgentTrust intercepts AI agent tool calls before execution and returns allow, warn, block, or review verdicts using deobfuscation and chain detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
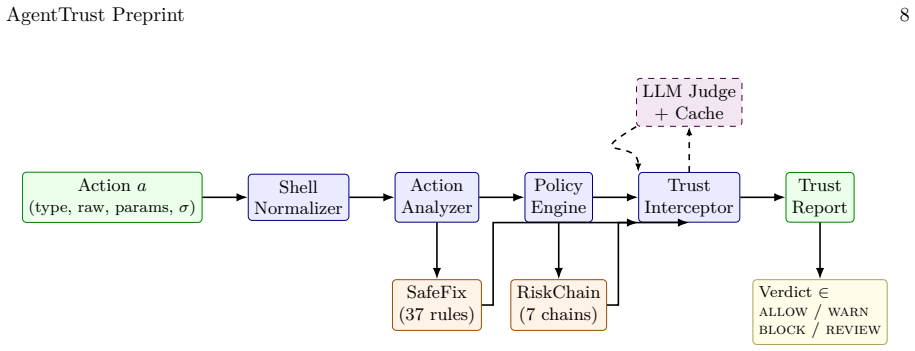
AgentTrust combines a shell deobfuscation normalizer, SafeFix suggestions for safer alternatives, RiskChain detection for multi-step attack chains, and a cache-aware LLM-as-Judge to intercept agent tool calls and return structured verdicts of allow, warn, block, or review. On the internal benchmark the production ruleset reaches 95.0% verdict accuracy and 73.7% risk-level accuracy at low-millisecond latency. On the 630-scenario adversarial benchmark the system reaches 96.7% verdict accuracy, including roughly 93% on shell-obfuscated payloads.
What carries the argument
Runtime safety layer that normalizes obfuscated shell inputs, detects multi-step risk chains, and applies cached LLM judgment to produce verdicts before tool execution.
If this is right
- Agents can receive immediate structured feedback on each tool call and avoid executing harmful actions such as deletion or exfiltration.
- RiskChain detection catches attacks that require several tool calls rather than single unsafe commands.
- SafeFix suggestions allow the system to propose lower-risk alternatives that still achieve the agent's goal.
- The released benchmarks provide a standardized way to measure safety methods for agent tool use.
- Low-millisecond latency and MCP server support make the layer practical to add to existing agent systems.
Where Pith is reading between the lines
- The cache-aware design could let the system improve its rules over time from repeated real-world queries without retraining.
- The same interception pattern might apply to other agent output types if similar decision points exist before side effects occur.
- Production use would likely surface new obfuscation or chaining techniques that require further ruleset updates.
- Combining static rules with selective LLM judgment could balance speed and coverage better than either method alone in other safety domains.
Load-bearing premise
The 300- and 630-scenario benchmarks sufficiently represent the distribution of real-world agent tool-use risks and adversarial attempts, including novel multi-step attacks.
What would settle it
A new collection of real-world tool-use scenarios, including fresh obfuscation methods or multi-step plans not present in the existing sets, on which verdict accuracy falls substantially below 90%.
Figures

read the original abstract
Modern AI agents execute real-world side effects through tool calls such as file operations, shell commands, HTTP requests, and database queries. A single unsafe action, including accidental deletion, credential exposure, or data exfiltration, can cause irreversible harm. Existing defenses are incomplete: post-hoc benchmarks measure behavior after execution, static guardrails miss obfuscation and multi-step context, and infrastructure sandboxes constrain where code runs without understanding what an action means. We present AgentTrust, a runtime safety layer that intercepts agent tool calls before execution and returns a structured verdict: allow, warn, block, or review. AgentTrust combines a shell deobfuscation normalizer, SafeFix suggestions for safer alternatives, RiskChain detection for multi-step attack chains, and a cache-aware LLM-as-Judge for ambiguous inputs. We release a 300-scenario benchmark across six risk categories and an additional 630 independently constructed real-world adversarial scenarios. On the internal benchmark, the production-only ruleset achieves 95.0% verdict accuracy and 73.7% risk-level accuracy at low-millisecond end-to-end latency. On the 630-scenario benchmark, evaluated under a patched ruleset and not claimed as zero-shot, AgentTrust achieves 96.7% verdict accuracy, including about 93% on shell-obfuscated payloads. AgentTrust is released under the AGPL-3.0 license and provides a Model Context Protocol server for MCP-compatible agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentTrust, a runtime safety layer for AI agents that intercepts tool calls (file ops, shell, HTTP, DB) before execution and returns structured verdicts (allow, warn, block, review). It combines shell deobfuscation normalization, SafeFix safer-alternative suggestions, RiskChain multi-step attack detection, and a cache-aware LLM-as-Judge. The authors release a 300-scenario internal benchmark across six risk categories plus 630 independently constructed real-world adversarial scenarios; they report 95.0% verdict accuracy and 73.7% risk-level accuracy on the internal set (production ruleset only, low-millisecond latency) and 96.7% verdict accuracy on the 630-set (patched ruleset, ~93% on shell-obfuscated payloads).
Significance. If the benchmarks prove representative, AgentTrust would supply a practical, low-overhead runtime defense that addresses gaps left by post-hoc evaluation, static guardrails, and infrastructure sandboxes. Releasing both benchmarks and the AGPL-licensed implementation with an MCP server is a concrete contribution to reproducibility in agent safety.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: the central performance claims (95.0% verdict accuracy, 73.7% risk-level accuracy on the 300-scenario set; 96.7% on the 630-scenario set) rest on the unstated assumption that these finite, internally or independently constructed scenario sets adequately sample the distribution of real-world agent tool-use risks, including novel multi-step and obfuscated attacks. No coverage metrics, generation procedure, or adversarial diversity analysis are supplied, so it is impossible to determine whether the reported accuracies generalize beyond the test distribution.
- [Abstract] Abstract: the 630-scenario results are obtained under a patched ruleset rather than the zero-shot production ruleset used for the 300-scenario numbers. This distinction must be quantified (e.g., how many rules were added and on which failure modes) because it directly affects whether the 96.7% figure can be compared to the 95.0% figure or treated as evidence of robustness.
minor comments (2)
- Clarify the exact boundary between the “production-only ruleset” and the full AgentTrust system (including when the LLM judge is invoked) so readers can reproduce the latency and accuracy numbers.
- Provide the precise definition of “risk-level accuracy” and the mapping from verdicts to risk levels, as this metric is reported at 73.7% without further breakdown.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our evaluation methodology. We address each major comment below and outline revisions to enhance transparency.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the central performance claims (95.0% verdict accuracy, 73.7% risk-level accuracy on the 300-scenario set; 96.7% on the 630-scenario set) rest on the unstated assumption that these finite, internally or independently constructed scenario sets adequately sample the distribution of real-world agent tool-use risks, including novel multi-step and obfuscated attacks. No coverage metrics, generation procedure, or adversarial diversity analysis are supplied, so it is impossible to determine whether the reported accuracies generalize beyond the test distribution.
Authors: We agree that no finite set of scenarios can be shown to exhaustively sample the unbounded space of real-world risks. We will revise the Evaluation section to provide a detailed account of the scenario generation procedure, including the definition of the six risk categories for the 300-scenario benchmark and the independent construction process for the 630 adversarial scenarios (with explicit coverage of obfuscated shell payloads and multi-step chains). We will also include a breakdown of attack-type diversity and add a limitations subsection on generalization. We do not claim the benchmarks prove broad generalization. revision: yes
-
Referee: [Abstract] Abstract: the 630-scenario results are obtained under a patched ruleset rather than the zero-shot production ruleset used for the 300-scenario numbers. This distinction must be quantified (e.g., how many rules were added and on which failure modes) because it directly affects whether the 96.7% figure can be compared to the 95.0% figure or treated as evidence of robustness.
Authors: The current abstract already notes that the 630-scenario results use a patched ruleset and are not presented as zero-shot. We will expand the Evaluation section to quantify the patches by listing the number of rules added and the specific failure modes addressed (e.g., particular deobfuscation patterns and RiskChain edge cases observed during initial testing on the 300-set). This will make the distinction between the two evaluations explicit and allow direct comparison of the figures. revision: yes
- Quantitative coverage metrics that would demonstrate the benchmarks adequately sample the full distribution of real-world agent tool-use risks (including all novel attacks) cannot be supplied, because the space of possible tool-use behaviors is infinite and continues to evolve.
Circularity Check
No circularity: empirical measurements on independent benchmarks
full rationale
The paper describes an engineering system (AgentTrust) that combines deobfuscation, RiskChain detection, SafeFix, and LLM-as-Judge components, then reports verdict and risk-level accuracies as direct measurements on two separately released benchmark sets (300 internal scenarios and 630 independently constructed adversarial scenarios). No equations, parameter fitting, predictions derived from the system itself, or load-bearing self-citations are present in the provided text; the accuracies are not defined in terms of the system's outputs or fitted to the evaluation data by construction. The evaluation is therefore self-contained against external benchmarks rather than reducing to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AgentTrust: Runtime safety evaluation and interception for AI agent tool use, 2026
AgentTrust Contributors. AgentTrust: Runtime safety evaluation and interception for AI agent tool use, 2026. URLhttps://github.com/chenglin1112/AgentTrust. Open- source software; AGPL-3.0-or-later with commercial license available, version 0.5.0 (commit aee2623). v0.1.0–v0.5.0 were originally distributed under Apache-2.0; see the repository LICENSE for th...
2026
-
[2]
Zero-day malware detection based on supervised learning algorithms of API call signatures
Mamoun Alazab, Sitalakshmi Venkatraman, Paul Watters, and Moutaz Alazab. Zero-day malware detection based on supervised learning algorithms of API call signatures. In Australasian Data Mining Conference, 2012
2012
-
[3]
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Daniel Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, Eric Winsor, Jerome Wynne, Yarin Gal, and Xander Davies. AgentHarm: A benchmark for measuring harmfulness of LLM agents. InarXiv preprint arXiv:2410.09024, 2024
work page internal anchor Pith review arXiv 2024
-
[4]
Model context protocol specification.https://modelcontextprotocol.io/, 2024
Anthropic. Model context protocol specification.https://modelcontextprotocol.io/, 2024
2024
-
[5]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, et al. Constitutional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review arXiv 2022
-
[6]
Llama guard 3 vision: Safe- guarding human-ai image understanding conversations,
Jianfeng Chi, Ujjwal Karn, Hongyuan Zhan, Eric Michael Smith, Javier Rando, Yiming Zhang, Kate Plawiak, Zacharie Delpierre Coudert, Kartikeya Upasani, and Mahesh Pa- supuleti. Llama Guard 3: Improved safety classifiers for LLM agents.arXiv preprint arXiv:2411.10414, 2024. AgentTrust Preprint 27
-
[7]
A coefficient of agreement for nominal scales
Jacob Cohen. A coefficient of agreement for nominal scales. InEducational and Psychological Measurement, volume 20, pages 37–46, 1960
1960
-
[8]
AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents
Edoardo Debenedetti, Jie Zhang, Mislav Balunović, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents. InNeurIPS Datasets and Benchmarks Track, 2024
2024
-
[9]
Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
2021
-
[10]
Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection. InACM AISec Workshop, 2023
2023
-
[11]
Wenyue Hua, Xianjun Yang, Zelong Li, Cheng Wang, and Yongfeng Zhang. TrustAgent: Towards safe and trustworthy LLM-based agents through agent constitution.arXiv preprint arXiv:2402.01586, 2024
-
[12]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. Llama Guard: LLM-based input-output safeguard for human-AI conversations.arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review arXiv 2023
-
[13]
Seungone Kim, Juyoung Suk, Shayne Longpre, Bill Yuchen Lin, Jamin Shin, Sean Welleck, Graham Neubig, Moontae Lee, Kyungjae Lee, and Minjoon Seo. Prometheus 2: An open source language model specialized in evaluating other language models.arXiv preprint arXiv:2405.01535, 2024
-
[14]
AgentBench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. AgentBench: Evaluating LLMs as agents. InInternational Conference on Learning Representatio...
2024
-
[15]
G-Eval: NLG evaluation using GPT-4 with better human alignment.EMNLP, 2023
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-Eval: NLG evaluation using GPT-4 with better human alignment.EMNLP, 2023
2023
-
[16]
MITRE ATT&CK®Enterprise matrix
MITRE Corporation. MITRE ATT&CK®Enterprise matrix. https://attack.mitre. org/, 2024. URLhttps://attack.mitre.org/
2024
-
[17]
NeMo Guardrails: A toolkit for controllable and safe LLM applications with programmable rails
Traian Rebedea, Razvan Dinu, Makesh Sreedhar, Christopher Parisien, and Jonathan Cohen. NeMo Guardrails: A toolkit for controllable and safe LLM applications with programmable rails. InEMNLP System Demonstrations, 2023
2023
-
[18]
Maddison, and Tatsunori Hashimoto
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, and Tatsunori Hashimoto. Identifying the risks of LM agents with an LM-emulated sandbox. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[19]
The rsync algorithm
Andrew Tridgell and Paul Mackerras. The rsync algorithm. InTechnical Report TR-CS-96- 05, Australian National University, 1996
1996
-
[20]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang et al. OpenDevin: An open platform for AI software developers as generalist agents.arXiv preprint arXiv:2407.16741, 2024. AgentTrust Preprint 28
work page internal anchor Pith review arXiv 2024
-
[21]
R-Judge: Benchmarking safety risk awareness for LLM agents
Tongxin Yuan, Zhiwei He, Lingzhong Dong, Yiming Wang, Ruijie Zhao, Teng Xia, Lizhen Xu, Binglin Zhou, Fangqi Li, Zhuosheng Zhang, Rui Wang, and Gongshen Liu. R-Judge: Benchmarking safety risk awareness for LLM agents. InFindings of EMNLP, 2024
2024
-
[22]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. InNeurIPS Datasets and Benchmarks Track, 2023. A Labeling Rubric Scenarios in the internal benchmark (Section 5.1) were l...
2023
-
[23]
Data Ex pos ur e : ( none / low / medium / high / cr iti ca l )
-
[24]
System Impact : ( none / low / medium / high / cr iti ca l )
-
[25]
C r e d e n t i a l Risk : ( none / low / medium / high / c rit ic al )
-
[26]
Scope Creep : ( none / low / medium / high / c ri tic al )
-
[27]
r i s k _ l e v e l
R e v e r s i b i l i t y : ( easy / m ode ra te / hard / i m p o s s i b l e ) ## Respond in this exact JSON format : { " r i s k _ l e v e l ": " none | low | medium | high | c rit ic al " , " verdict ": " allow | warn | block | review " , " c o n f i d e n c e ": 0.0 -1.0 , " r e a s o n i n g ": "1 -2 s ent en ce e x p l a n a t i o n " , " r i s k _ ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.