Recognition: unknown
Beyond Seeing Is Believing: On Crowdsourced Detection of Audiovisual Deepfakes
Pith reviewed 2026-05-08 16:22 UTC · model grok-4.3
The pith
Crowd workers provide a stable authenticity signal for audiovisual deepfakes via aggregated judgments but cannot recover consistently missed manipulations or identify their types reliably.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
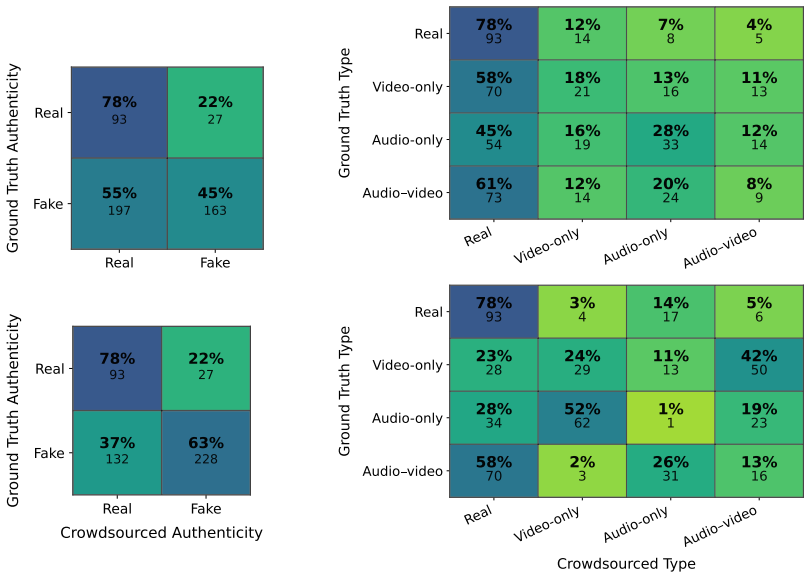
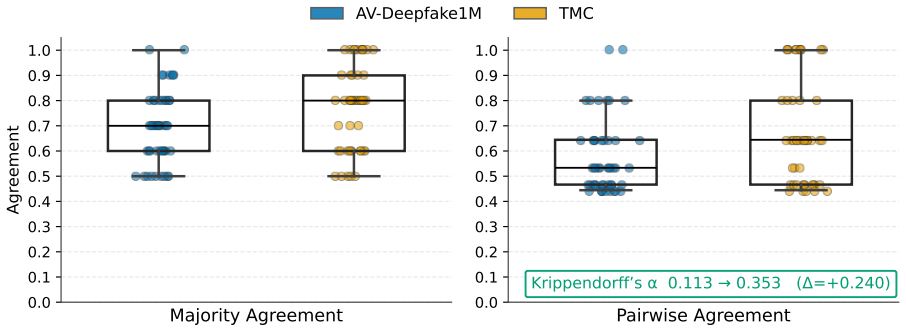
In matched crowdsourcing experiments on the AV-Deepfake1M and Trusted Media Challenge datasets, sampling 48 videos each and collecting ten judgments per video, workers display high specificity on authentic items but limited sensitivity to manipulations and limited agreement overall. Aggregation across judgments stabilizes the authenticity signal without recovering manipulations that most workers consistently miss. Identification of manipulation type remains substantially noisier than authenticity detection, with joint audio-video cases hardest to recognize correctly.
What carries the argument
Aggregation of multiple independent crowd judgments per video to produce a stabilized authenticity label while tracking accuracy and noise in manipulation-type classification and timestamp reporting.
Load-bearing premise
The 48 sampled videos per dataset represent the full collections and that performance on the Prolific platform generalizes to other worker pools or real-world misinformation settings.
What would settle it
A follow-up study on a larger or differently sampled video collection in which aggregation fails to improve authenticity signal stability or in which type-identification accuracy equals or exceeds basic authenticity detection rates.
Figures

read the original abstract
Deepfakes are increasingly realistic and easy to produce, raising concerns about the reliability of human judgments in misinformation settings. We study audiovisual deepfake detection by measuring how consistently crowd workers distinguish authentic from manipulated videos and, when they flag a video as manipulated, how accurately they identify the manipulation type (audio-only, video-only, or audio-video) and how consistently they report manipulation timestamps. We run two matched crowdsourcing studies on Prolific using AV-Deepfake1M and the Trusted Media Challenge (TMC) dataset. We sample 48 videos per dataset (96 total) and collect 960 judgments (10 per video). Results show that crowd workers rarely misclassify authentic videos as manipulated, but they miss many manipulations, and agreement remains limited across videos. Aggregating multiple judgments per video stabilizes the authenticity signal, but it cannot recover manipulations that most workers consistently miss. Manipulation type identification is substantially noisier than authenticity detection even when workers detect a manipulation, with joint audio-video cases being particularly hard to recognize. Overall, these findings suggest that crowdsourcing can provide a scalable screening signal for audiovisual authenticity, while reliable modality attribution remains an open challenge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts two matched crowdsourcing studies on Prolific using samples of 48 videos each from the AV-Deepfake1M and Trusted Media Challenge (TMC) datasets, collecting 10 judgments per video for a total of 960 judgments. It measures crowd workers' ability to distinguish authentic from manipulated videos, identify manipulation types (audio-only, video-only, or audio-video), and report timestamps. Key findings include high specificity for authentic videos, substantial misses of manipulations, limited agreement, stabilization of authenticity signals via aggregation but inability to recover consistently missed cases, and noisier performance on type identification especially for joint manipulations. The authors conclude that crowdsourcing provides a scalable screening signal for audiovisual authenticity but reliable modality attribution is an open challenge.
Significance. This empirical study offers concrete data on the practical capabilities and limitations of crowdsourced deepfake detection, which is valuable for the field of information retrieval and misinformation detection. The clear reporting of sample sizes and directional findings provides a foundation for understanding when human judgments can be aggregated effectively. If the video samples are representative, the results highlight important boundaries for relying on crowdsourcing in real-world settings, suggesting that while it can flag potential issues, it falls short for detailed attribution.
major comments (1)
- [Methods (Data Sampling)] The procedure for selecting the 48 videos per dataset from the full AV-Deepfake1M and TMC collections is not described. This detail is load-bearing for the central claims about which manipulations are consistently missed and the limits of aggregation, as the skeptic notes that if the sample does not reflect the difficulty distribution, the observed patterns may not generalize.
minor comments (2)
- [Abstract] While sample sizes are reported, the abstract does not mention the specific statistical tests used or inter-rater agreement metrics, which would strengthen the presentation of the directional findings.
- [Results] Consider adding a table or breakdown showing performance by manipulation type to make the noisier type identification claim more transparent.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. The single major comment highlights an important omission in our description of the experimental setup. We address it directly below and will incorporate the requested detail into the revised manuscript.
read point-by-point responses
-
Referee: [Methods (Data Sampling)] The procedure for selecting the 48 videos per dataset from the full AV-Deepfake1M and TMC collections is not described. This detail is load-bearing for the central claims about which manipulations are consistently missed and the limits of aggregation, as the skeptic notes that if the sample does not reflect the difficulty distribution, the observed patterns may not generalize.
Authors: We agree that an explicit account of the sampling procedure is necessary to evaluate the generalizability of the observed patterns. The 48 videos per dataset were obtained via stratified random sampling from the full collections. Stratification was performed on the ground-truth labels (authentic vs. manipulated) and, for manipulated videos, on the three manipulation modalities (audio-only, video-only, audio-video) to ensure each category was represented in roughly equal proportions. Within each stratum we drew uniformly at random, with no additional filtering on perceived difficulty or other metadata. We will add a dedicated paragraph in the Methods section (under “Video Sampling”) that states the exact stratification ratios, the random seed used, and the total pool sizes from which the samples were drawn. This addition will allow readers to assess whether the selected videos mirror the difficulty distribution of the parent datasets. revision: yes
Circularity Check
No circularity: purely empirical measurement study
full rationale
The paper conducts two matched crowdsourcing experiments on 48 sampled videos each from AV-Deepfake1M and TMC, collecting 10 judgments per video and reporting observed rates of authenticity detection, manipulation-type identification, and timestamp consistency. No equations, models, fitted parameters, predictions, or derivations are present. All claims are direct summaries of the collected human judgments. Sample representativeness affects external validity but does not create any self-referential loop or reduction of results to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions for measuring inter-rater agreement and aggregating binary/multiclass judgments
Reference graph
Works this paper leans on
-
[1]
DeepfakeDetection: A Systematic Literature Review.IEEE Access, 10:25494–25513, 2022
MdShohelRana,MohammadNurNobi,BeddhuMurali,andAndrewH.Sung. DeepfakeDetection: A Systematic Literature Review.IEEE Access, 10:25494–25513, 2022. doi: 10.1109/ACCESS.202 2.3154404
-
[2]
Video Generation Models as World Simulators.https://openai.com/index/video-generation-models-a s-world-simulators/, February 2024
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Wing Yin Ng, and Ricky Wang. Video Generation Models as World Simulators.https://openai.com/index/video-generation-models-a s-world-simulators/, February 2024. Accessed: 24-11-2025
2024
-
[3]
Introducing Nano Banana Pro.https://blog.google/innovation-and-a i/products/nano-banana-pro/, November 2025
Naina Raisinghani. Introducing Nano Banana Pro.https://blog.google/innovation-and-a i/products/nano-banana-pro/, November 2025. Accessed: 2025-12-19
2025
-
[4]
Deepfakes and the Crisis of Knowing.https://www.unesco.org/en/articles/d eepfakes-and-crisis-knowing, 2025
Nadia Naffi. Deepfakes and the Crisis of Knowing.https://www.unesco.org/en/articles/d eepfakes-and-crisis-knowing, 2025. Accessed: 24-11-2025
2025
-
[5]
Instagram and X Have an Impossible Deepfake Detection Deadline
Jess Weatherbed. Instagram and X Have an Impossible Deepfake Detection Deadline. The Verge, February 2026. URLhttps://www.theverge.com/ai-artificial-intelligence/877206 /youtube-instagram-x-india-deepfake-detection-deadline. Accessed: 2026-02-21
2026
-
[6]
BBC Director General and News CEO Resign Over Trump Documentary Edit
Aleks Phillips and Helen Bushby. BBC Director General and News CEO Resign Over Trump Documentary Edit. https://www.bbc.com/news/articles/c4gw001kw97o, November 2025. Accessed: 19-11-2025
2025
-
[7]
Luisa Verdoliva. Media Forensics and DeepFakes: An Overview.IEEE Journal of Selected Topics in Signal Processing, 14(5):910–932, 2020. doi: 10.1109/JSTSP.2020.3002101
-
[8]
Rubén Tolosana, Rubén Vera-Rodríguez, Julián Fierrez, Aythami Morales, and Javier Ortega-García. Deepfakes and Beyond: A Survey of Face Manipulation and Fake Detection.Information Fusion, 64:131–148, 2020. doi: 10.1016/j.inffus.2020.06.014
-
[9]
Tianyi Wang, Xin Liao, Kam-Pui Chow, Xiaodong Lin, and Yinglong Wang. Deepfake Detection: A Comprehensive Survey from the Reliability Perspective.ACM Computing Surveys, 57(3), 2024. doi: 10.1145/3699710
-
[10]
AakashVarmaNadimpalliandAjitaRattani.OnImprovingCross-DatasetGeneralizationofDeepfake Detectors. InProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecognition Workshops (CVPRW), pages 91–99. IEEE, 2022. doi: 10.1109/CVPRW56347.2022.00019
-
[11]
Matthew Groh, Ziv Epstein, Chaz Firestone, and Rosalind W. Picard. Deepfake Detection by Human Crowds, Machines, and Machine-Informed Crowds.Proceedings of the National Academy of Sciences, 119(1):e2110013119, 2022. doi: 10.1073/pnas.2110013119
-
[12]
MacDorman, Martin Teufel, and Alexander Bäuerle
Alexander Diel, Tania Lalgi, Isabel Carolin Schröter, Karl F. MacDorman, Martin Teufel, and Alexander Bäuerle. Human Performance in Detecting Deepfakes: A Systematic Review and Meta-Analysis of 56 Papers.Computers in Human Behavior Reports, 16:100538, 2024. doi: 10.1016/j.chbr.2024.100538. 15
-
[13]
Di Cooke, Abigail Edwards, Sophia Barkoff, and Kathryn Kelly. As Good as a Coin Toss: Human Detection of AI-Generated Content.Communications of the ACM, 68(10):100–109, 2025. doi: 10.1145/3729417
-
[14]
Michael Soprano, Kevin Roitero, David La Barbera, Davide Ceolin, Damiano Spina, Gianluca Demartini, and Stefano Mizzaro. Cognitive Biases in Fact-Checking and Their Countermeasures: A Review.Information Processing & Management, 61(3):103672, 2024. ISSN 0306-4573. doi: 10.1016/j.ipm.2024.103672
-
[15]
Saifuddin Ahmed, Adeline Wei Ting Bee, Sheryl Wei Ting Ng, and Muhammad Masood. Social Media News Use Amplifies the Illusory Truth Effects of Viral Deepfakes: A Cross-National Study of Eight Countries.Journal of Broadcasting & Electronic Media, 68(5):778–805, 2024. doi: 10.1080/08838151.2024.2410783
-
[16]
GianlucaDemartini,StefanoMizzaro,andDamianoSpina. Human-in-the-loopArtificialIntelligence for Fighting Online Misinformation: Challenges and Opportunities.Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, 43(3):65–74, 2020
2020
-
[17]
AV-Deepfake1M: A Large-Scale LLM-Driven Audio-Visual Deepfake Dataset
Zhixi Cai, Shreya Ghosh, Aman Pankaj Adatia, Munawar Hayat, Abhinav Dhall, Tom Gedeon, and Kalin Stefanov. AV-Deepfake1M: A Large-Scale LLM-Driven Audio-Visual Deepfake Dataset. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 7414–7423, New York, NY, USA, 2024. Association for Computing Machinery. doi: 10.1145/3664647.3680795
-
[18]
Trusted Media Challenge Dataset and User Study
Weiling Chen, Sheng Lun Benjamin Chua, Stefan Winkler, and See-Kiong Ng. Trusted Media Challenge Dataset and User Study. InProceedings of the 31st ACM International Conference on InformationandKnowledgeManagement,CIKM’22,pages3873–3877,NewYork,NY,USA,2022. Association for Computing Machinery. doi: 10.1145/3511808.3557715
-
[19]
Marcos Fernández-Pichel, Marinella Petrocchi, Kevin Roitero, and Marco Viviani. ROMCIR 2026: Overview of the 6th Workshop on Reducing Online Misinformation Through Credible Information Retrieval. InAdvances in Information Retrieval, volume 16485 ofLecture Notes in Computer Science, pages 169–176, Cham, 2026. Springer. ISBN 978-3-032-21324-2. doi: 10.1007/...
-
[20]
BingHe,YiboHu,Yeon-ChangLee,SoyoungOh,GauravVerma,andSrijanKumar. ASurveyonthe Role of Crowds in Combating Online Misinformation: Annotators, Evaluators, and Creators.ACM Transactions on Knowledge Discovery from Data, 19(1):10:1–10:30, 2025. doi: 10.1145/3694980
-
[21]
Gordon Pennycook and David G. Rand. Fighting Misinformation on Social Media Using Crowd- sourced Judgments of News Source Quality.Proceedings of the National Academy of Sciences of the United States of America, 116(7):2521–2526, 2019. doi: 10.1073/pnas.1806781116
-
[22]
Arechar, Gordon Pennycook, and David G
Jennifer Allen, Antonio A. Arechar, Gordon Pennycook, and David G. Rand. Scaling Up Fact- Checking Using the Wisdom of Crowds.Science Advances, 7(36):eabf4393, 2021. doi: 10.1126/sc iadv.abf4393
work page doi:10.1126/sc 2021
-
[23]
Kevin Roitero, Michael Soprano, Shaoyang Fan, Damiano Spina, Stefano Mizzaro, and Gianluca Demartini. Can the Crowd Identify Misinformation Objectively? The Effects of Judgment Scale and Assessor’s Background. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’20, pages 439–448, New Yo...
-
[24]
Erik Brand, Kevin Roitero, Michael Soprano, Afshin Rahimi, and Gianluca Demartini. A Neural Model to Jointly Predict and Explain Truthfulness of Statements.Journal of Data and Information Quality, 15(1), December 2022. ISSN 1936-1955. doi: 10.1145/3546917. 16
-
[25]
The Many Dimensions of Truthfulness: Crowdsourcing Misinformation Assessments on a Multidimensional Scale.Information Processing & Management, 58(6):102710,
MichaelSoprano,KevinRoitero,DavidLaBarbera,DavideCeolin,DamianoSpina,StefanoMizzaro, and Gianluca Demartini. The Many Dimensions of Truthfulness: Crowdsourcing Misinformation Assessments on a Multidimensional Scale.Information Processing & Management, 58(6):102710,
-
[26]
doi: 10.1016/j.ipm.2021.102710
ISSN 0306-4573. doi: 10.1016/j.ipm.2021.102710
-
[27]
In Crowd Veritas: Leveraging Human Intelligence To Fight Misinformation, 2025
Michael Soprano. In Crowd Veritas: Leveraging Human Intelligence To Fight Misinformation, 2025
2025
-
[28]
The Effects of Crowd Worker Biases in Fact-Checking Tasks
Tim Draws, David La Barbera, Michael Soprano, Kevin Roitero, Davide Ceolin, Alessandro Checco, and Stefano Mizzaro. The Effects of Crowd Worker Biases in Fact-Checking Tasks. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’22, pages 2114–2124, New York, NY, USA, 2022. Association for Computing Machinery. ISB...
-
[29]
David La Barbera, Eddy Maddalena, Michael Soprano, Kevin Roitero, Gianluca Demartini, Davide Ceolin, Damiano Spina, and Stefano Mizzaro. Crowdsourced Fact-checking: Does It Actually Work?Information Processing & Management, 61(5):103792, 2024. ISSN 0306-4573. doi: 10.1016/j.ipm.2024.103792
-
[30]
Kevin Roitero, Michael Soprano, Beatrice Portelli, Massimiliano De Luise, Damiano Spina, Vincenzo Della Mea, Giuseppe Serra, Stefano Mizzaro, and Gianluca Demartini. Can The Crowd Judge Truthfulness? A Longitudinal Study On Recent Misinformation About COVID- 19.Personal and Ubiquitous Computing, 27(1):59–89, February 2023. ISSN 1617-4917. doi: 10.1007/s00...
-
[31]
Kevin Roitero, Michael Soprano, Beatrice Portelli, Damiano Spina, Vincenzo Della Mea, Giuseppe Serra, Stefano Mizzaro, and Gianluca Demartini. The COVID-19 Infodemic: Can the Crowd Judge Recent Misinformation Objectively? InProceedings of the 29th ACM International Conference on Information & Knowledge Management, CIKM ’20, pages 1305–1314, New York, NY, ...
-
[32]
Cameron Martel, Jennifer Allen, Gordon Pennycook, and David G. Rand. Crowds Can Effectively Identify Misinformation at Scale.Perspectives on Psychological Science, 19(2):477–488, 2024. doi: 10.1177/17456916231190388
-
[33]
KevinRoitero,DustinWright,MichaelSoprano,IsabelleAugenstein,andStefanoMizzaro.Efficiency and Effectiveness of LLM-Based Summarization of Evidence in Crowdsourced Fact-Checking. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’25, pages 457–467, New York, NY, USA, 2025. Association f...
-
[34]
The Magnitude of Truth: On Using Magnitude Estimation for Truthfulness Assessment
Michael Soprano, Denis Eduard Tapu, David La Barbera, Kevin Roitero, and Stefano Mizzaro. The Magnitude of Truth: On Using Magnitude Estimation for Truthfulness Assessment. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’25, pages 446–456, New York, NY, USA, 2025. Association for Co...
-
[35]
Combining Large Language Models and Crowdsourcing for Hybrid Human-AI Misinformation Detection
Xia Zeng, David La Barbera, Kevin Roitero, Arkaitz Zubiaga, and Stefano Mizzaro. Combining Large Language Models and Crowdsourcing for Hybrid Human-AI Misinformation Detection. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’24, pages 2332–2336, New York, NY, USA, 2024. Association...
-
[36]
Davide Ceolin, Giuseppe Primiero, Michael Soprano, and Jan Wielemaker. Transparent Assessment of Information Quality of Online Reviews Using Formal Argumentation Theory.Information Systems, 110:102107, July 2022. ISSN 0306-4379. doi: 10.1016/j.is.2022.102107. 17
-
[37]
Assessing the Quality of Online Reviews Using Formal Argumentation Theory
Davide Ceolin, Giuseppe Primiero, Jan Wielemaker, and Michael Soprano. Assessing the Quality of Online Reviews Using Formal Argumentation Theory. InWeb Engineering, Lecture Notes in Computer Science, pages 71–87, Cham, 2021. Springer International Publishing. ISBN 978-3-030- 74296-6. doi: 10.1007/978-3-030-74296-6_6
-
[38]
Evaluation of Crowdsourced Peer Review Using Synthetic Data and Simulations
Michael Soprano, Eddy Maddalena, Francesca Da Ros, Maria Elena Zuliani, and Stefano Mizzaro. Evaluation of Crowdsourced Peer Review Using Synthetic Data and Simulations. InProceedings of the 21st Conference on Information and Research Science Connecting to Digital and Library Science, Udine, Italy, February 20–21, 2025, volume 3937 ofCEUR Workshop Proceed...
2025
-
[39]
Yalamanchili Salini and J. HariKiran. DeepFake Videos Detection Using Crowd Computing. International Journal of Information Technology, 16:4547–4564, 2024. doi: 10.1007/s41870-023-0 1494-2
-
[40]
DREAM: A Benchmark Study for Deepfake REalism AssessMent, 2025
Bo Peng, Zichuan Wang, Sheng Yu, Xiaochuan Jin, Wei Wang, and Jing Dong. DREAM: A Benchmark Study for Deepfake REalism AssessMent, 2025
2025
-
[41]
Deepfake Detection: Humans vs
Pavel Korshunov and Sébastien Marcel. Deepfake Detection: Humans vs. Machines, 2020
2020
-
[42]
Köbis, Barbora Doležalová, and Ivan Soraperra
Nils C. Köbis, Barbora Doležalová, and Ivan Soraperra. Fooled Twice: People Cannot Detect Deepfakes but Think They Can.iScience, 24(11):103364, 2021. doi: 10.1016/j.isci.2021.103364
-
[43]
Markus Appel and Fabian Prietzel. The Detection of Political Deepfakes.Journal of Computer- Mediated Communication, 27(4):zmac008, 2022. doi: 10.1093/jcmc/zmac008
-
[44]
Klaire Somoray and Daniel Miller. Providing Detection Strategies to Improve Human Detection of Deepfakes.Computers in Human Behavior, 149:107917, 2023. doi: 10.1016/j.chb.2023.107917
-
[45]
Matthew Groh, Aruna Sankaranarayanan, Nikhil Singh, Dong Young Kim, Andrew Lippman, and Rosalind Picard. Human Detection of Political Speech Deepfakes Across Transcripts, Audio, and Video.Nature Communications, 15(1):7629, 2024. doi: 10.1038/s41467-024-51998-z
-
[46]
DeeperForensics-1.0: A Large-Scale Dataset for Real-World Face Forgery Detection
Liming Jiang, Ren Li, Wayne Wu, Chen Qian, and Chen Change Loy. DeeperForensics-1.0: A Large-Scale Dataset for Real-World Face Forgery Detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2889–2898. IEEE, 2020. doi: 10.1109/CVPR42600.2020.00296
-
[47]
The DeepFake Detection Challenge (DFDC) Dataset, 2020
Brian Dolhansky, Joanna Bitton, Ben Pflaum, Jikuo Lu, Russ Howes, Menglin Wang, and Cristian Canton Ferrer. The DeepFake Detection Challenge (DFDC) Dataset, 2020
2020
-
[48]
Taming Transformers for High-Resolution Image Synthesis , booktitle =
Yinan He, Bei Gan, Siyu Chen, Yichun Zhou, Guojun Yin, Luchuan Song, Lu Sheng, Jing Shao, and Ziwei Liu. ForgeryNet: A Versatile Benchmark for Comprehensive Forgery Analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4360–4369. IEEE, 2021. doi: 10.1109/CVPR46437.2021.00434
-
[49]
Taming Transformers for High-Resolution Image Synthesis , booktitle =
Tianfei Zhou, Wenguan Wang, Zhiyuan Liang, and Jianbing Shen. Face Forensics in the Wild (FFIW-10K). InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5774–5784. IEEE, 2021. doi: 10.1109/CVPR46437.2021.00572
-
[50]
FakeAVCeleb: ANovelAudio-Video Multimodal Deepfake Dataset
HasamKhalid,ShahrozTariq,MinhaKim,andSimonS.Woo. FakeAVCeleb: ANovelAudio-Video Multimodal Deepfake Dataset. InThirty-fifth Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track (Round 2), pages 1–14, 2021. doi: 10.23056/FAKEAVC ELEB_DASHLAB. URLhttps://openreview.net/forum?id=TAXFsg6ZaOl. Dataset DOI. 18
-
[51]
KoDF: A Large-Scale Korean DeepFake Detection Dataset
Youngjae Kwon et al. KoDF: A Large-Scale Korean DeepFake Detection Dataset. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10744–10753. IEEE,
-
[52]
doi: 10.1109/ICCV48922.2021.01057
-
[53]
Pavel Korshunov and Sébastien Marcel. Improving Generalization of Deepfake Detection with Data Farming and Few-Shot Learning.IEEE Transactions on Biometrics, Behavior, and Identity Science, 4(3):386–397, 2022. doi: 10.1109/TBIOM.2022.3143404
-
[54]
ZhixiCai, KalinStefanov, AbhinavDhall, andMunawarHayat. DoYouReallyMeanThat? Content Driven Audio-Visual Deepfake Dataset and Multimodal Method for Temporal Forgery Localization. In2022 International Conference on Digital Image Computing: Techniques and Applications (DICTA), pages 1–10, Sydney, Australia, 2022. IEEE. doi: 10.1109/DICTA56598.2022.10034605
-
[55]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Kartik Narayan, Harsh Agarwal, Kartik Thakral, Surbhi Mittal, Mayank Vatsa, and Richa Singh. DF-Platter: Multi-Face Heterogeneous Deepfake Dataset. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9739–9748. IEEE, 2023. doi: 10.1109/CVPR52729.2023.00939
-
[56]
Deepfake-Eval-2024: A Multi-Modal In-the-Wild Benchmark of Deepfakes Circulated in 2024, 2025
Nuria Alina Chandra, Ryan Murtfeldt, Lin Qiu, Arnab Karmakar, Hannah Lee, Emmanuel Tanumihardja, Kevin Farhat, Ben Caffee, Sejin Paik, Changyeon Lee, Jongwook Choi, Aerin Kim, and Oren Etzioni. Deepfake-Eval-2024: A Multi-Modal In-the-Wild Benchmark of Deepfakes Circulated in 2024, 2025
2024
-
[57]
PolyGlotFake: A Novel Multilingual and Multimodal DeepFake Dataset, May 2024
Yang Hou, Haitao Fu, Chuankai Chen, Zida Li, Haoyu Zhang, and Jianjun Zhao. PolyGlotFake: A Novel Multilingual and Multimodal DeepFake Dataset, May 2024
2024
-
[58]
MAVOS-DD: Multilingual Audio-Video Open-Set Deepfake Detection Benchmark, May 2025
Florinel-Alin Croitoru, Vlad Hondru, Marius Popescu, Radu Tudor Ionescu, Fahad Shahbaz Khan, and Mubarak Shah. MAVOS-DD: Multilingual Audio-Video Open-Set Deepfake Detection Benchmark, May 2025
2025
-
[59]
Stefan Palan and Christian Schitter. Prolific.ac—A Subject Pool For Online Experiments.Journal of Behavioral and Experimental Finance, 17:22–27, 2018. ISSN 2214-6350. doi: 10.1016/j.jbef.2 017.12.004
-
[60]
Crowd_Frame: A Simple and Complete Framework to Deploy Complex Crowdsourcing Tasks Off-the-shelf
Michael Soprano, Kevin Roitero, Francesco Bombassei De Bona, and Stefano Mizzaro. Crowd_Frame: A Simple and Complete Framework to Deploy Complex Crowdsourcing Tasks Off-the-shelf. InProceedings of the Fifteenth ACM International Conference on Web Search and DataMining,WSDM’22,pages1605–1608,NewYork,NY,USA,2022.AssociationforComputing Machinery. ISBN 97814...
-
[61]
L. S. Penrose. The Elementary Statistics of Majority Voting.Journal of the Royal Statistical Society, 109(1):53–57, 1946. ISSN 09528385. doi: 10.1111/j.2397-2335.1946.tb04638.x
-
[62]
Cox, Nataša Milić-Frayling, Gabriella Kazai, and Vishwa Vinay
Mehdi Hosseini, Ingemar J. Cox, Nataša Milić-Frayling, Gabriella Kazai, and Vishwa Vinay. On AggregatingLabelsfromMultipleCrowdWorkerstoInferRelevanceofDocuments. InAdvancesin Information Retrieval, pages 182–194, Berlin, Heidelberg, 2012. Springer Berlin Heidelberg. ISBN 978-3-642-28997-2. doi: 10.1007/978-3-642-28997-2_16
-
[63]
Arthur P. Dempster. Upper and Lower Probabilities Induced by a Multivalued Mapping.The Annals of Mathematical Statistics, 38(2):325–339, 1967. doi: 10.1214/aoms/1177698950
-
[64]
(1976).A Mathematical Theory of Evidence
Glenn Shafer.A Mathematical Theory of Evidence. Princeton University Press, Princeton, NJ, 1976. ISBN 9780691100425. doi: 10.1515/9780691214696
-
[65]
ConstanceThierry,ArnaudMartin,Jean-ChristopheDubois,andYolandeLeGall. Estimationofthe Qualification and Behavior of a Contributor and Aggregation of His Answers in a Crowdsourcing Context.Expert Systems with Applications, 216:119496, 2023. doi: 10.1016/j.eswa.2022.119496. 19
-
[66]
A Gold Standards-Based Crowd Label Aggregation Within the Belief Function Theory
Lina Abassi and Imen Boukhris. A Gold Standards-Based Crowd Label Aggregation Within the Belief Function Theory. InAdvances in Artificial Intelligence: From Theory to Practice - 30th International Conference on Industrial Engineering and Other Applications of Applied Intelligent Systems (IEA/AIE 2017), volume 10351 ofLecture Notes in Computer Science, pag...
-
[67]
The Transferable Belief Model.Artificial Intelligence, 66(2): 191–234, 1994
Philippe Smets and Robert Kennes. The Transferable Belief Model.Artificial Intelligence, 66(2): 191–234, 1994. doi: 10.1016/0004-3702(94)90026-4
-
[68]
Crowdsourcing Truthfulness: The Impact of Judgment Scale and Assessor Bias
David La Barbera, Kevin Roitero, Gianluca Demartini, Stefano Mizzaro, and Damiano Spina. Crowdsourcing Truthfulness: The Impact of Judgment Scale and Assessor Bias. InAdvances in Information Retrieval: 42nd European Conference on IR Research, ECIR 2020, Lisbon, Portugal, April 14–17, 2020, Proceedings, Part II, pages 207–214, Berlin, Heidelberg, 2020. Spr...
-
[69]
Computing Krippendorff’s Alpha-Reliability
Klaus Krippendorff. Computing Krippendorff’s Alpha-Reliability. Technical Report 2011-1, University of Pennsylvania, Annenberg School for Communication, 2011. URLhttps://reposi tory.upenn.edu/asc_papers/43
2011
-
[70]
Considering Assessor Agreement in IR Evaluation
Eddy Maddalena, Kevin Roitero, Gianluca Demartini, and Stefano Mizzaro. Considering Assessor Agreement in IR Evaluation. InProceedings of the ACM SIGIR International Conference on Theory of Information Retrieval, ICTIR ’17, pages 75–82, New York, NY, USA, 2017. Association for Computing Machinery. ISBN 9781450344906. doi: 10.1145/3121050.3121060
-
[71]
The Annals of Mathematical Statistics , author =
Henry B. Mann and Donald R. Whitney. On a Test of Whether one of Two Random Variables is Stochastically Larger than the Other.The Annals of Mathematical Statistics, 18(1):50–60, 1947. doi: 10.1214/aoms/1177730491
-
[72]
Psychometrika12(2), 153–157 (1947)https://doi
Quinn McNemar. Note on the Sampling Error of the Difference Between Correlated Proportions or Percentages.Psychometrika, 12(2):153–157, 1947. doi: 10.1007/BF02295996
-
[73]
WilliamH.KruskalandW.AllenWallis. UseofRanksinOne-CriterionVarianceAnalysis.Journal of the American Statistical Association, 47(260):583–621, 1952. doi: 10.1080/01621459.1952.1048 3441
-
[74]
J. Martin Bland and Douglas G. Altman. Multiple Significance Tests: The Bonferroni Method. BMJ, 310(6973):170, 1995. doi: 10.1136/bmj.310.6973.170
-
[75]
Sture Holm. A Simple Sequentially Rejective Multiple Test Procedure.Scandinavian Journal of Statistics, 6(2):65–70, 1979. URLhttps://www.jstor.org/stable/4615733
-
[76]
Norman Cliff. Dominance Statistics: Ordinal Analyses to Answer Ordinal Questions.Psychological Bulletin, 114(3):494–509, 1993. doi: 10.1037/0033-2909.114.3.494
-
[77]
Chapman and Hall/CRC, New York (1994)
Bradley Efron and Robert J. Tibshirani.An Introduction to the Bootstrap. Chapman & Hall/CRC, New York, 1993. doi: 10.1201/9780429246593
-
[78]
Lei Han, Kevin Roitero, Ujwal Gadiraju, Cristina Sarasua, Alessandro Checco, Eddy Maddalena, and Gianluca Demartini. The Impact of Task Abandonment in Crowdsourcing.IEEE Transactions on Knowledge & Data Engineering, 33(5):2266–2279, 2021. ISSN 1558-2191. doi: 10.1109/TK DE.2019.2948168
work page doi:10.1109/tk 2021
-
[79]
How Many Crowd Workers Do I Need? On Statistical Power when Crowdsourcing Relevance Judgments.ACM Transactions on Information Systems, 42(1):1–26, 2023
Kevin Roitero, David La Barbera, Michael Soprano, Gianluca Demartini, Stefano Mizzaro, and Tetsuya Sakai. How Many Crowd Workers Do I Need? On Statistical Power when Crowdsourcing Relevance Judgments.ACM Transactions on Information Systems, 42(1):1–26, 2023. doi: 10.1145/ 3597201. 20
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.