Recognition: unknown
Tree-based Credit Assignment for Multi-Agent Memory System
Pith reviewed 2026-05-08 15:35 UTC · model grok-4.3
The pith
Tree expansion turns one final reward into specific credit signals for each agent in a memory pipeline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
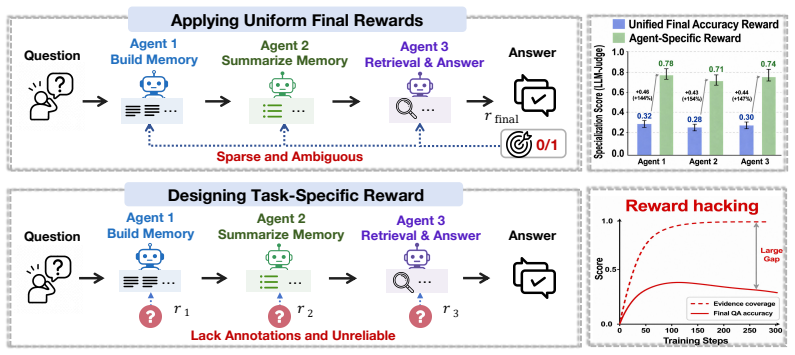
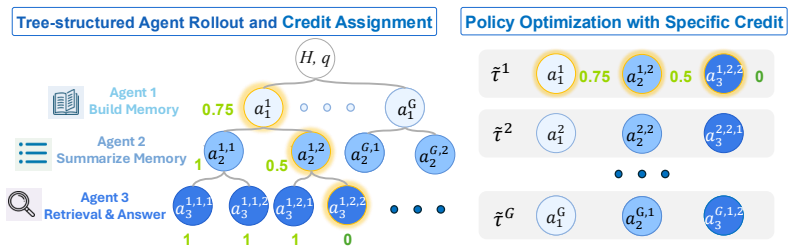
TreeMem extends the multi-agent pipeline into a tree structure where each agent's outputs are expanded into multiple subsequent branches; the contribution of each agent is estimated via Monte Carlo averaging over its subsequent branches, which converts the coarse final reward into agent-specific optimization signals that update all policies simultaneously.
What carries the argument
The tree-structured credit assignment that expands each agent's output into multiple branches and isolates its contribution through Monte Carlo averaging of final rewards across those branches.
If this is right
- All agents receive tailored optimization signals and can specialize without task-specific reward engineering.
- The memory system improves accuracy on long-horizon QA and similar benchmarks compared with uniform-reward training.
- Training requires only the final downstream reward, eliminating the need for annotations such as key evidence.
- Heterogeneous agents update their policies simultaneously using the same reward source.
Where Pith is reading between the lines
- The same branching-plus-averaging pattern could be applied to other multi-step agent pipelines that lack intermediate supervision.
- Computational cost of branching may limit depth, suggesting future work on adaptive or shared sampling across branches.
- The method implicitly treats branches as counterfactual rollouts, linking it to causal estimation techniques in reinforcement learning.
Load-bearing premise
That expanding each agent's outputs into multiple subsequent branches and averaging the final rewards over them accurately captures the causal contribution of that agent without bias introduced by the branching or sampling process.
What would settle it
An experiment in which agents trained under TreeMem show no performance improvement over uniform-reward baselines on tasks where the causal impact of specific intermediate actions can be directly measured.
Figures

read the original abstract
Memory systems are widely adopted to enhance LLMs for long-horizon tasks, and are commonly organized as multi-agent pipelines with memory building, summarizing, and retrieval agents. To empower this system, existing RL-based methods either apply final downstream task rewards (e.g., QA accuracy) for all agents uniformly, which are coarse and ambiguous, or design task-specific rewards for agents on different subtasks, which require costly annotations (e.g., key evidence) and are difficult to define reliably. To address these limitations, we propose Tree-based Credit Assignment for Multi-Agent Memory Systems (TreeMem), which derives agent-specific credit from the final reward without task-specific annotations. Specifically, TreeMem extends the multi-agent pipeline (builder--summarizer--retrieval) into a tree structure, where each agent's outputs are expanded into multiple subsequent branches. The contribution of each agent is estimated via Monte Carlo averaging over its subsequent branches, capturing how intermediate agent actions may influence the final reward. This converts the coarse final reward into agent-specific optimization signals. These signals are then used to update all agent policies simultaneously, helping heterogeneous agents specialize effectively. Experiments on long-horizon benchmarks show that TreeMem improves memory system performance over strong baselines, validating the effectiveness of tree-structured credit assignment for the multi-agent memory system.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TreeMem, a method for credit assignment in multi-agent LLM memory systems (builder-summarizer-retrieval pipeline). It extends the pipeline into a tree by expanding each agent's outputs into multiple subsequent branches and estimates each agent's contribution to the final task reward via Monte Carlo averaging over those branches. These agent-specific signals are then used to update all policies simultaneously, avoiding the need for task-specific annotations. The abstract asserts that this yields better performance on long-horizon benchmarks compared to strong baselines.
Significance. If the Monte Carlo estimator reliably isolates causal contributions without bias, TreeMem would provide a general, annotation-free approach to credit assignment in heterogeneous multi-agent LLM pipelines, potentially enabling more effective specialization for long-horizon tasks. The tree-structured application of standard RL Monte Carlo ideas to memory systems could influence training methods in multi-agent LLM setups, though the practical impact hinges on empirical validation and estimator properties.
major comments (2)
- [Method] The method description provides no derivation or analysis showing that Monte Carlo averaging over branches produces an unbiased estimate of an agent's marginal contribution when all downstream policies are updated simultaneously; correlations between upstream outputs and downstream sampling (via shared context or policy gradients) could bias the estimator, directly undermining the central claim of reliable agent-specific signals from the final reward alone.
- [Experiments] The experiments section asserts benchmark improvements but supplies no details on the number of runs, error bars, ablation studies on branch count, or specific baselines and metrics; without these, the empirical support for the tree-based credit assignment cannot be assessed, especially given the variance concerns inherent to finite Monte Carlo sampling.
minor comments (1)
- [Abstract] The abstract refers to 'long-horizon benchmarks' without naming them or providing even high-level performance numbers, which reduces the ability to contextualize the claimed gains.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive feedback on our paper. We address the major comments below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Method] The method description provides no derivation or analysis showing that Monte Carlo averaging over branches produces an unbiased estimate of an agent's marginal contribution when all downstream policies are updated simultaneously; correlations between upstream outputs and downstream sampling (via shared context or policy gradients) could bias the estimator, directly undermining the central claim of reliable agent-specific signals from the final reward alone.
Authors: We acknowledge that the original manuscript does not include a formal derivation or bias analysis for the Monte Carlo estimator. The TreeMem approach applies standard Monte Carlo ideas from RL to the tree-structured memory pipeline, with the intention that averaging over branches provides an estimate of each agent's contribution. However, we agree that simultaneous updates can introduce correlations, and the estimator may not be strictly unbiased. In the revised manuscript, we will add a new subsection under the method that discusses the estimator's properties, including potential sources of bias and why the tree expansion still provides useful agent-specific signals in practice. We will also clarify that the method offers a practical approximation for credit assignment rather than a theoretically unbiased one. revision: yes
-
Referee: [Experiments] The experiments section asserts benchmark improvements but supplies no details on the number of runs, error bars, ablation studies on branch count, or specific baselines and metrics; without these, the empirical support for the tree-based credit assignment cannot be assessed, especially given the variance concerns inherent to finite Monte Carlo sampling.
Authors: We agree with the referee that additional experimental details are necessary for a thorough evaluation. The submitted manuscript's experiments section was abbreviated due to space constraints, but we have the required data from our runs. In the revised version, we will expand the experiments section to include: the number of independent runs (5 runs with different random seeds), error bars showing mean and standard deviation, ablation studies on the number of branches (testing 2, 4, and 8 branches per agent), and detailed descriptions of the baselines (uniform reward assignment, task-specific reward baselines) and metrics (task accuracy, memory efficiency). This will better substantiate the empirical claims and address concerns about Monte Carlo variance. revision: yes
Circularity Check
No significant circularity; TreeMem applies standard Monte Carlo credit assignment to a tree-structured pipeline.
full rationale
The paper's core mechanism extends the multi-agent pipeline into a tree and estimates each agent's contribution by averaging final rewards over multiple downstream branches. This is an application of the well-established Monte Carlo estimator from reinforcement learning for expected return, which is externally defined and does not reduce to a self-referential definition, fitted parameter renamed as prediction, or self-citation chain within the paper. No equations or claims in the abstract equate the output signal to the input reward by construction, nor do they import uniqueness theorems or ansatzes from the authors' prior work. The derivation remains self-contained against external RL benchmarks, yielding an independent (if variance-sensitive) signal for policy updates.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Monte Carlo averaging over expanded branches provides an accurate estimate of each agent's contribution to the final reward
Reference graph
Works this paper leans on
-
[1]
Memory in the Age of AI Agents
Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, et al. Memory in the age of ai agents.arXiv preprint arXiv:2512.13564, 2025
work page internal anchor Pith review arXiv 2025
-
[2]
Memorybank: Enhancing large language models with long-term memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory. InAAAI, pages 19724–19731. AAAI Press, 2024
2024
-
[3]
Hipporag: Neurobiologically inspired long-term memory for large language models
Bernal Jimenez Gutierrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. Hipporag: Neurobiologically inspired long-term memory for large language models. InNeurIPS, 2024
2024
-
[4]
Pan, Yuxin Jiang, and Kam-Fai Wong
Yiming Du, Baojun Wang, Yifan Xiang, Zhaowei Wang, Wenyu Huang, Boyang XUE, Bin Liang, Xingshan Zeng, Fei Mi, Haoli Bai, Lifeng Shang, Jeff Z. Pan, Yuxin Jiang, and Kam-Fai Wong. Memory-t1: Reinforcement learning for temporal reasoning in multi-session agents. In ICLR, 2026
2026
-
[5]
Lightmem: Lightweight and efficient memory-augmented generation
Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, Huajun Chen, and Ningyu Zhang. Lightmem: Lightweight and efficient memory-augmented generation. InICLR, 2026
2026
-
[6]
Assomem: Scalable memory QA with multi-signal associative retrieval
Kai Zhang, Xinyuan Zhang, Ejaz Ahmed, Hongda Jiang, Caleb Kumar, Kai Sun, Zhaojiang Lin, Sanat Sharma, Shereen Oraby, AARON COLAK, Ahmed A Aly, Anuj Kumar, Xiaozhong Liu, and Xin Luna Dong. Assomem: Scalable memory QA with multi-signal associative retrieval. InICLR, 2026
2026
-
[7]
Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large language model
Mengkang Hu, Tianxing Chen, Qiguang Chen, Yao Mu, Wenqi Shao, and Ping Luo. Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large language model. InACL (1), pages 32779–32798. Association for Computational Linguistics, 2025
2025
-
[8]
MEM1: Learning to synergize memory and reasoning for efficient long-horizon agents
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low, and Paul Pu Liang. MEM1: Learning to synergize memory and reasoning for efficient long-horizon agents. InICLR, 2026
2026
-
[9]
Reasoningbank: Scaling agent self-evolving with reasoning memory
Siru Ouyang, Jun Yan, I-Hung Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long Le, Samira Daruki, Xiangru Tang, Vishy Tirumalashetty, George Lee, Mahsan Rofouei, Hangfei Lin, Jiawei Han, Chen-Yu Lee, and Tomas Pfister. Reasoningbank: Scaling agent self-evolving with reasoning memory. InICLR, 2026
2026
-
[10]
REMem: Reasoning with episodic memory in language agent
Yiheng Shu, Saisri Padmaja Jonnalagedda, Xiang Gao, Bernal Jiménez Gutiérrez, Weijian Qi, Kamalika Das, Huan Sun, and Yu Su. REMem: Reasoning with episodic memory in language agent. InICLR, 2026
2026
-
[11]
General agentic memory via deep research.arXiv preprint arXiv:2511.18423, 2025
BY Yan, Chaofan Li, Hongjin Qian, Shuqi Lu, and Zheng Liu. General agentic memory via deep research.arXiv preprint arXiv:2511.18423, 2025
-
[12]
MIRIX: Multi-Agent Memory System for LLM-Based Agents
Yu Wang and Xi Chen. MIRIX: multi-agent memory system for llm-based agents.CoRR, abs/2507.07957, 2025
work page internal anchor Pith review arXiv 2025
-
[13]
A-mem: Agentic memory for LLM agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for LLM agents. InNeurIPS, 2025
2025
-
[14]
Memagent: Reshaping long-context LLM with multi-conv RL-based memory agent
Hongli Yu, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, Weinan Dai, Qiying Yu, Ya-Qin Zhang, Wei-Ying Ma, Jingjing Liu, Mingxuan Wang, and Hao Zhou. Memagent: Reshaping long-context LLM with multi-conv RL-based memory agent. InICLR, 2026. 10
2026
-
[15]
Memgen: Weaving generative latent memory for self-evolving agents
Guibin Zhang, Muxin Fu, and Shuicheng Y AN. Memgen: Weaving generative latent memory for self-evolving agents. InICLR, 2026
2026
-
[16]
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Hinrich Schütze, V olker Tresp, and Yunpu Ma. Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning.CoRR, abs/2508.19828, 2025
work page internal anchor Pith review arXiv 2025
-
[17]
Yu Wang, Ryuichi Takanobu, Zhiqi Liang, Yuzhen Mao, Yuanzhe Hu, Julian McAuley, and Xiaojian Wu. Mem-{\alpha}: Learning memory construction via reinforcement learning.arXiv preprint arXiv:2509.25911, 2025
-
[18]
Joint Optimization of Multi-agent Memory System
Wenyu Mao, Haoyang Liu, Zhao Liu, Haosong Tan, Yaorui Shi, Jiancan Wu, An Zhang, and Xiang Wang. Collaborative multi-agent optimization for personalized memory system.CoRR, abs/2603.12631, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Joar Skalse, Nikolaus H. R. Howe, Dmitrii Krasheninnikov, and David Krueger. Defining and characterizing reward gaming. InNeurIPS, 2022
2022
-
[20]
CoMAS: Co-evolving multi-agent systems via interaction rewards
Xiangyuan Xue, Yifan Zhou, Guibin Zhang, Zaibin Zhang, Yijiang Li, Chen Zhang, Zhenfei Yin, Philip Torr, Wanli Ouyang, and LEI BAI. CoMAS: Co-evolving multi-agent systems via interaction rewards. InICLR, 2026
2026
-
[21]
MARSHAL: Incentivizing multi-agent reasoning via self-play with strategic LLMs
Huining Yuan, Zelai Xu, Zheyue Tan, Xiangmin Yi, Mo Guang, Kaiwen Long, Haojia Hui, Boxun Li, Xinlei Chen, Bo Zhao, Xiao-Ping Zhang, Chao Yu, and Yu Wang. MARSHAL: Incentivizing multi-agent reasoning via self-play with strategic LLMs. InICLR, 2026
2026
-
[22]
Stepleton, Nicolas Heess, Arthur Guez, Eric Moulines, Marcus Hutter, Lars Buesing, and Remi Munos
Thomas Mesnard, Theophane Weber, Fabio Viola, Shantanu Thakoor, Alaa Saade, Anna Harutyunyan, Will Dabney, Thomas S. Stepleton, Nicolas Heess, Arthur Guez, Eric Moulines, Marcus Hutter, Lars Buesing, and Remi Munos. Counterfactual credit assignment in model-free reinforcement learning. InICML, 2021
2021
-
[23]
Daw, and Gregory Wayne
Alexander Meulemans, Simon Schug, Seijin Kobayashi, Nathaniel D. Daw, and Gregory Wayne. Would i have gotten that reward? long-term credit assignment by counterfactual contribution analysis. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[24]
MARTI: A framework for multi-agent LLM systems reinforced training and inference
Kaiyan Zhang, Kai Tian, Runze Liu, Sihang Zeng, Xuekai Zhu, Guoli Jia, Yuchen Fan, Xingtai Lv, Yuxin Zuo, Che Jiang, Yuru wang, Jianyu Wang, Ermo Hua, Xinwei Long, Junqi Gao, Youbang Sun, Zhiyuan Ma, Ganqu Cui, Ning Ding, Biqing Qi, and Bowen Zhou. MARTI: A framework for multi-agent LLM systems reinforced training and inference. InICLR, 2026
2026
-
[25]
Lang Feng, Longtao Zheng, Shuo He, Fuxiang Zhang, and Bo An. Dr. MAS: Stable reinforce- ment learning for multi-agent LLM systems. InWorkshop on Multi-Agent Learning and Its Opportunities in the Era of Generative AI, 2026
2026
-
[26]
MALT: Improving reasoning with multi-agent LLM training
Sumeet Ramesh Motwani, Chandler Smith, Rocktim Jyoti Das, Rafael Rafailov, Philip Torr, Ivan Laptev, Fabio Pizzati, Ronald Clark, and Christian Schroeder de Witt. MALT: Improving reasoning with multi-agent LLM training. InSecond Conference on Language Modeling, 2025
2025
-
[27]
Stronger-MAS: Multi-agent reinforcement learning for collaborative LLMs
Yujie Zhao, Lanxiang Hu, Yang Wang, Minmin Hou, Hao Zhang, Ke Ding, and Jishen Zhao. Stronger-MAS: Multi-agent reinforcement learning for collaborative LLMs. InICLR, 2026
2026
-
[28]
Haoyang Hong, Jiajun Yin, Yuan Wang, Jingnan Liu, Zhe Chen, Ailing Yu, Ji Li, Zhiling Ye, Hansong Xiao, Yefei Chen, et al. Multi-agent deep research: Training multi-agent systems with m-grpo.arXiv preprint arXiv:2511.13288, 2025
-
[29]
Ozdaglar, Kaiqing Zhang, and Joo- Kyung Kim
Chanwoo Park, Seungju Han, Xingzhi Guo, Asuman E. Ozdaglar, Kaiqing Zhang, and Joo- Kyung Kim. Maporl: Multi-agent post-co-training for collaborative large language models with reinforcement learning. InACL (1), pages 30215–30248. Association for Computational Linguistics, 2025
2025
-
[30]
MARFT: multi-agent reinforcement fine-tuning.CoRR, abs/2504.16129, 2025
Junwei Liao, Muning Wen, Jun Wang, and Weinan Zhang. MARFT: multi-agent reinforcement fine-tuning.CoRR, abs/2504.16129, 2025. 11
-
[31]
ReMA: Learning to meta-think for LLMs with multi-agent reinforcement learning
Ziyu Wan, Yunxiang LI, Xiaoyu Wen, Yan Song, Hanjing Wang, Linyi Yang, Mark Schmidt, Jun Wang, Weinan Zhang, Shuyue Hu, and Ying Wen. ReMA: Learning to meta-think for LLMs with multi-agent reinforcement learning. InNeurIPS, 2026
2026
-
[32]
arXiv preprint arXiv:2508.17445 , year=
Yizhi Li, Qingshui Gu, Zhoufutu Wen, Ziniu Li, Tianshun Xing, Shuyue Guo, Tianyu Zheng, Xin Zhou, Xingwei Qu, Wangchunshu Zhou, Zheng Zhang, Wei Shen, Qian Liu, Chenghua Lin, Jian Yang, Ge Zhang, and Wenhao Huang. Treepo: Bridging the gap of policy optimization and efficacy and inference efficiency with heuristic tree-based modeling.CoRR, abs/2508.17445, 2025
-
[33]
Tree search for llm agent reinforcement learning, 2026
Yuxiang Ji, Ziyu Ma, Yong Wang, Guanhua Chen, Xiangxiang Chu, and Liaoni Wu. Tree search for LLM agent reinforcement learning.CoRR, abs/2509.21240, 2025
-
[34]
TreeRL: LLM reinforcement learning with on-policy tree search
Zhenyu Hou, Ziniu Hu, Yujiang Li, Rui Lu, Jie Tang, and Yuxiao Dong. TreeRL: LLM reinforcement learning with on-policy tree search. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 12355–12369, Vien...
2025
-
[35]
Agentrm: Enhancing agent generalization with reward modeling
Yu Xia, Jingru Fan, Weize Chen, Siyu Yan, Xin Cong, Zhong Zhang, Yaxi Lu, Yankai Lin, Zhiyuan Liu, and Maosong Sun. Agentrm: Enhancing agent generalization with reward modeling. InACL (1), pages 19277–19290. Association for Computational Linguistics, 2025
2025
-
[36]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.CoRR, abs/2402.03300, 2024
work page internal anchor Pith review arXiv 2024
-
[37]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InNeurIPS, 2020
2020
-
[38]
CAM: A constructivist view of agentic memory for LLM-based reading comprehension
Rui Li, Zeyu Zhang, Xiaohe Bo, Zihang Tian, Xu Chen, Quanyu Dai, Zhenhua Dong, and Ruiming Tang. CAM: A constructivist view of agentic memory for LLM-based reading comprehension. InNeurIPS, 2025
2025
-
[39]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review arXiv 2025
-
[40]
Know me, respond to me: Benchmarking LLMs for dynamic user profiling and personalized responses at scale
Bowen Jiang, Zhuoqun Hao, Young Min Cho, Bryan Li, Yuan Yuan, Sihao Chen, Lyle Ungar, Camillo Jose Taylor, and Dan Roth. Know me, respond to me: Benchmarking LLMs for dynamic user profiling and personalized responses at scale. InSecond Conference on Language Modeling, 2025
2025
-
[41]
Long- memeval: Benchmarking chat assistants on long-term interactive memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- memeval: Benchmarking chat assistants on long-term interactive memory. InICLR. OpenRe- view.net, 2025
2025
-
[42]
Evaluating very long-term conversational memory of LLM agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents. InACL (1), pages 13851–13870. Association for Computational Linguistics, 2024
2024
-
[43]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review arXiv 2025
-
[44]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurélien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models.CoRR, abs/2302.13971, 2023. 12 A Details of Experimental Settings A.1 ...
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.