Recognition: unknown
StoryAlign: Evaluating and Training Reward Models for Story Generation
Pith reviewed 2026-05-08 17:26 UTC · model grok-4.3
The pith
A reward model trained on 100,000 story preference pairs outperforms larger models at selecting human-preferred narratives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that StoryReward, trained on roughly 100,000 high-quality story preference pairs across diverse domains, achieves state-of-the-art performance on the StoryRMB benchmark and outperforms much larger models. Existing reward models reach at most 66.3 percent accuracy when asked to select the human-preferred story. When StoryReward is used for best-of-n selection at test time, it generally produces stories better aligned with human preferences than alternatives.
What carries the argument
StoryRMB benchmark of 1,133 human-verified instances, each with a prompt, one chosen story, and three rejected stories, together with the 100,000 constructed preference pairs used to train the StoryReward model that scores stories according to learned human preferences.
If this is right
- StoryReward improves best-of-n story selection so that the chosen output more often matches human judgments.
- Specialized training on preference pairs allows a smaller model to surpass larger general-purpose reward models on narrative tasks.
- Release of the benchmark, model, and code enables other researchers to test and extend story preference alignment.
Where Pith is reading between the lines
- The same preference-pair training method could be applied to other creative text tasks such as script or poetry generation.
- Expanding StoryRMB with stories from additional cultures or styles would test whether the current preferences generalize.
- Domain-specific reward models may prove more data-efficient than scaling general models for creative alignment.
Load-bearing premise
The 1,133 human-verified instances and the 100,000 constructed preference pairs accurately capture general human story preferences across domains.
What would settle it
A new human-annotated test set of story preferences drawn from domains absent from the training pairs, on which StoryReward fails to exceed the accuracy of larger general reward models or simple baselines.
Figures



read the original abstract
Story generation aims to automatically produce coherent, structured, and engaging narratives. Although large language models (LLMs) have significantly advanced text generation, stories generated by LLMs still diverge from human-authored works regarding complex narrative structure and human-aligned preferences. A key reason is the absence of effective modeling of human story preferences, which are inherently subjective and under-explored. In this work, we systematically evaluate the modeling of human story preferences and introduce StoryRMB, the first benchmark for assessing reward models on story preferences. StoryRMB contains $1,133$ high-quality, human-verified instances, each consisting of a prompt, one chosen story, and three rejected stories. We find existing reward models struggle to select human-preferred stories, with the best model achieving only $66.3\%$ accuracy. To address this limitation, we construct roughly $100,000$ high-quality story preference pairs across diverse domains and develop StoryReward, an advanced reward model for story preference trained on this dataset. StoryReward achieves state-of-the-art (SoTA) performance on StoryRMB, outperforming much larger models. We also adopt StoryReward in downstream test-time scaling applications for best-of-n (BoN) story selection and find that it generally chooses stories better aligned with human preferences. We will release our dataset, model, and code to facilitate future research. Related code and data are available at https://github.com/THU-KEG/StoryReward.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces StoryRMB, the first benchmark for assessing reward models on story preferences, consisting of 1,133 human-verified instances each containing a prompt, one chosen story, and three rejected stories. Existing reward models are shown to achieve at most 66.3% accuracy on this benchmark. The authors construct roughly 100,000 story preference pairs across diverse domains, train the StoryReward model on these pairs, and report that it achieves state-of-the-art performance on StoryRMB while outperforming much larger models. StoryReward is further applied to best-of-n selection in story generation, where it selects stories better aligned with human preferences. The dataset, model, and code are promised for release.
Significance. If the StoryRMB benchmark reliably captures human story preferences, the work fills a notable gap by providing the first dedicated evaluation resource for story reward modeling and demonstrates that a modestly sized model trained on constructed preference data can surpass much larger general-purpose models. The downstream use in test-time scaling offers a concrete application. Releasing the data and code would strengthen reproducibility and enable follow-on research.
major comments (2)
- [Abstract] Abstract: The headline SoTA claim for StoryReward on StoryRMB is load-bearing on the assumption that the 1,133 human-verified instances constitute a faithful, general test of story preferences. The abstract asserts 'high-quality, human-verified' status and 'diverse domains' but supplies no inter-annotator agreement statistics, annotation protocol, domain distribution, or external validation against other preference sources. Without these, it remains possible that outperformance reflects exploitation of benchmark artifacts (e.g., length, coherence heuristics, or model-specific flaws in the rejected stories) rather than superior preference modeling.
- [Evaluation/results sections] Evaluation and results sections: Accuracy figures (66.3% for the best baseline, SoTA for StoryReward) are reported without statistical significance tests, confidence intervals, or details on the exact scoring procedure (pairwise vs. top-1 among four options). This makes it impossible to determine whether the reported gains are robust or could be explained by variance in the small test set.
minor comments (2)
- [Title/Abstract] The paper title refers to 'StoryAlign' while the abstract and contributions center on 'StoryRMB' and 'StoryReward'; ensure consistent naming throughout.
- [Dataset construction section] The construction process for the ~100k training pairs should include explicit details on generation methods, filtering heuristics, and any models used, to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and have revised the manuscript to improve clarity and rigor where appropriate.
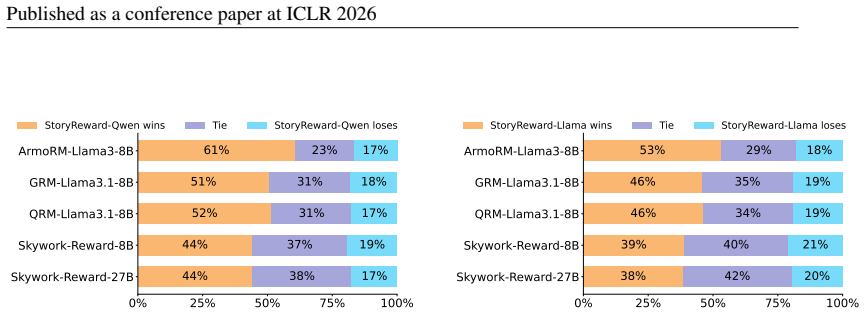
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline SoTA claim for StoryReward on StoryRMB is load-bearing on the assumption that the 1,133 human-verified instances constitute a faithful, general test of story preferences. The abstract asserts 'high-quality, human-verified' status and 'diverse domains' but supplies no inter-annotator agreement statistics, annotation protocol, domain distribution, or external validation against other preference sources. Without these, it remains possible that outperformance reflects exploitation of benchmark artifacts (e.g., length, coherence heuristics, or model-specific flaws in the rejected stories) rather than superior preference modeling.
Authors: We agree that the abstract should better substantiate the benchmark's quality. Section 3.2 of the original manuscript already details the annotation protocol (three annotators per instance with majority vote for chosen/rejected labels), domain distribution across 12 story genres, and inter-annotator agreement (Fleiss' kappa of 0.71). We have revised the abstract to explicitly reference these elements and added a sentence noting the human verification process. To address potential artifacts, the revised paper includes new ablation studies demonstrating that StoryReward's gains persist after controlling for length, coherence scores, and model-specific biases in the rejected stories. External validation against other preference datasets was not performed, as constructing StoryRMB was the primary focus, but we believe the multi-annotator verification provides sufficient grounding. revision: partial
-
Referee: [Evaluation/results sections] Evaluation and results sections: Accuracy figures (66.3% for the best baseline, SoTA for StoryReward) are reported without statistical significance tests, confidence intervals, or details on the exact scoring procedure (pairwise vs. top-1 among four options). This makes it impossible to determine whether the reported gains are robust or could be explained by variance in the small test set.
Authors: We concur that statistical rigor is necessary given the test set size. The revised manuscript now reports 95% bootstrap confidence intervals for all accuracy figures and includes paired statistical tests confirming StoryReward's improvements are significant (p < 0.01). We have also clarified the scoring procedure in Section 4: accuracy is measured as top-1 selection accuracy, i.e., the fraction of instances where the model assigns the highest reward to the single chosen story among the four candidates. These additions directly address concerns about variance and interpretability of the results. revision: yes
Circularity Check
No circularity: benchmark and training data are independently constructed and held-out.
full rationale
The paper introduces StoryRMB as a new human-verified benchmark (1,133 instances) and separately constructs ~100k preference pairs for training StoryReward. The central result is an empirical accuracy measurement of the trained model on the held-out benchmark, with no equations, fitted parameters, or self-citations that reduce the reported SoTA performance to a tautology or redefinition of the inputs. The derivation chain (data collection → training → evaluation) remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human story preferences can be modeled effectively via pairwise chosen/rejected story data.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2309.16609. Heather Barber and Daniel Kudenko. Generation of dilemma-based narratives: Method and turing test evaluation. In Ulrike Spierling and Nicolas Szilas (eds.),Interactive Storytelling, pp. 214–217, Berlin, Heidelberg,
work page internal anchor Pith review arXiv
-
[2]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Springer Berlin Heidelberg. ISBN 978-3-540-89454-4. Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787,
work page internal anchor Pith review arXiv
-
[3]
Internlm2 technical report,
Zheng Cai, Maosong Cao, Haojiong Chen, Kai Chen, Keyu Chen, Xin Chen, Xun Chen, Zehui Chen, Zhi Chen, Pei Chu, Xiaoyi Dong, Haodong Duan, Qi Fan, Zhaoye Fei, Yang Gao, Jiaye Ge, Chenya Gu, Yuzhe Gu, Tao Gui, Aijia Guo, Qipeng Guo, Conghui He, Yingfan Hu, Ting Huang, Tao Jiang, Penglong Jiao, Zhenjiang Jin, Zhikai Lei, Jiaxing Li, Jingwen Li, Linyang Li, S...
2026
-
[4]
URLhttps://arxiv.org/abs/2403.17297. Tuhin Chakrabarty, Philippe Laban, Divyansh Agarwal, Smaranda Muresan, and Chien-Sheng Wu. Art or artifice? large language models and the false promise of creativity,
-
[5]
Tuhin Chakrabarty, Philippe Laban, and Chien-Sheng Wu
URL https://arxiv.org/ abs/2309.14556. Tuhin Chakrabarty, Philippe Laban, and Chien-Sheng Wu. Ai-slop to ai-polish? aligning language models through edit-based writing rewards and test-time computation.arXiv preprint arXiv:2504.07532,
-
[6]
URLhttps://arxiv.org/abs/2507.06261. Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Bingxiang He, Wei Zhu, Yuan Ni, Guotong Xie, Ruobing Xie, Yankai Lin, et al. Ultrafeedback: Boosting language models with scaled ai feedback. InForty-first International Conference on Machine Learning,
work page internal anchor Pith review arXiv
-
[7]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
2026
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URL https://arxiv.org/abs/2501.12948. Nicolai Dorka. Quantile regression for distributional reward models in rlhf,
work page internal anchor Pith review arXiv
-
[9]
URL https://arxiv. org/abs/2409.10164. Angela Fan, Mike Lewis, and Yann Dauphin. Hierarchical neural story generation. In Iryna Gurevych and Yusuke Miyao (eds.),Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 889–898, Melbourne, Australia, July
-
[10]
Hierarchical neural story generation
Association for Computational Linguistics. doi: 10.18653/v1/P18-1082. URL https://aclanthology.org/ P18-1082/. Angela Fan, Mike Lewis, and Yann Dauphin. Strategies for structuring story generation. In Anna Korhonen, David Traum, and Lluís Màrquez (eds.),Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 2650–2660,...
-
[11]
Association for Computational Linguistics. doi: 10.18653/v1/P19-1254. URLhttps://aclanthology.org/P19-1254/. Daniel Fein, Sebastian Russo, Violet Xiang, Kabir Jolly, Rafael Rafailov, and Nick Haber. Litbench: A benchmark and dataset for reliable evaluation of creative writing,
-
[12]
URL https://arxiv.org/ abs/2507.00769. Jack Grieve. Quantitative authorship attribution: An evaluation of techniques.Literary and linguistic computing, 22(3):251–270,
-
[13]
URL https://arxiv.org/abs/2410.02603. Ruipeng Jia, Yunyi Yang, Yongbo Gai, Kai Luo, Shihao Huang, Jianhe Lin, Xiaoxi Jiang, and Guanjun Jiang. Writing-zero: Bridge the gap between non-verifiable tasks and verifiable rewards,
-
[14]
URL https://arxiv.org/abs/2506.00103. Slava M Katz. Distribution of content words and phrases in text and language modelling.Natural language engineering, 2(1):15–59,
-
[15]
URL http://www.jstor.org/stable/2332226
ISSN 00063444. URL http://www.jstor.org/stable/2332226. Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, Noah A. Smith, and Hannaneh Hajishirzi. Rewardbench: Evaluating reward models for language modeling,
-
[16]
arXiv preprint arXiv:2404.13919 , year =
URL https://arxiv.org/abs/ 2404.13919. 12 Published as a conference paper at ICLR 2026 Chris Yuhao Liu, Liang Zeng, Jiacai Liu, Rui Yan, Jujie He, Chaojie Wang, Shuicheng Yan, Yang Liu, and Yahui Zhou. Skywork-reward: Bag of tricks for reward modeling in llms,
-
[17]
URL https: //arxiv.org/abs/2410.18451. Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment. InProceedings of EMNLP, pp. 2511–2522,
-
[18]
URLhttps://arxiv.org/abs/2406.05690. Meta. Llama-3.1-70b-instruct. https://huggingface.co/meta-llama/Llama-3. 1-70B-Instruct, 2024a. Accessed: 2025-09-20. Meta. Llama-3.1-8b-instruct. https://huggingface.co/meta-llama/Llama-3. 1-8B-Instruct, 2024b. Released: July 23, 2024; Accessed: 2025-09-20. OpenAI. Hello gpt-4o,
-
[19]
Accessed: 2025-02-04
URL https://openai.com/index/hello-gpt-4o/. Accessed: 2025-02-04. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744,
2025
-
[20]
Samuel J Paech. Eq-bench: An emotional intelligence benchmark for large language models.arXiv preprint arXiv:2312.06281,
-
[21]
Hao Peng, Yunjia Qi, Xiaozhi Wang, Zijun Yao, Bin Xu, Lei Hou, and Juanzi Li. Agentic reward modeling: Integrating human preferences with verifiable correctness signals for reliable reward systems.arXiv preprint arXiv:2502.19328,
-
[22]
Yunjia Qi, Hao Peng, Xiaozhi Wang, Bin Xu, Lei Hou, and Juanzi Li. Constraint back-translation improves complex instruction following of large language models.arXiv preprint arXiv:2410.24175,
-
[23]
URLhttps://arxiv.org/abs/2412.15115. Alan Roberts. Rhythm in prose and the serial correlation of sentence lengths: A joyce cary case study. Literary and linguistic computing, 11(1):33–39,
work page internal anchor Pith review arXiv
-
[24]
Verbosity bias in preference labeling by large language models
Keita Saito, Akifumi Wachi, Koki Wataoka, and Youhei Akimoto. Verbosity bias in preference labeling by large language models. InNeurIPS 2023 Workshop on Instruction Tuning and Instruction Following. 5 Team, Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, Kedong Wang, Lucen Zhong, Mingda...
2023
-
[25]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
URL https://arxiv.org/abs/2508.06471. Yufei Tian, Tenghao Huang, Miri Liu, Derek Jiang, Alexander Spangher, Muhao Chen, Jonathan May, and Nanyun Peng. Are large language models capable of generating human-level narratives? InProceedings of EMNLP, pp. 17659–17681,
work page internal anchor Pith review arXiv
-
[26]
Qwenlong-l1: Towards long-context large reasoning models with reinforcement learning, 2025
Fanqi Wan, Weizhou Shen, Shengyi Liao, Yingcheng Shi, Chenliang Li, Ziyi Yang, Ji Zhang, Fei Huang, Jin- gren Zhou, and Ming Yan. Qwenlong-l1: Towards long-context large reasoning models with reinforcement learning, 2025a. URLhttps://arxiv.org/abs/2505.17667. Kaiyang Wan, Honglin Mu, Rui Hao, Haoran Luo, Tianle Gu, and Xiuying Chen. A cognitive writing pe...
-
[27]
Qianyue Wang, Jinwu Hu, Zhengping Li, Yufeng Wang, daiyuan li, Yu Hu, and Mingkui Tan
URLhttps://arxiv.org/abs/2406.00554. Qianyue Wang, Jinwu Hu, Zhengping Li, Yufeng Wang, daiyuan li, Yu Hu, and Mingkui Tan. Generating long-form story using dynamic hierarchical outlining with memory-enhancement, 2024b. URL https: //arxiv.org/abs/2412.13575. Yi Wang and Max Kreminski. Can llms generate good stories? insights and challenges from a narrativ...
-
[28]
Grok (version 2025-09-14),
xAI. Grok (version 2025-09-14),
2025
-
[29]
URLhttps://grok.x.ai. Large language model. Haotian Xia, Hao Peng, Yunjia Qi, Xiaozhi Wang, Bin Xu, Lei Hou, and Juanzi Li. Storywriter: A multi-agent framework for long story generation.arXiv preprint arXiv:2506.16445,
-
[30]
Lillicrap, Kenji Kawaguchi, and Michael Shieh
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P Lillicrap, Kenji Kawaguchi, and Michael Shieh. Monte carlo tree search boosts reasoning via iterative preference learning.arXiv preprint arXiv:2405.00451,
-
[31]
Qwen3 technical report,
14 Published as a conference paper at ICLR 2026 An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou...
2026
-
[32]
URL https://arxiv.org/abs/2505.09388. Dingyi Yang and Qin Jin. What makes a good story and how can we measure it? a comprehensive survey of story evaluation.arXiv preprint arXiv:2408.14622,
work page internal anchor Pith review arXiv
-
[33]
Jialun Zhong, Wei Shen, Yanzeng Li, Songyang Gao, Hua Lu, Yicheng Chen, Yang Zhang, Wei Zhou, Jinjie Gu, and Lei Zou. A comprehensive survey of reward models: Taxonomy, applications, challenges, and future.arXiv preprint arXiv:2504.12328,
-
[34]
a scientist proposes a theorem proving that free will is an illusion and faces backlash from multiple sides
15 Published as a conference paper at ICLR 2026 APPENDICES A PREMISEGENERATIONDETAILS We curated a diverse set of seed premises spanning multiple thematic domains. To avoid redundancy and maintain structural coherence, we introduced a thematic classification framework informed by motifs from literature, philosophy, and film. The framework organizes premis...
2026
-
[35]
vs DeepSeek-R1- Distill-Llama-70B (DeepSeek-AI et al., 2025), and Qwen2.5-14B (Bai et al.,
2025
-
[36]
On one hand we prompt larger LLMs to evaluate two stories generated by smaller LLMs, on the other hand we compare a story from a larger LLM with a story from a smaller LLM
vs QwQ-32B (Qwen et al., 2025). On one hand we prompt larger LLMs to evaluate two stories generated by smaller LLMs, on the other hand we compare a story from a larger LLM with a story from a smaller LLM. 17 Published as a conference paper at ICLR 2026 E.2 PREMISEBACK-GENERATIONDETAILS In addition to story rewriting and unguided generation, we also design...
2025
-
[37]
that elicit premises from existing texts. Specifically, we provide two article titles and abstracts as input and ask the model to identify their shared elements, such as themes, settings, characters, or narrative developments, and condense them into a single premise. This premise is required to be sufficiently general yet logically consistent, such that b...
2024
-
[38]
“Tie” means both models select the same story
18 Published as a conference paper at ICLR 2026 0% 25% 50% 75% 100% Skywork-Reward-27B Skywork-Reward-8B QRM-Llama3.1-8B GRM-Llama3.1-8B ArmoRM-Llama3-8B 44% 44% 52% 51% 61% 38% 37% 31% 31% 23% 17% 19% 17% 18% 17% StoryReward-Qwen wins Tie StoryReward-Qwen loses 0% 25% 50% 75% 100% Skywork-Reward-27B Skywork-Reward-8B QRM-Llama3.1-8B GRM-Llama3.1-8B ArmoR...
2026
-
[39]
(-) Premise Back-generation
with a widely-used evaluation method for story (Chhun et al., 2024). We first conduct a meta-evaluation of this evaluation method on STORYRMB, i.e., using this method to score each story and select the best one. We find it achieves94% accuracy on LLM–LLM pairs and54% on human–LLM pairs. Therefore, we believe this evaluation method is effective to evaluate...
2024
-
[40]
H.4 LINGUISTICANALYSIS We conduct linguistic analysis on stories selected by different reward models
We can find that stories selected by both StoryReward-Qwen and StoryReward-Llama achieve a higher score, which demonstrates the effectiveness of our trained reward models. H.4 LINGUISTICANALYSIS We conduct linguistic analysis on stories selected by different reward models. Specifically, we adopt the concept of linguistic burstiness from quantitative lingu...
1995
-
[41]
Difference
We observe that stories selected by STORYREWARD-QWENexhibit higher kurtosis compared to the ground truth references. This suggests a potential bias: since the training data includes human-written stories, STORYREWARD-QWEN may prefer linguistic burstiness (i.e., high kurtosis) as a proxy for quality. While this provides a statistical explanation for the mo...
2026
-
[42]
with a widely-used evaluation method for story generation (Chhun et al., 2024). Model Avg Score STORYREWARD-QWEN2.72 STORYREWARD-LLAMA2.51 GRM-Llama3.1-8B-rewardmodel-ft2.24 Skywork-Reward-Llama-3.1-8B-v0.22.24 QRM-Llama3.1-8B-v22.31 Skywork-Reward-Gemma-2-27B-v0.22.28 ArmoRM-Llama3-8B-v0.12.36 26
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.