Recognition: unknown
Data anonymization in the presence of outliers via invariant coordinate selection
Pith reviewed 2026-05-08 16:59 UTC · model grok-4.3
The pith
Invariant coordinate selection yields outlier-resistant data anonymization that improves privacy protection over spectral methods while preserving utility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
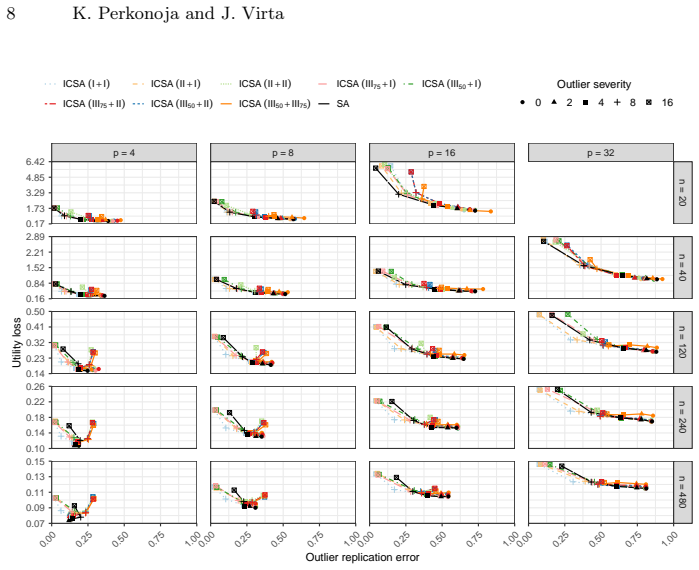
Replacing the PCA transformation in spectral anonymization with invariant coordinate selection allows the anonymization procedure's robustness to be regulated through the choice of scatter matrices. A theoretical result establishes that spectral anonymization fails under sufficiently influential outliers. Empirical comparisons under varying contamination settings indicate that ICSA implementations based on robust scatter matrices achieve stronger privacy protection than SA while typically maintaining comparable, and in some cases improved, utility.
What carries the argument
Invariant coordinate selection (ICS), the transformation that finds directions invariant under a pair of scatter matrices and replaces the PCA step to permit explicit robustness tuning via matrix choice.
If this is right
- Spectral anonymization can fail to protect privacy once outliers exert sufficient influence on the PCA directions.
- Robust scatter matrices in ICSA improve the privacy-utility trade-off under outlier contamination.
- The method exhibits superior overall efficiency on benchmark clinical data compared with standard spectral anonymization.
- Explicitly accounting for outliers through the choice of scatter matrices materially improves anonymization performance.
Where Pith is reading between the lines
- Other latent-space anonymization techniques that depend on PCA may inherit similar vulnerabilities to outliers and could benefit from analogous robust replacements.
- The framework suggests testing ICSA on additional data types, such as high-dimensional or time-series data, to determine the range of settings where robust scatter choices remain effective.
- Practitioners releasing sensitive data should consider whether their datasets contain influential points before defaulting to PCA-based anonymization.
Load-bearing premise
That the ICS transformation preserves the core anonymization properties of the latent-space approach while the scatter-matrix choice adds robustness without introducing new privacy vulnerabilities or utility losses.
What would settle it
A contamination setting in which spectral anonymization maintains its claimed privacy level despite the presence of influential outliers, or in which robust ICSA shows materially worse privacy-utility performance than SA.
Figures

read the original abstract
Protecting confidential data while preserving utility is particularly challenging when data sets contain outlying observations. Existing latent space anonymization methods, such as spectral anonymization (SA), rely on principal component analysis (PCA) and may therefore be vulnerable to contamination. We investigate anonymization in the presence of outliers and propose ICSA, a robust alternative to SA based on invariant coordinate selection (ICS). By replacing the PCA transformation with ICS, the robustness of the anonymization procedure can be regulated through the choice of scatter matrices. Alongside the methodological development, we derive a theoretical result showing that SA fails under sufficiently influential outliers. To assess the practical implications of this result, we compare the privacy-utility trade-off of ICSA and SA through simulation experiments under varying contamination settings and outlier severities. Our findings indicate that implementations of ICSA based on robust scatter matrices achieve stronger privacy protection than SA, while typically maintaining comparable, and in some cases improved, utility. We further examine the empirical performance of the proposed method using a benchmark clinical data set, where ICSA demonstrates superior overall privacy-utility efficiency relative to SA. These results suggest that explicitly accounting for outliers can materially improve anonymization performance and that robust latent space transformations offer a promising direction for privacy-preserving statistical data release.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ICSA, a robust variant of spectral anonymization (SA) that replaces PCA with invariant coordinate selection (ICS) to handle outliers in privacy-preserving data release. It derives a theoretical result that SA fails under sufficiently influential outliers, then compares ICSA and SA via simulations across contamination levels and a clinical benchmark dataset, concluding that robust-scatter ICSA implementations yield stronger privacy with comparable or improved utility.
Significance. If the theoretical failure mode and empirical privacy-utility gains hold, the work strengthens latent-space anonymization methods for real-world data containing outliers, a common practical challenge. The explicit robustness tuning via scatter-matrix choice and the clinical-data validation are concrete strengths that could inform future privacy-preserving releases.
major comments (2)
- [§3] §3 (theoretical result on SA failure): the statement that SA fails 'under sufficiently influential outliers' requires an explicit, quantitative bound on outlier magnitude or leverage (e.g., in terms of the contamination fraction or eigenvalue perturbation) to make the claim falsifiable and to clarify the regime where ICSA is guaranteed to improve upon SA.
- [§4.2] §4.2 (simulation design): the privacy metric (presumably some form of re-identification risk or disclosure probability) and utility metric (e.g., downstream estimation error) are not defined with sufficient precision to allow independent replication; without the exact formulas or code, it is unclear whether the reported superiority of ICSA is robust to alternative privacy definitions.
minor comments (3)
- [§2] Notation for the two scatter matrices in the ICS step should be introduced once and used consistently; the current alternation between S1/S2 and V1/V2 is confusing.
- [Figure 3] Figure 3 (clinical benchmark) lacks error bars or confidence intervals on the privacy-utility points, making it difficult to judge whether the reported efficiency gain is statistically meaningful.
- [Abstract] The abstract claims 'stronger privacy protection' but the main text should explicitly state whether this holds after multiple-testing correction across the simulation grid.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the detailed comments, which help clarify key aspects of the work. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [§3] §3 (theoretical result on SA failure): the statement that SA fails 'under sufficiently influential outliers' requires an explicit, quantitative bound on outlier magnitude or leverage (e.g., in terms of the contamination fraction or eigenvalue perturbation) to make the claim falsifiable and to clarify the regime where ICSA is guaranteed to improve upon SA.
Authors: We agree that an explicit bound would improve falsifiability. The proof in §3 establishes failure of SA when outlier influence perturbs the leading eigenvectors beyond the eigenvalue gap of the covariance matrix. In the revised manuscript we will add a corollary that states an explicit threshold on outlier magnitude as a function of the contamination fraction ε and the minimum eigenvalue gap, thereby specifying the precise regime in which SA fails and ICSA is guaranteed to improve upon it. revision: yes
-
Referee: [§4.2] §4.2 (simulation design): the privacy metric (presumably some form of re-identification risk or disclosure probability) and utility metric (e.g., downstream estimation error) are not defined with sufficient precision to allow independent replication; without the exact formulas or code, it is unclear whether the reported superiority of ICSA is robust to alternative privacy definitions.
Authors: We acknowledge that greater precision is needed for replicability. In the revision we will insert the exact formulas: the privacy metric is the re-identification risk defined as the expected proportion of records correctly matched via nearest-neighbor search in the anonymized space, and the utility metric is the relative mean-squared error of downstream linear regression coefficients estimated on the released data. We will also add a direct link to the public code repository containing the simulation scripts. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper derives an independent theoretical result on SA failure under influential outliers and proposes ICSA by substituting ICS (from prior literature) for PCA in the latent space anonymization pipeline. Privacy-utility comparisons are performed via simulation experiments and a clinical benchmark dataset rather than by fitting any parameter that defines the claimed superiority. No self-definitional equations, fitted-input predictions, or load-bearing self-citations appear in the abstract or described derivation chain; the method remains self-contained against external benchmarks and existing ICS theory.
Axiom & Free-Parameter Ledger
free parameters (1)
- choice of scatter matrices
axioms (1)
- domain assumption Invariant coordinate selection produces a transformation that preserves anonymization utility when substituted for PCA
Reference graph
Works this paper leans on
-
[1]
Econometrics and Statistics , author =
Alfons, A., Archimbaud, A., Nordhausen, K., Ruiz-Gazen, A.: Tandem clustering with invariant coordinate selection. Econometrics and Statistics (2024).https: //doi.org/10.1016/j.ecosta.2024.03.002
-
[2]
Econometrics and Statistics33, 282–303 (2025).https://doi.org/10.1016/j.ecosta.2022.03.003
Archimbaud, A., Boulfani, F., Gendre, X., Nordhausen, K., Ruiz-Gazen, A., Virta, J.: ICS for multivariate functional anomaly detection with applications to pre- dictive maintenance and quality control. Econometrics and Statistics33, 282–303 (2025).https://doi.org/10.1016/j.ecosta.2022.03.003
-
[3]
In: 2017 IEEE International Conference on Data Mining Workshops (ICDMW)
Calviño, A., Aldeguer, P., Domingo-Ferrer, J.: Factor analysis for anonymization. In: 2017 IEEE International Conference on Data Mining Workshops (ICDMW). pp. 984–991 (2017).https://doi.org/10.1109/ICDMW.2017.139
-
[4]
Data Mining and Knowledge Discovery 30(2016).https://doi.org/10.1007/s10618-015-0444-8
Campos, G.O., Zimek, A., Sander, J., Campello, R.J., Micenková, B., Schubert, E., Assent, I., Houle, M.E.: On the evaluation of unsupervised outlier detection: measures, datasets, and an empirical study. Data Mining and Knowledge Discovery 30(2016).https://doi.org/10.1007/s10618-015-0444-8
-
[5]
Dwork, C.: Differential privacy. In: Bugliesi, M., Preneel, B., Sassone, V., We- gener, I. (eds.) Automata, Languages and Programming. pp. 1–12. Springer Berlin Heidelberg, Berlin, Heidelberg (2006).https://doi.org/10.1007/11787006_1
-
[6]
D’Acquisto, G., Mazzoccoli, A., Ciminelli, F., Naldi, M.: Privacy through data recolouring. In: Annual Privacy Forum. pp. 61–72. Springer (2020).https://doi. org/10.1007/978-3-030-55196-4_4
-
[7]
BMC bioinformatics18(1), 173 (2017).https://doi.org/ 10.1186/s12859-017-1589-9
Fischer, D., Honkatukia, M., Tuiskula-Haavisto, M., Nordhausen, K., Cavero, D., Preisinger, R., Vilkki, J.: Subgroup detection in genotype data using invariant coordinate selection. BMC bioinformatics18(1), 173 (2017).https://doi.org/ 10.1186/s12859-017-1589-9
-
[8]
General Bayesian updating and the loss-likelihood bootstrap.Biometrika, 106(2):465–478, June 2019
Hettmansperger, T.P., Randles, R.H.: A practical affine equivariant multivariate median. Biometrika89(4), 851–860 (2002).https://doi.org/10.1093/biomet/ 89.4.851 16 K. Perkonoja and J. Virta
-
[9]
Hubert, M., Debruyne, M., Rousseeuw, P.J.: Minimum covariance determinant and extensions. Wiley Interdisciplinary Reviews: Computational Statistics10(3), e1421 (2018).https://doi.org/10.1002/wics.1421
-
[10]
Kundu, S., Suthaharan, S.: Privacy-preserving predictive model using factor anal- ysis for neuroscience applications. In: IEEE International Conference on Big Data Security on Cloud (BigDataSecurity), High Performance and Smart Comput- ing (HPSC) and Intelligent Data and Security (IDS). pp. 67–73. IEEE (2019). https://doi.org/10.1109/BigDataSecurity-HPSC-...
work page doi:10.1109/bigdatasecurity-hpsc-ids.2019.00023 2019
-
[11]
Lasko, T.A., Vinterbo, S.A.: Spectral anonymization of data. IEEE Transactions on Knowledge and Data Engineering22(3), 437–446 (2009).https://doi.org/ 10.1109/TKDE.2009.88
-
[12]
org/, R package version 0.99-7
Maechler, M., Rousseeuw, P., Croux, C., Todorov, V., Ruckstuhl, A., Salibian- Barrera, M., Verbeke, T., Koller, M., Conceicao, E.L.T., di Palma, M.A.: robust- base: Basic Robust Statistics (2026),http://robustbase.r-forge.r-project. org/, R package version 0.99-7
2026
-
[13]
Utilizing noise addition for data privacy, an overview,
Mivule, K.: Utilizing noise addition for data privacy, an overview. arXiv preprint arXiv:1309.3958 (2013).https://doi.org/10.48550/arXiv.1309.3958
-
[14]
In: An- nual Privacy Forum
Naldi, M., Mazzoccoli, A., D’Acquisto, G.: Hiding Alice in Wonderland: A case for the use of signal processing techniques in differential privacy. In: An- nual Privacy Forum. pp. 77–90. Springer (2018).https://doi.org/10.1007/ 978-3-030-02547-2_5
2018
-
[15]
Journal of Statistical Software28(6), 1–31 (2008).https://doi.org/ 10.18637/jss.v028.i06
Nordhausen, K., Oja, H., Tyler, D.E.: Tools for exploring multivariate data: The package ICS. Journal of Statistical Software28(6), 1–31 (2008).https://doi.org/ 10.18637/jss.v028.i06
-
[16]
Nordhausen, K., Sirkia, S., Oja, H., Tyler, D.E.: ICSNP: Tools for Multivari- ate Nonparametrics (2023).https://doi.org/10.32614/CRAN.package.ICSNP, R package version 1.1-2
-
[17]
In: Interna- tional Conference on Privacy in Statistical Databases
Perkonoja, K., Virta, J.: Asymptotic utility of spectral anonymization. In: Interna- tional Conference on Privacy in Statistical Databases. pp. 51–66. Springer (2024). https://doi.org/10.1007/978-3-031-69651-0_4
-
[18]
In: Robust and Multi- variate Statistical Methods: Festschrift in Honor of David E
Ruiz-Gazen, A., Thomas-Agnan, C., Laurent, T., Mondon, C.: Detecting outliers in compositional data using invariant coordinate selection. In: Robust and Multi- variate Statistical Methods: Festschrift in Honor of David E. Tyler, pp. 197–224. Springer (2022).https://doi.org/10.1007/978-3-031-22687-8_10
-
[19]
Journal of Statistical Software32(3), 1–47 (2009).https://doi.org/10
Todorov, V., Filzmoser, P.: An object-oriented framework for robust multivariate analysis. Journal of Statistical Software32(3), 1–47 (2009).https://doi.org/10. 18637/jss.v032.i03
2009
-
[20]
Biometrika69(2), 429–436 (1982).https://doi.org/10.1093/biomet/69.2.429
Tyler, D.E.: Radial estimates and the test for sphericity. Biometrika69(2), 429–436 (1982).https://doi.org/10.1093/biomet/69.2.429
-
[21]
Tyler, D.E.: A distribution-free M-estimator of multivariate scatter. The Annals of Statistics pp. 234–251 (1987).https://doi.org/10.1214/aos/1176350263
-
[22]
Tyler, D.E., Critchley, F., Dümbgen, L., Oja, H.: Invariant co-ordinate selection. Journal of the Royal Statistical Society Series B: Statistical Methodology71(3), 549–592 (2009).https://doi.org/10.1111/j.1467-9868.2009.00706.x
-
[23]
UCI Machine Learning Repository (1993).https://doi.org/10
Wolberg, W., Mangasarian, O., Street, N., Street, W.: Breast Cancer Wiscon- sin (Diagnostic). UCI Machine Learning Repository (1993).https://doi.org/10. 24432/C5DW2B
1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.