Recognition: unknown
To Fuse or to Drop? Dual-Path Learning for Resolving Modality Conflicts in Multimodal Emotion Recognition
Pith reviewed 2026-05-08 15:49 UTC · model grok-4.3
The pith
A dual-path framework learns when to fuse modalities and when to drop them to resolve conflicts in multimodal emotion recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
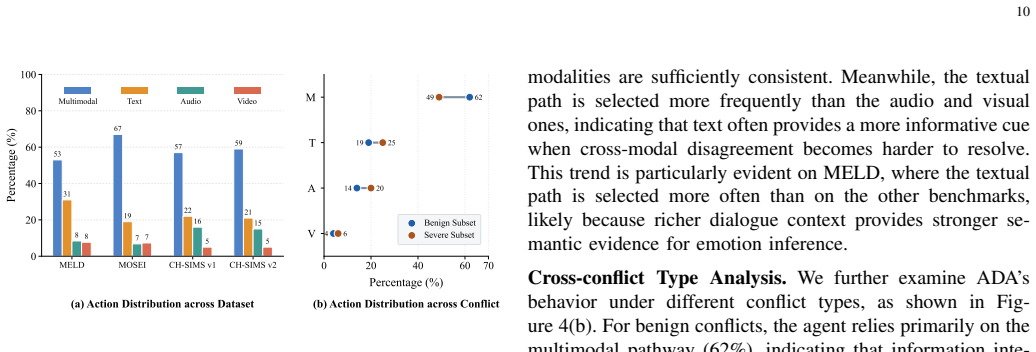
The central claim is that modality conflicts in multimodal emotion recognition are not uniform: benign conflicts from weak or ambiguous cues can be resolved through reverse distillation and calibration in the Affective Fusion Distiller, while severe conflicts from contradictory signals are handled by the Affective Discernment Agent that treats the task as a contextual bandit selecting among fusion and unimodal outputs using a dual-view state and calibration-aware reward, leading to superior or competitive results on five dialogue-level and clip-level benchmarks without per-modality labels.
What carries the argument
Dual-Path Conflict Resolution (DCR) framework consisting of Affective Fusion Distiller (AFD) for representation-level calibration via temporally weighted distillation and Affective Discernment Agent (ADA) as a contextual bandit for decision-level arbitration.
If this is right
- Standard fusion is replaced by context-aware selection that improves accuracy on both dialogue and clip benchmarks.
- The two paths are complementary: calibration helps when alignment exists, and arbitration avoids error amplification when it does not.
- No per-modality reliability labels are required because the bandit learns from calibration signals and full multimodal context.
- Conflict-specific evaluation shows gains precisely on subsets where modalities disagree.
- Modality-selection analysis confirms the agent learns to drop misleading inputs in irreconcilable cases.
Where Pith is reading between the lines
- The same split between calibration and arbitration could extend to other multimodal tasks like sentiment analysis or action recognition where signals can conflict.
- In deployed systems, the bandit could be updated online as new user feedback arrives, allowing adaptation to domain shifts in emotion cues.
- If the bandit reward can be made fully unsupervised, the method might scale to unlabeled multimodal streams without any emotion annotations.
- Real-world applications such as conversational agents would benefit from fewer false emotion detections during sarcastic exchanges.
Load-bearing premise
That modality conflicts split cleanly into benign cases solvable by calibration and severe cases solvable by bandit arbitration, and that the dual-view state plus calibration-aware reward captures the right policy without any per-modality reliability labels.
What would settle it
A dataset of emotion samples with explicitly labeled severe conflicts where the model still chooses fusion over the best unimodal prediction and shows lower accuracy than a simple best-unimodal baseline.
Figures





read the original abstract
Multimodal emotion recognition (MER) benefits from combining text, audio, and vision, yet standard fusion often fails when modalities conflict. Crucially, conflicts differ in resolvability: benign conflicts stem from missing, weak, or ambiguous cues and can be mitigated by cross-modal calibration, while severe conflicts arise from intrinsically contradictory (e.g., sarcasm) or misleading signals, for which forced fusion may amplify errors. Recognizing this, we propose Dual-Path Conflict Resolution (DCR), a unified framework that learns when to fuse and when to drop modalities. Path I (Affective Fusion Distiller, AFD) performs reverse distillation from audio/visual teachers to a textual student using temporally weighted class evidence, thereby enhancing representation-level calibration and improving fusion when alignment is beneficial. Path II (Affective Discernment Agent, ADA) formulates MER as a contextual bandit that selects among fusion and unimodal predictions based on a dual-view state and a calibration-aware reward, enabling decision-level arbitration under irreconcilable conflicts without requiring per-modality reliability labels. By taking into account the full multimodal context and coupling soft calibration with hard arbitration, DCR reconciles conflicts that can be aligned while bypassing misleading modalities when fusion is harmful. Across five benchmarks covering both dialogue-level and clip-level MER, DCR consistently outperforms competitive baselines or achieves highly competitive results. Further ablations, conflict-specific subset evaluation, and modality-selection analysis verify that AFD and ADA are complementary and jointly improve robust conflict-aware emotion recognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Dual-Path Conflict Resolution (DCR) for multimodal emotion recognition, with Path I (Affective Fusion Distiller, AFD) using reverse distillation from audio/visual teachers to a text student for representation-level calibration on benign conflicts, and Path II (Affective Discernment Agent, ADA) casting the problem as a contextual bandit with dual-view state and calibration-aware reward to arbitrate between fusion and unimodal predictions on severe conflicts. It reports that DCR outperforms or matches competitive baselines across five dialogue- and clip-level MER benchmarks, with ablations and conflict-specific analyses confirming that AFD and ADA are complementary.
Significance. If the empirical results hold, the work offers a principled separation of calibration (for resolvable conflicts) from arbitration (for irreconcilable ones) without per-modality reliability labels, which could meaningfully improve robustness in MER systems. The contextual-bandit framing applied to modality selection is a clean conceptual contribution that builds on standard tools while addressing a practical pain point in fusion.
major comments (2)
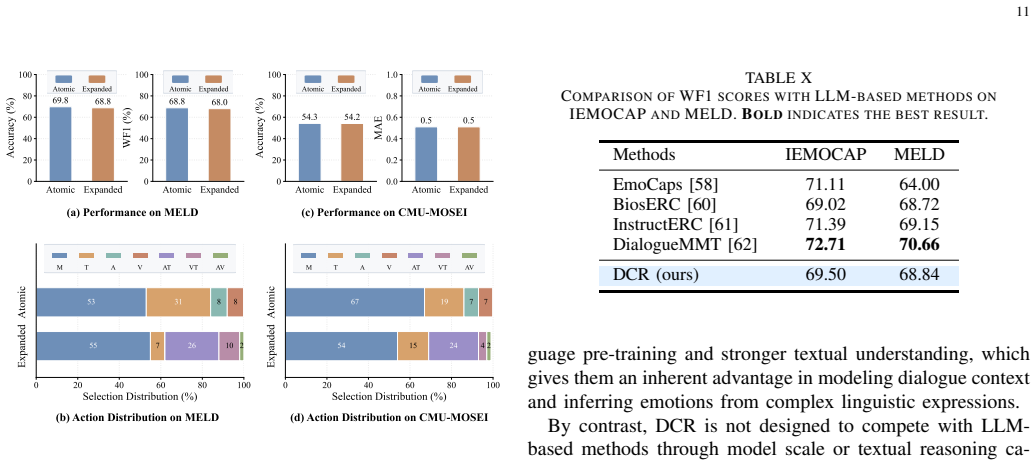
- [§4.2] §4.2 (ADA bandit formulation): the dual-view state and calibration-aware reward are load-bearing for the claim that ADA learns an optimal arbitration policy from multimodal context alone, yet the exact definitions of state features, reward computation, and the underlying bandit algorithm (e.g., update rule or exploration strategy) are not supplied; without them the independence from implicit fitting cannot be verified.
- [Results section] Results section, conflict-specific subset evaluation: the claim that AFD and ADA are complementary rests on these ablations, but the reported numbers do not include per-subset statistical tests or variance across random seeds, leaving open the possibility that gains on severe-conflict subsets are not reliably distinguishable from baseline variance.
minor comments (2)
- [Abstract / §3] The abstract and §3 introduce 'temporally weighted class evidence' without a concise equation or pseudocode; adding one would improve readability for readers unfamiliar with the distillation weighting.
- [Figure 1] Figure 1 (overall architecture) would benefit from explicit arrows or labels showing how AFD calibration output feeds into the ADA state, to clarify the coupling between the two paths.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments on our manuscript. We address each major comment point by point below. We will revise the manuscript to incorporate the requested clarifications and additional analyses.
read point-by-point responses
-
Referee: [§4.2] §4.2 (ADA bandit formulation): the dual-view state and calibration-aware reward are load-bearing for the claim that ADA learns an optimal arbitration policy from multimodal context alone, yet the exact definitions of state features, reward computation, and the underlying bandit algorithm (e.g., update rule or exploration strategy) are not supplied; without them the independence from implicit fitting cannot be verified.
Authors: We agree that the precise definitions and algorithmic details for the ADA component are essential for reproducibility and to fully support the claim of learning an arbitration policy from multimodal context. In the revised manuscript, we will expand §4.2 to include the explicit formulation of the dual-view state features, the complete calibration-aware reward function with its mathematical definition, and the underlying bandit algorithm including the update rule and exploration strategy. These additions will allow independent verification that the policy operates without reliance on per-modality reliability labels. revision: yes
-
Referee: Results section, conflict-specific subset evaluation: the claim that AFD and ADA are complementary rests on these ablations, but the reported numbers do not include per-subset statistical tests or variance across random seeds, leaving open the possibility that gains on severe-conflict subsets are not reliably distinguishable from baseline variance.
Authors: We acknowledge that the current results presentation lacks statistical rigor on the conflict-specific subsets. In the revised manuscript, we will report performance means and standard deviations across multiple random seeds for the ablations on benign and severe conflict subsets. We will also add appropriate statistical significance tests (e.g., paired t-tests) comparing DCR against baselines on the severe-conflict subsets to confirm that the observed gains are distinguishable from variance. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes a new Dual-Path Conflict Resolution (DCR) framework consisting of Affective Fusion Distiller (AFD) for reverse distillation-based calibration and Affective Discernment Agent (ADA) as a contextual bandit for arbitration. No equations, parameter fits, or self-citations are shown that reduce the central claims (distinguishing benign vs. severe conflicts and learning fusion/drop decisions) to inputs by construction. The components are presented as independent mechanisms operating on multimodal context without tautological redefinitions or load-bearing prior self-references. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- bandit reward and state parameters
axioms (1)
- domain assumption Modality conflicts can be partitioned into benign (mitigable by cross-modal calibration) and severe (requiring modality dropping) without per-modality reliability labels.
invented entities (2)
-
Affective Fusion Distiller (AFD)
no independent evidence
-
Affective Discernment Agent (ADA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A facial expression emotion recognition based human-robot interaction system
Z. Liu, M. Wu, W. Cao, L. Chen, J. Xu, R. Zhang, M. Zhou, and J. Mao, “A facial expression emotion recognition based human-robot interaction system.”IEEE CAA J. Autom. Sinica, vol. 4, no. 4, pp. 668–676, 2017
2017
-
[2]
Attention is not enough: Mitigating the distribution discrepancy in asynchronous multi- modal sequence fusion,
T. Liang, G. Lin, L. Feng, Y . Zhang, and F. Lv, “Attention is not enough: Mitigating the distribution discrepancy in asynchronous multi- modal sequence fusion,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 8148–8156
2021
-
[3]
Progressive modality re- inforcement for human multimodal emotion recognition from unaligned multimodal sequences,
F. Lv, X. Chen, Y . Huang, L. Duan, and G. Lin, “Progressive modality re- inforcement for human multimodal emotion recognition from unaligned multimodal sequences,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 2554–2562
2021
-
[4]
Decoupled multimodal distilling for emotion recognition,
Y . Li, Y . Wang, and Z. Cui, “Decoupled multimodal distilling for emotion recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 6631–6640
2023
-
[5]
TelME: Teacher-leading multimodal fusion network for emotion recognition in conversation,
T. Yun, H. Lim, J. Lee, and M. Song, “TelME: Teacher-leading multimodal fusion network for emotion recognition in conversation,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), K. Duh, H. Gomez, and S. Bethard, Eds. Mexico City, Mexico...
2024
-
[6]
A transformer-based model with self-distillation for multimodal emotion recognition in conversations,
H. Ma, J. Wang, H. Lin, B. Zhang, Y . Zhang, and B. Xu, “A transformer-based model with self-distillation for multimodal emotion recognition in conversations,”Trans. Multi., vol. 26, pp. 776–788, Jan
-
[7]
Available: https://doi.org/10.1109/TMM.2023.3271019
[Online]. Available: https://doi.org/10.1109/TMM.2023.3271019
-
[8]
Multimodal multi-loss fusion network for sentiment analysis,
Z. Wu, Z. Gong, J. Koo, and J. Hirschberg, “Multimodal multi-loss fusion network for sentiment analysis,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), K. Duh, H. Gomez, and S. Bethard, Eds. Mexico City, Mexico: Association for Compu...
2024
-
[9]
A facial expression-aware multimodal multi-task learning framework for emotion recognition in multi-party conversations,
W. Zheng, J. Yu, R. Xia, and S. Wang, “A facial expression-aware multimodal multi-task learning framework for emotion recognition in multi-party conversations,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds. Toronto, Canada: Association for ...
2023
-
[10]
CH-SIMS: A Chinese multimodal sentiment analysis dataset with fine-grained annotation of modality,
W. Yu, H. Xu, F. Meng, Y . Zhu, Y . Ma, J. Wu, J. Zou, and K. Yang, “CH-SIMS: A Chinese multimodal sentiment analysis dataset with fine-grained annotation of modality,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. Online: Association for Computational L...
2020
-
[11]
A survey of dialogic emotion analysis: Developments, approaches and perspectives,
C. Gan, J. Zheng, Q. Zhu, Y . Cao, and Y . Zhu, “A survey of dialogic emotion analysis: Developments, approaches and perspectives,”Pattern Recognition, vol. 156, p. 110794, 2024
2024
-
[12]
A comprehensive survey on multi-modal conversational emotion recognition with deep learning,
Y . Shou, T. Meng, W. Ai, F. Fu, N. Yin, and K. Li, “A comprehensive survey on multi-modal conversational emotion recognition with deep learning,”ACM Trans. Inf. Syst., vol. 44, no. 2, pp. 1–48, 2026
2026
-
[13]
Tensor fusion network for multimodal sentiment analysis,
A. Zadeh, M. Chen, S. Poria, E. Cambria, and L.-P. Morency, “Tensor fusion network for multimodal sentiment analysis,” inProceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, M. Palmer, R. Hwa, and S. Riedel, Eds. Copenhagen, Denmark: Association for Computational Linguistics, Sep. 2017, pp. 1103–1114. [Online]. Available...
2017
-
[14]
Efficient low-rank multimodal fusion with modality- specific factors,
Z. Liu, Y . Shen, V . B. Lakshminarasimhan, P. P. Liang, A. B. Zadeh, and L.-P. Morency, “Efficient low-rank multimodal fusion with modality- specific factors,” inProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2018, pp. 2247–2256
2018
-
[15]
Memory fusion network for multi-view sequential learning,
A. Zadeh, P. P. Liang, N. Mazumder, S. Poria, E. Cambria, and L.-P. Morency, “Memory fusion network for multi-view sequential learning,” inProceedings of the Thirty-Second AAAI Conference on Artificial In- telligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial ...
2018
-
[16]
Misa: Modality-invariant and-specific representations for multimodal sentiment analysis,
D. Hazarika, R. Zimmermann, and S. Poria, “Misa: Modality-invariant and-specific representations for multimodal sentiment analysis,” inPro- ceedings of the 28th ACM international conference on multimedia, 2020, pp. 1122–1131
2020
-
[17]
Token- disentangling mutual transformer for multimodal emotion recognition,
G. Yin, Y . Liu, T. Liu, H. Zhang, F. Fang, C. Tang, and L. Jiang, “Token- disentangling mutual transformer for multimodal emotion recognition,” Engineering Applications of Artificial Intelligence, vol. 133, p. 108348, 07 2024
2024
-
[18]
Disentangled representation learning for multimodal emotion recognition,
D. Yang, S. Huang, H. Kuang, Y . Du, and L. Zhang, “Disentangled representation learning for multimodal emotion recognition,” in Proceedings of the 30th ACM International Conference on Multimedia, ser. MM ’22. New York, NY , USA: Association for Computing Machinery, 2022, pp. 1642–1651. [Online]. Available: https://doi.org/ 10.1145/3503161.3547754
-
[19]
Multimodal transformer for unaligned multimodal language sequences,
Y .-H. H. Tsai, S. Bai, P. P. Liang, J. Z. Kolter, L.-P. Morency, and R. Salakhutdinov, “Multimodal transformer for unaligned multimodal language sequences,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, A. Korhonen, D. Traum, and L. M `arquez, Eds. Florence, Italy: Association for Computational Linguistics, Ju...
2019
-
[20]
Progressive modality re- inforcement for human multimodal emotion recognition from unaligned multimodal sequences,
F. Lv, X. Chen, Y . Huang, L. Duan, and G. Lin, “Progressive modality re- inforcement for human multimodal emotion recognition from unaligned multimodal sequences,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2021, pp. 2554–2562. 13
2021
-
[21]
Distilling the Knowledge in a Neural Network
G. E. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”ArXiv, vol. abs/1503.02531, 2015. [Online]. Available: https://api.semanticscholar.org/CorpusID:7200347
work page internal anchor Pith review arXiv 2015
-
[22]
FitNets: Hints for Thin Deep Nets
A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y . Bengio, “Fitnets: Hints for thin deep nets,”CoRR, vol. abs/1412.6550,
work page internal anchor Pith review arXiv
-
[23]
Available: https://api.semanticscholar.org/CorpusID: 2723173
[Online]. Available: https://api.semanticscholar.org/CorpusID: 2723173
-
[24]
Distilling knowledge via knowledge review,
P. Chen, S. Liu, H. Zhao, and J. Jia, “Distilling knowledge via knowledge review,” inIEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2021
2021
-
[25]
Multimodal knowledge distillation for emotion recognition,
Z. Zhang and G. Lu, “Multimodal knowledge distillation for emotion recognition,”Brain Sciences, vol. 15, no. 7, p. 707, 2025. [Online]. Available: https://www.mdpi.com/2076-3425/15/7/707
2025
-
[26]
Dynamic neural networks: A survey,
Y . Han, G. Huang, S. Song, L. Yang, H. Wang, and Y . Wang, “Dynamic neural networks: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, pp. 7436–7456, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:231855426
2021
-
[27]
Skipnet: Learning dynamic routing in convolutional networks,
X. Wang, F. Yu, Z.-Y . Dou, T. Darrell, and J. E. Gonzalez, “Skipnet: Learning dynamic routing in convolutional networks,” inProceedings of the European Conference on Computer Vision (ECCV), September 2018
2018
-
[28]
MOSEL: Inference serving using dynamic modality selection,
B. Hu, L. Xu, J. Moon, N. J. Yadwadkar, and A. Akella, “MOSEL: Inference serving using dynamic modality selection,” in Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, pp. 8872–8886. [Online]. A...
2024
-
[29]
Rl-emo: A reinforcement learning framework for multimodal emotion recognition,
C. Zhang, Y . Zhang, and B. Cheng, “Rl-emo: A reinforcement learning framework for multimodal emotion recognition,”ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 10 246–10 250, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:268577764
2024
-
[30]
The MuSe 2022 multimodal sentiment analysis challenge: Humor, emotional reactions, and stress,
L. Christ, S. Amiriparian, A. Baird, P. Tzirakis, A. Kathan, N. M ¨uller, L. Stappen, E.-M. Meßner, A. K ¨onig, A. Cowen, E. Cambria, and B. W. Schuller, “The MuSe 2022 multimodal sentiment analysis challenge: Humor, emotional reactions, and stress,” inProceedings of the 3rd In- ternational on Multimodal Sentiment Analysis Workshop and Challenge. New York...
2022
-
[31]
MER 2024: Semi-supervised learning, noise robustness, and open-vocabulary multimodal emotion recognition,
Z. Lian, H. Sun, L. Sun, Z. Wen, S. Zhang, S. Chen, H. Gu, J. Zhao, Z. Ma, X. Chen, J. Yi, R. Liu, K. Xu, B. Liu, E. Cambria, G. Zhao, B. W. Schuller, and J. Tao, “MER 2024: Semi-supervised learning, noise robustness, and open-vocabulary multimodal emotion recognition,” inProceedings of the 2nd International Workshop on Multimodal and Responsible Affectiv...
2024
-
[32]
Learning deep features for discriminative localization,
B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba, “Learning deep features for discriminative localization,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2921– 2929
2016
-
[33]
The epoch-greedy algorithm for multi- armed bandits with side information,
J. Langford and T. Zhang, “The epoch-greedy algorithm for multi- armed bandits with side information,”Advances in neural information processing systems, vol. 20, 2007
2007
-
[34]
Asynchronous methods for deep reinforcement learning,
V . Mnih, A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu, “Asynchronous methods for deep reinforcement learning,” inProceedings of The 33rd International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, M. F. Balcan and K. Q. Weinberger, Eds., vol. 48. New York, New York, USA: PMLR, 2...
2016
-
[35]
MELD: A multimodal multi-party dataset for emotion recognition in conversations,
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, and R. Mihalcea, “MELD: A multimodal multi-party dataset for emotion recognition in conversations,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, A. Korhonen, D. Traum, and L. M `arquez, Eds. Florence, Italy: Association for Computational Linguistics, Jul...
2019
-
[36]
Iemocap: Interactive emotional dyadic motion capture database,
C. Busso, M. Bulut, C.-C. Lee, A. Kazemzadeh, E. Mower, S. Kim, J. N. Chang, S. Lee, and S. S. Narayanan, “Iemocap: Interactive emotional dyadic motion capture database,”Language resources and evaluation, vol. 42, no. 4, pp. 335–359, 2008
2008
-
[37]
Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph,
A. Bagher Zadeh, P. P. Liang, S. Poria, E. Cambria, and L.-P. Morency, “Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph,” inProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), I. Gurevych and Y . Miyao, Eds. Melbourne, Australia: Association for...
2018
-
[38]
Make acoustic and visual cues matter: Ch-sims v2.0 dataset and av-mixup consistent module,
Y . Liu, Z. Yuan, H. Mao, Z. Liang, W. Yang, Y . Qiu, T. Cheng, X. Li, H. Xu, and K. Gao, “Make acoustic and visual cues matter: Ch-sims v2.0 dataset and av-mixup consistent module,” in Proceedings of the 2022 International Conference on Multimodal Interaction, ser. ICMI ’22. New York, NY , USA: Association for Computing Machinery, 2022, pp. 247–258. [Onl...
-
[39]
Dialoguecrn: Contextual reasoning networks for emotion recognition in conversations,
D. Hu, L. Wei, and X. Huai, “Dialoguecrn: Contextual reasoning networks for emotion recognition in conversations,” inProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2021, pp. 7042–7052
2021
-
[40]
Di- alogueRNN: An attentive RNN for emotion detection in conversations,
N. Majumder, S. Poria, D. Hazarika, R. Mihalcea, and E. Cambria, “Di- alogueRNN: An attentive RNN for emotion detection in conversations,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 6818–6825, 2019
2019
-
[41]
Supervised adversarial contrastive learning for emotion recognition in conversations,
D. Hu, Y . Bao, L. Wei, W. Zhou, and S. Hu, “Supervised adversarial contrastive learning for emotion recognition in conversations,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds. Toronto, Canada: Association for Computational Linguistics, J...
2023
-
[42]
Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis,
W. Yu, H. Xu, Y . Ziqi, and W. Jiele, “Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis,” inProceedings of the AAAI Conference on Artificial Intelligence, 2021
2021
-
[43]
UniMSE: Towards unified multimodal sentiment analysis and emotion recognition,
G. Hu, T.-E. Lin, Y . Zhao, G. Lu, Y . Wu, and Y . Li, “UniMSE: Towards unified multimodal sentiment analysis and emotion recognition,” inProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Y . Goldberg, Z. Kozareva, and Y . Zhang, Eds. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics, Dec. 202...
2022
-
[44]
RMER-DT: Robust multimodal emotion recognition in conversational contexts based on diffusion and transformers,
X. Zhu, Y . Wang, E. Cambria, I. Rida, J. S. L ´opez, L. Cui, and R. Wang, “RMER-DT: Robust multimodal emotion recognition in conversational contexts based on diffusion and transformers,” Information Fusion, vol. 123, p. 103268, 2025. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1566253525003410
2025
-
[45]
MMGCN: Multimodal fusion via deep graph convolution network for emotion recognition in conversation,
J. Hu, Y . Liu, J. Zhao, and Q. Jin, “MMGCN: Multimodal fusion via deep graph convolution network for emotion recognition in conversation,” inProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), C. Zong, F. Xia, W. Li, and...
2021
-
[46]
Graphcfc: A directed graph based cross-modal feature complementation approach for multimodal conversational emotion recognition,
J. Li, X. Wang, G. Lv, and Z. Zeng, “Graphcfc: A directed graph based cross-modal feature complementation approach for multimodal conversational emotion recognition,”IEEE Transactions on Multimedia, vol. 26, pp. 77–89, 2023
2023
-
[47]
ECERC: Evidence-cause attention network for multi-modal emotion recognition in conversation,
T. Zhang and Z. Tan, “ECERC: Evidence-cause attention network for multi-modal emotion recognition in conversation,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, Eds. Vienna, Austria: Association for Computational Linguistics, Jul. 2025...
2025
-
[48]
Efficient low-rank multimodal fusion with modality- specific factors,
Z. Liu, Y . Shen, V . B. Lakshminarasimhan, P. P. Liang, A. Bagher Zadeh, and L.-P. Morency, “Efficient low-rank multimodal fusion with modality- specific factors,” inProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), I. Gurevych and Y . Miyao, Eds. Melbourne, Australia: Association for Computa...
2018
-
[49]
Frequency restoration and modality enforcement towards resisting- corruption multimodal sentiment analysis,
W. Xie, H. Liang, Z. Niu, X. Hou, S. Song, Z. Yu, and L. Shen, “Frequency restoration and modality enforcement towards resisting- corruption multimodal sentiment analysis,”ACM Transactions on Multi- media Computing, Communications, and Applications, vol. 21, 10 2025
2025
-
[50]
Dash- fusion: Dual-stream alignment with hierarchical bottleneck fusion for multimodal sentiment analysis,
Y . Wen, Q. Li, Y . Zhou, Y . Gao, Z. Wen, J. Tao, and Y . Li, “Dash- fusion: Dual-stream alignment with hierarchical bottleneck fusion for multimodal sentiment analysis,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 10, pp. 17 941–17 952, 2025
2025
-
[51]
Context-dependent sentiment analysis in user-generated 14 videos,
S. Poria, E. Cambria, D. Hazarika, N. Majumder, A. Zadeh, and L.- P. Morency, “Context-dependent sentiment analysis in user-generated 14 videos,” inProceedings of the 55th annual meeting of the association for computational linguistics (volume 1: Long papers), 2017, pp. 873– 883
2017
-
[52]
Joyful: Joint modality fusion and graph contrastive learning for multimoda emotion recognition,
D. Li, Y . Wang, K. Funakoshi, and M. Okumura, “Joyful: Joint modality fusion and graph contrastive learning for multimoda emotion recognition,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 16 051–16 069....
2023
-
[53]
Dia- loguegcn: A graph convolutional neural network for emotion recognition in conversation,
D. Ghosal, N. Majumder, S. Poria, N. Chhaya, and A. Gelbukh, “Dia- loguegcn: A graph convolutional neural network for emotion recognition in conversation,” inProceedings of the 2019 conference on empirical methods in natural language processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019, pp. 154–164
2019
-
[54]
Dq-former: Layer-wise querying transformer with dynamic modality priority for conversational multi- modal emotion recognition,
J. Ye, L. Xiang, X. Zhao, and C. Zong, “Dq-former: Layer-wise querying transformer with dynamic modality priority for conversational multi- modal emotion recognition,”IEEE Transactions on Affective Computing, pp. 1–17, 2026
2026
-
[55]
ConKI: Contrastive knowledge injection for multimodal sentiment analysis,
Y . Yu, M. Zhao, S.-a. Qi, F. Sun, B. Wang, W. Guo, X. Wang, L. Yang, and D. Niu, “ConKI: Contrastive knowledge injection for multimodal sentiment analysis,” inFindings of the Association for Computational Linguistics: ACL 2023, A. Rogers, J. Boyd- Graber, and N. Okazaki, Eds. Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 13 6...
2023
-
[56]
CLGSI: A multimodal sentiment analysis framework based on contrastive learning guided by sentiment intensity,
Y . Yang, X. Dong, and Y . Qiang, “CLGSI: A multimodal sentiment analysis framework based on contrastive learning guided by sentiment intensity,” inFindings of the Association for Computational Linguistics: NAACL 2024, K. Duh, H. Gomez, and S. Bethard, Eds. Mexico City, Mexico: Association for Computational Linguistics, Jun. 2024, pp. 2099–2110. [Online]....
2024
-
[57]
Kebr: Knowledge enhanced self-supervised balanced representation for multimodal sentiment analysis,
A. Zhu, M. Hu, X. Wang, J. Yang, Y . Tang, and F. Ren, “Kebr: Knowledge enhanced self-supervised balanced representation for multimodal sentiment analysis,” inProceedings of the 32nd ACM International Conference on Multimedia, ser. MM ’24. New York, NY , USA: Association for Computing Machinery, 2024, pp. 5732–5741. [Online]. Available: https://doi.org/10...
-
[58]
Integrating multimodal information in large pretrained transformers,
W. Rahman, M. K. Hasan, S. Lee, A. Bagher Zadeh, C. Mao, L.-P. Morency, and E. Hoque, “Integrating multimodal information in large pretrained transformers,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. Online: Association for Computational Linguistics, ...
2020
-
[59]
Modal feature optimization network with prompt for multimodal sentiment analysis,
X. Zhang, W. Wei, and S. Zou, “Modal feature optimization network with prompt for multimodal sentiment analysis,” inProceedings of the 31st International Conference on Computational Linguistics, O. Rambow, L. Wanner, M. Apidianaki, H. Al-Khalifa, B. D. Eugenio, and S. Schockaert, Eds. Abu Dhabi, UAE: Association for Computational Linguistics, Jan. 2025, p...
2025
-
[60]
EmoCaps: Emotion capsule based model for conversational emotion recognition,
Z. Li, F. Tang, M. Zhao, and Y . Zhu, “EmoCaps: Emotion capsule based model for conversational emotion recognition,” inFindings of the Association for Computational Linguistics: ACL 2022, S. Muresan, P. Nakov, and A. Villavicencio, Eds. Dublin, Ireland: Association for Computational Linguistics, May 2022, pp. 1610–1618. [Online]. Available: https://aclant...
2022
-
[61]
Emoverse: Enhancing multimodal large language models for affective computing via multitask learning,
A. Li, L. Xu, C. Ling, J. Zhang, and P. Wang, “Emoverse: Enhancing multimodal large language models for affective computing via multitask learning,”Neurocomputing, vol. 650, p. 130810, 2025. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S0925231225014821
2025
-
[62]
Bioserc: Integrating biography speakers supported by llms for erc tasks,
J. Xue, P. M. Nguyen, B. Matheny, and L. M. Nguyen, “Bioserc: Integrating biography speakers supported by llms for erc tasks,” in International Conference on Artificial Neural Networks, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:271038809
2024
-
[63]
S. Lei, G. Dong, X. Wang, K. Wang, and S. Wang, “Instructerc: Reforming emotion recognition in conversation with a retrieval multi- task llms framework,”CoRR, vol. abs/2309.11911, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2309.11911
-
[64]
DialogueMMT: Dialogue scenes understanding enhanced multi-modal multi-task tuning for emotion recognition in conversations,
C. He, S. Zhu, H. Liu, F. Gao, Y . Jia, H. Zan, and M. Peng, “DialogueMMT: Dialogue scenes understanding enhanced multi-modal multi-task tuning for emotion recognition in conversations,” in Proceedings of the 31st International Conference on Computational Linguistics, O. Rambow, L. Wanner, M. Apidianaki, H. Al-Khalifa, B. D. Eugenio, and S. Schockaert, Ed...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.