Recognition: unknown
Self-Attention as Transport: Limits of Symmetric Spectral Diagnostics
Pith reviewed 2026-05-08 16:45 UTC · model grok-4.3
The pith
Symmetric spectral diagnostics on attention operators cannot detect the direction of information flow.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
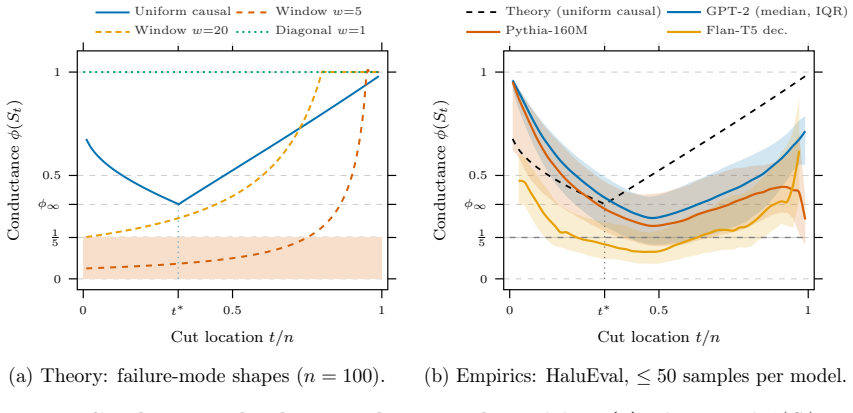
Every transpose-invariant spectral diagnostic applied to the degree-normalized attention operator fails to distinguish the operator from its transpose and therefore cannot detect information-flow direction. The asymmetry coefficient G is shown to be the unique control parameter for this direction. For canonical causal architectures a closed-form bipartite-Cheeger landscape gives uniform attention an n-independent capacity floor of φ ≥ 1/5 with worst cut at t*/n ≈ 0.32, while window attention reaches only O(w/n). The two-axis diagnostic (φ for capacity, G for direction) predicts and observes reversed polarity between bottleneck-dominated and diffuse-dominated hallucination benchmarks, with LC
What carries the argument
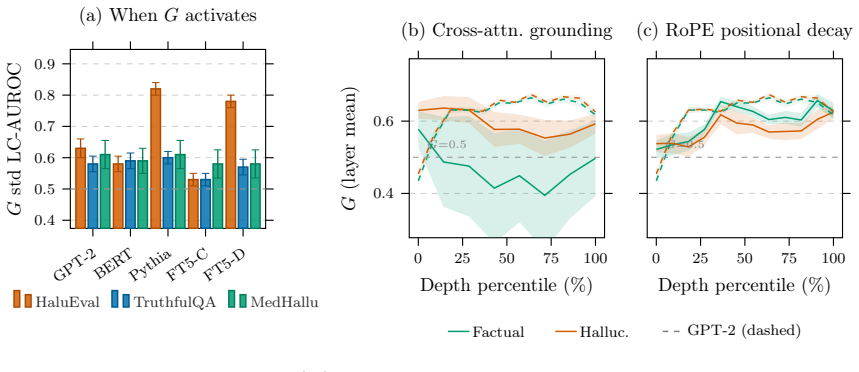
The asymmetry coefficient G of the degree-normalized attention operator, which serves as the unique parameter governing directional bias once transpose invariance is imposed on spectral diagnostics.
If this is right
- Symmetric-only spectral diagnostics cannot identify directional causes of attention failure.
- The φ-G plane separates bottleneck-dominated from diffuse-dominated hallucination regimes.
- Uniform causal attention carries an n-independent capacity lower bound of 1/5.
- Window attention capacity falls as O(w/n) and can undercut the uniform floor.
- Transport features retain measurable predictive signal for hallucinations up to 8B parameters.
Where Pith is reading between the lines
- The orientation-blindness result may apply to symmetric analyses of other attention-like operators in graph networks or diffusion models.
- Adding explicit directional measures could improve interpretability of internal routing in transformer stacks.
- The derived bounds on φ could inform the design of attention masks that avoid low-capacity regimes.
- The polarity prediction offers a direct test of whether transport properties dominate hallucination behavior across additional datasets.
Load-bearing premise
The dominant hallucination mechanisms in the tested benchmarks are fully captured by the transport capacity and directionality of the degree-normalized attention operator without substantial confounding from feed-forward layers, layer norms, or output decoding.
What would settle it
A concrete counterexample in which some transpose-invariant spectral diagnostic distinguishes an attention operator from its transpose, or a length-controlled evaluation on the same models in which the predicted polarity reversal between HaluEval and MedHallu fails to appear.
Figures




read the original abstract
Large language models hallucinate in predictable ways: attention routing fails by over-concentrating on a narrow set of positions, or by spreading so diffusely that relevance is diluted, and the shape of the failure carries diagnostic signal. A widely used family of spectral methods analyzes the symmetric component of the degree-normalized attention operator, which governs transport capacity; we prove that every transpose-invariant spectral diagnostic of this operator is structurally orientation-blind (it cannot distinguish an operator from its transpose, and therefore cannot detect information-flow direction), with a quantitative converse establishing the asymmetry coefficient $G$ as the unique control parameter for direction. Pairing this with a closed-form bipartite-Cheeger landscape for canonical causal architectures, we show that uniform causal attention satisfies an $n$-independent floor $\phi \ge 1/5$ with worst cut at $t^\ast/n \approx 0.32$, while window attention pierces the floor as $O(w/n)$; failure modes are shape-different, not just value-different. The resulting two-axis diagnostic ($\phi$ for capacity, $G$ for direction) yields a falsifiable polarity prediction: bottleneck- and diffuse-dominated benchmarks should exhibit opposite polarity. Under length-controlled evaluation, transport features retain interpretable signal (LC-AUROC from 0.62 to 0.84) on tested models up to 8B parameters, with polarity reversing as predicted between HaluEval and MedHallu.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proves that every transpose-invariant spectral diagnostic of the degree-normalized attention operator is orientation-blind (cannot distinguish an operator from its transpose) and provides a quantitative converse showing the asymmetry coefficient G as the unique control parameter for information-flow direction. It derives closed-form bipartite-Cheeger landscapes for canonical causal architectures (uniform causal attention satisfies an n-independent floor φ ≥ 1/5 with worst cut at t*/n ≈ 0.32; window attention scales as O(w/n)), yielding a two-axis diagnostic (φ for transport capacity, G for direction) with a falsifiable polarity prediction tested on hallucination benchmarks (LC-AUROC 0.62–0.84 on models up to 8B, with polarity reversal between HaluEval and MedHallu).
Significance. If the theoretical results hold, the work offers a rigorous account of why symmetric spectral methods fail to capture directionality in attention and supplies closed-form, parameter-free expressions together with a falsifiable prediction on external benchmarks. These elements constitute a clear strength for interpretability research in transformers.
major comments (2)
- [Empirical results (LC-AUROC reporting)] The empirical validation of the two-axis diagnostic (LC-AUROC range 0.62–0.84) is load-bearing for the falsifiable polarity prediction yet reports no baselines, confidence intervals, or exclusion criteria for the length-controlled evaluation; this leaves the claim that transport features retain interpretable signal only partially supported.
- [Discussion of diagnostic applicability] The central application of the diagnostic presupposes that the degree-normalized attention operator’s capacity ϕ and direction G dominate observed hallucination modes, but the manuscript provides no ablation or isolation argument addressing potential confounding from feed-forward sublayers, layer-norm scaling, or output decoding.
minor comments (1)
- [Abstract and introduction] Notation for the asymmetry coefficient G and the transport capacity ϕ should be introduced with explicit definitions before their use in the abstract and main claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below, agreeing on the need for stronger empirical reporting and a clearer discussion of applicability. Revisions will be incorporated as indicated.
read point-by-point responses
-
Referee: The empirical validation of the two-axis diagnostic (LC-AUROC range 0.62–0.84) is load-bearing for the falsifiable polarity prediction yet reports no baselines, confidence intervals, or exclusion criteria for the length-controlled evaluation; this leaves the claim that transport features retain interpretable signal only partially supported.
Authors: We agree that the current empirical reporting is incomplete and weakens support for the claims. In the revised manuscript we will add: (i) explicit baselines including a random classifier (expected AUROC 0.5) and symmetric spectral baselines such as the algebraic connectivity of the symmetrized operator; (ii) 95% bootstrap confidence intervals over the benchmark instances; (iii) precise exclusion criteria for length-controlled evaluation (sequences outside [50, 2048] tokens discarded, with per-benchmark sample counts reported). These additions will be placed in a new subsection of the experiments and will not alter the reported LC-AUROC ranges or polarity reversal. We view this as a necessary and straightforward strengthening of the falsifiable prediction. revision: yes
-
Referee: The central application of the diagnostic presupposes that the degree-normalized attention operator’s capacity ϕ and direction G dominate observed hallucination modes, but the manuscript provides no ablation or isolation argument addressing potential confounding from feed-forward sublayers, layer-norm scaling, or output decoding.
Authors: The referee correctly notes the absence of isolation arguments. Our theoretical results and the two-axis diagnostic are defined strictly on the degree-normalized attention operator extracted after the softmax; the empirical tests therefore operate on attention weights alone. Nevertheless, we acknowledge that feed-forward sublayers, layer-norm, and decoding can still influence final outputs. In revision we will add a dedicated limitations paragraph that (a) states the diagnostic isolates transport by construction because it uses only attention matrices, (b) cites prior literature on attention’s dominant role in routing failures, and (c) explicitly flags the lack of component-wise ablations as a limitation, recommending future controlled experiments on attention-only or frozen-FFN models. Full empirical isolation is not feasible within the current revision cycle, so this constitutes a partial revision focused on interpretive clarity rather than new experiments. revision: partial
Circularity Check
No significant circularity; derivation is self-contained mathematical proof with external validation
full rationale
The paper derives the orientation-blindness of transpose-invariant spectral diagnostics and the uniqueness of G as direction control parameter directly from properties of the degree-normalized attention operator, then obtains closed-form bipartite-Cheeger bounds for specific architectures and tests the resulting polarity prediction on external hallucination benchmarks. No quoted step reduces a claimed result to a fitted parameter, self-defined quantity, or self-citation chain by construction; the LC-AUROC values are reported as independent empirical checks rather than tautological outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The degree-normalized attention operator can be decomposed into symmetric and antisymmetric parts that separately control transport capacity and direction.
- domain assumption Canonical causal attention architectures admit a bipartite graph representation whose Cheeger constant yields an n-independent lower bound.
invented entities (1)
-
asymmetry coefficient G
independent evidence
Reference graph
Works this paper leans on
-
[1]
Jakub Binkowski, Denis Janiak, Albert Sawczyn, Bogdan Gabrys, and Tomasz Jan Kajdanowicz. Hallucination detection in LLMs using spectral features of attention maps. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 24354--24385, Suzhou, China, 2025. Association for Computational Linguistics. doi:10.18...
-
[2]
A Lower Bound for the Smallest Eigenvalue of the Laplacian
Jeff Cheeger. A Lower Bound for the Smallest Eigenvalue of the Laplacian . In Robert C. Gunning, editor, Problems in Analysis : A Symposium in Honor of Salomon Bochner , pages 195--199. Princeton University Press, Princeton, NJ, 1970. Princeton Legacy Library reprint: 2015, ISBN 978-1-4008-6931-2
1970
-
[3]
INSIDE : LLMs ' internal states retain the power of hallucination detection
Chao Chen, Kai Liu, Ze Chen, Yi Gu, Yue Wu, Mingyuan Tao, Zhihang Fu, and Jieping Ye. INSIDE : LLMs ' internal states retain the power of hallucination detection. In The Twelfth International Conference on Learning Representations (ICLR 2024), 2024
2024
-
[4]
URL https: //doi.org/10.18653/v1/2024.emnlp-main.84
Yung-Sung Chuang, Linlu Qiu, Cheng-Yu Hsieh, Ranjay Krishna, Yoon Kim, and James Glass. Lookback lens: Detecting and mitigating contextual hallucinations in large language models using only attention maps. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1419--1436, Miami, Florida, USA, 2024. Association for...
-
[5]
Fan R. K. Chung. Spectral Graph Theory, volume 92 of CBMS Regional Conference Series in Mathematics. American Mathematical Society, 1997. ISBN 978-0-8218-0315-8
1997
-
[6]
Fan R. K. Chung. Laplacians and the Cheeger Inequality for Directed Graphs . Annals of Combinatorics, 9 0 (1): 0 1--19, April 2005. ISSN 0219-3094. doi:10.1007/s00026-005-0237-z
-
[7]
Attention is not all you need: Pure attention loses rank doubly exponentially with depth
Yihe Dong, Jean-Baptiste Cordonnier, and Andreas Loukas. Attention is not all you need: Pure attention loses rank doubly exponentially with depth. In Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 2793--2803. PMLR, 2021
2021
-
[8]
Davide Ettori, Nastaran Darabi, Sina Tayebati, Ranganath Krishnan, Mahesh Subedar, Omesh Tickoo, and Amit Ranjan Trivedi. EigenTrack : Spectral activation feature tracking for hallucination and out-of-distribution detection in LLMs and VLMs , 2025. URL https://arxiv.org/abs/2509.15735
-
[9]
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy. Nature, 630 0 (8017): 0 625--630, June 2024. ISSN 1476-4687. doi:10.1038/s41586-024-07421-0
-
[10]
James Allen Fill. Eigenvalue bounds on convergence to stationarity for nonreversible M arkov chains, with an application to the exclusion process. The Annals of Applied Probability, 1 0 (1): 0 62--87, 1991. doi:10.1214/aoap/1177005981
-
[11]
The emergence of clusters in self-attention dynamics
Borjan Geshkovski, Cyril Letrouit, Yury Polyanskiy, and Philippe Rigollet. The emergence of clusters in self-attention dynamics. In Advances in Neural Information Processing Systems, volume 36, pages 57026--57037, 2023
2023
-
[12]
Transformer Feed-Forward Layers Are Key-Value Memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5484--5495, 2021. doi:10.18653/v1/2021.emnlp-main.446
work page internal anchor Pith review doi:10.18653/v1/2021.emnlp-main.446 2021
-
[13]
Golub and Charles F
Gene H. Golub and Charles F. van Loan. Matrix Computations. Johns Hopkins University Press, 4th edition, 2013. ISBN 978-1-4214-0794-4
2013
-
[14]
Graham, Donald E
Ronald L. Graham, Donald E. Knuth, and Oren Patashnik. Concrete Mathematics: A Foundation for Computer Science. Addison-Wesley, 2nd edition, 1994. ISBN 978-0-201-55802-9
1994
-
[15]
Higher dimensional discrete Cheeger inequalities
Anna Gundert and May Szedl\'ak. Higher dimensional discrete Cheeger inequalities. Journal of Computational Geometry, 6 0 (2): 0 54--71, 2015. doi:10.20382/jocg.v6i2a4
-
[16]
Roger A. Horn and Charles R. Johnson. Matrix Analysis . Cambridge University Press, 2nd edition, 2012. ISBN 978-0-521-83940-2. doi:10.1017/CBO9781139020411
-
[17]
Tsz Chiu Kwok, Lap Chi Lau, Yin Tat Lee, Shayan Oveis Gharan, and Luca Trevisan. Improved Cheeger's inequality: Analysis of spectral partitioning algorithms through higher order spectral gap. In Proceedings of the Forty-Fifth Annual ACM Symposium on Theory of Computing (STOC), pages 11--20. ACM, 2013. doi:10.1145/2488608.2488611
-
[18]
Frustration index and Cheeger inequalities for discrete and continuous magnetic Laplacians
Carsten Lange, Shiping Liu, Norbert Peyerimhoff, and Olaf Post. Frustration index and Cheeger inequalities for discrete and continuous magnetic Laplacians . Calculus of Variations and Partial Differential Equations, 54 0 (4): 0 4165--4196, 2015. doi:10.1007/s00526-015-0935-x
-
[19]
James R. Lee, Shayan Oveis Gharan, and Luca Trevisan. Multiway spectral partitioning and higher-order Cheeger inequalities. Journal of the ACM, 61 0 (6): 0 1--30, 2014. doi:10.1145/2665063. Conference version in STOC 2012
-
[20]
Levin, Yuval Peres, and Elizabeth L
David A. Levin, Yuval Peres, and Elizabeth L. Wilmer. Markov chains and mixing times . American Mathematical Society, 2006
2006
-
[21]
H alu E val: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models
Junyi Li, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. HaluEval : A large-scale hallucination evaluation benchmark for large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6449--6464, Singapore, 2023. Association for Computational Linguistics. doi:10.18653/v1/2023.emnlp-main.397
-
[22]
Bradley Efron and Robert J Tibshirani.An introduction to the bootstrap, volume
Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA : Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214--3252, Dublin, Ireland, 2022. Association for Computational Linguistics. doi:10.18653/v1/2022.acl-long.229
-
[23]
Lov\'asz
L. Lov\'asz. Random walks on graphs: A survey. In D. Mikl\'os , V. T. S\'os , and T. Sz o nyi , editors, Combinatorics, Paul Erd o s is Eighty , volume 2, pages 353--398. J\'anos Bolyai Mathematical Society, Budapest, 1996
1996
-
[24]
Potsawee Manakul, Adian Liusie, and Mark J. F. Gales. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9004--9017, 2023. doi:10.18653/v1/2023.emnlp-main.557
-
[25]
Clustering by weighted cuts in directed graphs
Marina Meila and William Pentney. Clustering by weighted cuts in directed graphs. In Proceedings of the 2007 SIAM International Conference on Data Mining, pages 135--144, 2007. doi:10.1137/1.9781611972771.13
-
[26]
Locating and editing factual associations in GPT
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT . In Advances in Neural Information Processing Systems, volume 35, 2022
2022
-
[27]
FActScore: Fine-grained atomic evaluation of factual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen - tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. FActScore : Fine-grained atomic evaluation of factual precision in long form text generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 12076--12100, 2023. do...
-
[28]
In: Proceedings of the 2025 Conference on Empirical Meth- ods in Natural Language Processing
Shrey Pandit, Jiawei Xu, Junyuan Hong, Zhangyang Wang, Tianlong Chen, Kaidi Xu, and Ying Ding. MedHallu : A comprehensive benchmark for detecting medical hallucinations in large language models. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2858--2873, Suzhou, China, 2025. Association for Computational Li...
-
[29]
Ori Parzanchevski, Ron Rosenthal, and Ran J. Tessler. Isoperimetric inequalities in simplicial complexes. Combinatorica, 36 0 (2): 0 195--227, 2016. doi:10.1007/s00493-014-3002-x
-
[30]
Robins, Andrea Rotnitzky, and Lue Ping Zhao
James M. Robins, Andrea Rotnitzky, and Lue Ping Zhao. Estimation of regression coefficients when some regressors are not always observed. Journal of the American Statistical Association, 89 0 (427): 0 846--866, 1994. doi:10.1080/01621459.1994.10476818
-
[31]
Mind the gap: A spectral analysis of rank collapse and signal propagation in attention layers
Thiziri Nait Saada, Alireza Naderi, and Jared Tanner. Mind the gap: A spectral analysis of rank collapse and signal propagation in attention layers. In Proceedings of the 42nd International Conference on Machine Learning, Proceedings of Machine Learning Research. PMLR, 2025
2025
-
[32]
Approximate counting, uniform generation and rapidly mixing Markov chains
Alistair Sinclair and Mark Jerrum. Approximate counting, uniform generation and rapidly mixing Markov chains. Information and Computation, 82 0 (1): 0 93--133, 1989. ISSN 0890-5401. doi:10.1016/0890-5401(89)90067-9
-
[33]
LLM-Check : Investigating detection of hallucinations in large language models
Gaurang Sriramanan, Siddhant Bharti, Vinu Sankar Sadasivan, Shoumik Saha, Priyatham Kattakinda, and Soheil Feizi. LLM-Check : Investigating detection of hallucinations in large language models. In Advances in Neural Information Processing Systems, volume 37, 2024
2024
-
[34]
RoFormer: Enhanced transformer with Rotary Position Embedding , journal =
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer : Enhanced transformer with rotary position embedding. Neurocomputing, 568: 0 127063, 2024. doi:10.1016/j.neucom.2023.127063
-
[35]
Elena Voita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 5797--5808, 2019. doi:10.18653/v1/P19-1580
-
[36]
Statistics and Computing , year =
Ulrike von Luxburg . A tutorial on spectral clustering. Statistics and Computing, 17 0 (4): 0 395--416, December 2007. ISSN 0960-3174. doi:10.1007/s11222-007-9033-z
-
[37]
Jerry Wei, Chengrun Yang, Xinying Song, Yifeng Lu, Nathan Hu, Jie Huang, Dustin Tran, Daiyi Peng, Ruibo Liu, Da Huang, Cosmo Du, and Quoc V. Le. Long-form factuality in large language models. In Advances in Neural Information Processing Systems, volume 37, 2024
2024
-
[38]
Stabilizing transformer training by preventing attention entropy collapse
Shuangfei Zhai, Tatiana Likhomanenko, Etai Littwin, Dan Busbridge, Jason Ramapuram, Yizhe Zhang, Jiatao Gu, and Josh Susskind. Stabilizing transformer training by preventing attention entropy collapse. In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 40770--40803. PMLR, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.