Recognition: unknown
On the (In-)Security of the Shuffling Defense in the Transformer Secure Inference
Pith reviewed 2026-05-08 17:19 UTC · model grok-4.3
The pith
The shuffling defense for secure Transformer inference can be broken by aligning permuted activations across queries to recover model weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Revealing only randomly permuted activations does not prevent model extraction in Transformer secure inference; an attack that aligns the differently shuffled activations from independent queries to a common order enables accurate recovery of the model weights.
What carries the argument
The alignment procedure that solves for the permutation minimizing mean squared error between activations observed from separate queries.
If this is right
- Secure inference services that expose permuted activations remain open to practical model weight extraction.
- The efficiency benefit of computing nonlinear layers in plaintext comes with measurable leakage of the model parameters.
- Providers relying on the shuffling defense for Transformers must adopt stronger countermeasures to prevent alignment-based attacks.
Where Pith is reading between the lines
- The same alignment technique could be tested on larger models or different architectures to measure how query count scales with accuracy.
- Adding small amounts of noise to the revealed activations might raise the alignment error enough to block weight recovery.
- If queries share any hidden state or seed, the defense could become even weaker than the independent-permutation case studied here.
Load-bearing premise
Each query applies an independent random permutation with no correlation or additional side-channel protections across queries.
What would settle it
An experiment showing that activations from different queries cannot be aligned to a common permutation with low mean squared error would disprove the attack's ability to enable weight extraction.
Figures





read the original abstract
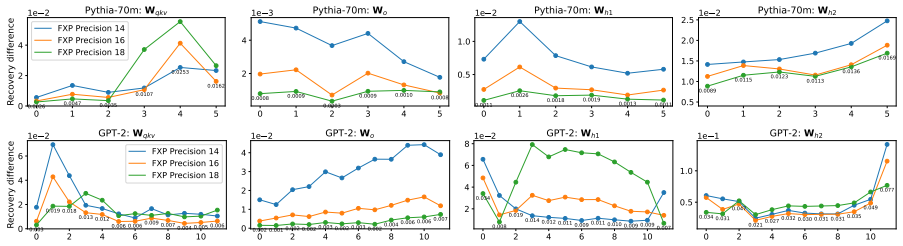
For Transformer models, cryptographically secure inference ensures that the client learns only the final output, while the server learns nothing about the client's input. However, securely computing nonlinear layers remains a major efficiency bottleneck due to the substantial communication rounds and data transmission required. To address this issue, prior works reveal intermediate activations to the client, allowing nonlinear operations to be computed in plaintext. Although this approach significantly improves efficiency, exposing activations enables adversaries to extract model weights. To mitigate this risk, existing works employ a shuffling defense that reveals only randomly permuted activations to the client. In this work, we show that the shuffling defense is not as robust as previously claimed. We propose an attack that aligns differently shuffled activations to a common permutation and subsequently exploits them to extract model weights. Experiments on Pythia-70m and GPT-2 demonstrate that the proposed attack can align shuffled activations with mean squared errors ranging from $10^{-9}$ to $10^{-6}$. With a query cost of approximately \$1, the adversary can recover model weights with L1-norm differences ranging from $10^{-4}$ to $10^{-2}$ compared to the oracle weights.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that the shuffling defense—randomly permuting intermediate activations before revealing them to the client in secure Transformer inference—is insecure. It presents an attack that recovers a common permutation across independently shuffled queries (achieving MSE alignment of 10^{-9} to 10^{-6}) and then extracts model weights with L1-norm error 10^{-4} to 10^{-2} at roughly $1 query cost, demonstrated empirically on Pythia-70m and GPT-2.
Significance. If the attack is correct and generalizes, it shows that permutation-based hiding of activations is insufficient to prevent weight recovery in activation-revealing secure inference protocols. This would be a concrete, low-cost counterexample to a previously proposed efficiency-security tradeoff and could prompt stronger defenses (e.g., additional noise, correlated permutations, or cryptographic nonlinear layers) in the design of private ML inference systems.
major comments (2)
- [§4 and §5] §4 (Attack Description) and §5 (Experiments): the alignment procedure is reported to succeed with very low MSE on Pythia-70m and GPT-2, yet the manuscript provides no ablation on activation collision rates or layer-norm effects. The skeptic note correctly flags that larger hidden sizes and post-norm statistics increase the risk of ambiguous matches; without a scaling experiment or a bound on the probability of unique values, the central claim that the attack works beyond the tested models remains load-bearing and unverified.
- [§3] §3 (Threat Model): the attack assumes each query receives an independent random permutation with no cross-query correlation or side-channel leakage. If the implementation re-uses randomness or the service batches queries, the alignment step could fail or become detectable; the paper should state whether this assumption was verified against the actual secure-inference codebase it attacks.
minor comments (2)
- [Table 1, Figure 2] Table 1 and Figure 2: axis labels and error-bar definitions are inconsistent between the alignment-MSE and weight-L1 plots; clarify whether the reported ranges are min/max or mean±std.
- [§5] The abstract states 'query cost of approximately $1' but the experimental section does not break down the exact number of queries or API pricing model used; add this detail for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We address each major comment below and indicate the changes made to the manuscript.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Attack Description) and §5 (Experiments): the alignment procedure is reported to succeed with very low MSE on Pythia-70m and GPT-2, yet the manuscript provides no ablation on activation collision rates or layer-norm effects. The skeptic note correctly flags that larger hidden sizes and post-norm statistics increase the risk of ambiguous matches; without a scaling experiment or a bound on the probability of unique values, the central claim that the attack works beyond the tested models remains load-bearing and unverified.
Authors: We appreciate the referee's point regarding the need for further analysis on activation collisions and layer-norm effects. The experiments in §5 are indeed limited to Pythia-70m and GPT-2. In the revised manuscript, we have added a discussion in §4 on the conditions for unique activations, including how post-layer-norm statistics can lead to higher collision risks in certain cases. We also note the absence of a formal bound or scaling experiment as a limitation in the updated §5. A comprehensive scaling study is beyond the current scope, but the low MSE achieved supports the attack's effectiveness on the evaluated models. revision: partial
-
Referee: [§3] §3 (Threat Model): the attack assumes each query receives an independent random permutation with no cross-query correlation or side-channel leakage. If the implementation re-uses randomness or the service batches queries, the alignment step could fail or become detectable; the paper should state whether this assumption was verified against the actual secure-inference codebase it attacks.
Authors: Regarding the threat model in §3, we have clarified in the revision that the assumption of independent random permutations per query is a standard modeling choice for analyzing the shuffling defense and was not verified against any specific secure-inference implementation or codebase. If real systems reuse randomness or batch queries, the attack's alignment step could indeed be affected, and we have added this caveat to the threat model section along with a brief discussion of potential defenses in the conclusion. revision: yes
Circularity Check
Empirical attack demonstration with no self-referential derivation or fitted predictions
full rationale
The paper proposes and evaluates an empirical attack to align independently shuffled activations across queries and recover Transformer weights, validated by direct comparison to oracle weights obtained outside the attack procedure. Experiments on Pythia-70m and GPT-2 report concrete MSE and L1-norm metrics without any mathematical derivation chain, uniqueness theorem, or parameter fitting that reduces the claimed result to its own inputs by construction. No load-bearing self-citations, ansatzes, or renamings of known results appear in the provided description; success is measured against external benchmarks rather than internal consistency. This is a standard empirical security analysis and remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Each query applies an independent uniform random permutation to the activations.
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
Pointer Sentinel Mixture Models , author=. International Conference on Learning Representations , year=
-
[2]
Network and Distributed System Security Symposium, NDSS , volume=
SHAFT: Secure, Handy, Accurate, and Fast Transformer Inference , author=. Network and Distributed System Security Symposium, NDSS , volume=
-
[3]
NDSS , year=
Secure Transformer Inference Made Non-interactive , author=. NDSS , year=
-
[4]
Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security , pages=
THOR: Secure transformer inference with homomorphic encryption , author=. Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security , pages=
2025
-
[5]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Powerformer: Efficient and High-Accuracy Privacy-Preserving Language Model with Homomorphic Encryption , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[6]
Advances in Neural Information Processing Systems , volume=
Heprune: Fast private training of deep neural networks with encrypted data pruning , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
ICLR 2025 Workshop on Building Trust in Language Models and Applications , year=
Hidden No More: Attacking and Defending Private Third-Party LLM Inference , author=. ICLR 2025 Workshop on Building Trust in Language Models and Applications , year=
2025
-
[8]
2022 , publisher=
Introduction to linear algebra , author=. 2022 , publisher=
2022
-
[9]
arXiv preprint arXiv:2407.18003
Keep the Cost Down: A Review on Methods to Optimize LLM's KV-Cache Consumption , author=. arXiv preprint arXiv:2407.18003 , year=
-
[10]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Centaur: bridging the impossible trinity of privacy, efficiency, and performance in privacy-preserving transformer inference , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[11]
2023 , url=
Elias Frantar and Saleh Ashkboos and Torsten Hoefler and Dan Alistarh , booktitle=. 2023 , url=
2023
-
[12]
Proceedings of Machine Learning and Systems , volume=
AWQ: Activation-aware Weight Quantization for On-Device LLM Compression and Acceleration , author=. Proceedings of Machine Learning and Systems , volume=
-
[13]
THE-X: Privacy-preserving transformer inference with homomorphic encryption,
The-x: Privacy-preserving transformer inference with homomorphic encryption , author=. arXiv preprint arXiv:2206.00216 , year=
-
[14]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Mpcvit: Searching for accurate and efficient mpc-friendly vision transformer with heterogeneous attention , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[15]
The approximate arithmetical solution by finite differences of physical problems involving differential equations, with an application to the stresses in a masonry dam , author=
IX. The approximate arithmetical solution by finite differences of physical problems involving differential equations, with an application to the stresses in a masonry dam , author=. Philosophical Transactions of the Royal Society of London. Series A, Containing Papers of a Mathematical or Physical Character , volume=. 1911 , publisher=
1911
-
[16]
arXiv preprint arXiv:2411.15707 , year=
Nimbus: Secure and Efficient Two-Party Inference for Transformers , author=. arXiv preprint arXiv:2411.15707 , year=
-
[17]
SIAM review , volume=
Solving ill-conditioned and singular linear systems: A tutorial on regularization , author=. SIAM review , volume=. 1998 , publisher=
1998
-
[18]
2025 , url =
OpenAI , title =. 2025 , url =
2025
-
[19]
2023 USENIX Annual Technical Conference (USENIX ATC 23) , pages=
\ SecretFlow-SPU \ : A Performant and \ User-Friendly \ Framework for \ Privacy-Preserving \ Machine Learning , author=. 2023 USENIX Annual Technical Conference (USENIX ATC 23) , pages=
2023
-
[20]
ACM Coffee Surveys , year =
John Smith and Krishna Das , title =. ACM Coffee Surveys , year =
-
[21]
Proceedings of the 23rd Annual ACM SIGCOFF Conference on Coffee Languages Design and Impelementation , year =
Alemu, Selamawit and Berhanu, Tadesse and Habte, Meseret , title =. Proceedings of the 23rd Annual ACM SIGCOFF Conference on Coffee Languages Design and Impelementation , year =
-
[22]
JavaBrew Journal , year =
Berhanu, Tadesse and Silva, Isabella and Mendez, Juan , title =. JavaBrew Journal , year =
-
[23]
CoffeeTech Quarterly , year =
Espresso, Oliver , title =. CoffeeTech Quarterly , year =
-
[24]
Proceedings of the Crazy Over-the-Top Specialty Coffee Pioneers (COSP) Conference , year =
Ricardo Cafeína and Isabela Pourover , title =. Proceedings of the Crazy Over-the-Top Specialty Coffee Pioneers (COSP) Conference , year =
-
[25]
Proceedings of the Operating System Support for Coffee Innovations (OSCI) Conference , year =
Marco Espresso and Sofia Cappuccino , title =. Proceedings of the Operating System Support for Coffee Innovations (OSCI) Conference , year =
-
[26]
Findings of the Association for Computational Linguistics: ACL 2022 , pages=
THE-X: Privacy-Preserving Transformer Inference with Homomorphic Encryption , author=. Findings of the Association for Computational Linguistics: ACL 2022 , pages=
2022
-
[27]
Strubell, Emma and Ganesh, Ananya and McCallum, Andrew. Energy and Policy Considerations for Deep Learning in NLP. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1355
-
[28]
Edward and Xiong, Wenjie and Lefaudeux, Benjamin and Knott, Brian and Annavaram, Murali and Lee, Hsien-Hsin S
Wang, Yongqin and Suh, G. Edward and Xiong, Wenjie and Lefaudeux, Benjamin and Knott, Brian and Annavaram, Murali and Lee, Hsien-Hsin S. , booktitle=. Characterization of MPC-based Private Inference for Transformer-based Models , year=
-
[29]
Annual international conference on the theory and applications of cryptographic techniques , pages=
Implementing gentry’s fully-homomorphic encryption scheme , author=. Annual international conference on the theory and applications of cryptographic techniques , pages=. 2011 , organization=
2011
-
[30]
and De Meulder, Fien
Tjong Kim Sang, Erik F. and De Meulder, Fien. Introduction to the C o NLL -2003 Shared Task: Language-Independent Named Entity Recognition. Proceedings of the Seventh Conference on Natural Language Learning at HLT - NAACL 2003. 2003
2003
-
[31]
International Conference on the Theory and Application of Cryptology and Information Security , pages=
Secret-shared shuffle , author=. International Conference on the Theory and Application of Cryptology and Information Security , pages=. 2020 , organization=
2020
-
[32]
Annual International Cryptology Conference , pages=
Private set intersection in the internet setting from lightweight oblivious PRF , author=. Annual International Cryptology Conference , pages=. 2020 , organization=
2020
-
[33]
, author=
GELU-Net: A Globally Encrypted, Locally Unencrypted Deep Neural Network for Privacy-Preserved Learning. , author=. IJCAI , pages=
-
[34]
30th USENIX Security Symposium (USENIX Security 21) , pages=
Muse: Secure inference resilient to malicious clients , author=. 30th USENIX Security Symposium (USENIX Security 21) , pages=
-
[35]
arXiv preprint arXiv:1906.00639 , year=
Bayhenn: Combining bayesian deep learning and homomorphic encryption for secure dnn inference , author=. arXiv preprint arXiv:1906.00639 , year=
-
[36]
Towards secure and practical machine learning via secret sharing and random permutation , journal =
Fei Zheng and Chaochao Chen and Xiaolin Zheng and Mingjie Zhu , keywords =. Towards secure and practical machine learning via secret sharing and random permutation , journal =. 2022 , issn =. doi:https://doi.org/10.1016/j.knosys.2022.108609 , url =
-
[37]
2021 IEEE Symposium on Security and Privacy (SP) , pages=
SiRnn: A math library for secure RNN inference , author=. 2021 IEEE Symposium on Security and Privacy (SP) , pages=. 2021 , organization=
2021
-
[38]
Gaussian Error Linear Units (GELUs)
Gaussian error linear units (gelus) , author=. arXiv preprint arXiv:1606.08415 , year=
work page internal anchor Pith review arXiv
-
[39]
International Conference on Learning Representations , year=
Do Wide and Deep Networks Learn the Same Things? Uncovering How Neural Network Representations Vary with Width and Depth , author=. International Conference on Learning Representations , year=
-
[40]
International Conference on Learning Representations , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. International Conference on Learning Representations , year=
-
[41]
Proceedings on Privacy Enhancing Technologies , volume=
Secure evaluation of quantized neural networks , author=. Proceedings on Privacy Enhancing Technologies , volume=
-
[42]
arXiv preprint arXiv:2011.11202 , year=
Effectiveness of MPC-friendly Softmax Replacement , author=. arXiv preprint arXiv:2011.11202 , year=
-
[43]
Advances in neural information processing systems , volume=
Xlnet: Generalized autoregressive pretraining for language understanding , author=. Advances in neural information processing systems , volume=
-
[44]
International Conference on Learning Representations , year=
SAFENet: A secure, accurate and fast neural network inference , author=. International Conference on Learning Representations , year=
-
[45]
29th USENIX Security Symposium (USENIX Security 20) , pages=
Delphi: A cryptographic inference service for neural networks , author=. 29th USENIX Security Symposium (USENIX Security 20) , pages=
-
[46]
Generating Long Sequences with Sparse Transformers
Generating long sequences with sparse transformers , author=. arXiv preprint arXiv:1904.10509 , year=
work page internal anchor Pith review arXiv 1904
-
[47]
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Transformer-xl: Attentive language models beyond a fixed-length context , author=. arXiv preprint arXiv:1901.02860 , year=
work page Pith review arXiv 1901
-
[48]
Advances in Neural Information Processing Systems , volume=
Big bird: Transformers for longer sequences , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
International Conference on Machine Learning , pages=
Transformer quality in linear time , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[50]
27th USENIX Security Symposium (USENIX Security 18) , pages=
\ GAZELLE \ : A low latency framework for secure neural network inference , author=. 27th USENIX Security Symposium (USENIX Security 18) , pages=
-
[51]
Advances in Neural Information Processing Systems , volume=
Crypten: Secure multi-party computation meets machine learning , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
, author=
Classification of Encrypted Word Embeddings using Recurrent Neural Networks. , author=. PrivateNLP@ WSDM , pages=
-
[53]
International Conference on Machine Learning , pages=
DeepReDuce: Relu reduction for fast private inference , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[54]
International Conference on Machine Learning , pages=
Selective Network Linearization for Efficient Private Inference , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[55]
CoRR , volume =
Jacob Devlin and Ming. CoRR , volume =. 2018 , url =
2018
-
[56]
ELECTRA: Pre-training text encoders as discriminators rather than generators
Electra: Pre-training text encoders as discriminators rather than generators , author=. arXiv preprint arXiv:2003.10555 , year=
-
[57]
2021 IEEE Symposium on Security and Privacy (SP) , pages=
CryptGPU: Fast privacy-preserving machine learning on the GPU , author=. 2021 IEEE Symposium on Security and Privacy (SP) , pages=. 2021 , organization=
2021
-
[58]
Deep Neural Networks as Gaussian Processes
Deep neural networks as gaussian processes , author=. arXiv preprint arXiv:1711.00165 , year=
-
[59]
arXiv preprint arXiv:1804.11271 , year=
Gaussian process behaviour in wide deep neural networks , author=. arXiv preprint arXiv:1804.11271 , year=
-
[60]
Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel R , journal=
-
[61]
and Brockett, Chris
Dolan, William B. and Brockett, Chris. Automatically Constructing a Corpus of Sentential Paraphrases. Proceedings of the Third International Workshop on Paraphrasing ( IWP 2005). 2005
2005
-
[62]
and Ng, Andrew and Potts, Christopher
Socher, Richard and Perelygin, Alex and Wu, Jean and Chuang, Jason and Manning, Christopher D. and Ng, Andrew and Potts, Christopher. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. 2013
2013
-
[63]
Semeval-2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation
Cer, Daniel and Diab, Mona and Agirre, Eneko and Lopez-Gazpio, I \ n igo and Specia, Lucia. S em E val-2017 Task 1: Semantic Textual Similarity Multilingual and Crosslingual Focused Evaluation. Proceedings of the 11th International Workshop on Semantic Evaluation ( S em E val-2017). 2017. doi:10.18653/v1/S17-2001
-
[64]
Williams, Adina and Nangia, Nikita and Bowman, Samuel. A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018. doi:10.18653/v1/N18-1101
-
[65]
SQuAD : 100,000+ questions for machine comprehension of text
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy. SQ u AD : 100,000+ Questions for Machine Comprehension of Text. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1264
-
[66]
Machine Learning Challenges Workshop , pages=
The PASCAL recognising textual entailment challenge , author=. Machine Learning Challenges Workshop , pages=. 2005 , organization=
2005
-
[67]
Proceedings of the second PASCAL challenges workshop on recognising textual entailment , volume=
The second pascal recognising textual entailment challenge , author=. Proceedings of the second PASCAL challenges workshop on recognising textual entailment , volume=. 2006 , organization=
2006
-
[68]
Proceedings of the ACL-PASCAL workshop on textual entailment and paraphrasing , pages=
The third pascal recognizing textual entailment challenge , author=. Proceedings of the ACL-PASCAL workshop on textual entailment and paraphrasing , pages=. 2007 , organization=
2007
-
[69]
, author=
The Fifth PASCAL Recognizing Textual Entailment Challenge. , author=. TAC , year=
-
[70]
Neural network acceptability judgments
Neural Network Acceptability Judgments , author=. arXiv preprint arXiv:1805.12471 , year=
-
[71]
Iyer, Shankar and Dandekar, Nikhil and Csernai, Kornel , title =
-
[72]
Thirteenth International Conference on the Principles of Knowledge Representation and Reasoning , year=
The winograd schema challenge , author=. Thirteenth International Conference on the Principles of Knowledge Representation and Reasoning , year=
-
[73]
Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence,
Learning Model with Error -- Exposing the Hidden Model of BAYHENN , author =. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence,. 2020 , month =. doi:10.24963/ijcai.2020/488 , url =
-
[74]
Reddi and Jonathan Hseu and Sanjiv Kumar and Srinadh Bhojanapalli and Xiaodan Song and James Demmel and Kurt Keutzer and Cho
Yang You and Jing Li and Sashank J. Reddi and Jonathan Hseu and Sanjiv Kumar and Srinadh Bhojanapalli and Xiaodan Song and James Demmel and Kurt Keutzer and Cho. Large Batch Optimization for Deep Learning: Training. 8th International Conference on Learning Representations,. 2020 , url =
2020
-
[75]
Journal of the American statistical Association , volume=
The Kolmogorov-Smirnov test for goodness of fit , author=. Journal of the American statistical Association , volume=. 1951 , publisher=
1951
-
[76]
, author=
Cheetah: Lean and Fast Secure Two-Party Deep Neural Network Inference. , author=. IACR Cryptol. ePrint Arch. , volume=
-
[77]
Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security , pages=
CrypTFlow2: Practical 2-party secure inference , author=. Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security , pages=
2020
-
[78]
International conference on machine learning , pages=
Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[79]
Proceedings of the IEEE international conference on computer vision , pages=
Delving deep into rectifiers: Surpassing human-level performance on imagenet classification , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[80]
A survey on privacy inference attacks and defenses in cloud-based Deep Neural Network , journal =
Xiaoyu Zhang and Chao Chen and Yi Xie and Xiaofeng Chen and Jun Zhang and Yang Xiang , keywords =. A survey on privacy inference attacks and defenses in cloud-based Deep Neural Network , journal =. 2023 , issn =. doi:https://doi.org/10.1016/j.csi.2022.103672 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.