Recognition: unknown
Delta-Based Neural Architecture Search: LLM Fine-Tuning via Code Diffs
Pith reviewed 2026-05-08 16:25 UTC · model grok-4.3
The pith
LLMs fine-tuned to output code diffs generate valid neural architectures at higher rates than full code synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
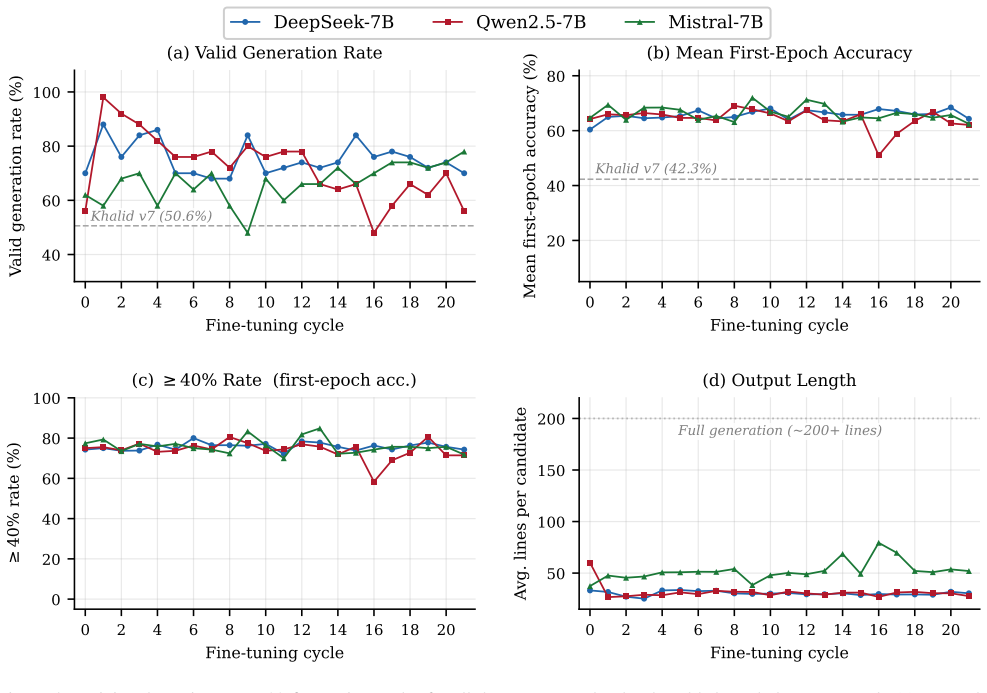
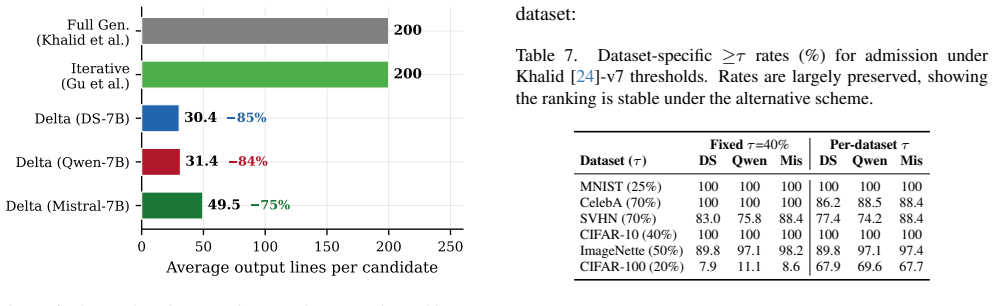
Delta-based generation lets fine-tuned LLMs produce unified diffs to iteratively refine baseline neural networks, yielding 75.3% valid rate and 65.8% mean first-epoch accuracy with DeepSeek-Coder, 72.1%/64.6% with Qwen2.5-Coder, and 66.6%/66.1% with Mistral, all above the full-generation baseline of 50.6% validity and 42.3% accuracy, while also reaching 85.5% best CIFAR-10 accuracy and shortening outputs to 30-50 lines.
What carries the argument
Delta-Code Generation: the iterative LoRA fine-tuning of an LLM on a MinHash-Jaccard filtered LEMUR dataset of architectures so that it outputs unified diffs to modify a baseline network instead of emitting full code.
If this is right
- The 1-epoch proxy reliably ranks architectures, as confirmed by Spearman ho = 0.926 in a 50-epoch study on Mistral.
- The same pipeline works across three different 7B LLMs without model-specific changes.
- Output length drops 75-85%, allowing more candidates within fixed token budgets.
- Performance gains hold on six datasets from CIFAR-10 to CelebA.
Where Pith is reading between the lines
- The delta approach could be applied to generate modifications for non-convolutional architectures or other modalities such as transformers.
- Combining delta outputs with existing search methods like evolutionary algorithms might accelerate convergence further.
- Shorter code sequences could enable on-device or interactive architecture search loops.
Load-bearing premise
That one-epoch accuracy preserves architecture rankings and that the filtered LEMUR dataset supplies training examples diverse enough for the fine-tuned LLM to generalize across domains.
What would settle it
If the top delta-generated architectures, when trained for the full 50 epochs, achieve lower final accuracy than the top full-generation architectures on the same dataset.
Figures






read the original abstract
Large language models (LLMs) show strong potential for neural architecture generation, yet existing approaches produce complete model implementations from scratch -- computationally expensive and yielding verbose code. We propose Delta-Code Generation, where fine-tuned LLMs generate compact unified diffs (deltas) to refine baseline architectures rather than synthesizing entire models. Our pipeline iteratively fine-tunes the LLM via LoRA on curated architectures from the LEMUR dataset, with MinHash-Jaccard novelty filtering for structural diversity. We evaluate three 7B-class LLMs -- DeepSeek-Coder-7B, Qwen2.5-Coder-7B, and Mistral-7B -- across six datasets (CIFAR-10, CIFAR-100, MNIST, SVHN, ImageNette, CelebA) using a 22-cycle protocol (1,100 candidates per LLM). All three substantially surpass the full-generation baseline (50.6% valid rate, 42.3% mean first-epoch accuracy): DeepSeek-Coder reaches 75.3% valid rate and 65.8% mean accuracy; Qwen2.5-Coder 72.1%/64.6%; Mistral 66.6%/66.1%. On CIFAR-10, best first-epoch accuracies reach 85.5% (Mistral), 85.2% (DeepSeek), 80.6% (Qwen) -- well above 63.98% full generation and 71.5% for the concurrent approach of Gu et al. Output lengths are 30-50 lines versus 200+ for full generation (75-85% reduction). A 50-epoch study confirms the 1-epoch proxy preserves rankings (Mistral: Spearman $\rho$ = 0.926). Delta-based generation is a token-efficient, multi-domain, LLM-agnostic alternative to full-model synthesis for LLM-driven NAS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Delta-Code Generation for LLM-driven neural architecture search, in which fine-tuned models generate compact unified diffs to refine baseline architectures rather than synthesizing full implementations. The pipeline uses LoRA fine-tuning on the LEMUR dataset with MinHash-Jaccard novelty filtering, and evaluates three 7B-class LLMs (DeepSeek-Coder, Qwen2.5-Coder, Mistral) over a 22-cycle protocol on six image-classification datasets. Reported results show substantially higher valid rates (66.6–75.3 %) and mean first-epoch accuracies (64.6–66.1 %) than the full-generation baseline (50.6 % valid, 42.3 % accuracy), together with 75–85 % shorter outputs; a 50-epoch study on Mistral supports the 1-epoch accuracy proxy (Spearman ρ = 0.926).
Significance. If the empirical gains and proxy validity hold, the delta-based formulation supplies a token-efficient, multi-domain, LLM-agnostic alternative to full-model synthesis for NAS. The reported reductions in output length and improvements in validity and early accuracy would constitute a practical advance for scaling LLM-assisted architecture search.
major comments (1)
- [Abstract] Abstract (and the 50-epoch proxy study): the Spearman ρ = 0.926 validation that the 1-epoch accuracy proxy preserves architecture rankings is reported only for Mistral. No equivalent full-training correlation is supplied for DeepSeek-Coder or Qwen2.5-Coder. Because the headline performance numbers (DeepSeek 65.8 % mean accuracy, Qwen 64.6 %, superiority over the 42.3 % full-generation baseline) rest on this proxy for all three models, the absence of validation for two of them is load-bearing for the central empirical claims.
minor comments (2)
- [Abstract] Abstract: the 22-cycle protocol and “1,100 candidates per LLM” are stated at high level only; explicit description of data splits, candidate-selection criteria, and exact LoRA hyperparameters would strengthen reproducibility.
- [Abstract] Abstract: the CIFAR-10 comparison to Gu et al. (71.5 %) lacks a full citation and a one-sentence characterization of their method.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The point regarding proxy validation is well-taken, and we address it directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the 50-epoch proxy study): the Spearman ρ = 0.926 validation that the 1-epoch accuracy proxy preserves architecture rankings is reported only for Mistral. No equivalent full-training correlation is supplied for DeepSeek-Coder or Qwen2.5-Coder. Because the headline performance numbers (DeepSeek 65.8 % mean accuracy, Qwen 64.6 %, superiority over the 42.3 % full-generation baseline) rest on this proxy for all three models, the absence of validation for two of them is load-bearing for the central empirical claims.
Authors: We agree that validating the 1-epoch proxy on all three models would strengthen the claims. The 50-epoch study was performed only on Mistral-7B due to the substantial computational cost of fully training 1,100+ candidate architectures to convergence for each LLM (approximately 50× the 1-epoch budget). Mistral was chosen because it produced the highest mean first-epoch accuracy, providing a conservative test of ranking preservation. The validity rates (66.6–75.3 %) are obtained directly from executable code and require no proxy. The first-epoch accuracy is used as an efficiency metric for NAS iteration, and the large, consistent gains over the full-generation baseline hold across all three models. In the revised manuscript we will (i) move the proxy discussion from the abstract to a dedicated subsection, (ii) explicitly state that the Spearman correlation was measured on Mistral, and (iii) add a limitations paragraph noting that the proxy is assumed to transfer to the other 7B code models given their architectural similarity and the model-agnostic nature of the 1-epoch vs. 50-epoch ranking question. We will also report the exact number of architectures used in the correlation study for transparency. revision: partial
Circularity Check
No circularity: purely empirical measurements against baselines
full rationale
The manuscript reports direct experimental outcomes from fine-tuning three LLMs on the LEMUR dataset and evaluating generated deltas on six image-classification tasks. All headline numbers (valid rates, 1-epoch accuracies, output-length reductions) are measured quantities compared to an explicit full-generation baseline; no equations, fitted parameters, or first-principles derivations are claimed. The single reported statistic (Spearman ρ = 0.926 for Mistral) is an empirical correlation check on a held-out 50-epoch study, not a self-referential definition or prediction that reduces to its own inputs. No self-citation chains, ansatzes, or uniqueness theorems appear in the provided text. The work is therefore self-contained empirical evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption One-epoch accuracy after training on the generated architecture is a reliable proxy for full training performance and ranking
invented entities (1)
-
Delta-Code Generation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Abdelfattah, Abhinav Mehrotra, Łukasz Dudziak, and Nicholas D
Mohamed S. Abdelfattah, Abhinav Mehrotra, Łukasz Dudziak, and Nicholas D. Lane. Zero-cost proxies for lightweight NAS. InInternational Conference on Learning Representations (ICLR), 2021. 13, 18
2021
-
[2]
Nada Aboudeshish, Dmitry Ignatov, and Radu Timofte. AUGMENTGEST: Can random data cropping augmentation boost gesture recognition performance?arXiv preprint, arXiv:2506.07216, 2025. 4
-
[3]
Zicheng Cai, Yaohua Tang, Yutao Lai, Hua Wang, Zhi Chen, and Hao Chen. SEKI: Self-evolution and knowledge inspira- tion based neural architecture search via large language mod- els.arXiv preprint arXiv:2502.20422, 2025. 1, 2, 3, 11
-
[4]
EvoPrompt- ing: Language models for code-level neural architecture search
Angelica Chen, David Dohan, and David So. EvoPrompt- ing: Language models for code-level neural architecture search. InAdvances in Neural Information Processing Sys- tems, 2023. 2, 3, 11
2023
-
[5]
Evaluating large lan- guage models trained on code.arXiv preprint, 2021
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Hen- rique Ponde de Oliveira Pinto, et al. Evaluating large lan- guage models trained on code.arXiv preprint, 2021. 2
2021
-
[6]
BERT: Pre-training of deep bidirectional trans- formers for language understanding.Proceedings of NAACL- HLT, pages 4171–4186, 2019
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional trans- formers for language understanding.Proceedings of NAACL- HLT, pages 4171–4186, 2019. 1 13
2019
-
[7]
AI on the edge: An automated pipeline for PyTorch-to-Android deployment and benchmarking.Preprints, 2025
Saif U Din, Muhammad Ahsan Hussain, Mohsin Ikram, Dmitry Ignatov, and Radu Timofte. AI on the edge: An automated pipeline for PyTorch-to-Android deployment and benchmarking.Preprints, 2025. 13
2025
-
[8]
Speeding up automatic hyperparameter optimization of deep neural networks by extrapolation of learning curves
Tobias Domhan, Jost Tobias Springenberg, and Frank Hut- ter. Speeding up automatic hyperparameter optimization of deep neural networks by extrapolation of learning curves. In Proceedings of the 24th International Joint Conference on Artificial Intelligence (IJCAI), pages 3460–3468, 2015. 13
2015
-
[9]
NAS-Bench-201: Extending the scope of reproducible neural architecture search.Inter- national Conference on Learning Representations (ICLR),
Xuanyi Dong and Yi Yang. NAS-Bench-201: Extending the scope of reproducible neural architecture search.Inter- national Conference on Learning Representations (ICLR),
-
[10]
Neural architecture search: A survey.Journal of Machine Learning Research, 20(55):1–21, 2019
Thomas Elsken, Jan Hendrik Metzen, and Frank Hutter. Neural architecture search: A survey.Journal of Machine Learning Research, 20(55):1–21, 2019. 1
2019
-
[11]
Mohamed Gado, Towhid Taliee, Muhammad Danish Memon, Dmitry Ignatov, and Radu Timofte. VIST-GPT: Ushering in the era of visual storytelling with LLMs?arXiv preprint, arXiv:2504.19267, 2025. 13
-
[12]
LEMUR neural net- work dataset: Towards seamless AutoML.arXiv preprint, arXiv:2504.10552, 2025
Arash Torabi Goodarzi, Roman Kochnev, Waleed Khalid, Furui Qin, Tolgay Atinc Uzun, Yashkumar Sanjaybhai Dhameliya, Yash Kanubhai Kathiriya, Zofia Antonina Ben- tyn, Dmitry Ignatov, and Radu Timofte. LEMUR neural net- work dataset: Towards seamless AutoML.arXiv preprint, arXiv:2504.10552, 2025. 3, 11
-
[13]
Resource- efficient iterative LLM-based NAS with feedback memory
Xiaojie Gu, Dmitry Ignatov, and Radu Timofte. Resource- efficient iterative LLM-based NAS with feedback memory. arXiv preprint, arXiv:2603.12091, 2026. Concurrent arXiv preprint (2026); disclosed for transparency. 1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 13, 18
-
[14]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, et al. DeepSeek-Coder: When the large language model meets programming – the rise of code intelligence.arXiv preprint arXiv:2401.14196, 2024. 1, 5
work page internal anchor Pith review arXiv 2024
-
[15]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016. 2
2016
-
[16]
Imagenette: A smaller subset of 10 eas- ily classified classes from ImageNet.https://github
Jeremy Howard. Imagenette: A smaller subset of 10 eas- ily classified classes from ImageNet.https://github. com/fastai/imagenette, 2019. 5
2019
-
[17]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InIn- ternational Conference on Learning Representations (ICLR),
-
[18]
Qwen2.5-Coder Technical Report
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayi- heng Liu, Fei Lei, Tianyu Liu, Jiajun Li, Kai Huang, Yichang Yang, Yang An, Ting Zhu, Bowen Yu, Chengyuan Hu, Jianhong Bai, Kai Bi, Jianqiang Gu, Jingren Wang, et al. Qwen2.5-Coder technical report.arXiv preprint, arXiv:2409.12186, 2024. 1, 5
work page internal anchor Pith review arXiv 2024
-
[19]
Krunal Jesani, Dmitry Ignatov, and Radu Timofte. LLM as a neural architect: Controlled generation of image cap- tioning models under strict API contracts.arXiv preprint, arXiv:2512.14706, 2025. 13
-
[20]
RZ-NAS: Enhancing LLM-guided neural architecture search via reflective zero-cost strategy
Zipeng Ji, Guanghui Zhu, Chunfeng Yuan, and Yihua Huang. RZ-NAS: Enhancing LLM-guided neural architecture search via reflective zero-cost strategy. InProceedings of the 42nd International Conference on Machine Learning (ICML),
-
[21]
Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lam- ple, Lucile Saulnier, L ´elio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timoth ´ee Lacroix, and William El Sayed. Mistral 7B.arXiv preprint arX...
work page internal anchor Pith review arXiv 2023
-
[22]
SWE- bench: Can language models resolve real-world GitHub is- sues?International Conference on Learning Representa- tions (ICLR), 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE- bench: Can language models resolve real-world GitHub is- sues?International Conference on Learning Representa- tions (ICLR), 2024. 2, 12
2024
-
[23]
Waleed Khalid, Dmitry Ignatov, and Radu Timofte. A retrieval-augmented generation approach to extracting al- gorithmic logic from neural networks.arXiv preprint, arXiv:2512.04329, 2025. 2
-
[24]
From Memorization to Creativity: LLM as a Designer of Novel Neural Architectures
Waleed Khalid, Dmitry Ignatov, and Radu Timofte. From memorization to creativity: LLM as a designer of novel neural-architectures.arXiv preprint, arXiv:2601.02997,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 16, 17, 18
Updated v7 (2026) adds CIFAR-100 and SVHN results with dataset-specific thresholds (20%/70%) and Wilson/t-based 95% confidence intervals. 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 16, 17, 18
2026
-
[26]
Roman Kochnev, Arash Torabi Goodarzi, Zofia Antonina Bentyn, Dmitry Ignatov, and Radu Timofte. Optuna vs code llama: Are LLMs a new paradigm for hyperparameter tun- ing? InProceedings of the IEEE/CVF International Confer- ence on Computer Vision Workshops (ICCVW), pages 5664– 5674, 2025. 2
2025
-
[27]
NNGPT: Rethinking AutoML with large language models.arXiv preprint, arXiv:2511.02033,
Roman Kochnev, Waleed Khalid, Tolgay Atinc Uzun, Xi Zhang, Yashkumar Sanjaybhai Dhameliya, Furui Qin, Chan- dini Vysyaraju, Raghuvir Duvvuri, Avi Goyal, Dmitry Igna- tov, and Radu Timofte. NNGPT: Rethinking AutoML with large language models.arXiv preprint, arXiv:2511.02033,
-
[28]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009. 5
2009
-
[29]
Gradient-based learning applied to document recog- nition.Proceedings of the IEEE, 86(11):2278–2324, 1998
Yann LeCun, L ´eon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recog- nition.Proceedings of the IEEE, 86(11):2278–2324, 1998. 5
1998
-
[30]
Zero-shot neural architecture search: Chal- lenges, solutions, and opportunities.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(6):4071– 4088, 2024
Guihong Li et al. Zero-shot neural architecture search: Chal- lenges, solutions, and opportunities.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(6):4071– 4088, 2024. 2
2024
-
[31]
DARTS: Differentiable architecture search
Hanxiao Liu, Karen Simonyan, and Yiming Yang. DARTS: Differentiable architecture search. InInternational Confer- ence on Learning Representations (ICLR), 2019. 1, 2, 11
2019
-
[32]
arXiv preprint arXiv:2402.02172 , year=
Jiawei Liu et al. A survey on LLM-based agents for code generation.arXiv preprint arXiv:2402.02172, 2024. 2
-
[33]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. InProceedings 14 of the IEEE International Conference on Computer Vision (ICCV), pages 3730–3738, 2015. 5
2015
-
[34]
Neural architecture search without training.In- ternational Conference on Machine Learning (ICML), pages 7588–7598, 2021
Joseph Mellor, Jack Turner, Amos Storkey, and Elliot J Shersby. Neural architecture search without training.In- ternational Conference on Machine Learning (ICML), pages 7588–7598, 2021. 2
2021
-
[35]
Preparation of Fractal-Inspired Computational Architectures for Automated Neural Design Exploration
Yash Mittal, Dmitry Ignatov, and Radu Timofte. Prepara- tion of fractal-inspired computational architectures for ad- vanced large language model analysis.arXiv preprint, arXiv:2511.07329, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Muhammad U Nasir, Sam Earle, Christopher Cleghorn, Steven James, and Julian Togelius. LLMatic: Neural ar- chitecture search via large language models and quality- diversity optimization.arXiv preprint arXiv:2306.01102,
-
[37]
1, 2, 3, 11
Also in GECCO 2024. 1, 2, 3, 11
2024
-
[38]
Reading digits in natural images with unsupervised feature learning.NeurIPS Work- shop on Deep Learning and Unsupervised Feature Learning,
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bis- sacco, Bo Wu, and Andrew Y Ng. Reading digits in natural images with unsupervised feature learning.NeurIPS Work- shop on Deep Learning and Unsupervised Feature Learning,
-
[39]
SW AP-NAS: Sample-wise activation patterns for ultra- fast NAS
Yameng Peng, Andy Huang, Zhixin Chen, Caiyang Wu, et al. SW AP-NAS: Sample-wise activation patterns for ultra- fast NAS. InInternational Conference on Learning Repre- sentations (ICLR), 2024. 18
2024
-
[40]
Efficient neural architecture search via parameter sharing
Hieu Pham, Melody Guan, Barret Zoph, Quoc V Le, and Jeff Dean. Efficient neural architecture search via parameter sharing. InInternational Conference on Machine Learning (ICML), pages 4095–4104, 2018. 2, 11
2018
-
[41]
An automated multi parameter neural archi- tecture discovery framework using ChatGPT in the backend
Md Hafizur Rahman, Zafaryab Haider, and Prabuddha Chakraborty. An automated multi parameter neural archi- tecture discovery framework using ChatGPT in the backend. Scientific Reports, 15(16871), 2025. 2, 3, 11
2025
-
[42]
Regularized evolution for image classifier architecture search
Esteban Real, Alok Aggarwal, Yanping Huang, and Quoc V Le. Regularized evolution for image classifier architecture search. InProceedings of the AAAI Conference on Artificial Intelligence, pages 4780–4789, 2019. 2
2019
-
[43]
Code Llama: Open Foundation Models for Code
Baptiste Rozi `ere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. Code LLama: Open foundation models for code.arXiv preprint arXiv:2308.12950, 2023. 1
work page internal anchor Pith review arXiv 2023
-
[44]
Explor- ing the collaboration between vision models and llms for en- hanced image classification.Preprints, 2025
Bhavya Rupani, Dmitry Ignatov, and Radu Timofte. Explor- ing the collaboration between vision models and llms for en- hanced image classification.Preprints, 2025. 13
2025
-
[45]
From brute force to semantic insight: Performance-guided data transformation design with LLMs.arXiv preprint, 2026
Usha Shrestha, Dmitry Ignatov, and Radu Timofte. From brute force to semantic insight: Performance-guided data transformation design with LLMs.arXiv preprint, 2026. 3
2026
-
[46]
EfficientNet: Rethinking model scaling for convolutional neural networks
Mingxing Tan and Quoc Le. EfficientNet: Rethinking model scaling for convolutional neural networks. InInter- national Conference on Machine Learning (ICML), pages 6105–6114, 2019. 2, 11
2019
-
[47]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. LLaMA: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. 1
work page internal anchor Pith review arXiv 2023
-
[48]
Closed-Loop LLM Discovery of Non-Standard Channel Priors in Vision Models
Tolgay Atinc Uzun, Dmitry Ignatov, and Radu Timofte. Closed-loop LLM discovery of non-standard channel priors in vision models.arXiv preprint, arXiv:2601.08517, 2026. 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
LEMUR 2: Unlocking neural network diversity for AI.arXiv preprint, 2026
Tolgay Atinc Uzun, Waleed Khalid, Saif U Din, Sai Revanth Mulukuledu, Akashdeep Singh, Chandini Vysyaraju, Raghu- vir Duvvuri, Avi Goyal, Dmitry Ignatov, Radu Timofte, et al. LEMUR 2: Unlocking neural network diversity for AI.arXiv preprint, 2026. 3
2026
-
[50]
Chandini Vysyaraju, Raghuvir Duvvuri, Avi Goyal, Dmitry Ignatov, and Radu Timofte. Enhancing LLM-based neural network generation: Few-shot prompting and efficient val- idation for automated architecture design.arXiv preprint, arXiv:2512.24120, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [51]
-
[52]
Edwin B. Wilson. Probable inference, the law of succession, and statistical inference.J. Am. Stat. Assoc., 22(158):209– 212, 1927. 5
1927
-
[53]
Automated program repair in the era of large pre-trained lan- guage models.arXiv preprint, 2023
Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. Automated program repair in the era of large pre-trained lan- guage models.arXiv preprint, 2023. 2
2023
-
[54]
Automl-gpt: Automatic machine learning with gpt
Shujian Zhang, Chengyue Gong, Lemeng Wu, Xingchao Liu, and Mingyuan Zhou. AutoML-GPT: Automatic ma- chine learning with GPT.arXiv preprint arXiv:2305.02499,
-
[55]
Can GPT-4 perform neural architecture search?arXiv preprint arXiv:2304.10970, 2023
Mingkai Zheng, Xiu Su, Shan You, Fei Wang, Chen Qian, Chang Xu, and Samuel Albanie. Can GPT-4 perform neural architecture search?arXiv preprint arXiv:2304.10970, 2023. 2, 11
-
[56]
EcoNAS: Finding proxies for economical neural architecture search
Dongzhan Zhou, Xinchi Zhou, Wenwei Zhang, Chen Change Loy, Shuai Yi, Xuesen Zhang, and Wanli Ouyang. EcoNAS: Finding proxies for economical neural architecture search. InIEEE Conf. Comput. Vis. Pattern Recog. (CVPR), pages 11396–11404, 2020. 13, 18
2020
-
[57]
Neural architecture search with reinforcement learning
Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning. InInternational Conference on Learning Representations (ICLR), 2017. 1, 2, 11 15 A. Additional Method Details A.1. MinHash/LSH Configuration for Novelty Fil- tering We employ MinHash-based near-duplicate detection [24] to ensure structural diversity in the training corpus. ...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.