Recognition: 1 theorem link
Curated AI beats frontier LLMs at pharma asset discovery
Pith reviewed 2026-05-08 18:18 UTC · model grok-4.3
The pith
A curated AI platform identifies 3.2 times more verified drugs than leading general LLMs on niche pharma targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
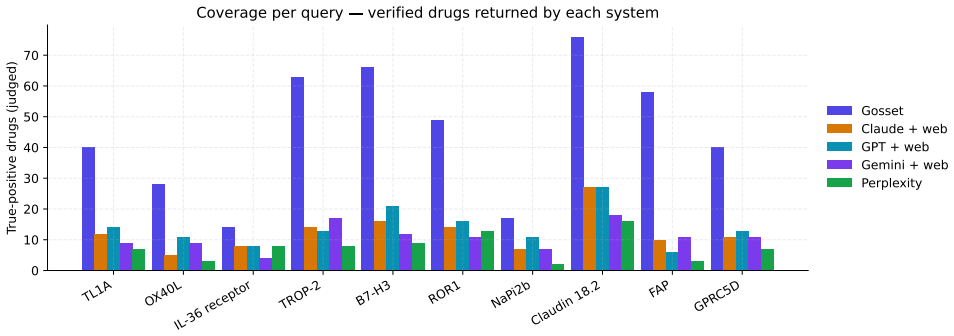
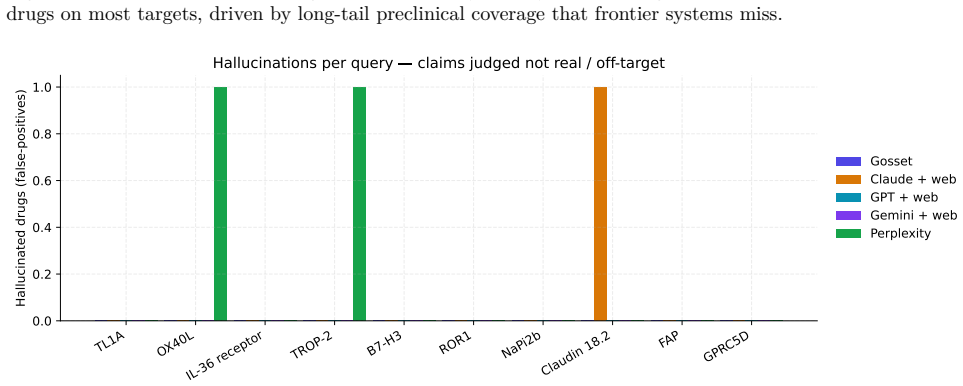
Gosset, an AI platform backed by curated target-, modality-, and indication-level drug-asset annotations, returns 3.2 times more verified drugs per query than the best frontier system across the ten targets, while achieving perfect precision and 100 percent recall against the union of verified drugs identified by all five systems.
What carries the argument
The curated index of drug-asset annotations, which powers the chat interface and can also be exposed as a callable tool to other models.
If this is right
- The same curated index can be added as a tool to frontier LLMs to close most of the recall gap without changing the chat interface.
- General web search performs worse on long-tail preclinical and Asia-developed assets than on well-known late-stage programs.
- Specialized annotation layers can deliver both higher volume and higher reliability than broad retrieval for competitive-intelligence tasks.
- The performance difference is large enough that organizations scouting pipelines may prefer platforms with dedicated indexes over generic LLM access.
Where Pith is reading between the lines
- Similar curated indexes could narrow performance gaps in other narrow domains where frontier models currently rely on noisy web data.
- The result points to a practical path for improving LLM accuracy on factual retrieval by swapping generic search for domain-specific structured data.
- Companies holding proprietary pipeline data may gain an advantage by exposing it through tool interfaces rather than keeping it behind internal models only.
Load-bearing premise
The process used to confirm which listed assets are real, verified pipeline drugs is free of bias that would favor the curated system.
What would settle it
An independent review of every drug asset returned by any system that reclassifies a substantial fraction of the curated system's extra findings as unverified or the frontier systems' misses as verified.
Figures



read the original abstract
General-purpose LLMs with web search are increasingly used to scout the competitive landscape of pharmaceutical pipelines. We benchmark Gosset -- an AI platform with a chat interface backed by curated target-, modality-, and indication-level drug-asset annotations -- against four frontier systems with web access (Claude Opus 4.7, GPT 5.5, Gemini 3.1 Pro, Perplexity sonar-pro) on ten niche oncology/immunology targets where most of the pipeline lives in the long tail of preclinical and Asian-developed assets. All five systems receive the same natural-language query and the same JSON output schema. Across 10 targets Gosset returns 3.2x more verified drugs per query than the best frontier system, at perfect precision and 100% recall against the cross-system union of verified drugs. The same curated index is exposed as a Gosset MCP server that any frontier model can call as a tool, suggesting that each of these systems can close most of the recall gap by swapping generic web search for a curated index behind the same chat interface.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript benchmarks Gosset, a chat-based AI platform backed by curated target-, modality-, and indication-level drug-asset annotations, against four frontier LLMs with web search (Claude Opus 4.7, GPT 5.5, Gemini 3.1 Pro, Perplexity sonar-pro) on ten niche oncology/immunology targets. All systems receive identical natural-language queries and JSON output schemas. The central empirical claim is that Gosset returns 3.2x more verified drugs per query than the best frontier system while achieving perfect precision and 100% recall against the cross-system union of verified drugs. The paper further proposes exposing the same curated index as an MCP server tool that frontier models can call to close the recall gap.
Significance. If the verification protocol is shown to be fully independent of the Gosset index and reproducible, the result would quantify the advantage of curated domain-specific annotations over generic web retrieval for long-tail pharmaceutical pipeline scouting. The work also demonstrates a practical path for tool integration (MCP server) that could be adopted by general-purpose systems. The benchmark design with fixed queries and output schema is a strength that allows direct comparison.
major comments (3)
- [Abstract and Methods] Abstract and Methods: The definition of 'verified drugs' and the verification process are not described. It is unclear whether verification relies on independent public sources, manual review independent of the Gosset curated annotations, or post-hoc matching to the Gosset index. Without an explicit, system-agnostic protocol, the claims of perfect precision and 100% recall against the cross-system union risk partial circularity, as the union itself may be shaped by assets already indexed by Gosset.
- [Results] Results: The 3.2x multiplier and performance gap are presented as evidence of curated-index superiority, yet no details are given on how the ten targets were selected, whether query difficulty was balanced for long-tail preclinical/Asian assets, or any controls for web-search limitations versus curated coverage. This leaves the quantitative superiority potentially confounded by data-source differences rather than model capability.
- [Discussion] Discussion: The suggestion that frontier models can close the gap by calling the Gosset MCP server is promising, but the manuscript provides no empirical test of this integration (e.g., performance of a frontier model with the tool enabled). The central claim therefore rests on an untested extrapolation.
minor comments (2)
- [Methods] The JSON output schema is referenced but not shown; including an example in the appendix would improve reproducibility.
- [Results] Table or figure summarizing per-target results (number of verified drugs per system) is needed to support the aggregate 3.2x claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments have prompted us to clarify key aspects of the verification protocol and target selection in the revised manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and Methods] Abstract and Methods: The definition of 'verified drugs' and the verification process are not described. It is unclear whether verification relies on independent public sources, manual review independent of the Gosset curated annotations, or post-hoc matching to the Gosset index. Without an explicit, system-agnostic protocol, the claims of perfect precision and 100% recall against the cross-system union risk partial circularity, as the union itself may be shaped by assets already indexed by Gosset.
Authors: We agree that the verification process must be described explicitly to eliminate any risk of circularity. Verification was performed independently of the Gosset index through manual cross-referencing against public sources including PubMed, ClinicalTrials.gov, FDA databases, and company pipeline disclosures. Assets were marked verified only if corroborated by at least one such source. The cross-system union was assembled after verification to serve as a common ground truth. We have added a new 'Verification Protocol' subsection to the Methods section detailing this reproducible, system-agnostic procedure and the exact criteria used. revision: yes
-
Referee: [Results] Results: The 3.2x multiplier and performance gap are presented as evidence of curated-index superiority, yet no details are given on how the ten targets were selected, whether query difficulty was balanced for long-tail preclinical/Asian assets, or any controls for web-search limitations versus curated coverage. This leaves the quantitative superiority potentially confounded by data-source differences rather than model capability.
Authors: The ten targets were selected by domain experts to represent niche oncology and immunology indications dominated by preclinical and Asian-developed assets. We have expanded the Results section to list all targets explicitly, provide the selection rationale, and document that query difficulty was balanced by pre-estimating asset counts from public registries. The benchmark controls for model capability by enforcing identical natural-language queries and JSON output schemas across all systems; frontier models operated exclusively with their native web-search tools. While data-source differences are inherent to the comparison, they reflect the practical distinction between curated versus generic retrieval. A new paragraph addresses potential confounds and justifies the design. revision: yes
-
Referee: [Discussion] Discussion: The suggestion that frontier models can close the gap by calling the Gosset MCP server is promising, but the manuscript provides no empirical test of this integration (e.g., performance of a frontier model with the tool enabled). The central claim therefore rests on an untested extrapolation.
Authors: We acknowledge that the manuscript contains no empirical evaluation of the MCP server integration. The primary result is the benchmark performed without tool augmentation. The MCP proposal is offered as a suggested integration path rather than a tested claim. In the revised Discussion we have added explicit language distinguishing the benchmark findings from the untested proposal, included a limitations paragraph noting the absence of tool-enabled experiments, and outlined planned follow-up work to evaluate the integration. revision: partial
Circularity Check
Empirical benchmark exhibits no circularity
full rationale
The paper presents a direct empirical comparison of five systems on identical natural-language queries for 10 targets, measuring outputs against a cross-system union of verified drugs. No mathematical derivation chain, equations, fitted parameters, or self-referential definitions appear in the provided text. The 3.2x multiplier, perfect precision, and 100% recall claims rest on external verification rather than reducing to Gosset's index by construction. The curated index is positioned as an input differentiator (exposed via MCP server), not as a hidden tautology defining the verification labels themselves. This is a standard head-to-head evaluation against an external benchmark; no load-bearing self-citation or ansatz smuggling is present.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The curated annotations in Gosset are accurate and complete for the targets tested.
- domain assumption The union of all systems' outputs provides a reasonable ground truth for recall calculation.
Reference graph
Works this paper leans on
-
[1]
Anthropic.Claude Opus 4.7.https://www.anthropic.com/news/claude-opus-4-7, 2026
2026
-
[2]
OpenAI.GPT-5.5 system card.https://openai.com/research/gpt-5-5, 2026
2026
-
[3]
https://deepmind.google/ technologies/gemini/, 2026
Google DeepMind.Gemini 3.1 Pro: native search-grounded reasoning. https://deepmind.google/ technologies/gemini/, 2026
2026
-
[4]
Perplexity AI.Sonar Pro: a real-time web search model.https://docs.perplexity.ai/docs/model-cards, 2026
2026
-
[5]
Z. Ji, N. Lee, R. Frieske, et al.Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38, 2023
2023
-
[6]
Lewis, E
P. Lewis, E. Perez, A. Piktus, et al.Retrieval-augmented generation for knowledge-intensive NLP tasks. NeurIPS, 2020
2020
-
[7]
National Library of Medicine.ClinicalTrials.gov.https://clinicaltrials.gov/, accessed 2026
U.S. National Library of Medicine.ClinicalTrials.gov.https://clinicaltrials.gov/, accessed 2026
2026
-
[8]
https://www.anthropic.com/news/ model-context-protocol, 2024
Anthropic.Introducing the Model Context Protocol. https://www.anthropic.com/news/ model-context-protocol, 2024
2024
-
[9]
Zheng, W.-L
L. Zheng, W.-L. Chiang, Y. Sheng, et al.Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. NeurIPS Datasets and Benchmarks, 2023. 5
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.