Recognition: 3 theorem links
· Lean TheoremA Foundation Model for Zero-Shot Logical Rule Induction
Pith reviewed 2026-05-08 18:11 UTC · model grok-4.3
The pith
A pretrained neural model can induce logical rules zero-shot in new domains by representing literals through statistical properties instead of their specific identities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that a model can perform zero-shot logical rule induction by encoding literals with domain-agnostic statistical properties such as class-conditional rates, entropy, and co-occurrence. This representation, handled by a statistical encoder and a parallel slot-based decoder with product T-norm relaxation for differentiability, allows generalization across different variable counts and predicate vocabularies without retraining on new tasks.
What carries the argument
The domain-agnostic statistical encoding of literals using class-conditional rates, entropy, and co-occurrence patterns, processed by a statistical encoder and parallel slot-based decoder.
If this is right
- The model accurately recovers rules from data even in the presence of label noise and spurious correlations.
- Zero-shot transfer is possible to real-world benchmarks using the same pretrained weights.
- Parallel decoding ensures that the order of clauses does not affect the logical disjunction.
- Training can be done solely based on prediction accuracy because the rule execution is made differentiable via the product T-norm.
Where Pith is reading between the lines
- This suggests that aggregate statistics over data can substitute for explicit symbolic identities in capturing logical structure.
- Similar statistical encodings might support zero-shot transfer in other areas of symbolic AI such as theorem proving or planning.
- Applying the model to larger scale problems with more complex rule forms could test how far the statistical approach extends.
Load-bearing premise
The chosen statistical properties of literals must contain sufficient information about their logical roles to support accurate rule induction when applied to completely unfamiliar domains and predicate sets.
What would settle it
The central claim would be disproven by a dataset of logical rules where the correct induction requires distinguishing predicates based on information not present in their class-conditional rates, entropy values, or co-occurrence counts, leading to poor performance on that data.
Figures


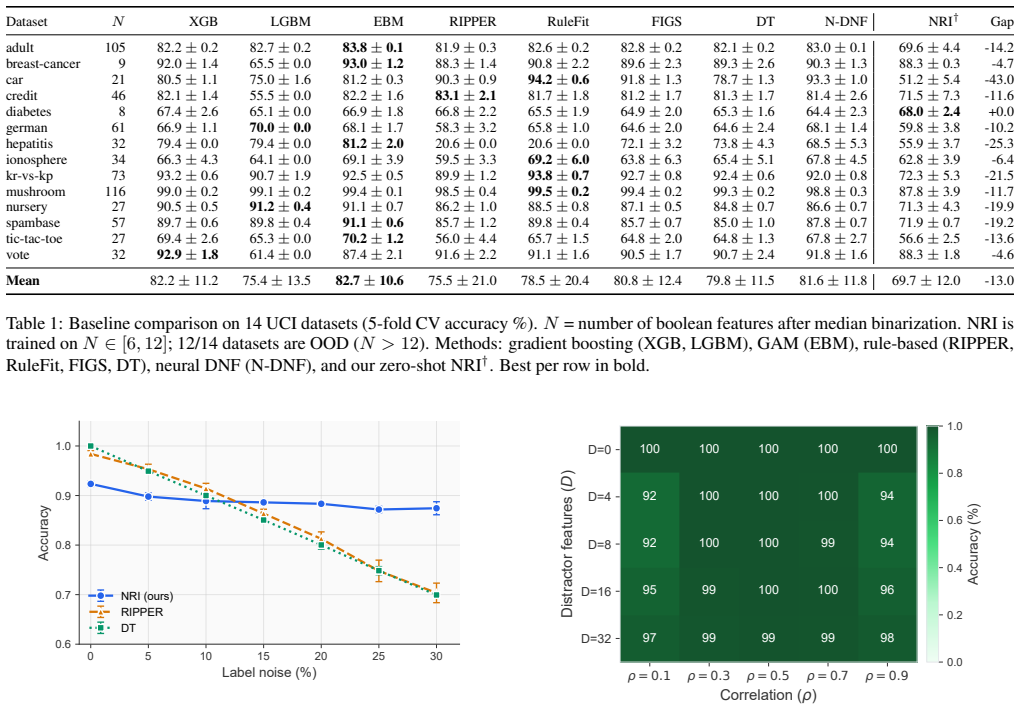

read the original abstract
Inductive Logic Programming (ILP) learns interpretable logical rules from data. Existing methods are transductive: their learned parameters are bound to specific predicates and require retraining for each new task. We introduce Neural Rule Inducer (NRI), a pretrained model for zero-shot rule induction. Rather than encoding literal identities, NRI represents literals using domain-agnostic statistical properties such as class-conditional rates, entropy, and co-occurrence, which generalize across variable identities and counts without retraining. The model consists of a statistical encoder and a parallel slot-based decoder. Parallel decoding preserves the permutation invariance of logical disjunction; an autoregressive decoder would instead impose an arbitrary clause order. Product T-norm relaxation makes rule execution differentiable, allowing end-to-end training on prediction accuracy alone. We evaluate NRI on rule recovery, robustness to label noise and spurious correlations, and zero-shot transfer to real-world benchmarks, and we believe this work opens up the possibility of foundation models for symbolic reasoning. Code and the reference checkpoint are available at https://github.com/phuayj/neural-rule-inducer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Neural Rule Inducer (NRI), a pretrained foundation model for zero-shot inductive logic programming. It encodes literals via domain-agnostic statistical features (class-conditional rates, entropy, co-occurrence) rather than predicate identities, using a statistical encoder paired with a parallel slot-based decoder. Product T-norm relaxation enables differentiable rule execution, and the design claims to support generalization across variable identities and counts without retraining. Evaluations are described on rule recovery, robustness to label noise and spurious correlations, and zero-shot transfer to real-world benchmarks.
Significance. If the claims hold, the work would mark a meaningful advance toward foundation models for symbolic reasoning by removing the transductive constraint of prior ILP methods. The parallel decoder for permutation invariance and the choice of statistical features are interesting architectural decisions. Releasing code and a reference checkpoint is a positive step for reproducibility.
major comments (2)
- [Abstract] Abstract: the central claim that class-conditional rates, entropy, and co-occurrence suffice for zero-shot rule induction is load-bearing yet unsupported; the manuscript supplies no argument, completeness proof, or counter-example showing these aggregates preserve enough logical structure to distinguish distinct Horn or Datalog rules that share the same marginal statistics.
- [Abstract] Abstract: despite stating that NRI is evaluated on rule recovery, robustness, and zero-shot transfer, the text contains no quantitative results, error bars, ablation studies, or performance numbers, preventing any assessment of whether the architecture achieves the claimed zero-shot generalization.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the manuscript accordingly to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that class-conditional rates, entropy, and co-occurrence suffice for zero-shot rule induction is load-bearing yet unsupported; the manuscript supplies no argument, completeness proof, or counter-example showing these aggregates preserve enough logical structure to distinguish distinct Horn or Datalog rules that share the same marginal statistics.
Authors: We agree that the abstract presents this claim without a supporting argument, proof, or counter-example. The features were selected to provide domain-agnostic encodings of literal properties that are invariant to predicate identity. In the revision, we will add a concise rationale to the abstract and include a new subsection with illustrative examples and counter-examples demonstrating how the aggregates differentiate rules with identical marginal statistics. While a general completeness proof for all Horn rules is beyond the current scope, the added analysis will strengthen the justification. revision: yes
-
Referee: [Abstract] Abstract: despite stating that NRI is evaluated on rule recovery, robustness, and zero-shot transfer, the text contains no quantitative results, error bars, ablation studies, or performance numbers, preventing any assessment of whether the architecture achieves the claimed zero-shot generalization.
Authors: We acknowledge that the abstract itself contains no specific quantitative results, error bars, or ablation numbers, which hinders immediate evaluation of the generalization claims. The full manuscript describes the evaluation protocol and reports results in the experiments section. In the revised version, we will update the abstract to include key quantitative highlights from the rule recovery, robustness, and zero-shot transfer experiments, along with references to error bars and ablations. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core construction uses a statistical encoder that maps literals to domain-agnostic aggregates (class-conditional rates, entropy, co-occurrence) by explicit design choice, followed by a parallel slot decoder and product T-norm relaxation for differentiability. No equations, fitted parameters, or self-citations are shown that make the zero-shot transfer performance equivalent to the training inputs by construction. The representation is motivated as independent of predicate identities, and the evaluation claims (rule recovery, noise robustness, real-world transfer) rest on empirical testing rather than tautological reduction. This is the common case of a self-contained model architecture without load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network hyperparameters
axioms (1)
- domain assumption Product T-norm relaxation preserves sufficient gradient signal for rule induction training
invented entities (1)
-
Neural Rule Inducer (NRI)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith.Cost (Jcost = ½(x+x⁻¹)−1)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Product T-Norm: Negation: ¬x = 1−x; Conjunction: x∧y = x·y; Disjunction: x∨y = 1−(1−x)(1−y).
-
Foundation.LogicAsFunctionalEquation / ArithmeticFromLogicn/a (paper is in cs.AI/ILP domain RS does not address) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
NRI represents literals using domain-agnostic statistical properties such as class-conditional rates, entropy, and co-occurrence ... pretrained on synthetic DNFs and evaluating on held-out real-world tabular tasks.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Uci machine learning repository,
[Asuncionet al., 2007 ] Arthur Asuncion, David Newman, et al. Uci machine learning repository,
2007
-
[2]
On the Opportunities and Risks of Foundation Models
[Bommasani, 2021] Rishi Bommasani. On the opportu- nities and risks of foundation models.arXiv preprint arXiv:2108.07258,
work page internal anchor Pith review arXiv 2021
-
[3]
Xgboost: A scalable tree boost- ing system
[Chen, 2016] Tianqi Chen. Xgboost: A scalable tree boost- ing system
2016
-
[4]
Fast ef- fective rule induction
[Cohen and others, 1995] William W Cohen et al. Fast ef- fective rule induction. InProceedings of the twelfth inter- national conference on machine learning, pages 115–123,
1995
-
[5]
Support-vector networks.Machine learning, 20(3):273–297,
[Cortes and Vapnik, 1995] Corinna Cortes and Vladimir Vapnik. Support-vector networks.Machine learning, 20(3):273–297,
1995
-
[6]
Learning programs by learning from failures
[Cropper and Morel, 2021] Andrew Cropper and Rolf Morel. Learning programs by learning from failures. Machine Learning, 110(4):801–856,
2021
-
[7]
Learning explanatory rules from noisy data
[Evans and Grefenstette, 2018] Richard Evans and Edward Grefenstette. Learning explanatory rules from noisy data. Journal of Artificial Intelligence Research, 61:1–64,
2018
-
[8]
Switch transformers: Scaling to trillion param- eter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39,
[Feduset al., 2022 ] William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion param- eter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39,
2022
-
[9]
Predictive learning via rule ensem- bles
[Friedman and Popescu, 2008] Jerome H Friedman and Bogdan E Popescu. Predictive learning via rule ensem- bles
2008
-
[10]
A differentiable first-order rule learner for inductive logic programming.Artificial Intelligence, 331:104108,
[Gaoet al., 2024 ] Kun Gao, Katsumi Inoue, Yongzhi Cao, and Hanpin Wang. A differentiable first-order rule learner for inductive logic programming.Artificial Intelligence, 331:104108,
2024
-
[11]
Tabpfn: A transformer that solves small tabular classification prob- lems in a second
[Hollmannet al., 2023 ] Noah Hollmann, Samuel M ¨uller, Katharina Eggensperger, and Frank Hutter. Tabpfn: A transformer that solves small tabular classification prob- lems in a second. InInternational Conference on Learning Representations 2023,
2023
-
[12]
Learning from interpretation transition.Ma- chine Learning, 94(1):51–79,
[Inoueet al., 2014 ] Katsumi Inoue, Tony Ribeiro, and Chi- aki Sakama. Learning from interpretation transition.Ma- chine Learning, 94(1):51–79,
2014
-
[13]
[Johnsonet al., 2025 ] Blair Johnson, Clayton Kerce, and Faramarz Fekri. Glidr: Graph-like inductive logic pro- gramming with differentiable reasoning.arXiv preprint arXiv:2508.06716,
-
[14]
Lightgbm: A highly efficient gradient boost- ing decision tree
[Keet al., 2017 ] Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: A highly efficient gradient boost- ing decision tree. volume 30,
2017
-
[15]
[Klementet al., 2013 ] Erich Peter Klement, Radko Mesiar, and Endre Pap.Triangular norms, volume
2013
-
[16]
[Loh, 2011] Wei-Yin Loh.Classification and regression trees, volume
2011
-
[17]
Accurate intelligible models with pairwise interactions
[Louet al., 2013 ] Yin Lou, Rich Caruana, Johannes Gehrke, and Giles Hooker. Accurate intelligible models with pairwise interactions. InProceedings of the 19th ACM SIGKDD international conference on Knowledge discov- ery and data mining, pages 623–631,
2013
-
[18]
Deepproblog: Neural probabilistic logic pro- gramming.Advances in Neural Information Processing Systems, 31,
[Manhaeveet al., 2018 ] Robin Manhaeve, Sebastijan Du- mancic, Angelika Kimmig, Thomas Demeester, and Luc De Raedt. Deepproblog: Neural probabilistic logic pro- gramming.Advances in Neural Information Processing Systems, 31,
2018
-
[19]
Inductive logic programming: Theory and methods.The Journal of Logic Programming, 19:629– 679,
[Muggleton and De Raedt, 1994] Stephen Muggleton and Luc De Raedt. Inductive logic programming: Theory and methods.The Journal of Logic Programming, 19:629– 679,
1994
-
[20]
Inverse entailment and progol.New generation computing, 13(3):245–286,
[Muggleton, 1995] Stephen Muggleton. Inverse entailment and progol.New generation computing, 13(3):245–286,
1995
-
[21]
arXiv preprint arXiv:1909.09223 , year=
[Noriet al., 2019 ] Harsha Nori, Samuel Jenkins, Paul Koch, and Rich Caruana. Interpretml: A unified framework for machine learning interpretability.arXiv preprint arXiv:1909.09223,
-
[22]
Linc: A neurosymbolic ap- proach for logical reasoning by combining language mod- els with first-order logic provers
[Olaussonet al., 2023 ] Theo Olausson, Alex Gu, Ben Lip- kin, Cedegao Zhang, Armando Solar-Lezama, Joshua Tenenbaum, and Roger Levy. Linc: A neurosymbolic ap- proach for logical reasoning by combining language mod- els with first-order logic provers. InProceedings of the 2023 Conference on Empirical Methods in Natural Lan- guage Processing, pages 5153–5176,
2023
-
[23]
[Penget al., 2025 ] Yifei Peng, Yaoli Liu, Enbo Xia, Yu Jin, Wang-Zhou Dai, Zhong Ren, Yao-Xiang Ding, and Kun Zhou. Abductive logical rule induction by bridging in- ductive logic programming and multimodal large language models.arXiv preprint arXiv:2509.21874,
-
[24]
Film: Visual reasoning with a general conditioning layer
[Perezet al., 2018 ] Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. In AAAI Conference on Artificial Intelligence, pages 3942– 3951,
2018
-
[25]
Variable assignment invariant neural networks for learning logic programs
[Phua and Inoue, 2024] Yin Jun Phua and Katsumi Inoue. Variable assignment invariant neural networks for learning logic programs. InInternational Conference on Neural- Symbolic Learning and Reasoning (NeSy). Springer,
2024
-
[26]
Ross Quinlan
[Quinlan, 1990] J. Ross Quinlan. Learning logical defini- tions from relations. volume 5, pages 239–266. Springer,
1990
-
[27]
[Renet al., 2025 ] ZZ Ren, Zhihong Shao, Junxiao Song, Huajian Xin, Haocheng Wang, Wanjia Zhao, Liyue Zhang, Zhe Fu, Qihao Zhu, Dejian Yang, et al. Deepseek-prover- v2: Advancing formal mathematical reasoning via re- inforcement learning for subgoal decomposition.arXiv preprint arXiv:2504.21801,
-
[28]
End-to-end differentiable proving
[Rockt¨aschel and Riedel, 2017] Tim Rockt¨aschel and Sebas- tian Riedel. End-to-end differentiable proving. volume 30,
2017
-
[29]
Drum: End-to-end differentiable rule mining on knowledge graphs.Advances in neural information processing sys- tems, 32,
[Sadeghianet al., 2019 ] Ali Sadeghian, Mohammadreza Ar- mandpour, Patrick Ding, and Daisy Zhe Wang. Drum: End-to-end differentiable rule mining on knowledge graphs.Advances in neural information processing sys- tems, 32,
2019
-
[30]
Logic tensor networks: Deep learning and logical reasoning from data and knowledge
[Serafini and Garcez, 2016] Luciano Serafini and Ar- tur d’Avila Garcez. Logic tensor networks: Deep learning and logical reasoning from data and knowledge
2016
-
[31]
The aleph manual
[Srinivasan, 2001] Ashwin Srinivasan. The aleph manual
2001
-
[32]
Fast in- terpretable greedy-tree sums.Proceedings of the National Academy of Sciences, 122(7):e2310151122,
[Tanet al., 2025 ] Yan Shuo Tan, Chandan Singh, Keyan Nasseri, Abhineet Agarwal, James Duncan, Omer Ronen, Matthew Epland, Aaron Kornblith, and Bin Yu. Fast in- terpretable greedy-tree sums.Proceedings of the National Academy of Sciences, 122(7):e2310151122,
2025
-
[33]
Attention is all you need
[Vaswaniet al., 2017 ] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. volume 30,
2017
-
[34]
FOLD-R++: A scalable toolset for automated inductive learning of default theories from mixed data
[Wang and Gupta, 2022] Huaduo Wang and Gopal Gupta. FOLD-R++: A scalable toolset for automated inductive learning of default theories from mixed data. InFunctional and Logic Programming - 16th International Symposium, FLOPS 2022, Kyoto, Japan, May 10-12, 2022, Proceed- ings, Lecture Notes in Computer Science, pages 224–242. Springer,
2022
-
[35]
Differentiable learning of logical rules for knowl- edge base reasoning.Advances in neural information pro- cessing systems, 30,
[Yanget al., 2017 ] Fan Yang, Zhilin Yang, and William W Cohen. Differentiable learning of logical rules for knowl- edge base reasoning.Advances in neural information pro- cessing systems, 30,
2017
-
[36]
Neurasp: Embracing neural networks into answer set programming
[Yanget al., 2020 ] Zhun Yang, Adam Ishay, and Joohyung Lee. Neurasp: Embracing neural networks into answer set programming. In29th International Joint Conference on Artificial Intelligence (IJCAI 2020), 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.