Recognition: 3 theorem links
· Lean TheoremDART: A Vision-Language Foundation Model for Comprehensive Rope Condition Monitoring
Pith reviewed 2026-05-08 18:36 UTC · model grok-4.3
The pith
DART vision-language model delivers comprehensive rope condition monitoring from a frozen shared representation without task-specific fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
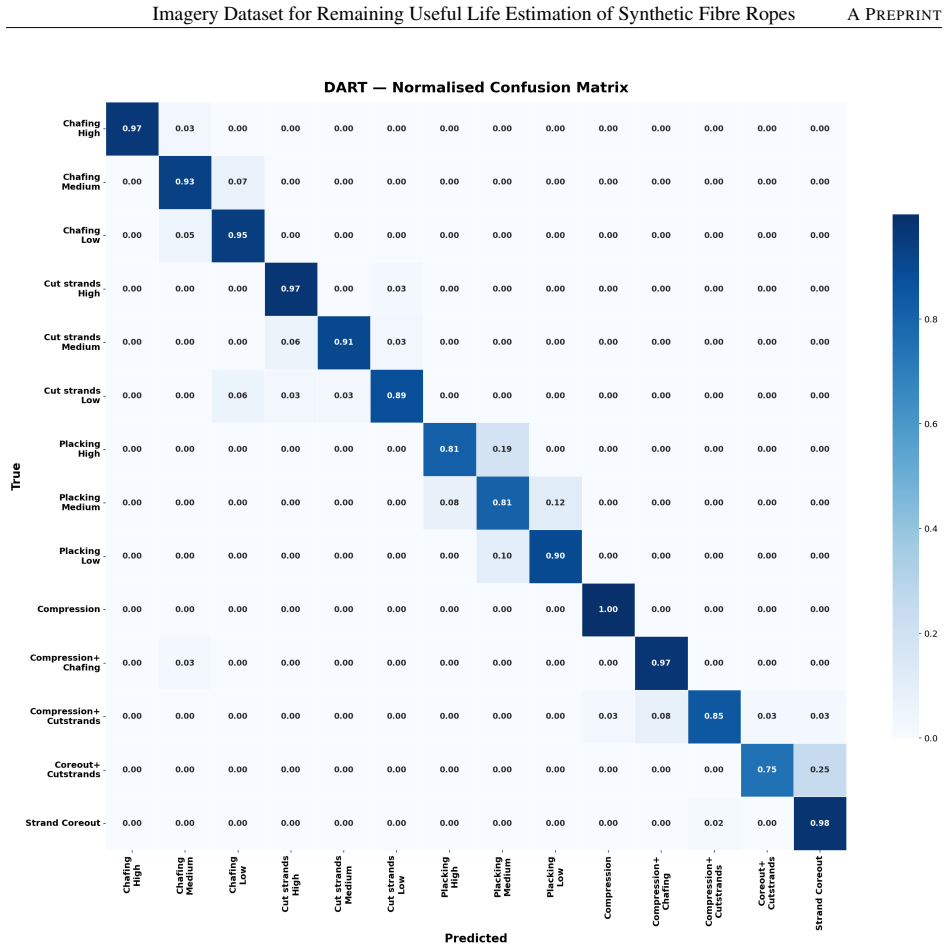
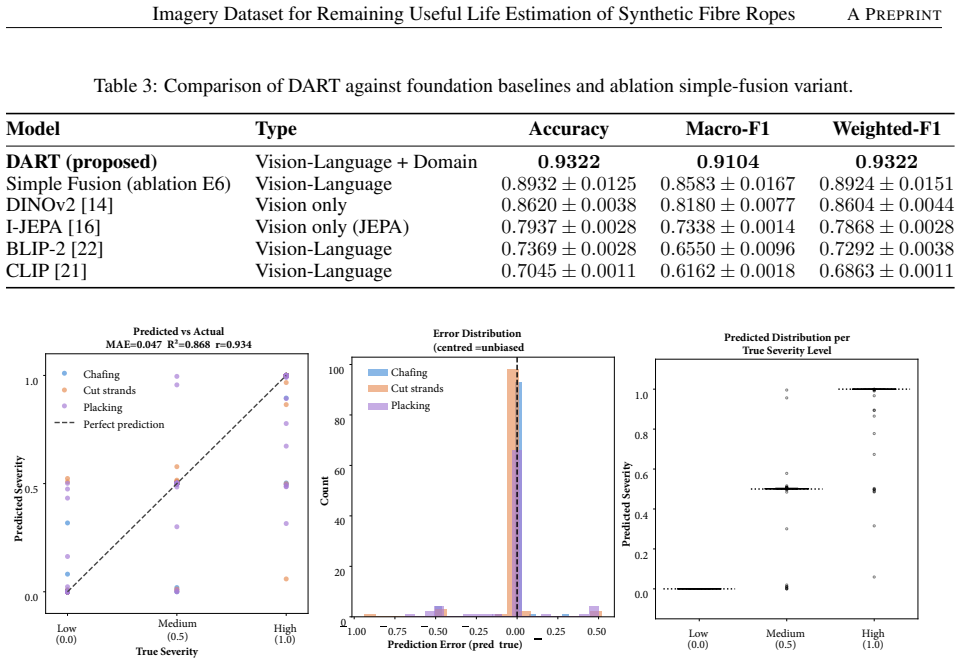
DART extends the Joint-Embedding Predictive Architecture to cross-modal settings by coupling a Vision Transformer with Llama-3.2 via a Severity-Conditioned Cross-Modal Fusion module, incorporating HD-MASK for damage-focused reconstruction, per-class severity gates, and a Contrastive Damage Disentanglement loss. Trained on 4,270 images, the frozen backbone achieves 93.22% accuracy and 91.04% macro-F1 in damage classification, Spearman rho of 0.94 with 99.6% within-1 accuracy in severity regression, and 89.2% macro-F1 in 20-shot few-shot recognition, showing it functions as a general-purpose condition monitoring backbone.
What carries the argument
Severity-Conditioned Cross-Modal Fusion (SC-CMF) module that couples ViT-H/14 vision encoder with Llama-3.2-3B-Instruct, enhanced by HD-MASK saliency-guided masking, learnable severity gates, and Contrastive Damage Disentanglement loss to encode damage type, severity ordering, and cross-modal semantics in a unified space.
Load-bearing premise
The performance metrics achieved on the 4,270-image training distribution will transfer directly to real-world rope images captured under varying lighting, viewing angles, rope types, and environmental conditions without requiring fine-tuning or domain adaptation.
What would settle it
Evaluating the frozen DART model on a new dataset of rope images collected from actual offshore, maritime, or industrial environments with diverse conditions and comparing its performance metrics to the reported ones.
Figures






read the original abstract
The condition monitoring (CM) of synthetic fibre ropes (SFRs) used in offshore, maritime, and industrial settings demands more than a classifier: inspectors need continuous severity estimates, maintenance recommendations, anomaly flags, deterioration timelines, and automated reports, all from a single inspection image. We present DART (Damage Assessment via Rope Transformer), a vision-language foundation model that addresses the full rope inspection workflow through a unified multi-task architecture. DART extends the Joint-Embedding Predictive Architecture (JEPA) to the cross-modal domain by coupling a Vision Transformer (ViT-H/14) with Llama-3.2-3B-Instruct via a Severity-Conditioned Cross-Modal Fusion (SC-CMF) module. Three architectural innovations drive the model's versatility: (1) HD-MASK, a saliency-guided masking strategy that focuses self-supervised reconstruction on damage-dense patches; (2) per-class learnable severity gates that adaptively weight language grounding by damage category; and (3) a Contrastive Damage Disentanglement (CDD) loss that shapes the embedding space to simultaneously encode damage type, severity ordering, and cross-modal semantics. Trained once on 4,270 images spanning 14 fine-grained rope damage classes, the frozen DART backbone supports downstream tasks without any task-specific fine-tuning: damage classification (93.22 % accuracy, 91.04 % macro-F1, +38.5 pp over a vision-only baseline), continuous severity regression (Spearman rho = 0.94, within-1-ordinal accuracy 99.6 %), few-shot recognition (89.2 % macro-F1 at 20 shots). These results demonstrate that DART functions as a general-purpose CM backbone that goes well beyond classification, providing actionable inspection intelligence from a single shared representation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents DART, a vision-language foundation model extending JEPA to cross-modal settings by coupling ViT-H/14 with Llama-3.2-3B-Instruct via a Severity-Conditioned Cross-Modal Fusion (SC-CMF) module. It introduces three innovations—HD-MASK saliency-guided masking, per-class learnable severity gates, and a Contrastive Damage Disentanglement (CDD) loss—and is trained once on 4,270 images spanning 14 fine-grained rope damage classes. The central claim is that the resulting frozen backbone supports multiple downstream tasks without task-specific fine-tuning, achieving 93.22% accuracy and 91.04% macro-F1 on damage classification (+38.5 pp over a vision-only baseline), Spearman rho = 0.94 and 99.6% within-1-ordinal accuracy on continuous severity regression, and 89.2% macro-F1 on 20-shot few-shot recognition.
Significance. If the evaluation protocols and generalizability claims hold, the work offers a potentially significant contribution by demonstrating a single shared representation that simultaneously encodes damage type, ordinal severity, and cross-modal semantics for comprehensive condition monitoring. This could reduce the need for separate models or per-task fine-tuning in industrial inspection workflows, particularly if the approach scales to other visual inspection domains.
major comments (3)
- [Abstract] Abstract: The headline metrics (93.22% accuracy, rho=0.94, 89.2% few-shot F1) and the +38.5 pp baseline improvement are reported without any description of train/test splits, cross-validation procedure, error bars, or how the vision-only baseline was constructed and trained; these omissions directly affect the reliability of the no-fine-tuning claim.
- [Abstract] Abstract: The assertion that the frozen DART backbone supports downstream tasks 'without any task-specific fine-tuning' is load-bearing for the central contribution, yet the abstract supplies no verification that the severity gates, HD-MASK parameters, or CDD loss components remain frozen and task-agnostic during the reported evaluations.
- [Abstract] Abstract: All quantitative results are stated to derive from an internal split of the 4,270-image collection; the absence of any external or out-of-distribution test set (varying lighting, viewpoints, rope constructions, or environmental conditions) leaves the transferability claim for real-world offshore use untested and therefore unsupported.
minor comments (2)
- [Abstract] The abstract would benefit from a concise statement of dataset diversity (e.g., number of rope types, lighting conditions, or capture angles) to contextualize the reported performance.
- [Abstract] Acronyms SC-CMF and CDD are introduced without immediate expansion or reference to their defining equations, which may hinder readability for readers unfamiliar with the architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below, providing clarifications from the full paper and indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline metrics (93.22% accuracy, rho=0.94, 89.2% few-shot F1) and the +38.5 pp baseline improvement are reported without any description of train/test splits, cross-validation procedure, error bars, or how the vision-only baseline was constructed and trained; these omissions directly affect the reliability of the no-fine-tuning claim.
Authors: The abstract is intentionally concise as a high-level summary. The full manuscript details the evaluation protocol in Section 4 (Experimental Setup), including an 80/20 train/test split on the 4,270 images, 5-fold cross-validation, error bars computed as standard deviation over 5 independent runs, and the vision-only baseline (identical ViT-H/14 backbone trained end-to-end with supervised cross-entropy loss on the same splits). To directly address the concern in the abstract itself, we will add a brief clause summarizing the evaluation protocol and baseline construction. revision: yes
-
Referee: [Abstract] Abstract: The assertion that the frozen DART backbone supports downstream tasks 'without any task-specific fine-tuning' is load-bearing for the central contribution, yet the abstract supplies no verification that the severity gates, HD-MASK parameters, or CDD loss components remain frozen and task-agnostic during the reported evaluations.
Authors: Section 3.4 and Section 4.2 of the manuscript explicitly describe the evaluation protocol: the full DART model (including SC-CMF, per-class severity gates, HD-MASK parameters, and CDD loss) is kept completely frozen, with only lightweight linear probes or simple regressors trained on the extracted embeddings for each downstream task. This ensures the representation remains task-agnostic. We will revise the abstract to include a short explicit statement confirming that all DART-specific components remain frozen during these evaluations. revision: yes
-
Referee: [Abstract] Abstract: All quantitative results are stated to derive from an internal split of the 4,270-image collection; the absence of any external or out-of-distribution test set (varying lighting, viewpoints, rope constructions, or environmental conditions) leaves the transferability claim for real-world offshore use untested and therefore unsupported.
Authors: We agree that external OOD testing would provide stronger support for real-world transferability claims. All reported results use an internal 80/20 split with 5-fold cross-validation on our 4,270-image dataset collected under controlled but varied conditions. We will add a new 'Limitations' section to the manuscript that explicitly acknowledges the absence of external validation data and outlines future work to collect and evaluate on diverse offshore datasets with varying lighting, viewpoints, and rope types. The current results still demonstrate the value of the shared representation within the evaluated domain. revision: partial
- The absence of an external out-of-distribution test set, as no such additional real-world data was available for this study.
Circularity Check
No significant circularity; empirical results from standard training and evaluation on internal splits.
full rationale
The paper describes a standard training pipeline for a vision-language model (ViT-H/14 + Llama-3.2-3B with SC-CMF, HD-MASK, severity gates, and CDD loss) on a fixed 4,270-image dataset. Reported metrics (93.22% accuracy, Spearman rho=0.94, 89.2% few-shot F1) are presented as direct empirical outcomes of evaluating the frozen backbone on downstream tasks. No equations, self-definitions, or self-citations are supplied that reduce these numbers to quantities defined by the fitted parameters themselves. Architectural choices are introduced as design decisions rather than derived from the target results. The derivation chain is self-contained as an empirical ML contribution; performance claims rest on data splits rather than tautological redefinitions or load-bearing self-citations.
Axiom & Free-Parameter Ledger
free parameters (2)
- per-class learnable severity gates
- HD-MASK saliency parameters
axioms (2)
- domain assumption The joint-embedding predictive architecture (JEPA) can be extended to cross-modal vision-language settings while preserving its self-supervised benefits.
- domain assumption A single shared representation can simultaneously encode damage type, ordinal severity, and cross-modal semantics without task-specific heads.
Lean theorems connected to this paper
-
Cost.FunctionalEquation (washburn_uniqueness_aczel) — RS forces J(x) = ½(x + x⁻¹) − 1 with no adjustable weights; DART uses four hand-chosen hyperparameters.washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The training objective combines four complementary terms: L = λ₁ L_recon + λ₂ L_sev + λ₃ L_orth + λ₄ L_focal, λ₁₋₄ = {1.0, 0.5, 0.3, 1.0}.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Research directions in synthetic fiber ropes applied as mooring lines for floating offshore wind turbines.Renewable and Sustainable Energy Reviews, 225:116183, 2026
Wei Huang. Research directions in synthetic fiber ropes applied as mooring lines for floating offshore wind turbines.Renewable and Sustainable Energy Reviews, 225:116183, 2026
2026
-
[2]
A survey of vision-based condition monitoring methods using deep learning: A synthetic fiber rope perspective.Engineering Applications of Artificial Intelligence, 136:108921, 2024
Anju Rani, Daniel Ortiz-Arroyo, and Petar Durdevic. A survey of vision-based condition monitoring methods using deep learning: A synthetic fiber rope perspective.Engineering Applications of Artificial Intelligence, 136:108921, 2024. 13 Imagery Dataset for Remaining Useful Life Estimation of Synthetic Fibre RopesA PREPRINT 0.0 0.2 0.8 1.0 0.0 0.2 0.4 0.6 0...
2024
-
[3]
Defect detection in synthetic fibre ropes using detectron2 framework.Applied Ocean Research, 150:104109, 2024
Anju Rani, Daniel Ortiz-Arroyo, and Petar Durdevic. Defect detection in synthetic fibre ropes using detectron2 framework.Applied Ocean Research, 150:104109, 2024
2024
-
[4]
Anju Rani, Daniel O Arroyo, and Petar Durdevic. Imagery dataset for condition monitoring of synthetic fibre ropes.arXiv preprint arXiv:2309.17058, 2023
-
[5]
Yahia Halabi, Hu Xu, Zhixiang Yu, Wael Alhaddad, and Isabelle Dreier. Experimental-based statistical models for the tensile characterization of synthetic fiber ropes: a machine learning approach.Scientific Reports, 13(1):17768, 14 Imagery Dataset for Remaining Useful Life Estimation of Synthetic Fibre RopesA PREPRINT True: Immediate Replace Pred: Schedule...
2023
-
[6]
EdgeRopeNet: Lightweight neural network for real-time wire rope tension monitoring using FBG sensors in edge-fog mining systems.Informatica, 50(5), 2026
Ruihua Tong, Hao Xu, Peijiang Wang, Qingru Zhang, and Chaoyang Hou. EdgeRopeNet: Lightweight neural network for real-time wire rope tension monitoring using FBG sensors in edge-fog mining systems.Informatica, 50(5), 2026
2026
-
[7]
Real-time object detection network in uav-vision based on cnn and transformer.IEEE Transactions on Instrumentation and Measurement, 72:1–13, 2023
Tao Ye, Wenyang Qin, Zongyang Zhao, Xiaozhi Gao, Xiangpeng Deng, and Yu Ouyang. Real-time object detection network in uav-vision based on cnn and transformer.IEEE Transactions on Instrumentation and Measurement, 72:1–13, 2023
2023
-
[8]
Detection and segmentation of manufacturing defects with convolutional neural networks and transfer learning.Smart and sustainable manufacturing systems, 2(1):137–164, 2018
Max Ferguson, Ronay Ak, Yung-Tsun Tina Lee, and Kincho H Law. Detection and segmentation of manufacturing defects with convolutional neural networks and transfer learning.Smart and sustainable manufacturing systems, 2(1):137–164, 2018
2018
-
[9]
Detection of surface damage on steel wire ropes based on improved u-net.Journal of Failure Analysis and Prevention, 25(1):458–467, 2025
Jilin Wei, Juwei Zhang, and Hongli Wang. Detection of surface damage on steel wire ropes based on improved u-net.Journal of Failure Analysis and Prevention, 25(1):458–467, 2025. 15 Imagery Dataset for Remaining Useful Life Estimation of Synthetic Fibre RopesA PREPRINT
2025
-
[10]
Steel wire rope damage width identification method based on residual networks and multi-channel feature fusion.Machines, 12(11):744, 2024
Yan Peng, Junde Liu, Junjie He, Yongjun Qiu, Xie Liu, Le Chen, Fengfeng Yang, Bulong Chen, Bin Tang, and Yuhan Wang. Steel wire rope damage width identification method based on residual networks and multi-channel feature fusion.Machines, 12(11):744, 2024
2024
-
[11]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[12]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page Pith review arXiv 2010
-
[13]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
2022
-
[14]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review arXiv 2023
-
[15]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
2021
-
[16]
Self-supervised learning from images with a joint-embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15619–15629, 2023
2023
-
[17]
Connecting joint-embedding predictive architecture with contrastive self- supervised learning.Advances in neural information processing systems, 37:2348–2377, 2024
Shentong Mo and Shengbang Tong. Connecting joint-embedding predictive architecture with contrastive self- supervised learning.Advances in neural information processing systems, 37:2348–2377, 2024
2024
-
[18]
Vjepa: Variational joint embedding predictive architectures as probabilistic world models
Yongchao Huang. Vjepa: Variational joint embedding predictive architectures as probabilistic world models. arXiv preprint arXiv:2601.14354, 2026
-
[19]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018
work page Pith review arXiv 2018
-
[20]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020
2020
-
[21]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[22]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[23]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[24]
Llama 3 model card.GitHub https://github
AI Meta. Llama 3 model card.GitHub https://github. com/meta- llama/llamamodels/blob/main/models/llama3_1/MODEL_CARD. md. Accessed, 21, 2024
2024
-
[25]
Bridge inspection using a multi-modal vision language model
Zhengxing Chen, Yang Zou, Vicente A González, Jason Ingham, and Liam M Wotherspoon. Bridge inspection using a multi-modal vision language model. InProceedings of The Sixth International Confer, volume 22, pages 578–588, 2025
2025
-
[26]
Construction safety inspection with contrastive language-image pre-training (clip) image captioning and attention
Wei-Lun Tsai, Phuong-Linh Le, Wang-Fat Ho, Nai-Wen Chi, Jacob J Lin, Shuai Tang, and Shang-Hsien Hsieh. Construction safety inspection with contrastive language-image pre-training (clip) image captioning and attention. Automation in Construction, 169:105863, 2025
2025
-
[27]
Hongyang Lei, Xiaolong Cheng, Qi Qin, Dan Wang, Kun Fan, Huazhen Huang, Qingqing Gu, Yetao Wu, Zhonglin Jiang, Yong Chen, et al. M3-jepa: Multimodal alignment via multi-gate moe based on the joint-embedding predictive architecture.arXiv preprint arXiv:2409.05929, 2024
-
[28]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Out- rageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017. 16 Imagery Dataset for Remaining Useful Life Estimation of Synthetic Fibre RopesA PREPRINT
work page internal anchor Pith review arXiv 2017
-
[29]
José Ferreira, Roya Darabi, Armando Sousa, Frank Brueckner, Luís Paulo Reis, Ana Reis, João Manuel RS Tavares, and João Sousa. Gen-jema: enhanced explainability using generative joint embedding multimodal alignment for monitoring directed energy deposition.Journal of Intelligent Manufacturing, pages 1–26, 2025
2025
-
[30]
Cross-modal remote sensing image–text retrieval via context and uncertainty-aware prompt.IEEE Transactions on Neural Networks and Learning Systems, 36(6):11384–11398, 2024
Yijing Wang, Xu Tang, Jingjing Ma, Xiangrong Zhang, Fang Liu, and Licheng Jiao. Cross-modal remote sensing image–text retrieval via context and uncertainty-aware prompt.IEEE Transactions on Neural Networks and Learning Systems, 36(6):11384–11398, 2024
2024
-
[31]
Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection
Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9592–9600, 2019
2019
-
[32]
Padim: a patch distribution modeling framework for anomaly detection and localization
Thomas Defard, Aleksandr Setkov, Angelique Loesch, and Romaric Audigier. Padim: a patch distribution modeling framework for anomaly detection and localization. InInternational conference on pattern recognition, pages 475–489. Springer, 2021
2021
-
[33]
Towards total recall in industrial anomaly detection
Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Schölkopf, Thomas Brox, and Peter Gehler. Towards total recall in industrial anomaly detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14318–14328, 2022
2022
-
[34]
Deep industrial image anomaly detection: A survey.Machine Intelligence Research, 21(1):104–135, 2024
Jiaqi Liu, Guoyang Xie, Jinbao Wang, Shangnian Li, Chengjie Wang, Feng Zheng, and Yaochu Jin. Deep industrial image anomaly detection: A survey.Machine Intelligence Research, 21(1):104–135, 2024
2024
-
[35]
A simple unified framework for detecting out-of- distribution samples and adversarial attacks.Advances in neural information processing systems, 31, 2018
Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framework for detecting out-of- distribution samples and adversarial attacks.Advances in neural information processing systems, 31, 2018
2018
-
[36]
The many faces of robustness: A critical analysis of out-of-distribution generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, et al. The many faces of robustness: A critical analysis of out-of-distribution generalization. InProceedings of the IEEE/CVF international conference on computer vision, pages 8340–8349, 2021
2021
-
[37]
Attention guided anomaly localization in images
Shashanka Venkataramanan, Kuan-Chuan Peng, Rajat Vikram Singh, and Abhijit Mahalanobis. Attention guided anomaly localization in images. InEuropean conference on computer vision, pages 485–503. Springer, 2020
2020
-
[38]
Generalizing from a few examples: A survey on few-shot learning.ACM computing surveys (csur), 53(3):1–34, 2020
Yaqing Wang, Quanming Yao, James T Kwok, and Lionel M Ni. Generalizing from a few examples: A survey on few-shot learning.ACM computing surveys (csur), 53(3):1–34, 2020
2020
-
[39]
Prototypical networks for few-shot learning.Advances in neural information processing systems, 30, 2017
Jake Snell, Kevin Swersky, and Richard Zemel. Prototypical networks for few-shot learning.Advances in neural information processing systems, 30, 2017
2017
-
[40]
Model-agnostic meta-learning for fast adaptation of deep networks
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. InInternational conference on machine learning, pages 1126–1135. PMLR, 2017
2017
-
[41]
Coft-ad: Contrastive fine-tuning for few-shot anomaly detection.IEEE Transactions on Image Processing, 33:2090–2103, 2024
Jingyi Liao, Xun Xu, Manh Cuong Nguyen, Adam Goodge, and Chuan Sheng Foo. Coft-ad: Contrastive fine-tuning for few-shot anomaly detection.IEEE Transactions on Image Processing, 33:2090–2103, 2024
2090
-
[42]
Cross position aggregation network for few-shot strip steel surface defect segmentation.IEEE Transactions on Instrumentation and Measurement, 72:1–10, 2023
Hu Feng, Kechen Song, Wenqi Cui, Yiming Zhang, and Yunhui Yan. Cross position aggregation network for few-shot strip steel surface defect segmentation.IEEE Transactions on Instrumentation and Measurement, 72:1–10, 2023
2023
-
[43]
Attention-based deep meta-transfer learning for few-shot fine-grained fault diagnosis.Knowledge-Based Systems, 264:110345, 2023
Chuanjiang Li, Shaobo Li, Huan Wang, Fengshou Gu, and Andrew D Ball. Attention-based deep meta-transfer learning for few-shot fine-grained fault diagnosis.Knowledge-Based Systems, 264:110345, 2023
2023
-
[44]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017
2017
-
[45]
Randaugment: Practical automated data augmentation with a reduced search space
Ekin D Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V Le. Randaugment: Practical automated data augmentation with a reduced search space. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 702–703, 2020
2020
-
[46]
An introduction to structural health monitoring.Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 365(1851):303–315, 2007
Charles R Farrar and Keith Worden. An introduction to structural health monitoring.Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 365(1851):303–315, 2007
2007
-
[47]
Multimodal deep neural network-based sensor data anomaly diagnosis method for structural health monitoring.Buildings, 13(8):1976, 2023
Xingzhong Nong, Xu Luo, Shan Lin, Yanmei Ruan, and Xijun Ye. Multimodal deep neural network-based sensor data anomaly diagnosis method for structural health monitoring.Buildings, 13(8):1976, 2023
1976
-
[48]
Data-driven structural health monitoring using feature fusion and hybrid deep learning.IEEE Transactions on Automation Science and Engineering, 18(4):2087–2103, 2020
Hung V Dang, Hoa Tran-Ngoc, Tung V Nguyen, Thanh Bui-Tien, Guido De Roeck, and Huan X Nguyen. Data-driven structural health monitoring using feature fusion and hybrid deep learning.IEEE Transactions on Automation Science and Engineering, 18(4):2087–2103, 2020
2087
-
[49]
Multimodal sensing for sustainable structural health monitoring of critical infrastructures and built environment
Francesco Soldovieri, Felice C Ponzo, Rocco Ditommaso, and Vincenzo Cuomo. Multimodal sensing for sustainable structural health monitoring of critical infrastructures and built environment. InMultimodal Sensing and Artificial Intelligence: Technologies and Applications II, volume 11785, pages 31–39. SPIE, 2021. 17 Imagery Dataset for Remaining Useful Life...
2021
-
[50]
Multimodal deep learning with integrated automatic labeling for structural damage detection in high-pile wharves.Ocean Engineering, 340:122457, 2025
Xubing Xu, Xin Lan, Yonglai Zheng, Chenyu Hou, and Zhengxie Zhang. Multimodal deep learning with integrated automatic labeling for structural damage detection in high-pile wharves.Ocean Engineering, 340:122457, 2025. 18
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.