Recognition: unknown
TabEmbed: Benchmarking and Learning Generalist Embeddings for Tabular Understanding
Pith reviewed 2026-05-08 16:13 UTC · model grok-4.3
The pith
TabEmbed learns a single embedding space for tabular data by turning classification and retrieval into semantic matching tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
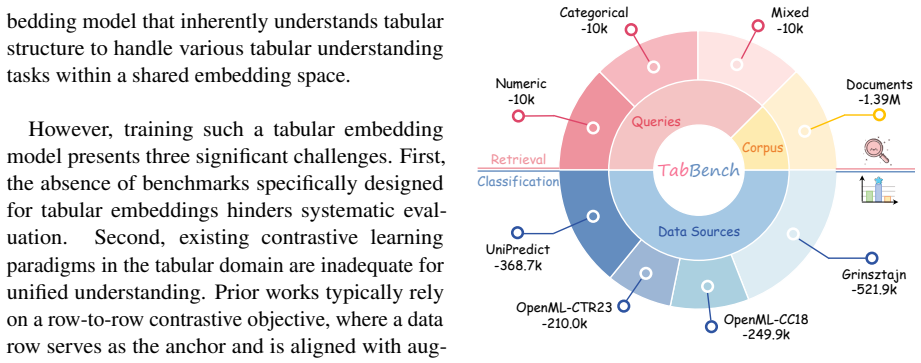
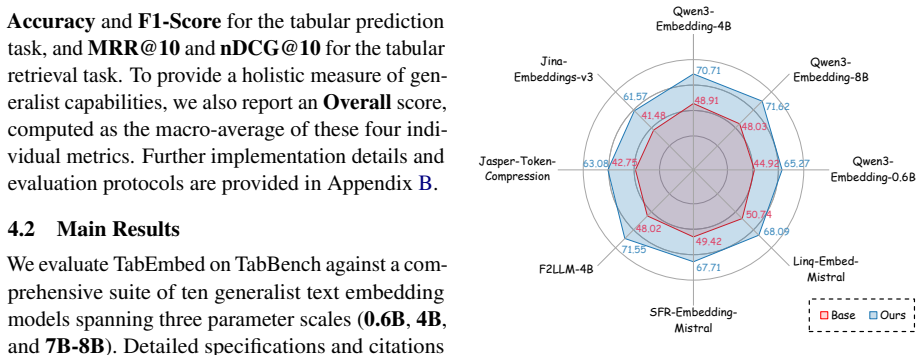
TabEmbed is the first generalist embedding model that unifies tabular classification and retrieval within a shared embedding space. By reformulating diverse tabular tasks as semantic matching problems, it applies large-scale contrastive learning with positive-aware hard negative mining to discern fine-grained structural and numerical nuances, outperforming state-of-the-art text embedding models on the TabBench suite and establishing a new baseline for universal tabular representation learning.
What carries the argument
Reformulating tabular tasks as semantic matching problems, paired with positive-aware hard negative mining inside contrastive learning, to produce a shared embedding space that captures table structure and numbers.
If this is right
- A single trained embedding can support both classification and retrieval without task-specific retraining.
- Contrastive training on tables can encode numerical values and row-column relationships directly in vectors.
- Universal tabular representations become feasible without relying on text-only models.
- New evaluation suites like TabBench can standardize progress in tabular embedding work.
Where Pith is reading between the lines
- The same reformulation trick might extend to other structured data such as graphs or time series.
- Combining the resulting embeddings with language models could improve hybrid table-and-text applications.
- Wider adoption would reduce the need for separate tabular models in data integration or search systems.
Load-bearing premise
Turning many different tabular tasks into semantic matching problems and using positive-aware hard negative mining in contrastive learning is enough to pick up the detailed structure and number meanings that text embedding models miss.
What would settle it
An evaluation on TabBench or a similar suite where TabEmbed shows no clear performance gain over text embedding models on tasks that require precise numerical ordering or nested table relations.
Figures









read the original abstract
Foundation models have established unified representations for natural language processing, yet this paradigm remains largely unexplored for tabular data. Existing methods face fundamental limitations: LLM-based approaches lack retrieval-compatible vector outputs, whereas text embedding models often fail to capture tabular structure and numerical semantics. To bridge this gap, we first introduce the Tabular Embedding Benchmark (TabBench), a comprehensive suite designed to evaluate the tabular understanding capability of embedding models. We then propose TabEmbed, the first generalist embedding model that unifies tabular classification and retrieval within a shared embedding space. By reformulating diverse tabular tasks as semantic matching problems, TabEmbed leverages large-scale contrastive learning with positive-aware hard negative mining to discern fine-grained structural and numerical nuances. Experimental results on TabBench demonstrate that TabEmbed significantly outperforms state-of-the-art text embedding models, establishing a new baseline for universal tabular representation learning. Code and datasets are publicly available at https://github.com/qiangminjie27/TabEmbed and https://huggingface.co/datasets/qiangminjie27/TabBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Tabular Embedding Benchmark (TabBench), a comprehensive suite for evaluating embedding models on tabular understanding tasks, and proposes TabEmbed, the first generalist embedding model for tabular data. TabEmbed reformulates diverse tabular classification and retrieval tasks as semantic matching problems and trains via large-scale contrastive learning with positive-aware hard negative mining to capture structural and numerical nuances. It claims that TabEmbed significantly outperforms state-of-the-art text embedding models on TabBench, establishing a new baseline for universal tabular representation learning, with code and datasets released publicly.
Significance. If the reported gains hold under the supplied controls and ablations, the work is significant for bridging the gap between foundation models and tabular data, where existing LLM and text-embedding approaches fall short on structure and numerics. The explicit public release of code (https://github.com/qiangminjie27/TabEmbed) and datasets (https://huggingface.co/datasets/qiangminjie27/TabBench) is a clear strength that enables reproducibility and further research in the area.
minor comments (2)
- [Abstract] Abstract: the claim of significant outperformance is stated without any quantitative metrics, baseline names, or dataset sizes, which weakens the immediate readability of the central result even though the full experimental section supplies these details.
- [Benchmark section] §4 (Benchmark Construction) or equivalent: while the paper describes TabBench, a brief table summarizing the number of tasks, total rows, and column-type distributions across the suite would help readers quickly assess its diversity and scale.
Simulated Author's Rebuttal
We thank the referee for the positive summary, acknowledgment of the work's significance in bridging foundation models with tabular data, and recommendation for minor revision. We appreciate the recognition of our public code and dataset releases as a strength for reproducibility.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces TabBench as an external benchmark and trains TabEmbed via standard contrastive learning on reformulated tabular tasks using positive-aware hard negative mining. Performance claims rest on empirical results, architecture details, training procedures, and ablations that are independently verifiable via released code and datasets. No step reduces a prediction to a fitted parameter defined by the claim itself, nor relies on self-citation chains or imported uniqueness theorems for the central result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tabular tasks can be reformulated as semantic matching problems without loss of critical structure or numerical semantics
Reference graph
Works this paper leans on
-
[1]
Sercan \"O Arik and Tomas Pfister. 2021. Tabnet: Attentive interpretable tabular learning. In Proceedings of the AAAI conference on artificial intelligence, volume 35, pages 6679--6687
2021
- [2]
- [3]
- [4]
-
[5]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171--4186
2019
- [6]
-
[7]
Sebastian Felix Fischer, Matthias Feurer, and Bernd Bischl. 2023. Openml-ctr23--a curated tabular regression benchmarking suite. In AutoML Conference 2023 (Workshop)
2023
- [8]
-
[9]
Josh Gardner, Juan C Perdomo, and Ludwig Schmidt. 2024. Large scale transfer learning for tabular data via language modeling. Advances in Neural Information Processing Systems, 37:45155--45205
2024
-
[10]
Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. 2021. Revisiting deep learning models for tabular data. Advances in neural information processing systems, 34:18932--18943
2021
-
[11]
L \'e o Grinsztajn, Edouard Oyallon, and Ga \"e l Varoquaux. 2022. Why do tree-based models still outperform deep learning on typical tabular data? Advances in neural information processing systems, 35:507--520
2022
-
[12]
Sylvain Gugger, Lysandre Debut, Thomas Wolf, Philipp Schmid, Zachary Mueller, Sourab Mangrulkar, Marc Sun, and Benjamin Bossan. 2022. Accelerate: Training and inference at scale made simple, efficient and adaptable. https://github.com/huggingface/accelerate
2022
-
[13]
Stefan Hegselmann, Alejandro Buendia, Hunter Lang, Monica Agrawal, Xiaoyi Jiang, and David Sontag. 2023. Tabllm: Few-shot classification of tabular data with large language models. In International conference on artificial intelligence and statistics, pages 5549--5581. PMLR
2023
-
[14]
Jonathan Herzig, Pawel Krzysztof Nowak, Thomas M \"u ller, Francesco Piccinno, and Julian Eisenschlos. 2020. Tapas: Weakly supervised table parsing via pre-training. In Proceedings of the 58th annual meeting of the association for computational linguistics, pages 4320--4333
2020
-
[15]
Junseong Kim, Seolhwa Lee, Jihoon Kwon, Sangmo Gu, Yejin Kim, Minkyung Cho, Jy yong Sohn, and Chanyeol Choi. 2024. https://getlinq.com/blog/linq-embed-mistral/ Linq-embed-mistral:elevating text retrieval with improved gpt data through task-specific control and quality refinement . Linq AI Research Blog
2024
-
[16]
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. 2024. Nv-embed: Improved techniques for training llms as generalist embedding models. arXiv preprint arXiv:2405.17428
work page internal anchor Pith review arXiv 2024
- [17]
-
[18]
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. 2023. Towards general text embeddings with multi-stage contrastive learning. arXiv preprint arXiv:2308.03281
work page internal anchor Pith review arXiv 2023
-
[19]
Duncan McElfresh, Sujay Khandagale, Jonathan Valverde, Vishak Prasad C, Ganesh Ramakrishnan, Micah Goldblum, and Colin White. 2023. When do neural nets outperform boosted trees on tabular data? Advances in Neural Information Processing Systems, 36:76336--76369
2023
-
[20]
Rui Meng, Ye Liu, Shafiq Rayhan Joty, Caiming Xiong, Yingbo Zhou, and Semih Yavuz. 2024. https://www.salesforce.com/blog/sfr-embedding/ Sfr-embedding-mistral:enhance text retrieval with transfer learning . Salesforce AI Research Blog
2024
-
[21]
Andreas C Mueller, Carlo A Curino, and Raghu Ramakrishnan. 2025. https://openreview.net/forum?id=6H4jRWKFc3 Mothernet: Fast training and inference via hyper-network transformers . In The Thirteenth International Conference on Learning Representations
2025
- [22]
-
[23]
Niklas Muennighoff, Nouamane Tazi, Lo \" c Magne, and Nils Reimers. 2023. Mteb: Massive text embedding benchmark. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2014--2037
2023
-
[24]
Panupong Pasupat and Percy Liang. 2015. Compositional semantic parsing on semi-structured tables. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1470--1480
2015
-
[25]
Minjie Qiang, Zhongqing Wang, Shoushan Li, and Guodong Zhou. 2025. Exploring unified training framework for multimodal user profiling. In Proceedings of the 31st International Conference on Computational Linguistics, pages 1699--1710
2025
-
[26]
u ller, Ga \
Jingang Qu, David Holzm \"u ller, Ga \"e l Varoquaux, and Marine Le Morvan. 2025. Tabicl: A tabular foundation model for in-context learning on large data. In ICML 2025-Forty-Second International Conference on Machine Learning
2025
-
[27]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1--67
2020
-
[28]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084
work page internal anchor Pith review arXiv 2019
- [29]
-
[30]
Octen Team. 2025. https://octen-team.github.io/octen_blog/posts/octen-rteb-first-place/ Octen series: Optimizing embedding models to \#1 on rteb leaderboard
2025
-
[31]
Nandan Thakur, Nils Reimers, Andreas R \"u ckl \'e , Abhishek Srivastava, and Iryna Gurevych. 2021. Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models. arXiv preprint arXiv:2104.08663
work page internal anchor Pith review arXiv 2021
-
[32]
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. 2022. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533
work page internal anchor Pith review arXiv 2022
-
[33]
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024. Improving text embeddings with large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11897--11916
2024
-
[34]
Ruiyu Wang, Zifeng Wang, and Jimeng Sun. 2023. Unipredict: Large language models are universal tabular predictors
2023
-
[35]
Zifeng Wang and Jimeng Sun. 2022. Transtab: Learning transferable tabular transformers across tables. Advances in Neural Information Processing Systems, 35:2902--2915
2022
-
[36]
Xumeng Wen, Han Zhang, Shun Zheng, Wei Xu, and Jiang Bian. 2024. From supervised to generative: A novel paradigm for tabular deep learning with large language models. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 3323--3333
2024
-
[37]
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. 2024. C-pack: Packed resources for general chinese embeddings. In Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval, pages 641--649
2024
-
[38]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
work page internal anchor Pith review arXiv 2025
-
[39]
Han-Jia Ye, Si-Yang Liu, and Wei-Lun Chao. 2025. A closer look at tabpfn v2: Understanding its strengths and extending its capabilities. In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[40]
Pengcheng Yin, Graham Neubig, Wen-tau Yih, and Sebastian Riedel. 2020. Tabert: Pretraining for joint understanding of textual and tabular data. In Proceedings of the 58th annual meeting of the association for computational linguistics, pages 8413--8426
2020
- [41]
-
[42]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, and 1 others. 2018. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task. In Proceedings of the 2018 conference on empirical methods in natural language processing, pages 3911--3921
2018
- [43]
- [44]
-
[45]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025 b . Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv preprint arXiv:2506.05176
work page internal anchor Pith review arXiv 2025
- [46]
- [47]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.