Recognition: unknown
Empirical Study of Pop and Jazz Mix Ratios for Genre-Adaptive Chord Generation
Pith reviewed 2026-05-08 16:08 UTC · model grok-4.3
The pith
Pop chord accuracy recovers to baseline after jazz fine-tuning once 2.5K pop rehearsal samples are mixed in.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
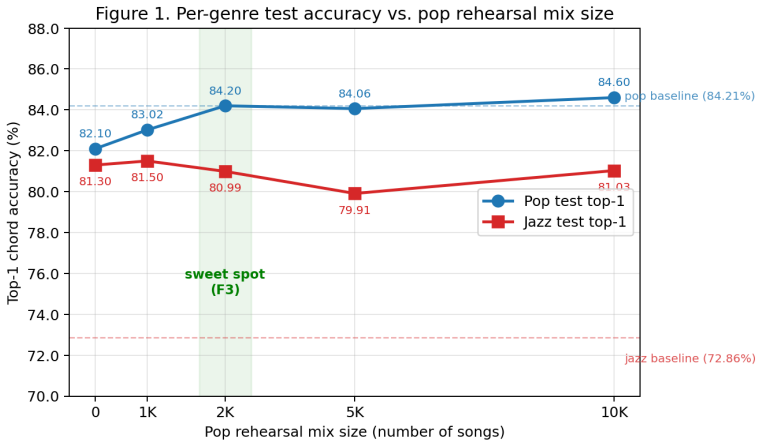
Fine-tuning the pop-pretrained 25M-parameter Music Transformer on all 1,513 jazz sequences improves jazz top-1 chord accuracy by 7 to 9 points across every rehearsal level. Pop accuracy drops by 2.14 points under pure jazz fine-tuning, recovers to the original 84.24 percent baseline at approximately 2.5K pop rehearsal samples, and saturates beyond that point. The 2.5K-mix checkpoint records the highest combined metric score, yet the 1K and 10K endpoints are more frequently chosen in informal listening for their stronger genre identities.
What carries the argument
Rehearsal-data mixing, in which fixed-volume jazz sequences are combined with variable volumes of pop sequences (0, 1K, 2.5K, 5K, or 10K) during continued training of the chord-only Music Transformer.
If this is right
- Jazz top-1 accuracy rises by 7 to 9 points in every fine-tuning condition that includes the full jazz corpus.
- Pop accuracy collapses by 2.14 points only when no rehearsal data is retained and recovers once rehearsal volume reaches 1.65 times the jazz data size.
- Further increases beyond 2.5K pop samples produce no additional pop or jazz gains.
- The single checkpoint with the best combined metric score is not always the one preferred in informal listening.
- The six resulting model checkpoints are released publicly for further use.
Where Pith is reading between the lines
- The 1.65x rehearsal ratio may serve as a starting point for adapting chord models to other genres whose training sets differ in size.
- Music co-creation tools could expose the rehearsal ratio as a user-controllable parameter to produce outputs with stronger or weaker stylistic commitment.
- The observed mismatch between metric ranking and listener preference indicates that top-1 accuracy alone may miss aspects of musical coherence or stylistic clarity.
- Repeating the sweep on larger models or additional genre pairs would test whether the observed saturation point generalizes.
Load-bearing premise
Top-1 chord accuracy on the chosen held-out test sets is a reliable proxy for useful musical output and the pop and jazz corpora adequately represent their genres.
What would settle it
A new held-out test set or corpus in which pop top-1 accuracy does not return to the original baseline even after 2.5K or more pop rehearsal samples are added.
Figures


read the original abstract
Chord progression generation is practically important but understudied. Most large-scale symbolic music systems target melody, multi-track arrangement, or audio synthesis, and chord-only models tend to be relegated to conditioning components inside larger pipelines. This paper treats chord generation as a standalone task and addresses a question that arises whenever such a model is adapted across genres: how much old-domain data must be retained during fine-tuning to acquire a new domain without forgetting the old? I study jazz fine-tuning starting from a pop-pretrained 25M-parameter Music Transformer (84.24% top-1 chord accuracy on a held-out pop test set). The available jazz corpus is an order of magnitude smaller than the pop corpus, so every fine-tune run uses all 1,513 jazz training sequences. The swept variable is the volume of pop "rehearsal" data mixed alongside, taking values in {0, 1K, 2.5K, 5K, 10K}. Every fine-tuned model gains 7 to 9 points of jazz top-1. Pop accuracy collapses by 2.14 points under jazz-only fine-tuning, recovers to baseline at approximately 2.5K rehearsal samples (1.65x the jazz volume), and saturates beyond that point. A complementary observation: the metric-best run (F3, 2.5K mix) is not always the perceptually preferred one. The pop-leaning (10K) and jazz-leaning (1K) endpoints carry more committed stylistic identities that the author more often selects as finished output in informal listening. I discuss what this suggests for music co-creation tools but make no perceptual claim, since no formal listening study has been conducted. All six checkpoints are released on the HuggingFace Hub at https://huggingface.co/PearlLeeStudio.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical study of rehearsal data volumes for genre-adaptive chord generation. Starting from a 25M-parameter Music Transformer pretrained on pop (84.24% top-1 accuracy on held-out pop), the authors fine-tune on the full jazz training set of 1,513 sequences while mixing in varying amounts of pop rehearsal data (0, 1K, 2.5K, 5K, 10K samples). They report that jazz accuracy improves 7–9 points in all conditions, pop accuracy drops 2.14 points with zero rehearsal but recovers to baseline at ~2.5K pop samples (1.65× jazz volume) and saturates thereafter. The work notes that the metric-best checkpoint is not always perceptually preferred and releases all six models on the Hugging Face Hub.
Significance. If the reported rehearsal threshold is robust, the study supplies concrete, actionable guidance for practitioners fine-tuning symbolic music models across genres with severe data imbalance, quantifying the volume needed to avoid catastrophic forgetting of the source domain. The public release of checkpoints is a clear strength that supports reproducibility and follow-on work. The observation that metric optimality and perceptual quality diverge is also useful for co-creation tool design, though the lack of formal listening data prevents strong claims in that direction.
major comments (2)
- [Abstract] Abstract and results: the central claim that pop top-1 accuracy recovers specifically at approximately 2.5K rehearsal samples rests on point estimates alone. No error bars, multiple random seeds, test-set sizes, or statistical significance tests are supplied, so it is impossible to determine whether the 2.14-point drop and its recovery exceed training stochasticity or sampling variability on the held-out sets.
- [Methods] Methods: training hyperparameters (learning rate, optimizer, batch size, number of epochs, early-stopping criteria) are not reported. These details are load-bearing for interpreting whether the observed accuracy trajectories are driven by the mix ratios or by other training choices.
minor comments (3)
- Dataset description: only order-of-magnitude sizes are given; exact cardinalities of the pop and jazz training and test splits, as well as how the held-out sets were constructed, should be stated so readers can gauge the precision of the reported percentages.
- Evaluation: top-1 chord accuracy is the sole quantitative metric. Adding perplexity, n-gram overlap, or other sequence-level measures would strengthen the analysis of genre adaptation.
- The informal listening observations are presented without a formal study; the text already notes this limitation, but a brief explicit statement that no perceptual experiment was run would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of rigor and reproducibility in our empirical study. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and results: the central claim that pop top-1 accuracy recovers specifically at approximately 2.5K rehearsal samples rests on point estimates alone. No error bars, multiple random seeds, test-set sizes, or statistical significance tests are supplied, so it is impossible to determine whether the 2.14-point drop and its recovery exceed training stochasticity or sampling variability on the held-out sets.
Authors: We agree that the results would be more robust with measures of variability. The current manuscript reports single-run point estimates without error bars, multiple seeds, or statistical tests. We will revise the abstract, results, and any associated figures to include the sizes of the held-out test sets and, where computationally feasible, results from additional random seeds to report means and standard deviations. This will help readers assess whether the observed drop and recovery at ~2.5K samples exceed typical training variability. We note that the consistent trend across all five mix ratios (0K through 10K) already provides supporting evidence for the reported threshold. revision: yes
-
Referee: [Methods] Methods: training hyperparameters (learning rate, optimizer, batch size, number of epochs, early-stopping criteria) are not reported. These details are load-bearing for interpreting whether the observed accuracy trajectories are driven by the mix ratios or by other training choices.
Authors: We acknowledge the omission and agree that these details are necessary for full interpretation and reproducibility. We will add a complete specification of all training hyperparameters to the Methods section in the revised manuscript, including the optimizer, learning rate, batch size, maximum number of epochs, and early-stopping criteria. revision: yes
Circularity Check
No circularity: all results are direct empirical measurements
full rationale
The paper performs an empirical study by fine-tuning a fixed 25M-parameter Music Transformer on controlled mixtures of pop and jazz sequences and directly measuring top-1 chord accuracy on held-out test sets. The central observations (7-9 point jazz gains, 2.14-point pop drop at zero rehearsal, recovery at ~2.5K pop samples) are reported as observed outcomes of the training runs rather than quantities derived from any internal equations, fitted parameters, or predictions. No self-definitional relations, fitted-input-as-prediction steps, load-bearing self-citations, uniqueness theorems, or ansatzes appear in the derivation chain. The work is self-contained as a set of controlled experiments whose claims rest on external test-set evaluations, not on quantities defined by the study itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- Rehearsal mix volumes
axioms (1)
- domain assumption Held-out pop and jazz test sets accurately reflect genre-specific chord usage and top-1 accuracy is a meaningful quality signal.
Reference graph
Works this paper leans on
-
[1]
Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, Matt Sharifi, Neil Zeghidour, and Christian Frank
Andrea Agostinelli, Timo I. Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, Matt Sharifi, Neil Zeghidour, and Christian Frank. MusicLM: Generating music from text, 2023
2023
-
[2]
Curriculum learning
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. InInternational Conference on Machine Learning (ICML), 2009
2009
-
[3]
Springer, 2020
Jean-Pierre Briot, Gaëtan Hadjeres, and François-David Pachet.Deep Learning Techniques for Music Generation. Springer, 2020
2020
-
[4]
An expert ground truth set for audio chord recognition and music analysis
John Ashley Burgoyne, Jonathan Wild, and Ichiro Fujinaga. An expert ground truth set for audio chord recognition and music analysis. InInternational Society for Music Information Retrieval Conference, 2011
2011
-
[5]
Efficient lifelong learning with A-GEM
Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient lifelong learning with A-GEM. InICLR, 2019
2019
-
[6]
Transfer learning for music classification and regression tasks
Keunwoo Choi, György Fazekas, Mark Sandler, and Kyunghyun Cho. Transfer learning for music classification and regression tasks. InInternational Society for Music Information Retrieval Conference, 2017. 14
2017
-
[7]
Simple and controllable music generation
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Défossez. Simple and controllable music generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[8]
David Dalmazzo, Kévin Déguernel, and Bob L. T. Sturm. The Chordinator: Modeling music harmony by implementing transformer networks and token strategies. InArtificial Intelligence in Music, Sound, Art and Design (EvoMUSART 2024), volume 14633 ofLecture Notes in Computer Science, pages 52–67. Springer, 2024
2024
-
[9]
A corpus analysis of rock harmony.Popular Music, 30(1):47–70, 2011
Trevor de Clercq and David Temperley. A corpus analysis of rock harmony.Popular Music, 30(1):47–70, 2011
2011
-
[10]
A continual learning survey: Defying forgetting in classification tasks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(7):3366–3385, 2021
Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Aleš Leonardis, Greg Slabaugh, and Tinne Tuytelaars. A continual learning survey: Defying forgetting in classification tasks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(7):3366–3385, 2021
2021
-
[11]
MuseGAN: Multi-track sequential generative adversarial networks for symbolic music generation and accompaniment
Hao-Wen Dong, Wen-Yi Hsiao, Li-Chia Yang, and Yi-Hsuan Yang. MuseGAN: Multi-track sequential generative adversarial networks for symbolic music generation and accompaniment. InAAAI Conference on Artificial Intelligence, 2018
2018
-
[12]
MMM: Exploring conditional multi-track music generation with the transformer, 2020
Jeff Ens and Philippe Pasquier. MMM: Exploring conditional multi-track music generation with the transformer, 2020
2020
-
[13]
Audio-aligned jazz har- mony dataset for automatic chord transcription and corpus-based research
Vsevolod Eremenko, Emir Demirel, Baris Bozkurt, and Xavier Serra. Audio-aligned jazz har- mony dataset for automatic chord transcription and corpus-based research. InInternational Society for Music Information Retrieval Conference, 2018
2018
-
[14]
Robert M. French. Catastrophic forgetting in connectionist networks.Trends in Cognitive Sciences, 3(4):128–135, 1999
1999
-
[15]
The Pile: An 800gb dataset of diverse text for language modeling, 2020
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The Pile: An 800gb dataset of diverse text for language modeling, 2020
2020
-
[16]
Goodfellow, Mehdi Mirza, Da Xiao, Aaron Courville, and Yoshua Bengio
Ian J. Goodfellow, Mehdi Mirza, Da Xiao, Aaron Courville, and Yoshua Bengio. An empirical investigation of catastrophic forgetting in gradient-based neural networks, 2013
2013
-
[17]
A robust parser-interpreter for jazz chord sequences.Journal of New Music Research, 43(4), 2014
Mark Granroth-Wilding and Mark Steedman. A robust parser-interpreter for jazz chord sequences.Journal of New Music Research, 43(4), 2014
2014
-
[18]
DeepBach: A steerable model for Bach chorales generation
Gaëtan Hadjeres, François Pachet, and Frank Nielsen. DeepBach: A steerable model for Bach chorales generation. InInternational Conference on Machine Learning (ICML), 2017
2017
-
[19]
The jazz harmony treebank
Daniel Harasim, Christoph Finkensiep, Petter Ericson, Timothy J O’Donnell, and Martin Rohrmeier. The jazz harmony treebank. InInternational Society for Music Information Retrieval Conference, 2020
2020
-
[20]
Compound word trans- former: Learning to compose full-song music over dynamic directed hypergraphs
Wen-Yi Hsiao, Jen-Yu Liu, Yin-Cheng Yeh, and Yi-Hsuan Yang. Compound word trans- former: Learning to compose full-song music over dynamic directed hypergraphs. InAAAI Conference on Artificial Intelligence, 2021
2021
-
[21]
Cheng-Zhi Anna Huang, David Duvenaud, and Krzysztof Z. Gajos. ChordRipple: Recom- mending chords to help novice composers go beyond the ordinary. InACM Conference on Intelligent User Interfaces (IUI), 2016. 15
2016
-
[22]
Music transformer: Generating music with long-term structure
Cheng-Zhi Anna Huang, Ashish Vaswani, Jakob Uszkoreit, Noam Shazeer, Ian Simon, Curtis Hawthorne, Andrew M Dai, Matthew D Hoffman, Monica Dinculescu, and Douglas Eck. Music transformer: Generating music with long-term structure. InInternational Conference on Learning Representations, 2019
2019
-
[23]
Improving automatic jazz melody generation by transfer learning techniques
Hsiao-Tzu Hung, Chung-Yang Wang, Yi-Hsuan Yang, and Hsin-Min Wang. Improving automatic jazz melody generation by transfer learning techniques. InAPSIPA Annual Summit and Conference, 2019
2019
-
[24]
A comprehensive survey on deep music generation: Multi-level representations, algorithms, evaluations, and future directions, 2020
Shulei Ji, Jing Luo, and Xinyu Yang. A comprehensive survey on deep music generation: Multi-level representations, algorithms, evaluations, and future directions, 2020
2020
-
[25]
Yannakakis
Spyridon Kantarelis, Edmund Thomas, Wenqing Liu, Vassilis Lyberatos, Giorgos Stamou, and Georgios N. Yannakakis. Chordonomicon: A dataset of 666,000 songs and their chord progressions, 2024
2024
-
[26]
Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):3521–3526, 2017
2017
-
[27]
Learning without forgetting.IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(12):2935–2947, 2018
Zhizhong Li and Derek Hoiem. Learning without forgetting.IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(12):2935–2947, 2018
2018
-
[28]
Liang, Mark Gotham, Matthew Johnson, and Jamie Shotton
Feynman T. Liang, Mark Gotham, Matthew Johnson, and Jamie Shotton. Automatic stylistic composition of Bach chorales with deep LSTM. InInternational Society for Music Information Retrieval Conference, 2017
2017
-
[29]
Gradient episodic memory for continual learning
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. InNeurIPS, 2017
2017
-
[30]
Chord jazzification: Learning jazz interpretations of chord symbols
Dimos Makris, Ioannis Karydis, and Katia Lida Kermanidis. Chord jazzification: Learning jazz interpretations of chord symbols. InInternational Society for Music Information Retrieval Conference, 2020
2020
-
[31]
Michael McCloskey and Neal J. Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. InPsychology of Learning and Motivation, volume 24, pages 109–165. Academic Press, 1989
1989
-
[32]
JazzStandards: A community chord-sequence corpus derived from iReal Pro.https://github.com/mikeoliphant/JazzStandards, 2023
Oliphant, Mike and contributors. JazzStandards: A community chord-sequence corpus derived from iReal Pro.https://github.com/mikeoliphant/JazzStandards, 2023
2023
-
[33]
The continuator: Musical interaction with style.Journal of New Music Research, 32(3):333–341, 2003
François Pachet. The continuator: Musical interaction with style.Journal of New Music Research, 32(3):333–341, 2003
2003
-
[34]
A probabilistic model for chord progressions
Jean-François Paiement, Douglas Eck, and Samy Bengio. A probabilistic model for chord progressions. InInternational Society for Music Information Retrieval Conference, 2005
2005
-
[35]
MuseNet.https://openai.com/blog/musenet, 2019
Christine Payne. MuseNet.https://openai.com/blog/musenet, 2019
2019
-
[36]
Schott Cam- pus, 2017
Martin Pfleiderer, Klaus Frieler, Jakob Abeßer, Wolf-Georg Zaddach, and Benjamin Burkhardt.Inside the Jazzomat — New Perspectives for Jazz Research. Schott Cam- pus, 2017
2017
-
[37]
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H. Lampert. iCaRL: Incremental classifier and representation learning. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. 16
2017
-
[38]
A hierarchical latent vector model for learning long-term structure in music
Adam Roberts, Jesse Engel, Colin Raffel, Curtis Hawthorne, and Douglas Eck. A hierarchical latent vector model for learning long-term structure in music. InInternational Conference on Machine Learning (ICML), 2018
2018
-
[39]
Catastrophic forgetting, rehearsal and pseudorehearsal.Connection Science, 7(2), 1995
Anthony Robins. Catastrophic forgetting, rehearsal and pseudorehearsal.Connection Science, 7(2), 1995
1995
-
[40]
Towards a generative syntax of tonal harmony.Journal of Mathematics and Music, 5(1):35–53, 2011
Martin Rohrmeier. Towards a generative syntax of tonal harmony.Journal of Mathematics and Music, 5(1):35–53, 2011
2011
-
[41]
Experience replay for continual learning
David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy Lillicrap, and Greg Wayne. Experience replay for continual learning. InNeurIPS, 2019
2019
-
[42]
Steedman
Mark J. Steedman. A generative grammar for jazz chord sequences.Music Perception, 2(1):52–77, 1984
1984
-
[43]
Score Transformer: Generating musical score from note-level representa- tion
Masahiro Suzuki. Score Transformer: Generating musical score from note-level representa- tion. InACM Multimedia Asia, 2021
2021
-
[44]
Anticipatory music trans- former, 2024
John Thickstun, David Hall, Chris Donahue, and Percy Liang. Anticipatory music trans- former, 2024
2024
-
[45]
A comprehensive survey of continual learning: Theory, method and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8):5362–5383, 2024
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8):5362–5383, 2024
2024
-
[46]
Le, Tengyu Ma, and Adams Wei Yu
Sang Michael Xie, Hieu Pham, Xinyun Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy Liang, Quoc V. Le, Tengyu Ma, and Adams Wei Yu. DoReMi: Optimizing data mixtures speeds up language model pretraining. InNeurIPS, 2023
2023
-
[47]
MidiNet: A convolutional generative adversarial network for symbolic-domain music generation
Li-Chia Yang, Szu-Yu Chou, and Yi-Hsuan Yang. MidiNet: A convolutional generative adversarial network for symbolic-domain music generation. InInternational Society for Music Information Retrieval Conference, 2017. 17
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.