Recognition: unknown
SoK: Robustness in Large Language Models against Jailbreak Attacks
Pith reviewed 2026-05-08 16:38 UTC · model grok-4.3
The pith
Security Cube supplies a multi-dimensional framework that benchmarks 13 jailbreak attacks and 5 defenses to map LLM vulnerabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a systematic taxonomy combined with the Security Cube framework enables comprehensive benchmarking of jailbreak techniques and defenses, exposing current limitations and open problems in making large language models robust.
What carries the argument
Security Cube, a unified multi-dimensional framework that evaluates jailbreak attacks and defenses across several security aspects simultaneously.
Load-bearing premise
The chosen 13 attacks, 5 defenses, and the dimensions defined in Security Cube are representative enough to capture the full range of LLM security issues.
What would settle it
A previously unknown jailbreak attack that evades all five defenses while scoring low on every dimension of Security Cube, or a defense that blocks attacks across all dimensions with no measurable drop in model utility.
Figures




read the original abstract
Large Language Models (LLMs) have achieved remarkable success but remain highly susceptible to jailbreak attacks, in which adversarial prompts coerce models into generating harmful, unethical, or policy-violating outputs. Such attacks pose real-world risks, eroding safety, trust, and regulatory compliance in high-stakes applications. Although a variety of attack and defense methods have been proposed, existing evaluation practices are inadequate, often relying on narrow metrics like attack success rate that fail to capture the multidimensional nature of LLM security. In this paper, we present a systematic taxonomy of jailbreak attacks and defenses and introduce Security Cube, a unified, multi-dimensional framework for comprehensive evaluation of these techniques. We provide detailed comparison tables of existing attacks and defenses, highlighting key insights and open challenges across the literature. Leveraging Security Cube, we conduct benchmark studies on 13 representative attacks and 5 defenses, establishing a clear view of the current landscape encompassing jailbreak attacks, defenses, automated judges, and LLM vulnerabilities. Based on these evaluations, we distill critical findings, identify unresolved problems, and outline promising research directions for enhancing LLM robustness against jailbreak attacks. Our analysis aims to pave the way towards more robust, interpretable, and trustworthy LLM systems. Our code is available at Code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a systematization of knowledge (SoK) on jailbreak attacks against LLMs, introduces a taxonomy of attacks and defenses, proposes the Security Cube as a multi-dimensional evaluation framework, provides comparison tables of existing methods, and reports benchmark results on 13 representative attacks and 5 defenses to map the current landscape, distill findings on vulnerabilities and automated judges, and suggest research directions for improved robustness.
Significance. If the benchmarks hold, this work offers a valuable unified framework and landscape overview that could standardize evaluations beyond single-metric attack success rates, helping the field identify gaps in LLM safety; the open code and explicit taxonomy are strengths for reproducibility and future work.
major comments (1)
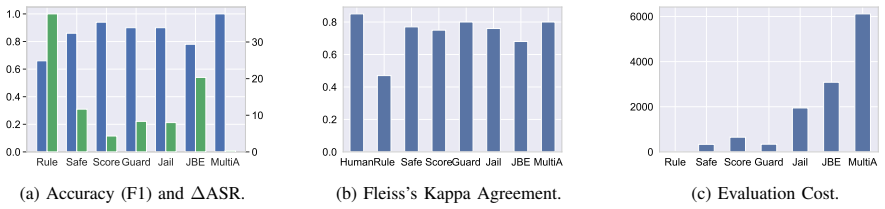
- [Benchmark studies] Benchmark studies section (as described in abstract): the central claim that the selected 13 attacks and 5 defenses, evaluated under Security Cube, establish a 'clear view of the current landscape' is load-bearing but rests on the unelaborated assertion that they are 'representative'; without explicit selection criteria or coverage analysis (e.g., across gradient-based vs. prompt-engineering attacks, alignment vs. detection defenses, or model families), the distilled findings and research directions risk incompleteness or selection bias, directly undermining the comprehensiveness asserted in the abstract.
minor comments (2)
- [Abstract] Abstract: the code availability statement ('Our code is available at Code.') is incomplete; provide the actual repository URL.
- Throughout: ensure all comparison tables explicitly reference the Security Cube dimensions used for each entry to improve traceability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and will revise the manuscript accordingly to strengthen the presentation of our benchmark studies.
read point-by-point responses
-
Referee: [Benchmark studies] Benchmark studies section (as described in abstract): the central claim that the selected 13 attacks and 5 defenses, evaluated under Security Cube, establish a 'clear view of the current landscape' is load-bearing but rests on the unelaborated assertion that they are 'representative'; without explicit selection criteria or coverage analysis (e.g., across gradient-based vs. prompt-engineering attacks, alignment vs. detection defenses, or model families), the distilled findings and research directions risk incompleteness or selection bias, directly undermining the comprehensiveness asserted in the abstract.
Authors: We agree that the selection of the 13 attacks and 5 defenses requires explicit justification to support the claim of a representative landscape view. While our taxonomy (Section 3) and comparison tables (Sections 4 and 5) already organize methods by core dimensions, the benchmark section does not sufficiently articulate the selection process. In the revised manuscript we will add a dedicated paragraph (and supporting table) in the Benchmark Studies section that states the criteria: (1) coverage of all major taxonomy branches (prompt-engineering vs. optimization/gradient-based attacks; alignment-based vs. detection-based defenses); (2) inclusion of both closed-source (GPT family) and open-source (Llama, Vicuna) model families; (3) prominence and recency in the literature. We will also include a coverage matrix showing how the chosen methods map onto the taxonomy axes, thereby demonstrating breadth and mitigating concerns of selection bias. These additions will be placed before the results tables so that the distilled findings rest on a transparent foundation. revision: yes
Circularity Check
No significant circularity in the SoK taxonomy, Security Cube framework, or benchmarks
full rationale
This is a systematization-of-knowledge paper that surveys existing jailbreak literature, proposes an independent multi-dimensional evaluation framework (Security Cube), and runs benchmarks on 13 attacks plus 5 defenses drawn from prior work. No mathematical derivations, parameter-fitting steps, or predictions appear in the provided text. The central claims rest on explicit selection of representative methods and construction of comparison tables rather than any self-referential definition, fitted-input-as-prediction, or load-bearing self-citation chain. The framework and taxonomy are presented as new organizing structures built on external literature, not as reductions of the paper's own inputs. Selection of the 13+5 methods is a representativeness judgment, not a circularity issue.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Security Cube
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Detecting language model attacks with perplexity
Gabriel Alon and Michael Kamfonas. Detecting language model attacks with perplexity.arXiv preprint arXiv:2308.14132, 2023
-
[2]
Jailbreaking leading safety-aligned llms with simple adaptive attacks
Maksym Andriushchenko, Francesco Croce, and Nicolas Flammar- ion. Jailbreaking leading safety-aligned llms with simple adaptive attacks. InICLR, 2025
2025
-
[3]
Claude 3.7 sonnet system card
Anthropic. Claude 3.7 sonnet system card. https://www.anthropic.com/news/claude-3-7-sonnet, 2025
2025
-
[4]
Mt- bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues
Ge Bai, Jie Liu, Xingyuan Bu, Yancheng He, Jiaheng Liu, Zhanhui Zhou, Zhuoran Lin, Wenbo Su, Tiezheng Ge, Bo Zheng, et al. Mt- bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues. InACL, pages 7421–7454, 2024
2024
-
[5]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmless- ness from ai feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review arXiv 2022
-
[6]
Safety-tuned llamas: Lessons from improving the safety of large language models that follow instructions
Federico Bianchi, Mirac Suzgun, Giuseppe Attanasio, Paul R ¨ottger, Dan Jurafsky, Tatsunori Hashimoto, and James Zou. Safety-tuned llamas: Lessons from improving the safety of large language models that follow instructions. InICLR, 2024
2024
-
[7]
A realistic threat model for large language model jailbreaks.arXiv preprint arXiv:2410.16222, 2024
Valentyn Boreiko, Alexander Panfilov, Vaclav V oracek, Matthias Hein, and Jonas Geiping. A realistic threat model for large language model jailbreaks.arXiv preprint arXiv:2410.16222, 2024
-
[8]
Baryannis, G., Validi, S., Dani, S., and Antoniou, G
Hannah Brown, Leon Lin, Kenji Kawaguchi, and Michael Shieh. Self-evaluation as a defense against adversarial attacks on llms. ArXiv, abs/2407.03234, 2024
-
[9]
Hongye Cao, Yanming Wang, Sijia Jing, Ziyue Peng, Zhixin Bai, Zhe Cao, Meng Fang, Fan Feng, Boyan Wang, Jiaheng Liu, Tianpei Yang, Jing Huo, Yang Gao, Fanyu Meng, Xi Yang, Chao Deng, and Junlan Feng. Safedialbench: A fine-grained safety benchmark for large language models in multi-turn dialogues with diverse jailbreak attacks.ArXiv, abs/2502.11090, 2025
-
[10]
Evaluating the feasibility of chatgpt in healthcare: an analysis of multiple clinical and research scenarios.Journal of medical systems, 47(1):33, 2023
Marco Cascella, Jonathan Montomoli, Valentina Bellini, and Elena Bignami. Evaluating the feasibility of chatgpt in healthcare: an analysis of multiple clinical and research scenarios.Journal of medical systems, 47(1):33, 2023
2023
-
[11]
Pappas, Florian Tram `er, Hamed Hassani, and Eric Wong
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tram `er, Hamed Hassani, and Eric Wong. Jailbreakbench: An open robustness benchmark for jailbreaking large language models.NIPS, 37:55005– 55029, 2024
2024
-
[12]
Jailbreaking black box large language models in twenty queries
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries. InSaTML, pages 23–42. IEEE, 2025
2025
-
[13]
Comprehensive assessment of jailbreak attacks against LLMs
Junjie Chu, Yugeng Liu, Ziqing Yang, Xinyue Shen, Michael Backes, and Yang Zhang. Comprehensive assessment of jailbreak attacks against llms.arXiv preprint arXiv:2402.05668, 2024
-
[14]
Safe rlhf: Safe reinforcement learning from human feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe rlhf: Safe reinforcement learning from human feedback. InICLR, 2024
2024
-
[15]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025
2025
-
[16]
Multilingual jailbreak challenges in large language models
Yue Deng, Wenxuan Zhang, Sinno Jialin Pan, and Lidong Bing. Multilingual jailbreak challenges in large language models. InICLR, 2024
2024
-
[17]
Garak: A framework for security probing of large language models
Leon Derczynski, Erick Galinkin, Jeffrey Martin, Subho Majumdar, and Nanna Inie. garak: A framework for security probing large language models.arXiv preprint arXiv:2406.11036, 2024
-
[18]
A wolf in sheep’s clothing: Generalized nested jailbreak prompts can fool large language models easily
Peng Ding, Jun Kuang, Dan Ma, Xuezhi Cao, Yunsen Xian, Jiajun Chen, and Shujian Huang. A wolf in sheep’s clothing: Generalized nested jailbreak prompts can fool large language models easily. In NAACL, pages 2136–2153, 2024
2024
-
[19]
A compre- hensive survey of attack techniques, implementation, and mitigation strategies in large language models
Aysan Esmradi, Daniel Wankit Yip, and Chun Fai Chan. A compre- hensive survey of attack techniques, implementation, and mitigation strategies in large language models. InUbiSec, 2023
2023
-
[20]
Measuring nominal scale agreement among many raters.Psychological bulletin, 76(5):378, 1971
Joseph L Fleiss. Measuring nominal scale agreement among many raters.Psychological bulletin, 76(5):378, 1971
1971
-
[21]
Shaping the safety boundaries: Understanding and defending against jailbreaks in large language models
Lang Gao, Xiangliang Zhang, Preslav Nakov, and Xiuying Chen. Shaping the safety boundaries: Understanding and defending against jailbreaks in large language models. InACL, 2025
2025
-
[22]
Gemini-2.0-flash documents
Google. Gemini-2.0-flash documents. https://modelcards.withgoogle.com/assets/documents/gemini-2- flash.pdf, 2025
2025
-
[23]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review arXiv 2024
-
[24]
Melody Y . Guan, Manas Joglekar, Eric Wallace, Saachi Jain, Boaz Barak, Alec Helyar, Rachel Dias, Andrea Vallone, Hongyu Ren, Jason Wei, Hyung Won Chung, Sam Toyer, Johannes Heidecke, Alex Beutel, and Amelia Glaese. Deliberative alignment: Reasoning enables safer language models, 2025
2025
-
[25]
Cold-attack: Jailbreaking llms with stealthiness and controllability
Xingang Guo, Fangxu Yu, Huan Zhang, Lianhui Qin, and Bin Hu. Cold-attack: Jailbreaking llms with stealthiness and controllability. InICML, pages 16974–17002. PMLR, 2024
2024
-
[26]
Columbia university, 1997
Orris C Herfindahl.Concentration in the steel industry. Columbia university, 1997
1997
-
[27]
Xinzhe Huang, Kedong Xiu, Tianhang Zheng, Churui Zeng, Wangze Ni, Zhan Qiin, Kui Ren, and Chun Chen. Dualbreach: Efficient dual-jailbreaking via target-driven initialization and multi-target op- timization.ArXiv, abs/2504.18564, 2025
-
[28]
John Hughes, Sara Price, Aengus Lynch, Rylan Schaeffer, Fazl Barez, Sanmi Koyejo, Henry Sleight, Erik Jones, Ethan Perez, and Mrinank Sharma. Best-of-n jailbreaking.arXiv preprint arXiv:2412.03556, 2024
-
[29]
Llama guard: Llm- based input-output safeguard for human-ai conversations, 2023
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. Llama guard: Llm- based input-output safeguard for human-ai conversations, 2023
2023
-
[30]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beu- tel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024. 15
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Aligner: Efficient alignment by learning to correct
Jiaming Ji, Boyuan Chen, Hantao Lou, Donghai Hong, Borong Zhang, Xuehai Pan, Tianyi Qiu, Juntao Dai, and Yaodong Yang. Aligner: Efficient alignment by learning to correct. InNIPS, 2024
2024
-
[32]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bam- ford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L ´elio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timoth ´ee Lacroix, and William El Sayed. Mistral 7b, 2023
2023
-
[33]
Artprompt: Ascii art-based jailbreak attacks against aligned llms
Fengqing Jiang, Zhangchen Xu, Luyao Niu, Zhen Xiang, Bhaskar Ramasubramanian, Bo Li, and Radha Poovendran. Artprompt: Ascii art-based jailbreak attacks against aligned llms. InACL, 2024
2024
-
[34]
Chatgpt for good? on opportunities and challenges of large language models for education
Enkelejda Kasneci, Kathrin Seßler, Stefan K ¨uchemann, Maria Ban- nert, Daryna Dementieva, Frank Fischer, Urs Gasser, Georg Groh, Stephan G¨unnemann, Eyke H ¨ullermeier, et al. Chatgpt for good? on opportunities and challenges of large language models for education. Learning and individual differences, 103:102274, 2023
2023
-
[35]
h4rm3l: A dynamic benchmark of composable jailbreak attacks for llm safety assessment.arXiv e- prints, pages arXiv–2408, 2024
Moussa Koulako Bala Doumbouya, Ananjan Nandi, Gabriel Poesia, Davide Ghilardi, Anna Goldie, Federico Bianchi, Dan Jurafsky, and Christopher D Manning. h4rm3l: A dynamic benchmark of composable jailbreak attacks for llm safety assessment.arXiv e- prints, pages arXiv–2408, 2024
2024
-
[36]
Certifying llm safety against adversarial prompting
Aounon Kumar, Chirag Agarwal, Suraj Srinivas, Aaron Jiaxun Li, Soheil Feizi, and Himabindu Lakkaraju. Certifying llm safety against adversarial prompting. InCOLM, 2024
2024
-
[37]
Jailpo: A novel black-box jailbreak framework via preference optimization against aligned llms
Hongyi Li, Jiawei Ye, Jie Wu, Tianjie Yan, Chu Wang, and Zhixin Li. Jailpo: A novel black-box jailbreak framework via preference optimization against aligned llms. InAAAI, pages 27419–27427, 2025
2025
-
[38]
One model transfer to all: On robust jailbreak prompts generation against llms
Linbao Li, Yannan Liu, Daojing He, and Yu Li. One model transfer to all: On robust jailbreak prompts generation against llms. InICLR, 2025
2025
-
[39]
Drattack: Prompt decomposition and reconstruction makes powerful llm jailbreakers
Xirui Li, Ruochen Wang, Minhao Cheng, Tianyi Zhou, and Cho-Jui Hsieh. Drattack: Prompt decomposition and reconstruction makes powerful llm jailbreakers. InEMNLP, 2024
2024
-
[40]
Deepincep- tion: Hypnotize large language model to be jailbreaker
Xuan Li, Zhanke Zhou, Jianing Zhu, Jiangchao Yao, Tongliang Liu, and Bo Han. Deepinception: Hypnotize large language model to be jailbreaker.arXiv preprint arXiv:2311.03191, 2023
-
[41]
Hashimoto
Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gul- rajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Alpacaeval: An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca eval, 5 2023
2023
-
[42]
Amplegcg: Learning a universal and transferable generative model of adversarial suffixes for jailbreaking both open and closed llms
Zeyi Liao and Huan Sun. Amplegcg: Learning a universal and transferable generative model of adversarial suffixes for jailbreaking both open and closed llms. InCOLM, 2024
2024
-
[43]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review arXiv 2024
-
[44]
Fan Liu, Yue Feng, Zhao Xu, Lixin Su, Xinyu Ma, Dawei Yin, and Hao Liu. Jailjudge: A comprehensive jailbreak judge benchmark with multi-agent enhanced explanation evaluation framework.ArXiv, abs/2410.12855, 2024
-
[45]
Edward Suh, Yevgeniy V orobeychik, Zhuoqing Mao, Somesh Jha, Patrick McDaniel, Huan Sun, Bo Li, and Chaowei Xiao
Xiaogeng Liu, Peiran Li, G. Edward Suh, Yevgeniy V orobeychik, Zhuoqing Mao, Somesh Jha, Patrick McDaniel, Huan Sun, Bo Li, and Chaowei Xiao. AutoDAN-turbo: A lifelong agent for strategy self-exploration to jailbreak LLMs. InICLR, 2025
2025
-
[46]
Autodan: Generating stealthy jailbreak prompts on aligned large language models
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. Autodan: Generating stealthy jailbreak prompts on aligned large language models. InICLR, 2024
2024
-
[47]
Yanjiang Liu, Shuheng Zhou, Yaojie Lu, Huijia Zhu, Weiqiang Wang, Hongyu Lin, Ben He, Xianpei Han, and Le Sun. Auto- rt: Automatic jailbreak strategy exploration for red-teaming large language models.ArXiv, abs/2501.01830, 2025
-
[48]
doi:10.48550/arXiv.2410.02832 , abstract =
Yue Liu, Xiaoxin He, Miao Xiong, Jinlan Fu, Shumin Deng, and Bryan Hooi. Flipattack: Jailbreak llms via flipping.arXiv preprint arXiv:2410.02832, 2024
-
[49]
Safety at Scale: A Comprehensive Survey of Large Model and Agent Safety
Xingjun Ma, Yifeng Gao, Yixu Wang, Ruofan Wang, Xin Wang, Ye Sun, Yifan Ding, Hengyuan Xu, Yunhao Chen, Yunhan Zhao, et al. Safety at scale: A comprehensive survey of large model safety. arXiv preprint arXiv:2502.05206, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
You can’t eat your cake and have it too: The performance degradation of llms with jailbreak defense
Wuyuao Mai, Geng Hong, Pei Chen, Xudong Pan, Baojun Liu, Yuan Zhang, Haixin Duan, and Min Yang. You can’t eat your cake and have it too: The performance degradation of llms with jailbreak defense. InWWW, pages 872–883, 2025
2025
-
[51]
Harmbench: A standardized evaluation framework for auto- mated red teaming and robust refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. Harmbench: A standardized evaluation framework for auto- mated red teaming and robust refusal. InICML, pages 35181–35224. PMLR, 2024
2024
-
[52]
Tree of attacks: Jailbreaking black-box llms automatically.NIPS, 37:61065– 61105, 2024
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nel- son, Hyrum Anderson, Yaron Singer, and Amin Karbasi. Tree of attacks: Jailbreaking black-box llms automatically.NIPS, 37:61065– 61105, 2024
2024
-
[53]
Fight back against jailbreaking via prompt adversarial tuning
Yichuan Mo, Yuji Wang, Zeming Wei, and Yisen Wang. Fight back against jailbreaking via prompt adversarial tuning. InNIPS, 2024
2024
-
[54]
Sg-bench: Evaluating llm safety generalization across diverse tasks and prompt types.NIPS, 37:123032–123054, 2024
Yutao Mou, Shikun Zhang, and Wei Ye. Sg-bench: Evaluating llm safety generalization across diverse tasks and prompt types.NIPS, 37:123032–123054, 2024
2024
-
[55]
Accessed: 2024-02- 25
Zvi Mowshowitz., 2022. Accessed: 2024-02- 25
2022
-
[56]
Gary D Lopez Munoz, Amanda J Minnich, Roman Lutz, Richard Lundeen, Raja Sekhar Rao Dheekonda, Nina Chikanov, Bolor- Erdene Jagdagdorj, Martin Pouliot, Shiven Chawla, Whitney Maxwell, et al. Pyrit: A framework for security risk identifi- cation and red teaming in generative ai system.arXiv preprint arXiv:2410.02828, 2024
-
[57]
arXiv preprint arXiv:2402.02309 , year=
Zhenxing Niu, Haodong Ren, Xinbo Gao, Gang Hua, and Rong Jin. Jailbreaking attack against multimodal large language model.arXiv preprint arXiv:2402.02309, 2024
-
[58]
gpt-3.5-turbo system card
OpenAI. gpt-3.5-turbo system card. https://platform.openai.com/docs/models/gpt-3.5-turbo, 2023
2023
-
[59]
How we think about safety and alignment
OpenAI. How we think about safety and alignment. https://openai.com/safety/how-we-think-about-safety-alignment/, 2025
2025
-
[60]
Training language models to follow instruc- tions with human feedback.NIPS, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wain- wright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instruc- tions with human feedback.NIPS, 35:27730–27744, 2022
2022
-
[61]
Benji Peng, Ziqian Bi, Qian Niu, Ming Liu, Pohsun Feng, Tianyang Wang, Lawrence KQ Yan, Yizhu Wen, Yichao Zhang, and Cait- lyn Heqi Yin. Jailbreaking and mitigation of vulnerabilities in large language models.arXiv preprint arXiv:2410.15236, 2024
-
[62]
Safety alignment should be made more than just a few tokens deep
Xiangyu Qi, Ashwinee Panda, Kaifeng Lyu, Xiao Ma, Subhrajit Roy, Ahmad Beirami, Prateek Mittal, and Peter Henderson. Safety alignment should be made more than just a few tokens deep. In ICLR, 2025
2025
-
[63]
Qwen. Qwen-2.5-max technical report. https://www.researchgate.net/publication/388485555 Technical Report on Qwen-25 Max, 2025
-
[64]
Jailbreakeval: An integrated toolkit for evaluating jailbreak attempts against large language models
Delong Ran, Jinyuan Liu, Yichen Gong, Jingyi Zheng, Xinlei He, Tianshuo Cong, and Anyu Wang. Jailbreakeval: An integrated toolkit for evaluating jailbreak attempts against large language models. ArXiv, abs/2406.09321, 2024
-
[65]
Tricking llms into disobedience: Formalizing, analyzing, and detecting jailbreaks
Abhinav Rao, Sachin Vashistha, Atharva Naik, Somak Aditya, and Monojit Choudhury. Tricking llms into disobedience: Formalizing, analyzing, and detecting jailbreaks. InLREC, 2023. 16
2023
-
[66]
Codeattack: Revealing safety generalization challenges of large language models via code completion
Qibing Ren, Chang Gao, Jing Shao, Junchi Yan, Xin Tan, Wai Lam, and Lizhuang Ma. Codeattack: Revealing safety generalization challenges of large language models via code completion. InACL, pages 11437–11452, 2024
2024
-
[67]
LLMs know their vulnerabilities: Uncover safety gaps through natural distribution shifts.ACL, 2025
Qibing Ren, Hao Li, Dongrui Liu, Zhanxu Xie, Xiaoya Lu, Yu Qiao, Lei Sha, Junchi Yan, Lizhuang Ma, and Jing Shao. LLMs know their vulnerabilities: Uncover safety gaps through natural distribution shifts.ACL, 2025
2025
-
[68]
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks
Alexander Robey, Eric Wong, Hamed Hassani, and George J. Pap- pas. Smoothllm: Defending large language models against jailbreak- ing attacks.ArXiv, abs/2310.03684, 2023
work page internal anchor Pith review arXiv 2023
-
[69]
Code Llama: Open Foundation Models for Code
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950, 2023
work page internal anchor Pith review arXiv 2023
-
[70]
Great, now write an article about that: The crescendo multi-turn llm jailbreak attack
Mark Russinovich, Ahmed Salem, and Ronen Eldan. Great, now write an article about that: The crescendo multi-turn llm jailbreak attack. InUSENIX Security, pages 2421–2440, 2025
2025
-
[71]
Guobin Shen, Dongcheng Zhao, Linghao Feng, Xiang He, Jihang Wang, Sicheng Shen, Haibo Tong, Yiting Dong, Jindong Li, Xiang Zheng, et al. Pandaguard: Systematic evaluation of llm safety against jailbreaking attacks.arXiv preprint arXiv:2505.13862, 2025
-
[72]
” do anything now”: Characterizing and evaluating in-the- wild jailbreak prompts on large language models
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. ” do anything now”: Characterizing and evaluating in-the- wild jailbreak prompts on large language models. InACM SIGSAC, pages 1671–1685, 2024
2024
-
[73]
Pal: Proxy-guided black-box attack on large language models,
Chawin Sitawarin, Norman Mu, David Wagner, and Alexandre Araujo. Pal: Proxy-guided black-box attack on large language models.ArXiv, abs/2402.09674, 2024
-
[74]
Trustllm: Trustworthiness in large language models
Lichao Sun, Yue Huang, Haoran Wang, Siyuan Wu, Qihui Zhang, Chujie Gao, Yixin Huang, Wenhan Lyu, Yixuan Zhang, Xiner Li, et al. Trustllm: Trustworthiness in large language models. InICML, pages 20166–20270, 2024
2024
-
[75]
Angel, and Arul Jothi
Sadaf Surur, J. Angel, and Arul Jothi. Jailbreak attacks on large language models and possible defenses: Present status and future possibilities.ISTAS, pages 1–7, 2024
2024
-
[76]
Decodingtrust: A comprehensive assessment of trustworthiness in gpt models.NIPS, 36:31232–31339, 2023
Boxin Wang, Weixin Chen, Hengzhi Pei, Chulin Xie, Mintong Kang, Chenhui Zhang, Chejian Xu, Zidi Xiong, Ritik Dutta, Rylan Schaeffer, et al. Decodingtrust: A comprehensive assessment of trustworthiness in gpt models.NIPS, 36:31232–31339, 2023
2023
-
[77]
Fengxiang Wang, Ranjie Duan, Peng Xiao, Xiaojun Jia, Shiji Zhao, Cheng Wei, YueFeng Chen, Chongwen Wang, Jialing Tao, Hang Su, et al. Mrj-agent: An effective jailbreak agent for multi-round dialogue.arXiv preprint arXiv:2411.03814, 2024
-
[78]
Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation
Yue Wang, Weishi Wang, Shafiq Joty, and Steven CH Hoi. Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation. InEMNLP, pages 8696–8708. Asso- ciation for Computational Linguistics (ACL), 2021
2021
-
[79]
Jochen Wulf and J ¨urg Meierhofer. Exploring the potential of large language models for automation in technical customer service.arXiv preprint arXiv:2405.09161, 2024
-
[80]
Defending chatgpt against jailbreak attack via self-reminders.Nature Machine Intelli- gence, 5:1486–1496, 2023
Yueqi Xie, Jingwei Yi, Jiawei Shao, Justin Curl, Lingjuan Lyu, Qifeng Chen, Xing Xie, and Fangzhao Wu. Defending chatgpt against jailbreak attack via self-reminders.Nature Machine Intelli- gence, 5:1486–1496, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.