Recognition: unknown
The Impossibility Triangle of Long-Context Modeling
Pith reviewed 2026-05-08 17:11 UTC · model grok-4.3
The pith
No long-sequence model can keep per-step computation fixed, state size fixed, and recall capacity growing with length.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Within the Online Sequence Processor abstraction, any model obeying Efficiency and Compactness is provably limited to recalling O(poly(d)/log V) key-value pairs from an arbitrarily long sequence. The bound is obtained by showing that the fixed-size state can transmit only a limited amount of distinguishable information about the history, with the Data Processing Inequality controlling the flow through each step and Fano's Inequality converting that information into a recall error probability.
What carries the argument
The Online Sequence Processor abstraction, which represents every architecture as a state-update rule whose per-step cost and state dimension are independent of sequence length.
Load-bearing premise
Every relevant long-sequence model, including Transformers and state-space models, can be faithfully described as an Online Sequence Processor whose state-update rule satisfies the fixed-cost and fixed-size constraints.
What would settle it
A concrete model that, on associative-recall tasks with sequence lengths far exceeding poly(d), maintains both constant per-step computation and constant state size while correctly retrieving a number of key-value pairs that grows linearly with length.
Figures





read the original abstract
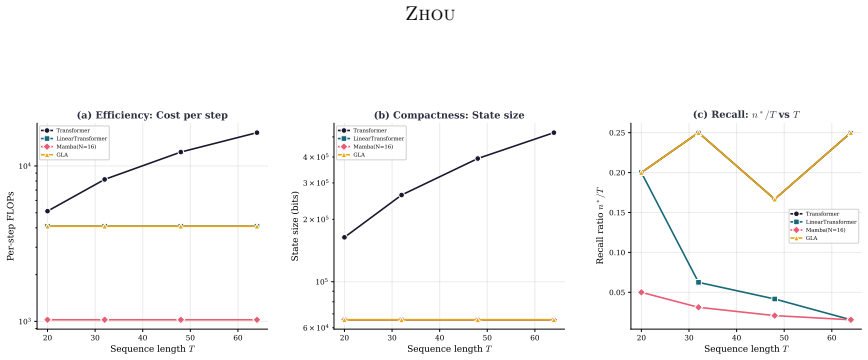
We identify and prove a fundamental trade-off governing long-sequence models: no model can simultaneously achieve (i) per-step computation independent of sequence length (Efficiency), (ii) state size independent of sequence length (Compactness), and (iii) the ability to recall a number of historical facts proportional to sequence length (Recall). We formalize this trade-off within an Online Sequence Processor abstraction that unifies Transformers, state space models, linear recurrent networks, and their hybrids. Using the Data Processing Inequality and Fano's Inequality, we prove that any model satisfying Efficiency and Compactness can recall at most O(poly(d)/log V) key-value pairs from a sequence of arbitrary length, where d is the model dimension and V is the vocabulary size. We classify 52 architectures published before March 2026 into the triangle, showing that each achieves at most two of the three properties and that hybrid architectures trace continuous trajectories in the interior. Experiments on synthetic associative recall tasks with five representative architectures validate the theoretical bound: empirical recall capacity lies strictly below the information-theoretic limit, and no architecture escapes the triangle.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to identify and prove a fundamental impossibility triangle for long-sequence models: no model can simultaneously achieve Efficiency (per-step computation independent of sequence length), Compactness (state size independent of sequence length), and Recall (recovering Θ(length) historical facts). It introduces the Online Sequence Processor (OSP) abstraction unifying Transformers, state space models, linear recurrent networks, and hybrids. Using the Data Processing Inequality and Fano's Inequality, it proves that Efficiency + Compactness implies recall bounded by O(poly(d)/log V) independent of length. It classifies 52 pre-2026 architectures into the triangle and validates via synthetic associative recall experiments on five models showing empirical recall below the bound.
Significance. If correct, the result provides a unifying information-theoretic lens on long-context limitations, explaining architectural trade-offs across many models. Strengths include the classification of 52 architectures and synthetic experiments that empirically respect the derived bound without parameter fitting. The derivation from standard inequalities (DPI, Fano) to a length-independent bound is a positive aspect.
major comments (2)
- [Abstract and §1] Abstract and §1: The universal phrasing 'no model can simultaneously achieve' the three properties exceeds what is formally proven, which applies only inside the OSP abstraction. The paper must explicitly delimit the claim to models captured by the state-update and information-flow rules of OSP, and address whether external-memory or non-Markovian architectures fall outside (as raised by the stress-test concern).
- [Proof section (main theorem)] Proof section (main theorem): The application of Data Processing Inequality followed by Fano's Inequality to obtain the O(poly(d)/log V) recall bound is only sketched. The manuscript must supply the complete step-by-step derivation, including how the fixed-state Markovian update in OSP produces the information bottleneck and how the poly(d) term arises, so the bound can be independently verified.
minor comments (2)
- [Classification table] The table classifying the 52 architectures would be clearer if it included explicit criteria or decision rules used to assign each model to Efficiency, Compactness, or Recall vertices.
- [Experiments section] Synthetic experiment figures should report variance across multiple random seeds or runs to demonstrate that observed recall capacities lie reliably below the theoretical limit.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major comment below and commit to revisions that strengthen the manuscript's clarity and rigor.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1: The universal phrasing 'no model can simultaneously achieve' the three properties exceeds what is formally proven, which applies only inside the OSP abstraction. The paper must explicitly delimit the claim to models captured by the state-update and information-flow rules of OSP, and address whether external-memory or non-Markovian architectures fall outside (as raised by the stress-test concern).
Authors: We agree that greater precision is warranted. While the manuscript already states that the trade-off is formalized within the OSP abstraction, the abstract and §1 will be revised to explicitly delimit the impossibility result to models obeying the OSP state-update and information-flow rules. We will also add a dedicated paragraph discussing models outside this class (e.g., external-memory or non-Markovian architectures), noting that they lie beyond the scope of the current analysis and may evade the triangle, thereby addressing the stress-test concern. revision: yes
-
Referee: [Proof section (main theorem)] Proof section (main theorem): The application of Data Processing Inequality followed by Fano's Inequality to obtain the O(poly(d)/log V) recall bound is only sketched. The manuscript must supply the complete step-by-step derivation, including how the fixed-state Markovian update in OSP produces the information bottleneck and how the poly(d) term arises, so the bound can be independently verified.
Authors: We acknowledge that the main-theorem proof is presented concisely. The revised manuscript will expand this section into a fully detailed, numbered derivation: (1) formal definition of the fixed-size Markovian state update under Efficiency + Compactness, (2) application of the Data Processing Inequality to establish the information bottleneck between the input sequence and the model's output, (3) explicit derivation of the mutual-information upper bound that yields the poly(d) dependence on model dimension, and (4) invocation of Fano's Inequality to obtain the final O(poly(d)/log V) recall-capacity limit. This expanded proof will enable independent verification. revision: yes
Circularity Check
No circularity: deductive proof from standard inequalities on defined abstraction
full rationale
The derivation defines the Online Sequence Processor abstraction explicitly, then applies the Data Processing Inequality and Fano's Inequality (standard external results) to obtain the O(poly(d)/log V) recall bound under Efficiency and Compactness. This is a direct information-theoretic deduction, not a reduction to fitted parameters, self-referential definitions, or self-citation chains. The classification of 52 models and synthetic experiments are presented as validation within the abstraction rather than as load-bearing premises for the proof itself. No step equates the claimed impossibility to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Data Processing Inequality applies to the Online Sequence Processor
- domain assumption Fano's Inequality applies to the recall task in the abstraction
invented entities (1)
-
Online Sequence Processor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gqa: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel De Jong, Yury Zemlyanskiy, Federico Lebr´ on, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4895–4901,
2023
-
[2]
Simple linear attention language models balance the recall-throughput tradeoff, 2024
Simran Arora, Sabri Eyuboglu, Michael Zhang, Aman Timalsina, Silas Alberti, Dylan Zins- ley, James Zou, Atri Rudra, and Christopher R´ e. Simple linear attention language models balance the recall-throughput tradeoff.arXiv preprint arXiv:2402.18668,
-
[3]
arXiv preprint arXiv:2501.00663 , year=
Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Titans: Learning to memorize at test time. arXiv preprint arXiv:2501.00663,
-
[4]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document trans- former.arXiv preprint arXiv:2004.05150,
work page internal anchor Pith review arXiv 2004
-
[5]
Nemotron-h: A family of accurate and efficient hybrid mamba-transformer models
Aaron Blakeman, Aarti Basant, Abhinav Khattar, Adithya Renduchintala, Akhiad Bercovich, Aleksander Ficek, Alexis Bjorlin, Ali Taghibakhshi, Amala Sanjay Deshmukh, Ameya Sunil Mahabaleshwarkar, et al. Nemotron-h: A family of accurate and efficient hybrid mamba-transformer models.arXiv preprint arXiv:2504.03624,
-
[6]
Generating Long Sequences with Sparse Transformers
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509,
work page internal anchor Pith review arXiv 1904
-
[7]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691,
work page internal anchor Pith review arXiv
-
[8]
URLhttps://arxiv.org/abs/ 2405.21060. Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher R´ e. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359,
work page internal anchor Pith review arXiv
-
[9]
Griffin: Mixing gated linear recurrences with local attention for efficient language models,
37 Zhou Soham De, Samuel L Smith, Anushan Fernando, Aleksandar Botev, George Cristian- Muraru, Albert Gu, Ruba Haroun, Leonard Berrada, Yutian Chen, Srivatsan Srinivasan, et al. Griffin: Mixing gated linear recurrences with local attention for efficient language models.arXiv preprint arXiv:2402.19427,
-
[10]
Were RNNs all we needed?arXiv preprint arXiv:2410.01201, 2024
Leo Feng, Frederick Tung, Mohamed Osama Ahmed, Yoshua Bengio, and Hossein Hajimir- sadeghi. Were rnns all we needed?arXiv preprint arXiv:2410.01201,
-
[11]
Daniel Y Fu, Tri Dao, Khaled K Saab, Armin W Thomas, Atri Rudra, and Christopher R´ e. Hungry hungry hippos: Towards language modeling with state space models. arxiv 2022.arXiv preprint arXiv:2212.14052,
-
[12]
The zamba2 suite: Technical report
Paolo Glorioso, Quentin Anthony, Yury Tokpanov, Anna Golubeva, Vasudev Shyam, James Whittington, Jonathan Pilault, and Beren Millidge. The zamba2 suite: Technical report. arXiv preprint arXiv:2411.15242, 2024a. Paolo Glorioso, Quentin Anthony, Yury Tokpanov, James Whittington, Jonathan Pilault, Adam Ibrahim, and Beren Millidge. Zamba: A compact 7b ssm hyb...
-
[13]
Efficiently Modeling Long Sequences with Structured State Spaces
Albert Gu, Karan Goel, and Christopher R´ e. Efficiently modeling long sequences with structured state spaces.arXiv preprint arXiv:2111.00396,
work page internal anchor Pith review arXiv
-
[14]
Lm-infinite: Zero-shot extreme length generalization for large language models
Chi Han, Qifan Wang, Hao Peng, Wenhan Xiong, Yu Chen, Heng Ji, and Sinong Wang. Lm-infinite: Zero-shot extreme length generalization for large language models. InPro- ceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 3991–4008,
2024
-
[15]
Hongye Jin, Xiaotian Han, Jingfeng Yang, Zhimeng Jiang, Zirui Liu, Chia-Yuan Chang, Huiyuan Chen, and Xia Hu. Llm maybe longlm: Self-extend llm context window without tuning.arXiv preprint arXiv:2401.01325,
-
[16]
URLhttps://proceedings.mlr.press/v119/katharopoulos20a. html. Nikita Kitaev, Lukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. arXiv preprint arXiv:2001.04451,
work page internal anchor Pith review arXiv 2001
-
[17]
Li, Berlin Chen, Caitlin Wang, Aviv Bick, J
Aakash Lahoti, Kevin Y Li, Berlin Chen, Caitlin Wang, Aviv Bick, J Zico Kolter, Tri Dao, and Albert Gu. Mamba-3: Improved sequence modeling using state space principles. arXiv preprint arXiv:2603.15569,
-
[18]
Aonian Li, Bangwei Gong, Bo Yang, Boji Shan, Chang Liu, Cheng Zhu, Chunhao Zhang, Congchao Guo, Da Chen, Dong Li, et al. Minimax-01: Scaling foundation models with lightning attention.arXiv preprint arXiv:2501.08313,
-
[19]
Jamba: A Hybrid Transformer-Mamba Language Model
Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, et al. Jamba: A hybrid transformer-mamba language model.arXiv preprint arXiv:2403.19887,
work page internal anchor Pith review arXiv
-
[20]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434,
work page internal anchor Pith review arXiv
-
[21]
Ring Attention with Blockwise Transformers for Near-Infinite Context
Hao Liu, Matei Zaharia, and Pieter Abbeel. Ring attention with blockwise transformers for near-infinite context.arXiv preprint arXiv:2310.01889,
work page internal anchor Pith review arXiv
-
[22]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arxiv.arXiv preprint arXiv:1711.05101, 10,
work page internal anchor Pith review arXiv
-
[23]
Mega: Moving average equipped gated atten- tion.arXiv preprint arXiv:2209.10655,
Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer. Mega: Moving average equipped gated atten- tion.arXiv preprint arXiv:2209.10655,
-
[24]
39 Zhou Tsendsuren Munkhdalai, Manaal Faruqui, and Siddharth Gopal. Leave no context behind: Efficient infinite context transformers with infini-attention.arXiv preprint arXiv:2404.07143, 101:15,
-
[25]
Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Stella Bider- man, Huanqi Cao, Xin Cheng, Michael Chung, Leon Derczynski, et al. Rwkv: Reinventing rnns for the transformer era. InFindings of the association for computational linguistics: EMNLP 2023, pages 14048–14077, 2023a. Bo Peng, Daniel Goldstein, Quentin Anthony, Alon Albalak,...
-
[26]
RWKV-7 “Goose” with expressive dynamic state evolution, 2025
Bo Peng, Ruichong Zhang, Daniel Goldstein, Eric Alcaide, Xingjian Du, Haowen Hou, Jiaju Lin, Jiaxing Liu, Janna Lu, William Merrill, et al. Rwkv-7” goose” with expressive dynamic state evolution.arXiv preprint arXiv:2503.14456,
-
[27]
YaRN: Efficient Context Window Extension of Large Language Models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. Yarn: Efficient context window extension of large language models.arXiv preprint arXiv:2309.00071, 2023b. Michael Poli, Stefano Massaroli, Eric Nguyen, Daniel Y Fu, Tri Dao, Stephen Baccus, Yoshua Bengio, Stefano Ermon, and Christopher R´ e. Hyena hierarchy: Towards larger convolutional langu...
work page internal anchor Pith review arXiv
-
[28]
arXiv preprint arXiv:2404.07904 , year=
Zhen Qin, Songlin Yang, Weixuan Sun, Xuyang Shen, Dong Li, Weigao Sun, and Yiran Zhong. Hgrn2: Gated linear rnns with state expansion.arXiv preprint arXiv:2404.07904,
-
[29]
Samba: Simple hybrid state space models for efficient unlimited context language modeling
Liliang Ren, Yang Liu, Yadong Lu, Yelong Shen, Chen Liang, and Weizhu Chen. Samba: Simple hybrid state space models for efficient unlimited context language modeling.arXiv preprint arXiv:2406.07522,
-
[30]
Fast Transformer Decoding: One Write-Head is All You Need
Noam Shazeer. Fast transformer decoding: One write-head is all you need.arXiv preprint arXiv:1911.02150,
work page internal anchor Pith review arXiv 1911
-
[31]
T., Warrington, A., and Linderman, S
40 Impossibility Triangle of Long-Context Modeling Jimmy TH Smith, Andrew Warrington, and Scott W Linderman. Simplified state space layers for sequence modeling, 2023.URL https://arxiv. org/abs/2208.04933, 2208:04933. Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, et al. Learn...
-
[32]
N., Hutchins, D., and Szegedy, C
Yuhuai Wu, Markus N Rabe, DeLesley Hutchins, and Christian Szegedy. Memorizing trans- formers.arXiv preprint arXiv:2203.08913,
-
[33]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient stream- ing language models with attention sinks.arXiv preprint arXiv:2309.17453,
work page internal anchor Pith review arXiv
-
[34]
arXiv preprint arXiv:2312.06635 , year=
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, and Yoon Kim. Gated linear attention transformers with hardware-efficient training.arXiv preprint arXiv:2312.06635,
-
[35]
Gated Delta Networks: Improving Mamba2 with Delta Rule
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule.arXiv preprint arXiv:2412.06464, 2024a. Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. Parallelizing linear transformers with the delta rule over sequence length.Advances in neural information processing systems, 37:115491–115522, 2024b. J...
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.