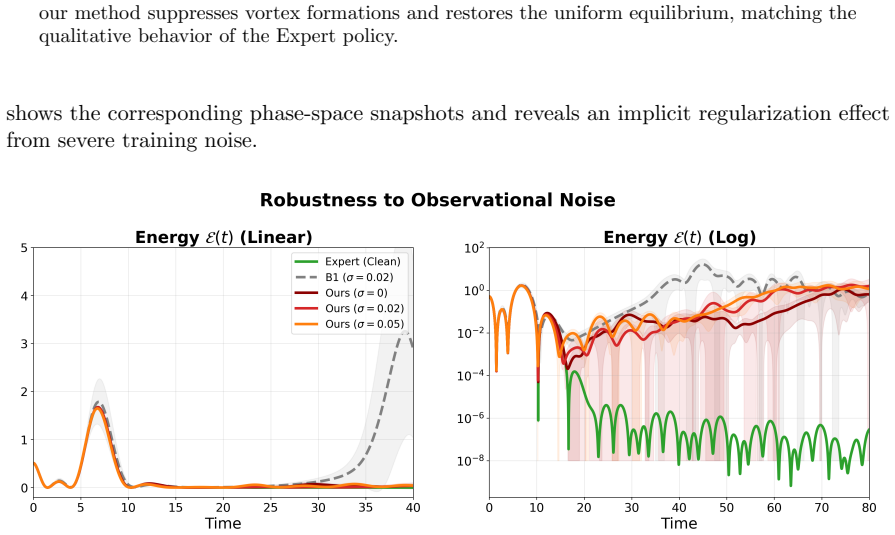
Recognition: unknown
Provable imitation learning for control of instability in partially-observed Vlasov--Poisson equations
Pith reviewed 2026-05-08 16:27 UTC · model grok-4.3
The pith
Imitation learning transfers full-state expert control to macroscopic observations for stabilizing Vlasov-Poisson plasmas.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By distilling a fully observed expert policy through behavior cloning, a controller using only macroscopic measurements can stabilize the Vlasov-Poisson system. The stability error is bounded above by the minimal cloning loss possible under the observation constraints, and this loss is characterized via the entropy of the initial distribution, which quantifies its complexity. The results establish the theoretical feasibility of learning stabilizing feedback from macroscopic data and demonstrate the approach's adaptivity to low-complexity initial structures.
What carries the argument
Behavior cloning loss under partial macroscopic observations, with its minimal value characterized by initial-distribution entropy
If this is right
- Stability holds up to an error floor given by the minimal behavior cloning loss under the observation constraints.
- Lower entropy in the initial distribution yields a smaller minimal loss and therefore tighter error bounds.
- Learned policies achieve significantly longer stabilization horizons than non-adaptive baseline controllers.
- The method automatically exploits low-complexity structures in the initial distribution.
Where Pith is reading between the lines
- Similar imitation techniques could apply to other kinetic systems where full-state experts are simulable but real sensors are limited.
- Fusion experiments might directly test whether macroscopic diagnostics suffice once an expert simulator policy is available.
- Different choices of macroscopic measurements could be ranked by how much they reduce the entropy-based minimal loss.
Load-bearing premise
A stabilizing expert policy exists under full observation whose actions remain imitable from the chosen macroscopic measurements, together with well-posedness of the Vlasov-Poisson system.
What would settle it
Simulations in which the learned policy's stabilization horizon fails to improve over baselines in proportion to the measured drop in minimal behavior cloning loss when initial entropy is reduced.
Figures



read the original abstract
We consider the stabilization of Vlasov--Poisson plasma dynamics, a central control problem in nuclear fusion. Our focus is the gap between what an ideal controller would use and what experiments can actually observe: while optimal policy may rely on the full phase-space state, practical feedback is typically limited to sparse macroscopic diagnostics. We therefore study imitation learning methods that distill a fully observed expert policy into controllers operating only on macroscopic measurements. We show the stability guarantees of the learned policy, where the error floor depends on the minimal behavior cloning loss achievable under the observation constraints. We further characterize this minimal loss in terms of a notion of entropy that quantifies the complexity of the initial distribution. Our results demonstrates the theoretical feasibility of learning stabilizing feedback policies for kinetic plasma dynamics from macroscopic observations, and exhibits the adaptivity of the learning approach to low-complexity structures. Through extensive numerical experiments, we validate our theory and show that the learned policies can stabilize the system using only macroscopic observations, within a significantly longer time horizon than non-adaptive baseline controllers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops an imitation learning approach to stabilize instabilities in the partially observed Vlasov-Poisson system, a model relevant to nuclear fusion plasmas. It assumes the existence of a stabilizing expert policy under full phase-space observations and derives stability guarantees for a learned policy that operates only on macroscopic measurements. The error floor of the learned controller is bounded by the minimal behavior-cloning loss under the observation constraints, which is further characterized in terms of an entropy quantity that quantifies the complexity of the initial distribution. Numerical experiments are presented to validate that the learned policies stabilize the system over longer horizons than non-adaptive baselines.
Significance. If the central derivations hold, the work would offer a meaningful contribution to imitation learning for high-dimensional kinetic control problems with partial observations. The entropy characterization of the minimal loss provides a concrete link between initial-data complexity and achievable performance, and the numerical results illustrate practical stabilization from realistic diagnostics. This could inform controller design in fusion contexts where full-state feedback is unavailable, provided the expert-policy premise is secured.
major comments (1)
- [Problem formulation and main stability result] The stability theorem for the learned policy (stated after the problem formulation) is conditional on the existence of a full-observation expert that stabilizes the Vlasov-Poisson dynamics and whose actions remain imitable from the chosen macroscopic measurements. The manuscript states this as an assumption without constructing the expert (e.g., via linear feedback on the linearized operator) or proving closed-loop stability. Because the subsequent imitation-error bound and entropy characterization rest directly on this premise, and because Vlasov-Poisson instabilities are known to be non-trivial to control even with full state, the claim requires either an explicit construction or a clear statement that the result is conditional on an unverified expert.
minor comments (3)
- [Problem formulation] The precise definition of the macroscopic observation operator (which moments or diagnostics are used) should be stated with an explicit formula in the problem setup section to make the partial-observation constraint reproducible.
- [Numerical experiments] In the numerical experiments section, the time horizons, discretization parameters, and exact form of the non-adaptive baseline controllers should be tabulated for direct comparison with the learned policies.
- [Entropy characterization] Notation for the entropy functional and the behavior-cloning loss should be introduced once with a clear reference to the initial distribution to avoid ambiguity when the characterization is invoked later.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review of our manuscript. The major comment raises an important point about the conditional nature of our stability result, which we address directly below. We have revised the manuscript to improve clarity on this aspect while preserving the focus of our contribution on imitation learning under partial observations.
read point-by-point responses
-
Referee: The stability theorem for the learned policy (stated after the problem formulation) is conditional on the existence of a full-observation expert that stabilizes the Vlasov-Poisson dynamics and whose actions remain imitable from the chosen macroscopic measurements. The manuscript states this as an assumption without constructing the expert (e.g., via linear feedback on the linearized operator) or proving closed-loop stability. Because the subsequent imitation-error bound and entropy characterization rest directly on this premise, and because Vlasov-Poisson instabilities are known to be non-trivial to control even with full state, the claim requires either an explicit construction or a clear statement that the result is conditional on an unverified expert.
Authors: We agree that the main theorem is conditional on the existence of a stabilizing full-observation expert whose actions are imitable from the macroscopic measurements. This premise is stated as an assumption in the original manuscript because the core technical contribution lies in the subsequent imitation-error bound and its characterization via entropy of the initial distribution, rather than in constructing the expert itself. In the revised manuscript we have added an explicit remark immediately following the problem formulation that (i) reiterates the assumption, (ii) notes that constructing a provably stabilizing expert for the full nonlinear Vlasov-Poisson system remains a separate and challenging open problem in plasma control, and (iii) clarifies that our results quantify the performance degradation incurred when only macroscopic observations are available. We have also included a short paragraph discussing plausible routes to obtaining such experts (e.g., linear feedback on the linearized operator or model-predictive control on the kinetic system) to provide context without claiming to resolve that construction within the present work. revision: yes
Circularity Check
No circularity: stability bound derived from independent entropy characterization of minimal imitation loss
full rationale
The central derivation establishes a stability error floor for the learned policy that depends on the minimal behavior-cloning loss under partial observations, then characterizes that minimal loss via an entropy functional on the initial distribution. This step is a mathematical bound rather than a self-definition or a fitted quantity renamed as a prediction. No load-bearing self-citation, uniqueness theorem imported from the authors' prior work, or ansatz smuggled via citation is present in the provided abstract and claim structure. The existence of a full-observation expert is stated as an assumption without circular reduction to the target result. Numerical experiments supply independent empirical support. The chain therefore remains non-circular.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The Vlasov-Poisson system admits a stabilizing feedback policy when the full phase-space state is available.
- domain assumption The chosen macroscopic observations are sufficient to define a behavior-cloning loss whose minimum can be bounded by entropy of the initial distribution.
Reference graph
Works this paper leans on
-
[1]
u rk c \
Cihan Ak c ay, John M. Finn, Dylan P. Brennan, Thomas Burr, and Do g a M. K \"u rk c \"u o g lu. Machine learning methods for probabilistic locked-mode predictors in tokamak plasmas. Physics of Plasmas , 28(8):082106, 2021
2021
-
[2]
Magnetic Control of Tokamak Plasmas
Marco Ariola and Alfredo Pironti. Magnetic Control of Tokamak Plasmas . Springer, Cham, 2 edition, 2016
2016
-
[3]
Bishop, Paul S
Christopher M. Bishop, Paul S. Haynes, Mike E. U. Smith, Tom N. Todd, and David L. Trotman. Real-time control of a tokamak plasma using neural networks. Neural Computation , 7(1):206--217, 1995
1995
-
[4]
Controlling a Vlasov-Poisson plasma by a particle-in-cell method based on a monte carlo framework
Jan Bartsch, Patrik Knopf, Stefania Scheurer, and J \"o rg Weber. Controlling a Vlasov-Poisson plasma by a particle-in-cell method based on a monte carlo framework. SIAM Journal on Control and Optimization , 62(4):1977--2011, 2024
1977
-
[5]
Neural operators for bypassing gain and control computations in PDE backstepping
Luke Bhan, Yuanyuan Shi, and Miroslav Krstic. Neural operators for bypassing gain and control computations in PDE backstepping. IEEE Transactions on Automatic Control , 69(8):5310--5325, 2024
2024
-
[6]
Offline model-based reinforcement learning for tokamak control
Ian Char, Joseph Abbate, Laszlo Bardoczi, Mark Boyer, Youngseog Chung, Rory Conlin, Keith Erickson, Viraj Mehta, Nathan Richner, Egemen Kolemen, and Jeff Schneider. Offline model-based reinforcement learning for tokamak control. In Proceedings of The 5th Annual Learning for Dynamics and Control Conference , volume 211 of Proceedings of Machine Learning Re...
2023
-
[7]
Francis F. Chen. Introduction to Plasma Physics and Controlled Fusion . Springer, Cham, 3 edition, 2016
2016
-
[8]
Magnetic control of tokamak plasmas through deep reinforcement learning
Jonas Degrave, Federico Felici, Jonas Buchli, Michael Neunert, Brendan Tracey, Francesco Carpanese, Timo Ewalds, Roland Hafner, Abbas Abdolmaleki, Diego de las Casas, Craig Donner, Leslie Fritz, Cristian Galperti, Andrea Huber, James Keeling, Maria Tsimpoukelli, Jackie Kay, Antoine Merle, Jean-Marc Moret, Seb Noury, Federico Pesamosca, David Pfau, Olivier...
2022
-
[9]
Aggregation by exponential weighting, sharp pac-bayesian bounds and sparsity
Arnak Dalalyan and Alexandre B Tsybakov. Aggregation by exponential weighting, sharp pac-bayesian bounds and sparsity. Machine Learning , 72(1):39--61, 2008
2008
-
[10]
Plasma magnetic control in tokamak devices
Gianmaria De Tommasi. Plasma magnetic control in tokamak devices. Journal of Fusion Energy , 38(3--4):406--436, 2019
2019
-
[11]
Einkemmer, Q
L. Einkemmer, Q. Li, C. Mouhot, and Y. Yue. Control of instability in a Vlasov-Poisson system through an external electric field. Journal of Computational Physics , 530:113904, 2025
2025
-
[12]
Control of instability in a Vlasov-Poisson system through an external electric field
Lukas Einkemmer, Qin Li, Cl \'e ment Mouhot, and Yukun Yue. Control of instability in a Vlasov-Poisson system through an external electric field. Journal of Computational Physics , 530:113904, 2025
2025
-
[13]
Suppressing instability in a Vlasov-Poisson system by an external electric field through constrained optimization
Lukas Einkemmer, Qin Li, Li Wang, and Yunan Yang. Suppressing instability in a Vlasov-Poisson system by an external electric field through constrained optimization. Journal of Computational Physics , 498:112662, 2024
2024
-
[14]
Foster, Adam Block, and Dipendra Misra
Dylan J. Foster, Adam Block, and Dipendra Misra. Is behavior cloning all you need? understanding horizon in imitation learning. In Advances in Neural Information Processing Systems , volume 37, pages 120602--120666, 2024
2024
-
[15]
Boyer, Nick Eidietis, Nathaniel Barbour, Olivier Izacard, and Egemen Kolemen
Yichen Fu, David Eldon, Keith Erickson, Kornee Kleijwegt, Leonard Lupin-Jimenez, Mark D. Boyer, Nick Eidietis, Nathaniel Barbour, Olivier Izacard, and Egemen Kolemen. Machine learning control for disruption and tearing mode avoidance. Physics of Plasmas , 27(2):022501, 2020
2020
-
[16]
On the controllability of the Vlasov-Poisson system in the presence of external force fields
Olivier Glass and Daniel Han-Kwan. On the controllability of the Vlasov-Poisson system in the presence of external force fields. Journal of Differential Equations , 252(10):5453--5491, 2012
2012
-
[17]
On the controllability of the Vlasov-Poisson system
Olivier Glass. On the controllability of the Vlasov-Poisson system. Journal of Differential Equations , 195(2):332--379, 2003
2003
-
[18]
Solving PDE -constrained control problems using operator learning
Rakhoon Hwang, Jae Yong Lee, Jin Young Shin, and Hyung Ju Hwang. Solving PDE -constrained control problems using operator learning. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 36(4), pages 4504--4512, 2022
2022
-
[19]
Learning to control PDEs with differentiable physics
Philipp Holl, Nils Thuerey, and Vladlen Koltun. Learning to control PDEs with differentiable physics. In International Conference on Learning Representations , 2020
2020
-
[20]
Predicting disruptive instabilities in controlled fusion plasmas through deep learning
Julian Kates-Harbeck, Alexey Svyatkovskiy, and William Tang. Predicting disruptive instabilities in controlled fusion plasmas through deep learning. Nature , 568(7753):526--531, 2019
2019
-
[21]
J. E. Kinsey, L. L. Lao, O. Meneghini, J. Candy, P. B. Snyder, and G. M. Staebler. Equilibrium reconstruction of DIII-D plasmas using predictive modeling of the pressure profile. Physics of Plasmas , 29(6):062502, 2022
2022
-
[22]
L. D. Landau. On the vibrations of the electronic plasma. Yad. Fiz. , 10:25, 1946. Also listed as Zh. Eksp. Teor. Fiz. 16 (1946), p. 574; English translation commonly cited as Journal of Physics (USSR) 10(1), 25--34
1946
-
[23]
L. L. Lao, H. E. St. John, Q. Peng, J. R. Ferron, E. J. Strait, T. S. Taylor, W. H. Meyer, C. Zhang, and K. I. You. MHD equilibrium reconstruction in the DIII-D tokamak. Fusion Science and Technology , 48(2):968--977, 2005
2005
-
[24]
McClenaghan, C
J. McClenaghan, C. Ak c ay, T. B. Amara, X. Sun, S. Madireddy, L. L. Lao, S. E. Kruger, and O. M. Meneghini. Augmenting machine learning of grad--shafranov equilibrium reconstruction with green's functions. Physics of Plasmas , 31(8):082507, 2024
2024
-
[25]
First application of data assimilation-based control to fusion plasma
Yuya Morishita, Sadayoshi Murakami, Naoki Kenmochi, Hisamichi Funaba, Ichihiro Yamada, Yoshinori Mizuno, Kazuki Nagahara, Hideo Nuga, Ryosuke Seki, Masayuki Yokoyama, Genta Ueno, and Masaki Osakabe. First application of data assimilation-based control to fusion plasma. Scientific Reports , 14(1):137, 2024
2024
-
[26]
A control oriented strategy of disruption prediction to avoid the configuration collapse of tokamak reactors
Andrea Murari, Riccardo Rossi, Teddy Craciunescu, Jes \'u s Vega, JET Contributors , and Michela Gelfusa. A control oriented strategy of disruption prediction to avoid the configuration collapse of tokamak reactors. Nature Communications , 15(1):2424, 2024
2024
-
[27]
K. J. Montes, C. Rea, R. S. Granetz, R. A. Tinguely, N. Eidietis, O. M. Meneghini, D. L. Chen, B. Shen, B. J. Xiao, K. Erickson, and M. D. Boyer. Machine learning for disruption warnings on Alcator C-Mod , DIII-D , and EAST . Nuclear Fusion , 59(9):096015, 2019
2019
-
[28]
On L andau damping
Cl \'e ment Mouhot and C \'e dric Villani. On L andau damping. Acta Mathematica , 207(1):29--201, 2011
2011
-
[29]
Electrostatic instabilities of a uniform non-maxwellian plasma
Oliver Penrose. Electrostatic instabilities of a uniform non-maxwellian plasma. The Physics of Fluids , 3(2):258--265, 1960
1960
-
[30]
Pomerleau
Dean A. Pomerleau. ALVINN : An autonomous land vehicle in a neural network. In Advances in Neural Information Processing Systems , volume 1, pages 305--313, 1988
1988
-
[31]
Efficient reductions for imitation learning
Stephane Ross and Drew Bagnell. Efficient reductions for imitation learning. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , volume 9 of Proceedings of Machine Learning Research , pages 661--668, 2010
2010
-
[32]
Reinforcement and Imitation Learning via Interactive No-Regret Learning
Stephane Ross and J. Andrew Bagnell. Reinforcement and imitation learning via interactive no-regret learning. arXiv preprint arXiv:1406.5979 , 2014
work page Pith review arXiv 2014
-
[33]
A reduction of imitation learning and structured prediction to no-regret online learning
Stephane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics , volume 15 of Proceedings of Machine Learning Research , pages 627--635, 2011
2011
-
[34]
C. Rea, K. J. Montes, K. G. Erickson, R. S. Granetz, and R. A. Tinguely. A real-time machine learning-based disruption predictor in DIII-D . Nuclear Fusion , 59(9):096016, 2019
2019
-
[35]
A machine learning framework for solving high-dimensional mean field game and mean field control problems
Lars Ruthotto, Stanley J Osher, Wuchen Li, Levon Nurbekyan, and Samy Wu Fung. A machine learning framework for solving high-dimensional mean field game and mean field control problems. Proceedings of the National Academy of Sciences , 117(17):9183--9193, 2020
2020
-
[36]
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational physics , 378:686--707, 2019
2019
-
[37]
Toward the fundamental limits of imitation learning
Nived Rajaraman, Lin Yang, Jiantao Jiao, and Kannan Ramchandran. Toward the fundamental limits of imitation learning. In Advances in Neural Information Processing Systems , volume 33, pages 2914--2924, 2020
2020
-
[38]
Avoiding fusion plasma tearing instability with deep reinforcement learning
Jaemin Seo, SangKyeun Kim, Azarakhsh Jalalvand, Rory Conlin, Andrew Rothstein, Joseph Abbate, Keith Erickson, Josiah Wai, Ricardo Shousha, and Egemen Kolemen. Avoiding fusion plasma tearing instability with deep reinforcement learning. Nature , 626(8000):746--751, 2024
2024
-
[39]
The pitfalls of imitation learning when actions are continuous
Max Simchowitz, Daniel Pfrommer, and Ali Jadbabaie. The pitfalls of imitation learning when actions are continuous. In Proceedings of Thirty Eighth Conference on Learning Theory , volume 291 of Proceedings of Machine Learning Research , pages 5248--5351, 2025
2025
-
[40]
Real-time disruption prediction in the plasma control system of HL-2A based on deep learning
Zongyu Yang, Fan Xia, Xianming Song, Zhe Gao, Yixuan Li, Xinwen Gong, Yunbo Dong, Yipo Zhang, Chengyuan Chen, Cuiwen Luo, Bo Li, Xiaobo Zhu, Xiaoquan Ji, Yonggao Li, Liang Liu, Jinming Gao, and Yuhang Liu. Real-time disruption prediction in the plasma control system of HL-2A based on deep learning. Fusion Engineering and Design , 182:113223, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.