Recognition: unknown
External Validation of Deep Learning Models for BI-RADS Breast Density Prediction from Ultrasound Images
Pith reviewed 2026-05-08 15:24 UTC · model grok-4.3
The pith
Deep learning models for breast density prediction from ultrasound images generalize well to external data with different racial composition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
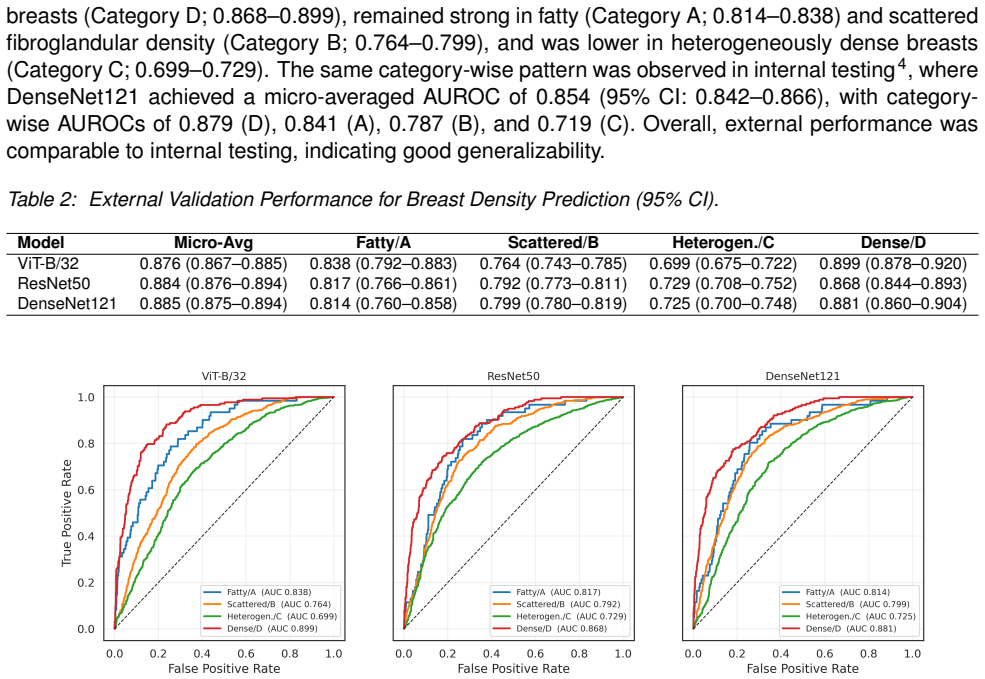
Three models (DenseNet121, ViT-B/32, and ResNet50) were externally validated on 2,000 ultrasound exams, yielding patient-level AUROCs of 0.814-0.838 for fatty, 0.764-0.799 for scattered, 0.699-0.729 for heterogeneously dense, and 0.868-0.899 for extremely dense breasts. DenseNet121 reached the highest micro-averaged AUROC of 0.885, with category performance comparable between internal and external testing. Substituting AI-derived density for mammography-reported density in the Tyrer-Cuzick model produced an AUROC of 0.541 versus 0.570, a nonsignificant difference.
What carries the argument
Patient-level AUROC evaluation of DenseNet121, ViT-B/32, and ResNet50 on a matched external ultrasound cohort for four-class BI-RADS density classification.
If this is right
- Deep learning models can assess BI-RADS breast density from ultrasound with performance that transfers across populations differing in racial composition.
- Extremely dense breasts are classified most reliably while heterogeneously dense breasts remain the hardest category and need targeted improvements.
- AI-derived density scores can be substituted into existing risk models such as Tyrer-Cuzick with results statistically similar to those using mammography-reported density.
Where Pith is reading between the lines
- Ultrasound-based density assessment could become practical in screening programs or regions where mammography access is limited.
- Focusing model development on the heterogeneous-density category may require richer image features or additional clinical variables.
- Broad external validation of this kind supports eventual multi-site or cross-population deployment of ultrasound density tools.
Load-bearing premise
The external validation set is truly independent and representative of the target population, with cancer cases correctly identified by negative initial exam followed by diagnosis within 6 months to 10 years, and controls matched by manufacturer and study year without introducing selection bias.
What would settle it
A new external test set with similar racial diversity that produces AUROCs below 0.65 for heterogeneously dense breasts or statistically lower overall performance than internal testing would falsify the generalization claim.
Figures
read the original abstract
We externally validated three deep learning models (DenseNet121, ViT-B/32, and ResNet50) for predicting mammographic breast density from breast ultrasound exams on an independent cohort. The external validation set comprised 2,000 ultrasound exams, including 500 cancer cases defined by an initial negative exam (BI-RADS 1 or 2) followed by a cancer diagnosis within 6 months to 10 years, and 1,500 negative controls matched by manufacturer and study year. Performance was measured using patient-level AUROC across four density categories: A (fatty), B (scattered), C (heterogeneous), and D (extremely dense). As a downstream assessment, we also evaluated 10-year risk prediction by incorporating age and AI-derived density into the Tyrer-Cuzick model and comparing performance against a reference model using age and mammography-reported density. All three models performed best in extremely dense breasts (AUROC 0.868-0.899), with strong performance in fatty (0.814-0.838) and scattered density (0.764-0.799), and lower performance in heterogeneously dense breasts (0.699-0.729). DenseNet121 achieved the highest overall performance (micro-averaged AUROC 0.885), and performance across categories was comparable between internal and external testing. For risk modeling, age combined with AI-derived density yielded a lower AUROC than age combined with mammography-reported density (0.541 vs. 0.570; p = 0.23), with no statistically significant difference. These findings indicate that deep learning models generalize well to external data with different racial composition for breast density assessment. While performance is strongest in extremely dense breasts, heterogeneously dense remains more challenging, highlighting the need for targeted optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper externally validates three deep learning models (DenseNet121, ViT-B/32, ResNet50) for BI-RADS breast density classification from ultrasound images on an independent 2,000-exam cohort (500 interval-cancer cases defined by initial BI-RADS 1/2 followed by diagnosis in 6 mo–10 yr, plus 1,500 manufacturer/year-matched controls). It reports patient-level AUROCs (micro-averaged 0.885 for DenseNet121; category-specific ranges 0.699–0.899), notes strongest performance in extremely dense breasts and weaker in heterogeneously dense, shows comparable internal/external category performance, and finds no significant difference in 10-year risk prediction when substituting AI-derived density for mammography-reported density in the Tyrer-Cuzick model (AUROC 0.541 vs 0.570, p=0.23). The central claim is that the models generalize well to external data with different racial composition.
Significance. If the external cohort truly represents a racially shifted population and the performance numbers are robust, the work would provide useful evidence that ultrasound-based density models can transfer across sites and demographics, supporting broader deployment of AI density tools where mammography is limited. The risk-modeling experiment is a reasonable downstream check, though the non-significant result limits its impact.
major comments (3)
- [Methods / External validation set] External validation set construction (Methods section): The cohort is assembled from 500 future-cancer cases plus 1,500 matched controls; because density is a known risk factor, this case-control design is expected to enrich for higher-density exams relative to a pure screening population. The manuscript must report the actual racial composition percentages (e.g., % Asian, Black, White) for both internal training and external sets, together with a statistical test of difference, to substantiate the claim of “different racial composition.” Without these numbers the generalization interpretation cannot be separated from selection effects.
- [Results] Performance reporting (Results): AUROCs are given as point estimates (e.g., micro 0.885, category C 0.70) with no confidence intervals, bootstrap standard errors, or per-model variance across the three architectures. In addition, the risk-model comparison yields p=0.23; the manuscript should state the power calculation or sample-size justification for detecting a clinically meaningful difference in this downstream task.
- [Methods] Independence and harmonization (Methods): The paper asserts the external set is “independent” and drawn from a population with different racial makeup, yet provides no details on site-specific ultrasound acquisition protocols, probe frequencies, or image preprocessing steps that might differ from the training distribution. A table or paragraph comparing key acquisition parameters and confirming no patient overlap is required to support the external-validation framing.
minor comments (2)
- [Abstract / Results] Abstract and Results: The phrase “performance across categories was comparable between internal and external testing” should be supported by a side-by-side table of AUROCs rather than a qualitative statement.
- [Results] Notation: “micro-averaged AUROC” is used without defining whether it is the micro-average over the four-class one-vs-rest AUROCs or a different aggregation; a brief clarification would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments, which have helped us identify areas to strengthen the manuscript. We have prepared point-by-point responses below and will incorporate revisions to address the concerns raised regarding demographic reporting, statistical rigor, and validation details.
read point-by-point responses
-
Referee: [Methods / External validation set] External validation set construction (Methods section): The cohort is assembled from 500 future-cancer cases plus 1,500 matched controls; because density is a known risk factor, this case-control design is expected to enrich for higher-density exams relative to a pure screening population. The manuscript must report the actual racial composition percentages (e.g., % Asian, Black, White) for both internal training and external sets, together with a statistical test of difference, to substantiate the claim of “different racial composition.” Without these numbers the generalization interpretation cannot be separated from selection effects.
Authors: We agree that explicit reporting of racial demographics is necessary to support the generalization claim. We will add a dedicated table in the Methods section listing the racial composition percentages (Asian, Black, White, and other) for both the internal training cohort and the external validation set. We will also perform and report a chi-square test (or Fisher's exact test as appropriate) to quantify the statistical difference in distributions. While the case-control sampling does enrich for higher-density breasts, we note that performance is already stratified by density category and that controls were matched on manufacturer and year; the added demographics will allow readers to better isolate racial effects from selection bias. revision: yes
-
Referee: [Results] Performance reporting (Results): AUROCs are given as point estimates (e.g., micro 0.885, category C 0.70) with no confidence intervals, bootstrap standard errors, or per-model variance across the three architectures. In addition, the risk-model comparison yields p=0.23; the manuscript should state the power calculation or sample-size justification for detecting a clinically meaningful difference in this downstream task.
Authors: We accept the need for improved statistical transparency. We will recompute and report 95% confidence intervals for all AUROCs via bootstrap resampling (1,000 iterations) and will include the standard deviation of AUROC values across the three architectures (DenseNet121, ViT-B/32, ResNet50). For the Tyrer-Cuzick risk-model comparison, we will add a brief sample-size justification based on the 2,000-exam external cohort and note that the study was powered for the primary density-classification task rather than the secondary risk-modeling endpoint. We will also state that the observed p=0.23 indicates the data are consistent with no meaningful difference but acknowledge limited power to detect small AUROC shifts; the point estimates (0.541 vs 0.570) remain informative for the manuscript's conclusions. revision: partial
-
Referee: [Methods] Independence and harmonization (Methods): The paper asserts the external set is “independent” and drawn from a population with different racial makeup, yet provides no details on site-specific ultrasound acquisition protocols, probe frequencies, or image preprocessing steps that might differ from the training distribution. A table or paragraph comparing key acquisition parameters and confirming no patient overlap is required to support the external-validation framing.
Authors: We will expand the Methods section with a new paragraph describing the external site's ultrasound acquisition protocols, including probe frequencies, transducer types, and gain settings. We will also insert a comparison table listing manufacturer, probe frequency range, image resolution, and preprocessing steps (e.g., resizing, normalization) for both internal and external data. Finally, we will explicitly confirm zero patient overlap by cross-checking unique identifiers and study dates. These additions will provide the necessary technical context to substantiate the external-validation design. revision: yes
Circularity Check
No significant circularity in empirical external validation study
full rationale
The paper conducts a straightforward empirical validation of three deep learning models (DenseNet121, ViT-B/32, ResNet50) trained on internal ultrasound data and evaluated via AUROC on a held-out external cohort of 2000 exams. No mathematical derivations, equations, or parameter estimations are presented that reduce the generalization claim to the training inputs by construction. Performance metrics are computed directly on the external set without any self-referential fitting or renaming of results. The central claim rests on observed AUROCs (e.g., micro-averaged 0.885) rather than any load-bearing self-citation chain or ansatz. This is a standard independent validation setup with no circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The BI-RADS density categories from mammography are the ground truth for training and evaluation.
- domain assumption The external cohort is independent of the training data.
Reference graph
Works this paper leans on
-
[1]
Journal Name , volume =
Author One and Author Two and Author Three , title =. Journal Name , volume =. 2022 , doi =
2022
-
[2]
Reference examples , year =
-
[3]
The Lancet Regional Health--Americas , volume=
Prediction of mammographic breast density based on clinical breast ultrasound images using deep learning: a retrospective analysis , author=. The Lancet Regional Health--Americas , volume=. 2025 , publisher=
2025
-
[4]
Annals of internal medicine , volume=
Using clinical factors and mammographic breast density to estimate breast cancer risk: development and validation of a new predictive model , author=. Annals of internal medicine , volume=. 2008 , publisher=
2008
-
[5]
Journal of global oncology , year=
Ultrasound for breast cancer detection globally: a systematic review and meta-analysis , author=. Journal of global oncology , year=
-
[6]
PLoS One , volume=
BUSClean: Open-source software for breast ultrasound image pre-processing and knowledge extraction for medical AI , author=. PLoS One , volume=. 2024 , publisher=
2024
-
[7]
2021 , url=
The NYU Breast Ultrasound Dataset v1.0 , author=. 2021 , url=
2021
-
[8]
Anonymous Breast Ultrasound Dataset , author=
-
[9]
Spak, David Allen and Plaxco, JS and Santiago, L and Dryden, MJ and Dogan, BE , journal=. BI-RADS. 2017 , publisher=
2017
-
[10]
Statistics in medicine , volume=
A breast cancer prediction model incorporating familial and personal risk factors , author=. Statistics in medicine , volume=. 2004 , publisher=
2004
-
[11]
2017 , howpublished =
Cuzick, Jack , title =. 2017 , howpublished =
2017
-
[12]
Annual Estimates of the Resident Population by Sex, Race, and Hispanic Origin for Hawaii: April 1, 2020 to July 1, 2023 (SC-EST2023-SR11H-15) , year =
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.