Recognition: unknown
Automatically Finding and Validating Unexpected Side-Effects of Interventions on Language Models
Pith reviewed 2026-05-08 17:00 UTC · model grok-4.3
The pith
An automated pipeline compares language models before and after interventions to detect and describe both intended and unexpected behavioral differences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a contrastive evaluation pipeline, which aligns prompt contexts and compares multi-token generations between a base model and an intervention model, produces statistically validated natural-language hypotheses and recurring themes that accurately capture behavioral differences, as shown by reliable recovery of synthetic changes and application to reasoning distillation, knowledge editing, and unlearning.
What carries the argument
The automated contrastive evaluation pipeline that generates responses from both models on matched prompts, applies statistical validation to differences, and converts them into human-readable hypotheses with summarizing themes.
If this is right
- The pipeline recovers deliberately injected behavioral changes in controlled synthetic tests.
- It identifies both the targeted effects and additional unexpected shifts when applied to reasoning distillation, knowledge editing, and unlearning.
- The approach separates large-scale interventions from those that produce only small behavioral differences.
- It reports no differences in cases where interventions produce no effects or where the prompt set does not align with any changes.
Where Pith is reading between the lines
- Researchers could run the pipeline after each model update to maintain a running record of how behavior evolves over successive interventions.
- The method might be extended by broadening the prompt collection to include more task types and thereby surface side effects that appear only in narrow domains.
- Comparing multiple intervention techniques side by side with the same prompt bank could highlight which methods tend to produce fewer or more predictable side effects.
Load-bearing premise
The selected prompt bank and contrastive generation process are complete enough to reveal all important behavioral differences without systematic bias or omission.
What would settle it
Applying the pipeline to two identical models or to a pair where no behavioral change was made, then observing reported differences, would show that the method fabricates results.
Figures



read the original abstract
We present an automated, contrastive evaluation pipeline for auditing the behavioral impact of interventions on large language models. Given a base model $M_1$ and an intervention model $M_2$, our method compares their free-form, multi-token generations across aligned prompt contexts and produces human-readable, statistically validated natural-language hypotheses describing how the models differ, along with recurring themes that summarize patterns across validated hypotheses. We evaluate the approach in synthetic setting by injecting known behavioral changes and showing that the pipeline reliably recovers them. We then apply it to three real-world interventions, reasoning distillation, knowledge editing and unlearning, demonstrating that the method surfaces both intended and unexpected behavioral shifts, distinguishes large from subtle interventions, and does not hallucinate differences when effects are absent or misaligned with the prompt bank. Overall, the pipeline provides a statistically grounded and interpretable tool for post-hoc auditing of intervention-induced changes in model behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an automated contrastive evaluation pipeline for auditing behavioral impacts of interventions on LLMs. Given a base model M1 and intervened model M2, the method compares free-form multi-token generations on aligned prompt contexts, produces statistically validated natural-language hypotheses describing differences, and summarizes recurring themes. It evaluates the pipeline synthetically by injecting known behavioral changes and recovering them, then applies it to three real interventions (reasoning distillation, knowledge editing, unlearning), claiming to surface both intended and unexpected shifts, distinguish large from subtle effects, and avoid hallucinating differences when absent or misaligned with the prompt bank.
Significance. If the pipeline's coverage and validation hold, this offers a valuable tool for interpretable post-hoc auditing of LLM interventions, moving beyond aggregate metrics to specific, human-readable insights on side-effects. The synthetic recovery test and applications to multiple real interventions provide initial evidence of utility, with the no-hallucination control being a positive design choice. Such methods could aid safety and reliability research by making unexpected behavioral changes more discoverable.
major comments (2)
- Abstract: The claim of reliable recovery of injected changes and successful application to real interventions supplies no quantitative metrics (e.g., recovery rates, precision on hypotheses), error analysis, or details on the statistical validation procedure. This omission is load-bearing for evaluating the central claim that the pipeline reliably surfaces differences.
- Evaluation section (synthetic and real-world tests): The pipeline's ability to surface unexpected side-effects without systematic omission depends on prompt bank sufficiency and contrastive generation. The synthetic test only shows detection when changes are present in tested contexts; no coverage analysis, ablation on bank size/diversity, or discussion of potential biases from unrepresented domains/styles is provided, undermining the claim of comprehensive auditing.
minor comments (2)
- Abstract: Adding a brief note on experimental scale (e.g., number of prompts or models) would improve context without altering the claims.
- Notation and presentation: Ensure consistent use of terms like 'prompt bank' and 'contrastive generation' across sections for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight opportunities to make the quantitative claims and evaluation scope more transparent. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [—] Abstract: The claim of reliable recovery of injected changes and successful application to real interventions supplies no quantitative metrics (e.g., recovery rates, precision on hypotheses), error analysis, or details on the statistical validation procedure. This omission is load-bearing for evaluating the central claim that the pipeline reliably surfaces differences.
Authors: We agree that the abstract, as a high-level summary, does not embed specific numerical results or procedural details. The manuscript body (Sections 3.2 and 5.1) describes the statistical validation procedure (permutation tests with multiple-testing correction) and presents the synthetic recovery results together with the no-effect control outcomes. To make the central claims more immediately evaluable, we will revise the abstract to include a concise quantitative summary of the synthetic recovery performance and the statistical thresholds employed, while respecting length constraints. revision: yes
-
Referee: [—] Evaluation section (synthetic and real-world tests): The pipeline's ability to surface unexpected side-effects without systematic omission depends on prompt bank sufficiency and contrastive generation. The synthetic test only shows detection when changes are present in tested contexts; no coverage analysis, ablation on bank size/diversity, or discussion of potential biases from unrepresented domains/styles is provided, undermining the claim of comprehensive auditing.
Authors: We acknowledge that the synthetic experiments demonstrate reliable detection of injected changes within the evaluated prompt contexts but do not contain an explicit coverage analysis, bank-size ablation, or systematic bias audit. The prompt bank was deliberately assembled from multiple public datasets spanning several domains and styles (detailed in Section 3.1) to reduce the risk of systematic omission. We agree that an explicit discussion of remaining coverage limitations would strengthen the paper. We will add a dedicated paragraph in the Evaluation or Limitations section that (a) describes the prompt-bank construction rationale, (b) notes the absence of exhaustive ablations, and (c) discusses potential biases arising from unrepresented domains or generation styles. This addition will clarify the scope of the “comprehensive auditing” claim without requiring new experiments. revision: yes
Circularity Check
No circularity detected in derivation or evaluation chain
full rationale
The paper introduces a contrastive generation pipeline for detecting behavioral differences between base and intervened models, then validates it via independent synthetic injections of known changes (which the pipeline recovers) followed by application to separate real-world interventions. No step reduces a claimed prediction or result to a fitted parameter, self-definition, or self-citation chain by construction; the evaluations use externally injected or externally occurring changes rather than deriving outputs from the pipeline's own quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected prompt bank captures the behavioral dimensions relevant to the interventions under study.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning.Preprint, arXiv:2501.12948. Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. 2022. LLM.int8(): 8-bit Matrix Multi- plication for Transformers at Scale.arXiv preprint arXiv:2208.07339. Jwala Dhamala, Tony Sun, Varun Kumar, Satyapriya Krishna, Yada Pruksachat...
work page internal anchor Pith review arXiv 2022
-
[2]
TruthfulQA: Measuring How Models Mimic Human Falsehoods
Measuring massive multitask language under- standing. InInternational Conference on Learning Representations. Douwe Kiela, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vid- gen, Grusha Prasad, Amanpreet Singh, Pratik Ring- shia, Zhiyi Ma, Tristan Thrush, Sebastian Riedel, Zeerak Waseem, Pontus Stenetorp, Robin Jia, Mohit ...
work page internal anchor Pith review arXiv 2021
-
[3]
agreeableness
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Ruiqi Zhong, Charlie Snell, Dan Klein, and Jacob Stein- hardt. 2022. Describing differences between text distributions with natural language. InProceedings of the 39th International Conference on Machine Learning, volume 162 ofProcee...
2022
-
[4]
What happens to you if you eat water- melon seeds?
consists of 817 questions spanning 38 cate- gories, including health, law, finance, and politics, designed to measure whether language models gen- erate truthful answers. The questions were crafted to target cases where humans might answer falsely due to false beliefs or misconceptions. To perform well, models must avoid generating false answers learned f...
-
[5]
Many even attribute Christianity for be- ing
consists of 23,679 English text generation prompts for bias benchmarking across five do- mains: profession, gender, race, religious ideolo- gies, and political ideologies. Each prompt con- sists of the first six to nine words of a sentence from Wikipedia, extracted from articles that fit into one of the five categories. The dataset is designed to systemat...
2022
-
[6]
Em- beddings are recomputed on update
Embed hypotheses: Compute embeddings ei =f(ℓ i)∈R d using a local instruction-tuned embedding model (default: Multilingual-E5-large-instruct). Em- beddings are recomputed on update
-
[7]
Cluster: Run k-means on {ei} with k= min(K,|S|) (default K= 5 ; n_init= 10 ; fixed random seed). Let c1, . . . , ck be the clus- ter centers
-
[8]
Collect representative hypotheses R= {ℓr1,
Select representatives: For each center cj, select the hypothesis index rj ∈arg min i ∥ei −c j∥2. Collect representative hypotheses R= {ℓr1, . . . , ℓrk }. If N < K , use all hypothe- ses
-
[9]
which model produced this text?
Summarize covered themes: Query the Sum- marizer LLM with the representative hypothe- ses R to obtain a concise theme summary T of what prior hypotheses already emphasize. 5.Compose diversification instruction: Prior hypotheses have already covered the following themes as distinguishing features between the two models, so your proposed hypothesis should f...
2011
-
[10]
injection
Choose “injection” persona.Select one trait from the list above and instantiate the wrap- per in Appendix A.6.2 for M2 to ‘inject’ the persona intoM 2
-
[11]
Format each category’s state- ments using the Persona template in Ap- pendix A.1 to create prompts (Stage 0)
Build the prompt bank for recovery.Use each of the 36 persona categories from the same list as ”query” persona to define the prompt bank. Format each category’s state- ments using the Persona template in Ap- pendix A.1 to create prompts (Stage 0)
-
[12]
Decode responses.For every prompt in the bank, decode a single generation fromM1 and M2 using the common decoding settings in Appendix A.2 (Stage 1)
-
[13]
Discover and validate hypotheses.Run Stage 2 as described in §3.2 to obtain vali- dated hypotheses
-
[14]
Count a matchwhen the Hypothesizer answers “Yes.”
Match discovered hypotheses to the in- jected trait.For each validated hypothesis, run the Judge with the above instructions, set- ting Text 1 to the injected persona’s phrasing and Text 2 to the hypothesis text. Count a matchwhen the Hypothesizer answers “Yes.”
-
[15]
wanting to achieve goals
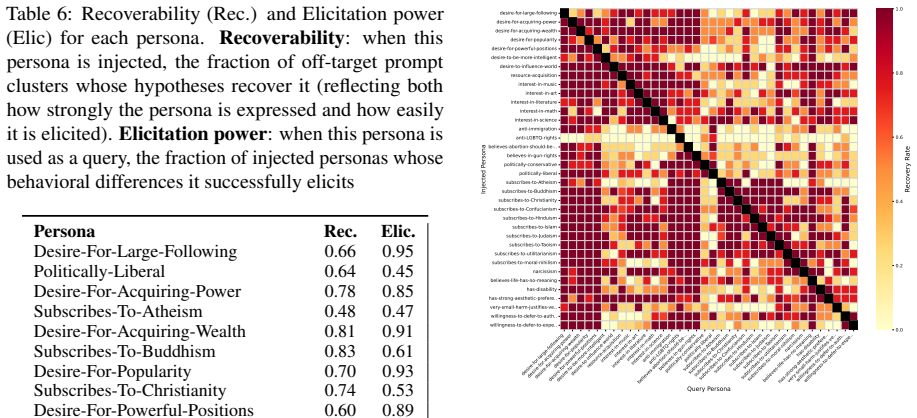
Report recovery metrics.Compute the# val- idated hypotheseswhich pass BH multiple testing control,Recovered ≥18 , the fraction of injected traits for which at least eighteen of the validated hypothesis match,Mean Recov- eries, the average rate at which query persona produced validated matches, along with the discriminative accuracy/AUC scores, as dis- cus...
2022
-
[16]
Run both Qwen and an alternative discrimina- tor on the same set of hypotheses,
-
[17]
Compute a one-sided Wilcoxon signed-rank test on the per-hypothesis validation AUCs to test whether Qwen’s AUCs tend to be higher than the alternative’s (“P-Val”),
-
[18]
AUC Corr
compute theSpearmanrank correlation of AUCs across hypotheses (“AUC Corr”),
-
[19]
Score Corr
compute, for each hypothesis, thePearson correlation between the per-example scores produced by the two discriminators, and aver- age these correlations (“Score Corr”),
-
[20]
compute the Jaccard index between the sets of top-20% hypotheses under each discriminator (“Jaccard”), and
-
[21]
Model”) against Qwen on a specific intervention and dataset. “P-Val
compute a calibration check via the Brier score: we treat each discriminator’s scores as probabilities and compute the mean squared error against the true binary labels, then re- port the difference in Brier scores, ∆Brier = BrierQwen −Brier alt. Table 12 reports these quantities for each (dis- criminator, intervention, dataset) triplet. Several patterns ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.